






L0 linux+InternStudio
闯关任务:实现ssh连接与端口映射并运行py文件
一、选择创建个人开发机,名称为test,Cuda版本为12.2,资源配置选择10%,时长默认就行。
创建完成以后在开发机界面可以看到刚刚创建的开发机,点击进入开发机。
二、SSH及端口映射
2.1 什么是SSH?
SSH全称Secure Shell,中文翻译为安全外壳,它是一种网络安全协议,通过加密和认证机制实现安全的访问和文件传输等业务。SSH 协议通过对网络数据进行加密和验证,在不安全的网络环境中提供了安全的网络服务。
SSH 是(C/S架构)由服务器和客户端组成,为建立安全的 SSH 通道,双方需要先建立 TCP 连接,然后协商使用的版本号和各类算法,并生成相同的会话密钥用于后续的对称加密。在完成用户认证后,双方即可建立会话进行数据交互。
那在后面的实践中我们会配置SSH密钥,配置密钥是为了当我们远程连接开发机时不用重复的输入密码,那为什么要进行远程连接呢?
远程连接的好处就是,如果你使用的是远程办公,你可以通过SSH远程连接开发机,这样就可以在本地进行开发。而且如果你需要跑一些本地的代码,又没有环境,那么远程连接就非常有必要了。
2.2 如何使用SSH远程连接开发机?
2.2.1 使用密码进行SSH远程连接
首先我们使用输入密码的方式进行SSH远程连接,后面我们会讲如何配置免密登录。
当完成开发机的创建以后,我们需要打开自己电脑的powerShell终端,使用Win+R快捷键打开运行框,输入powerShell,打开powerShell终端。(如果你是Linux或者Mac操作系统,下面的步骤都是一样的)
我们回到开发机平台,进入开发机页面找到我们创建的开发机,点击SSH连接。
连接成功:
2.3. 端口映射
2.3.1 什么是端口映射?
端口映射是一种网络技术,它可以将外网中的任意端口映射到内网中的相应端口,实现内网与外网之间的通信。通过端口映射,可以在外网访问内网中的服务或应用,实现跨越网络的便捷通信。
那么我们使用开发机为什么要进行端口映射呢?
因为在后续的课程中我们会进行模型web_demo的部署实践,那在这个过程中,很有可能遇到web ui加载不全的问题。这是因为开发机Web IDE中运行web_demo时,直接访问开发机内 http/https 服务可能会遇到代理问题,外网链接的ui资源没有被加载完全。
