







本文属于专栏《构建工业级QPS百万级服务》系列简介-CSDN博客
1、什么是可观测性
可观测性最早是1948年由电气工程领域的控制理论家Claude Shannon在《通信的数学理论》提出的。这也是信息论的奠基性文献。可观测性是指能够通过检查系统或应用的指标(Metrics)、日志(Logs)、痕迹(Traces)来监控、测量和理解系统或应用的状态。
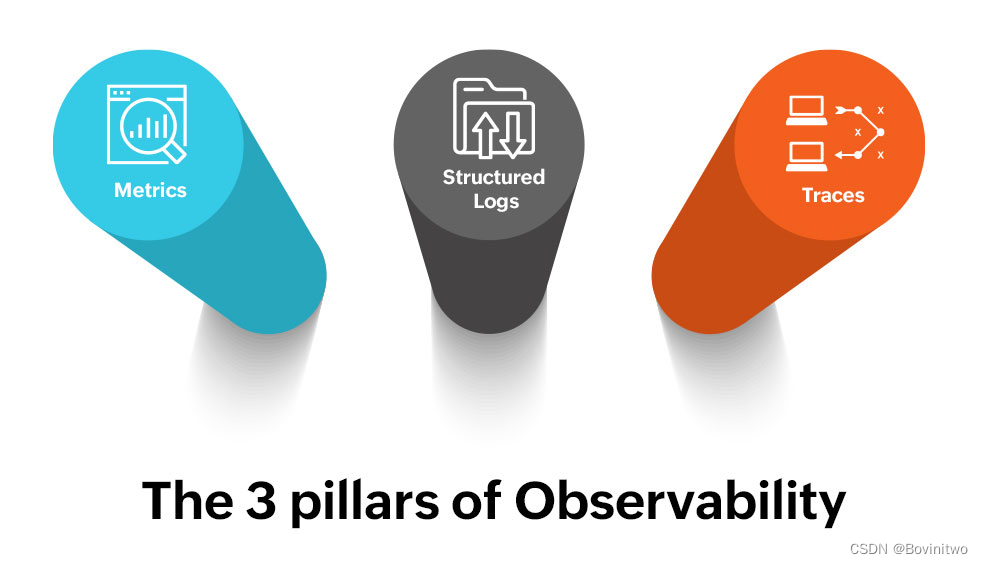
同理,对应到软件系统,这单个指标基本适用,但不够直接到让我们基于它们直接设计落地方案。我的实践经验是,软件系统中,“输出”、“日志”、“性能”,是系统状态最重要的指标。它们分别对应了
- 输出(下游观测):当前系统生产给I/O设备的字节
- 日志(自身观测):应用程序运行中的,向磁盘写入的,记录进程运行过程的数据
- 性能(平台观测):操作系统角度观察的进程运行时的硬件资源占用情况
从上面可以看出,所有软件系统的观测,本质都是人观测I/O设备的数据。(在云时代,CPU的温度的硬件信息
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