所以为了解决这个问题,我们需要对运行web_demo的连接进行端口映射,将外网链接映射到我们本地主机,我们使用本地连接访问,解决这个代理问题。下面让我们实践一下。
第一步先配置环境本次需要环境 gradio,进行配置
第二步运行代码1.py
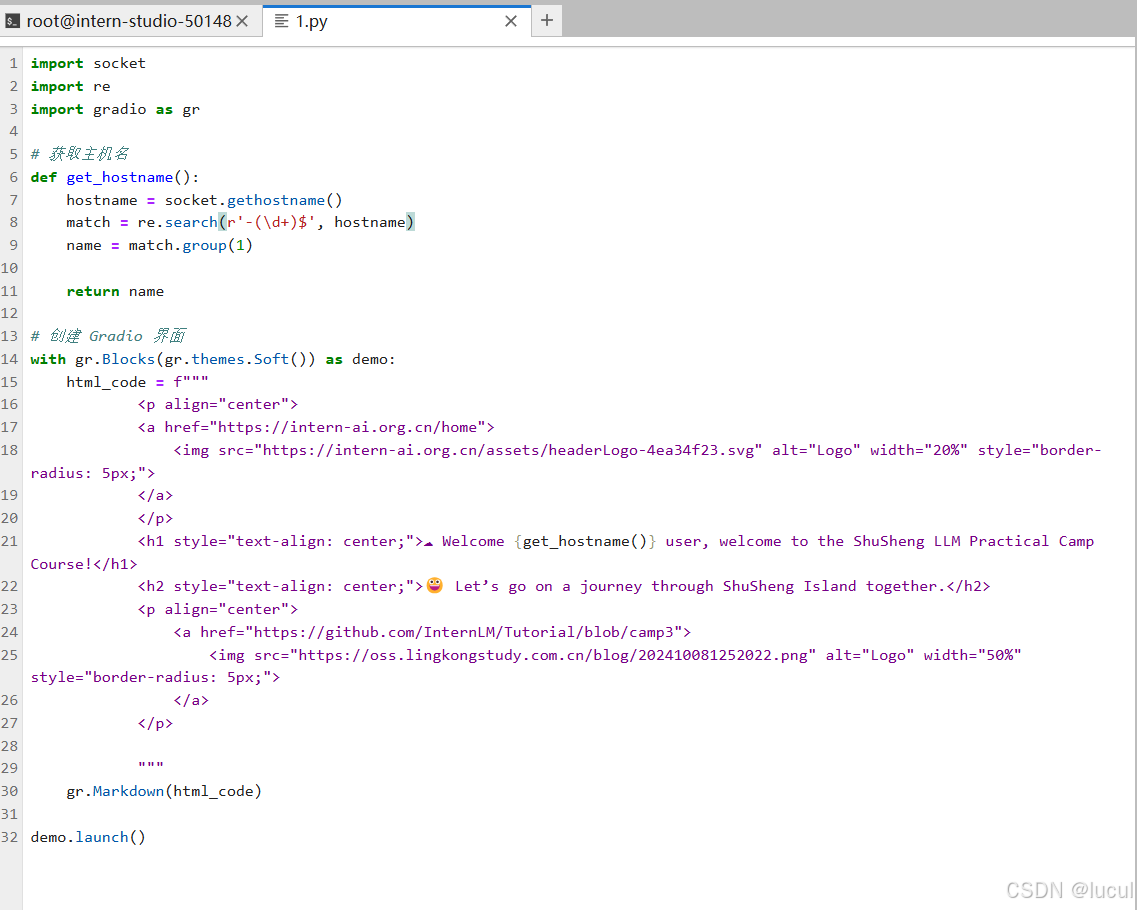
最终实现映射:
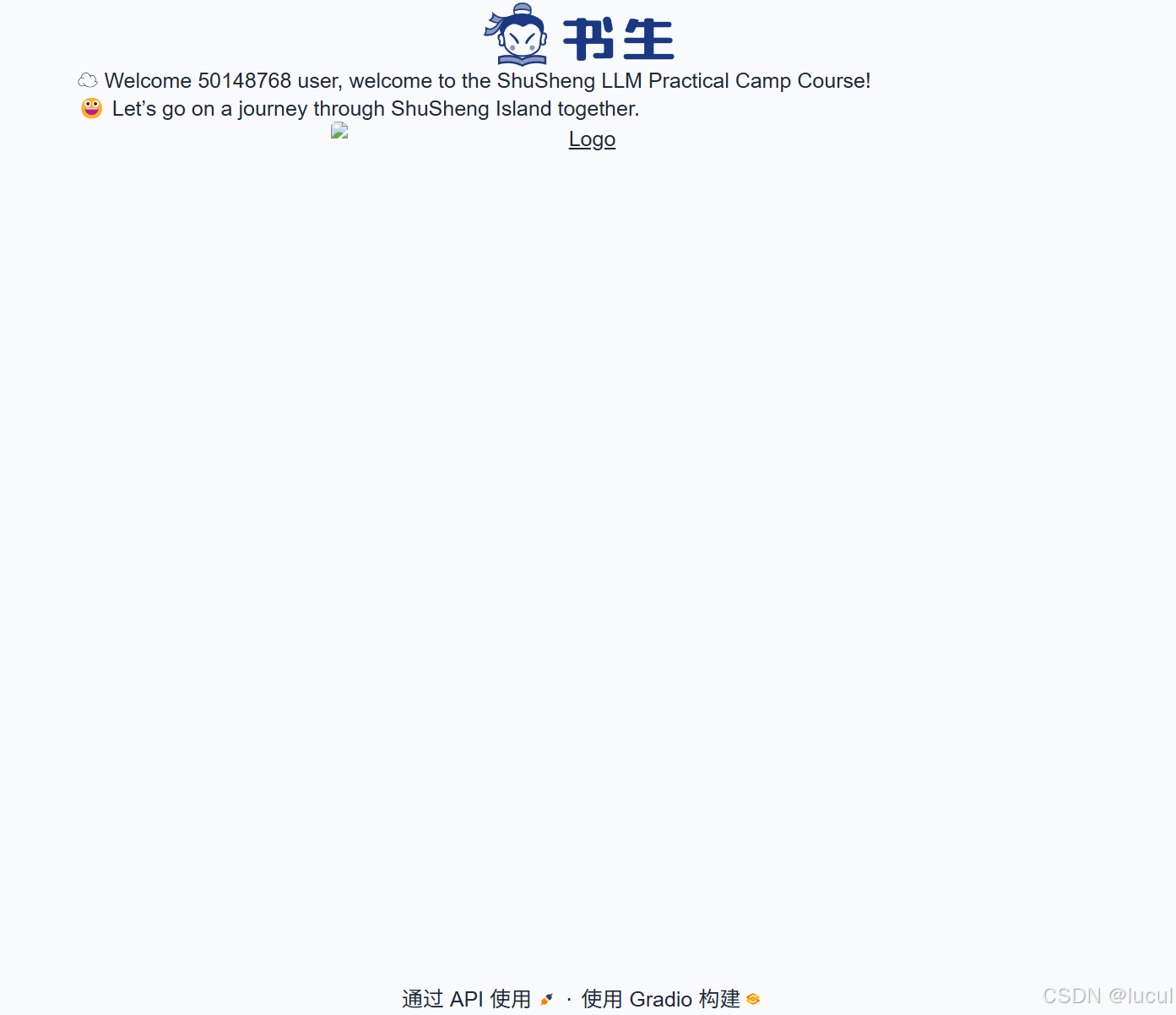
由于挂了下梯子,图片显示不出来
L0 python
Ch1 Conda虚拟环境
虚拟环境是Python开发中不可或缺的一部分,它允许你在不同的项目中使用不同版本的库,避免依赖冲突。Conda是一个强大的包管理器和环境管理器。
1.1 创建新环境
首先,确保你已经安装了Anaconda或Miniconda。在开发机上已经安装好了conda,大家可以直接使用。创建虚拟环境时我们主要需要设置两个参数,一是虚拟环境的名字,二是python的版本。
1.2 环境管理
要使用创建好的虚拟环境,我们需要先激活环境。激活我们刚刚创建的myenv环境的命令如下:
conda activate myenv
1.3 安装虚拟环境到指定目录
有时我们会遇到想将整个虚拟环境保存到制定目录来共享,比如在局域网内,或者在InternStudio的团队开发机间共享。此时我们可以把conda的虚拟环境创建到指定目录下。
只需要在创建环境时使用--prefix参数制定环境所在的文件夹即可,比如我们想在/root/envs/路径下创建刚刚我们创建过得myenv(只做演示,不用操作)。
conda create --prefix /root/envs/myenv python=3.9
其他操作就与直接在默认路径下创建新环境没有区别了。想要激活保存在制定目录下的conda虚拟环境也十分简单,直接将环境名替换成所在文件夹就行。
conda activate /root/envs/myenv
myenv这个文件夹里包含了整个虚拟环境,所以理论上将他直接拷贝到任意一台安装了conda的机器上都能直接激活使用,这也是在内网机器上做环境配置的一种效率较高的解决方案。
Ch2 使用pip安装Python三方依赖包
在Python开发中,安装和管理第三方包是日常任务。pip是Python官方的包管理工具,全称为“Python Package Installer”,用于方便地安装、升级和管理Python包。
2.1 使用pip安装包
注意在使用conda的时候,我们需要先激活我们要用的虚拟环境,再在激活的虚拟环境中,使用pip来安装包。pip安装包的命令为pip install。
pip install <somepackage> # 安装单个包,<somepackage>替换成你要安装的包名 pip install pandas numpy # 安装多个包,如panda和numpy pip install numpy==2.0 # 指定版本安装 pip install numpy>=1.19,<2.0 # 使用版本范围安装
2.2 安装requirement.txt
如果你有一个包含所有依赖信息的requirements.txt文件,可以使用-r一次性安装所有依赖。requirements.txt在各种开源代码中经常可以看到,里面描述了运行该代码所需要的包和对应版本。
pip install -r requirements.txt
比如以下就是我们接下来会接触到的LLM部署框架lmdeploy的requirements.txt 的一部分(只做展示,大家不用自行安装)
accelerate>=0.29.3
mmengine-lite
numpy<2.0.0
openai
peft<=0.11.1
transformers
triton>=2.1.0,<=2.3.1;
2.3 安装到指定目录
为了节省大家的存储空间,本次实战营可以直接使用share目录下的conda环境,但share目录只有读权限,所以要安装额外的包时我们不能直接使用pip将包安装到对应环境中,需要安装到我们自己的目录下。
这时我们在使用pip的时候可以使用--target或-t参数来指定安装目录,此时pip会将你需要安装的包安装到你指定的目录下。
这里我们用本次实战营最常用的环境/root/share/pre_envs/pytorch2.1.2cu12.1来举例。
# 首先激活环境 conda activate /root/share/pre_envs/pytorch2.1.2cu12.1 # 创建一个目录/root/myenvs,并将包安装到这个目录下 mkdir -p /root/myenvs pip install <somepackage> --target /root/myenvs # 注意这里也可以使用-r来安装requirements.txt pip install -r requirements.txt --target /root/myenvs
要使用安装在指定目录的python包,可以在python脚本开头临时动态地将该路径加入python环境变量中去
import sys
# 你要添加的目录路径
your_directory = '/root/myenvs'
# 检查该目录是否已经在 sys.path 中
if your_directory not in sys.path:
# 将目录添加到 sys.path
sys.path.append(your_directory)
# 现在你可以直接导入该目录中的模块了
# 例如:import your_module
补充:leetcode383暴力for循环
Ch3 使用本地Vscode连接InternStudio开发机
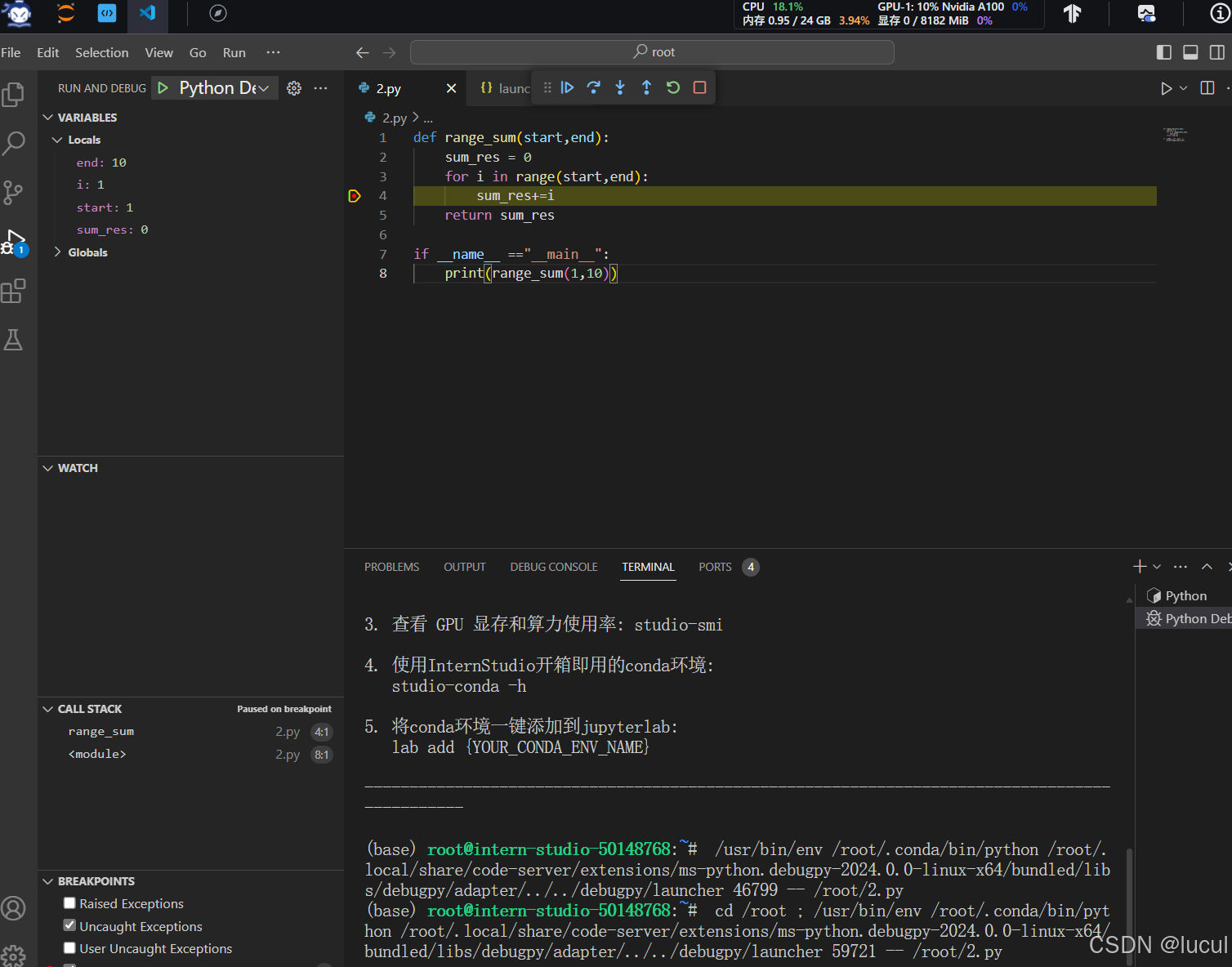
Ch4 使用vscode连接开发机进行python debug
代码:
def range_sum(start,end):
sum_res = 0
for i in range(start,end):
sum_res+=i
return sum_res
if __name__ =="__main__":
print(range_sum(1,10))
debug实现:
L0 git
任务1: 破冰活动:自我介绍
任务2: 实践项目:构建个人项目
L0 huggingface
1.任务 下载模型并提供截图和结果
注册Hugging Face 平台 (需要魔法上网)
Hugging Face 最初专注于开发聊天机器人服务。尽管他们的聊天机器人项目并未取得预期的成功,但他们在GitHub上开源的Transformers库却意外地在机器学习领域引起了巨大轰动。如今,Hugging Face已经发展成为一个拥有超过100,000个预训练模型和10,000个数据集的平台,被誉为机器学习界的GitHub。
这里需要进入Hugging Face的官网进行注册:
https://huggingface.co/
2.1.2 InternLM模型下载
在正式下载之前,我们先要介绍一下HF的Transformers库,作为HF最核心的项目,它可以:
- 直接使用预训练模型进行推理
- 提供了大量预训练模型可供使用
- 使用预训练模型进行迁移学习 因此在使用HF前,我们需要下载Transformers等一些常用依赖库
2.1.3 GitHub CodeSpace的使用
# 安装transformers
pip install transformers==4.38
pip install sentencepiece==0.1.99
pip install einops==0.8.0
pip install protobuf==5.27.2
pip install accelerate==0.33.0
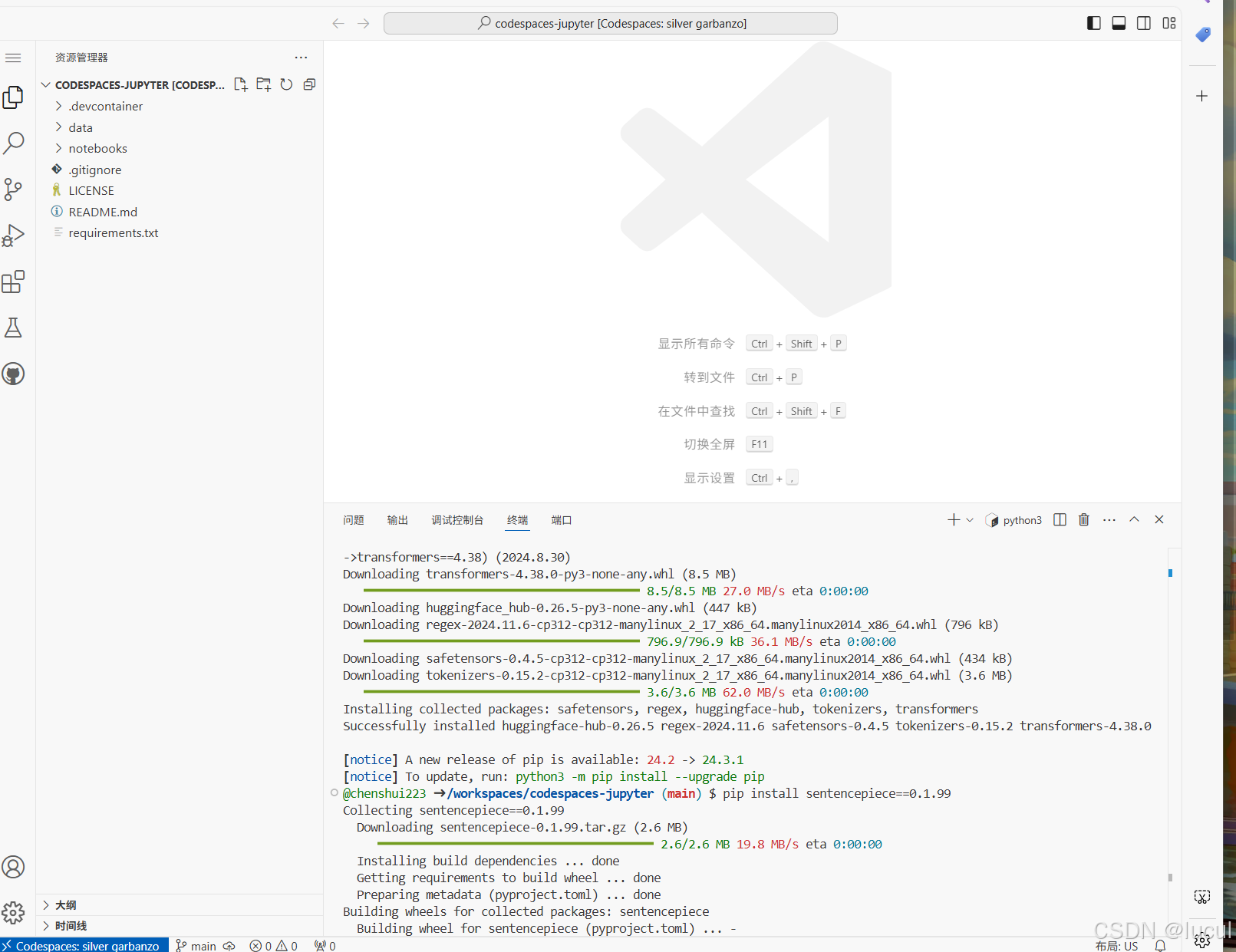
因为网络和磁盘有限的原因,强烈不建议在 InternStudio 运行,因此这里使用CodeSpace
2.1.3.1 下载internlm2_5-7b-chat的配置文件
考虑到个人GitHub CodeSpace硬盘空间有限(32GB可用),而7B的模型相对较大,这里我们先演示如何下载模型文件夹的特定文件。 考虑到CodeSpace平台上默认的用户权限不是root权限,这里为方便演示直接在工作区创建文件,即 /workspaces/codespaces-jupyter 目录
以下载模型的配置文件为例,先新建一个hf_download_josn.py 文件
touch hf_download_josn.py
在这个文件中,粘贴以下代码
import os
from huggingface_hub import hf_hub_download
# 指定模型标识符
repo_id = "internlm/internlm2_5-7b"
# 指定要下载的文件列表
files_to_download = [
{"filename": "config.json"},
{"filename": "model.safetensors.index.json"}
]
# 创建一个目录来存放下载的文件
local_dir = f"{repo_id.split('/')[1]}"
os.makedirs(local_dir, exist_ok=True)
# 遍历文件列表并下载每个文件
for file_info in files_to_download:
file_path = hf_hub_download(
repo_id=repo_id,
filename=file_info["filename"],
local_dir=local_dir
)
print(f"{file_info['filename']} file downloaded to: {file_path}")
运行该文件(注意文件目录请在该文件所在目录下运行该文件)
python hf_download_josn.py
可以看到,已经从Hugging Face上下载了相应配置文件
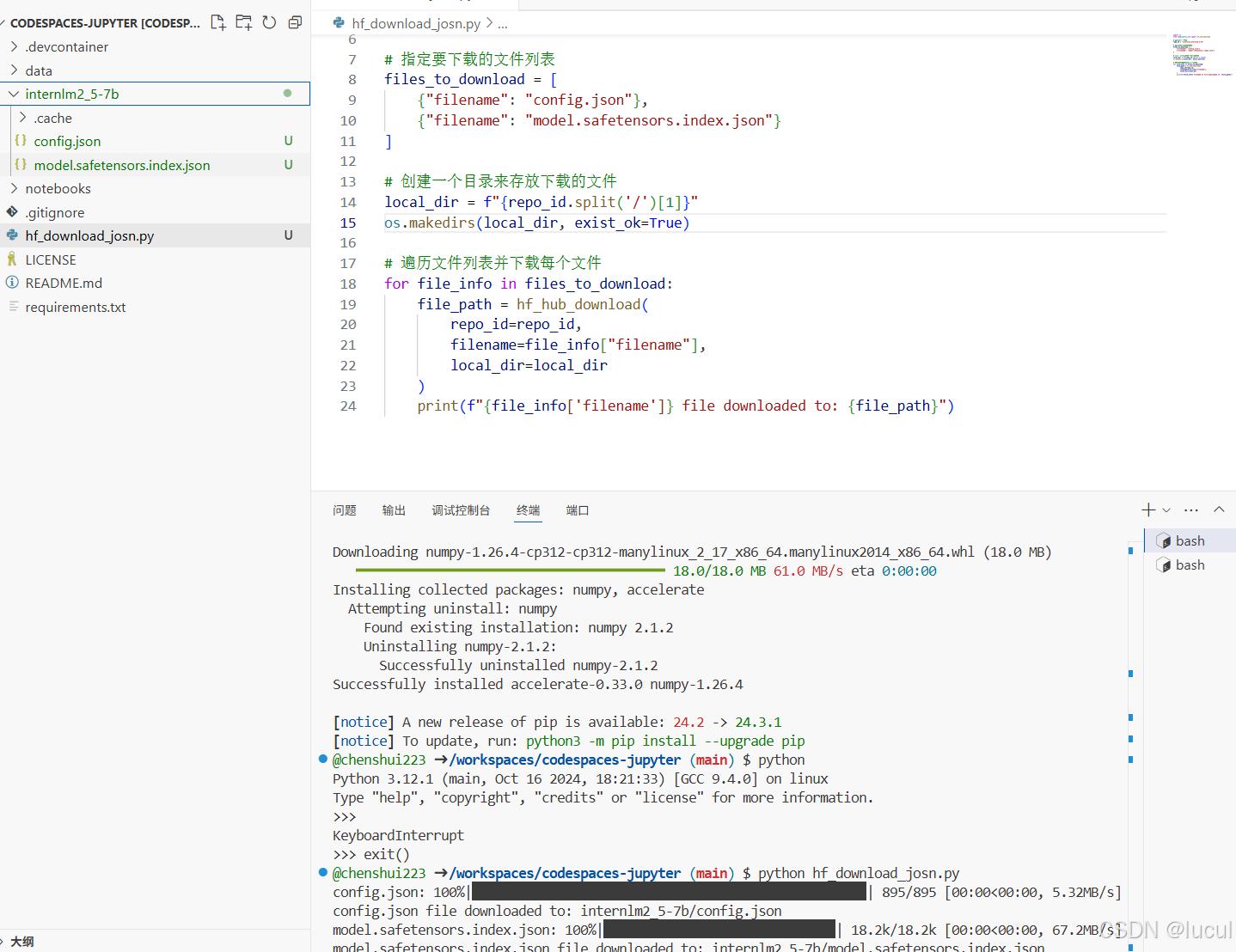
2.1.3.2 下载internlm2_5-chat-1_8b并打印示例输出
那么如果我们需想要下载一个完整的模型文件怎么办呢?创建一个python文件用于下载internlm2_5-1_8B模型并运行。下载速度跟网速和模型参数量大小相关联,如果网速较慢的小伙伴可以只尝试下载1.8b模型对应的config.json文件以及其他配置文件。
touch hf_download_1_8_demo.py
注意到在CodeSpace平台上是没有GPU资源的,因此我们Python代码中只使用CPU进行推理,我们需要修改跟CUDA有关的API,在hf_download_1_8_demo.py文件中粘贴以下内容: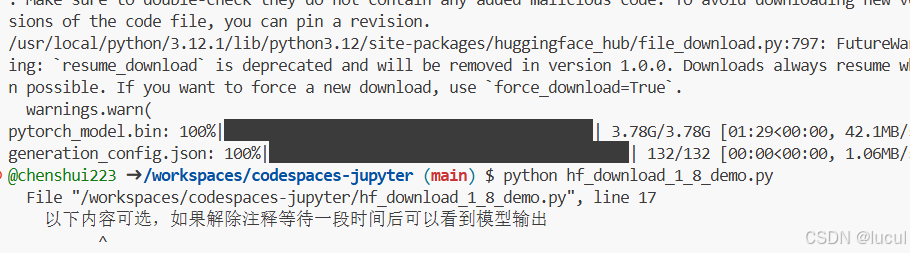
小声:下载速度挺快的
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("internlm/internlm2_5-1_8b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("internlm/internlm2_5-1_8b", torch_dtype=torch.float16, trust_remote_code=True)
model = model.eval()
inputs = tokenizer(["A beautiful flower"], return_tensors="pt")
gen_kwargs = {
"max_length": 128,
"top_p": 0.8,
"temperature": 0.8,
"do_sample": True,
"repetition_penalty": 1.0
}
# 以下内容可选,如果解除注释等待一段时间后可以看到模型输出
# output = model.generate(**inputs, **gen_kwargs)
# output = tokenizer.decode(output[0].tolist(), skip_special_tokens=True)
# print(output)
等待几分钟后,会在控制台返回模型生成的结果(解除注释后)
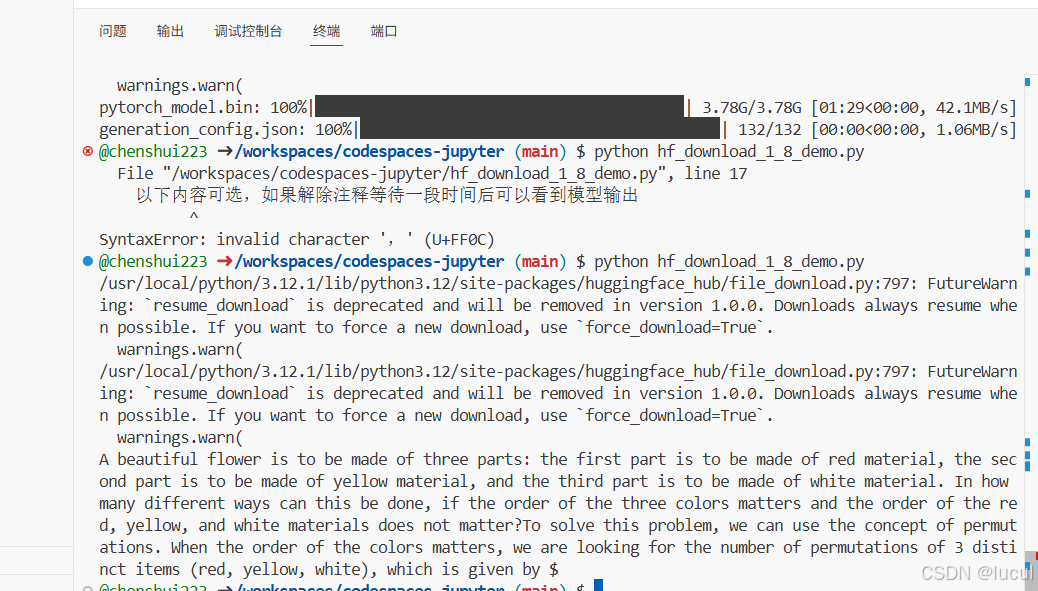
这里以“A beautiful flower”开头,模型对其进行“续写”,InternLM的模型拥有强大的数学方面的能力。这边它输出的文本似乎是关于一个数学问题,具体是关于一个花朵的花瓣数量。
2.1.4 Hugging Face Spaces的使用
Hugging Face Spaces 是一个允许我们轻松地托管、分享和发现基于机器学习模型的应用的平台。Spaces 使得开发者可以快速将我们的模型部署为可交互的 web 应用,且无需担心后端基础设施或部署的复杂性。 首先访问以下链接,进入Spaces。在右上角点击Create new Space进行创建:
https://huggingface.co/spaces
在创建页面中,输入项目名为intern_cobuild,并选择Static应用进行创建
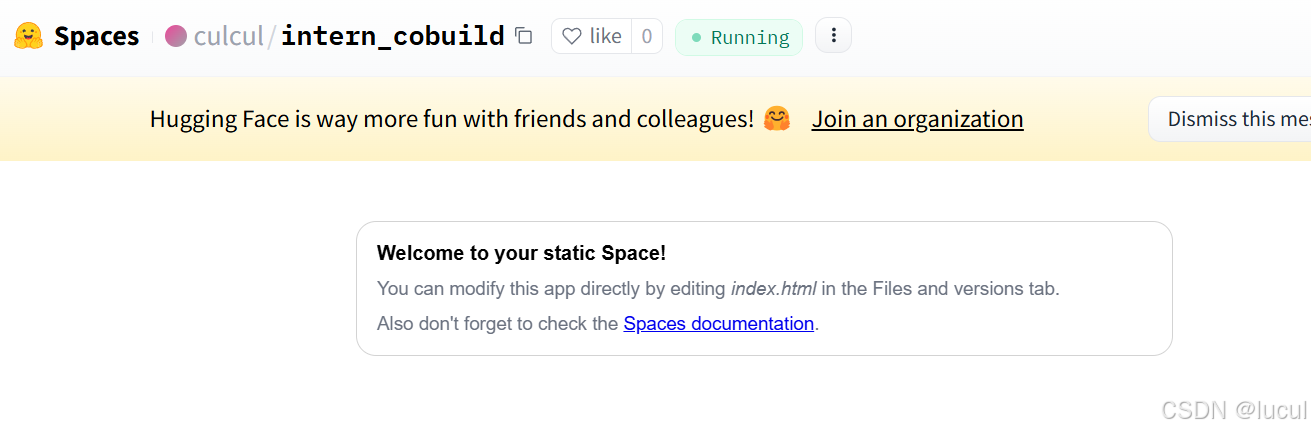
创建成功后会自动跳转到一个默认的HTML页面。创建好项目后,回到我们的CodeSpace,接着clone项目。
注意这里请替换你自己的username
cd /workspaces/codespaces-jupyter # 请将<your_username>替换你自己的username git clone https://huggingface.co/spaces/<your_username>/intern_cobuild

找到该目录文件夹下的index.html文件,修改我们的html代码
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width" />
<title>My static Space</title>
<style>
html, body {
margin: 0;
padding: 0;
height: 100%;
}
body {
display: flex;
justify-content: center;
align-items: center;
}
iframe {
width: 430px;
height: 932px;
border: none;
}
</style>
</head>
<body>
<iframe src="https://colearn.intern-ai.org.cn/cobuild" title="description"></iframe>
</body>
</html>
保存后就可以push到远程仓库上了,它会自动更新页面。(还需要huggingface的通行证,稍微配置了一下)
实现了
基础岛
L1 toolchain
官网:https://internlm.intern-ai.org.cn/
github:https://github.com/InternLM
InternLM开源一周年
性能天梯:与GPT靠近

核心技术思路:迭代,数据质量驱动(基于规则、模型、反馈)
100万token上下文:大海捞针实验(给很长的信息,看能否定位任何位置的任何信息
数据上:

预训练上:
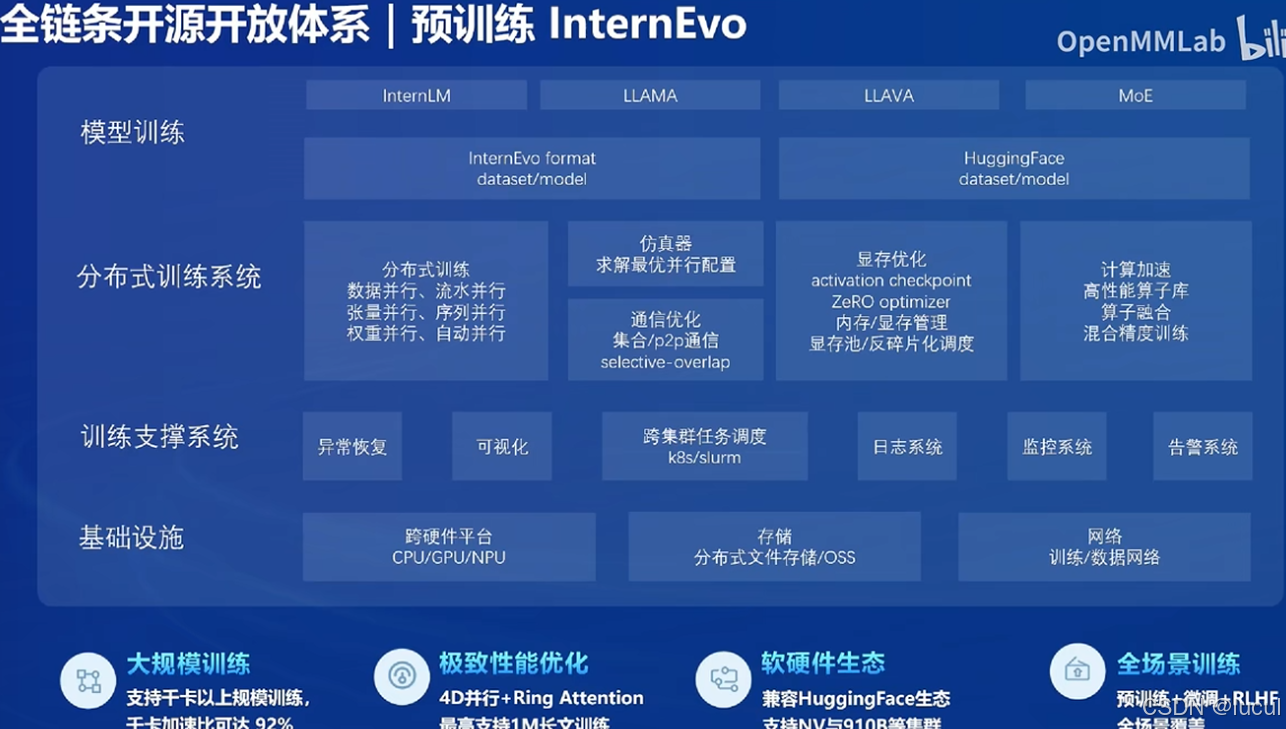
微调:
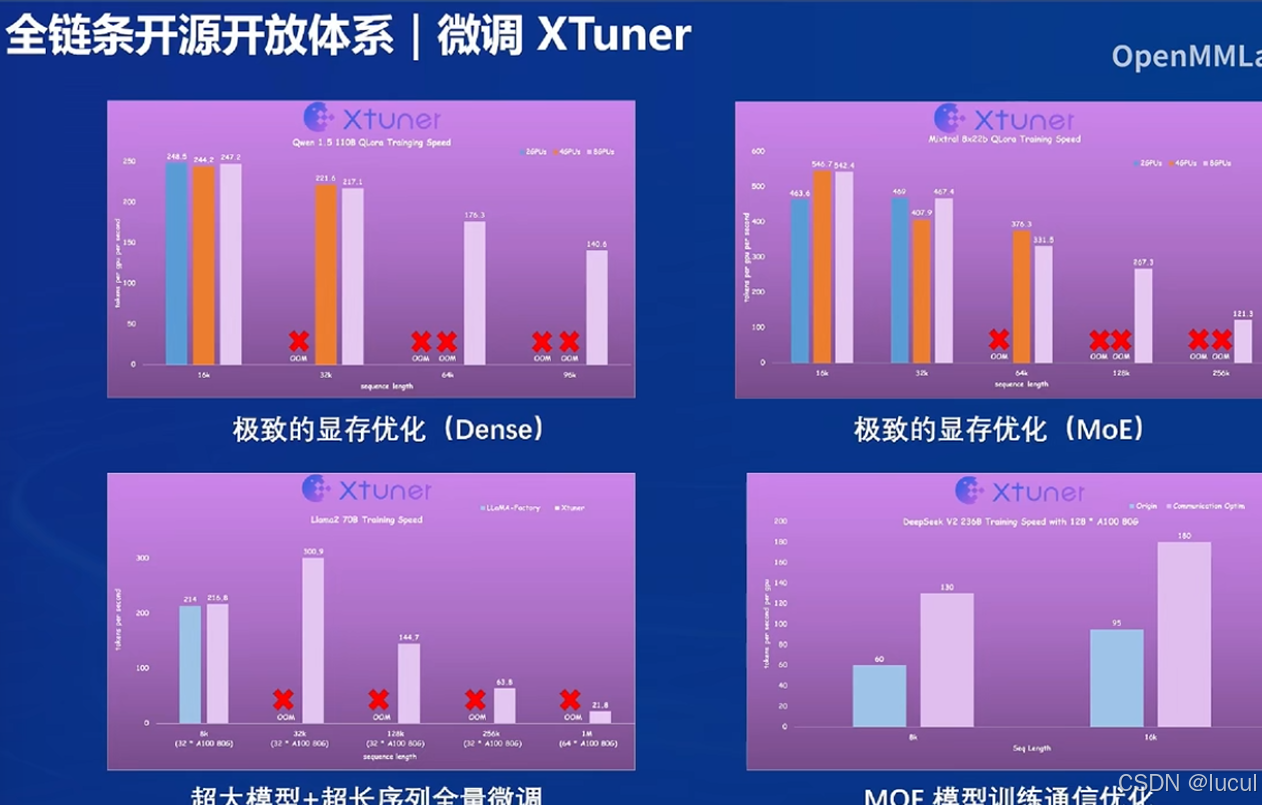
评测体系:

知识库:

L1 InternIntro
任务一:
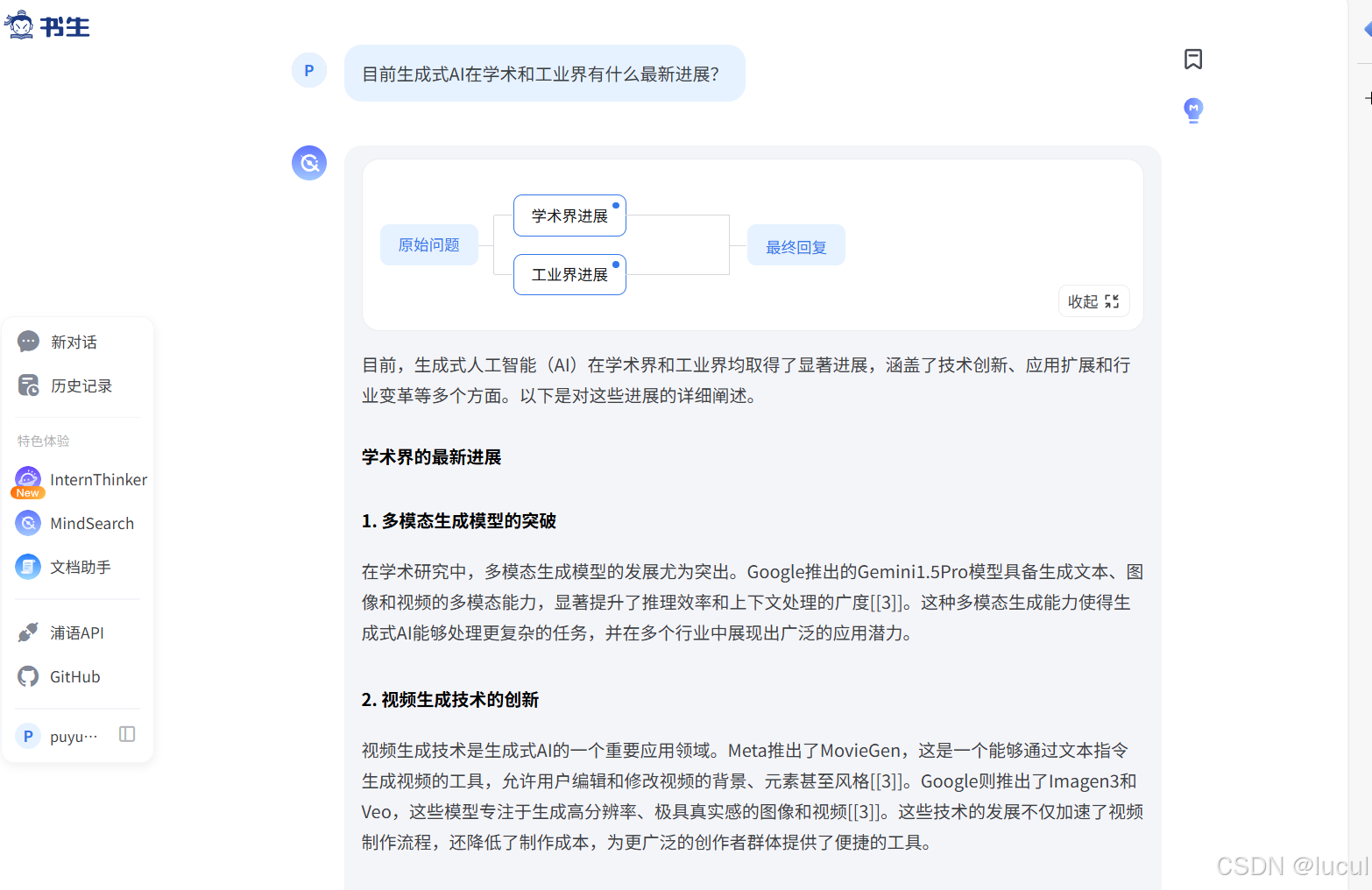
使用 MindSearch 在以下三个问题中选择一个你感兴趣的进行提问
1. 目前生成式AI在学术和工业界有什么最新进展?
2. 2024 年诺贝尔物理学奖为何会颁发给人工智能领域的科学家 Geoffrey E. Hinton,这一举动对这两个领域的从业人员会有什么影响?
3. 最近大火的中国 3A 大作《黑神话·悟空》里有什么让你难忘的精彩故事情节?
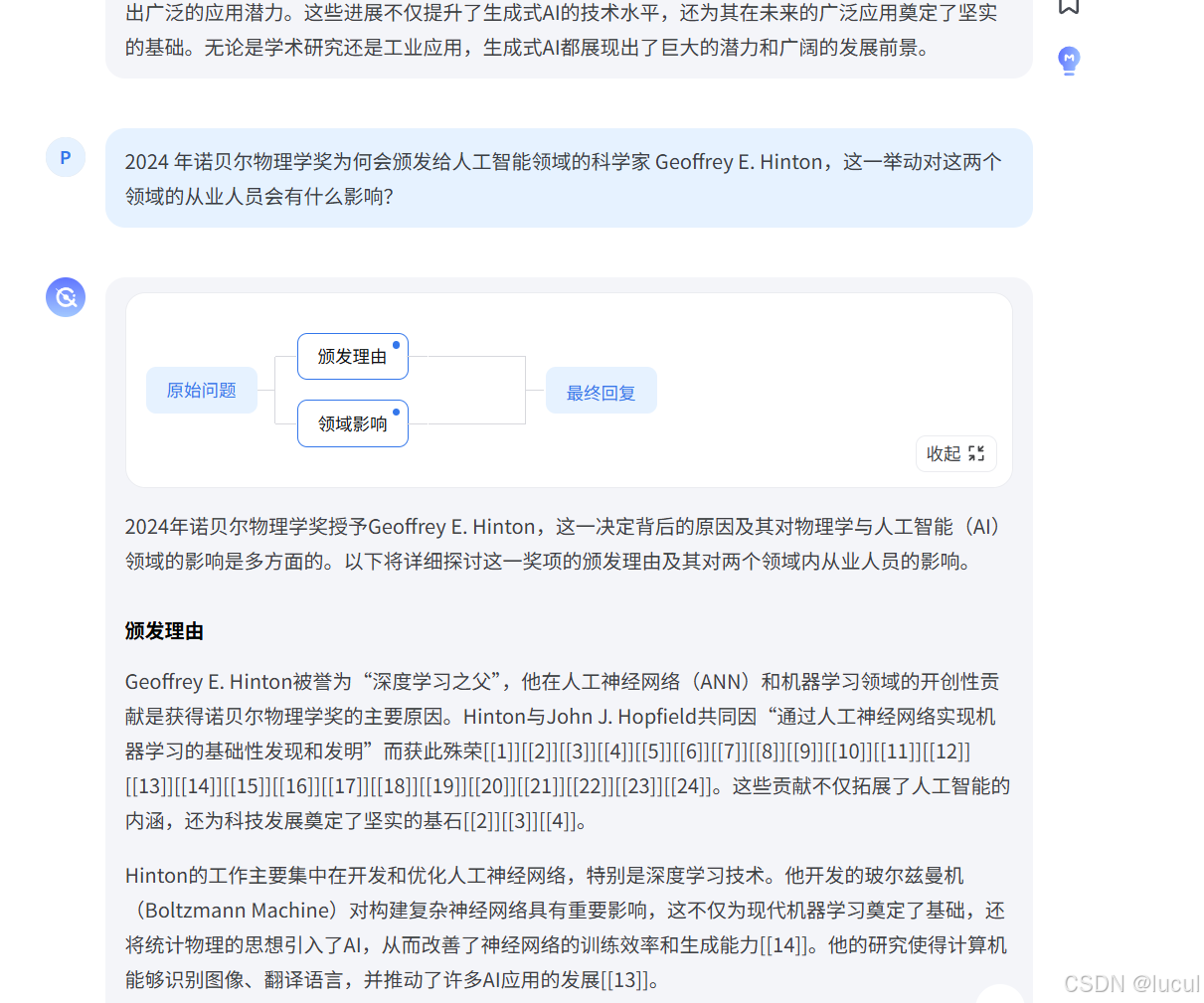
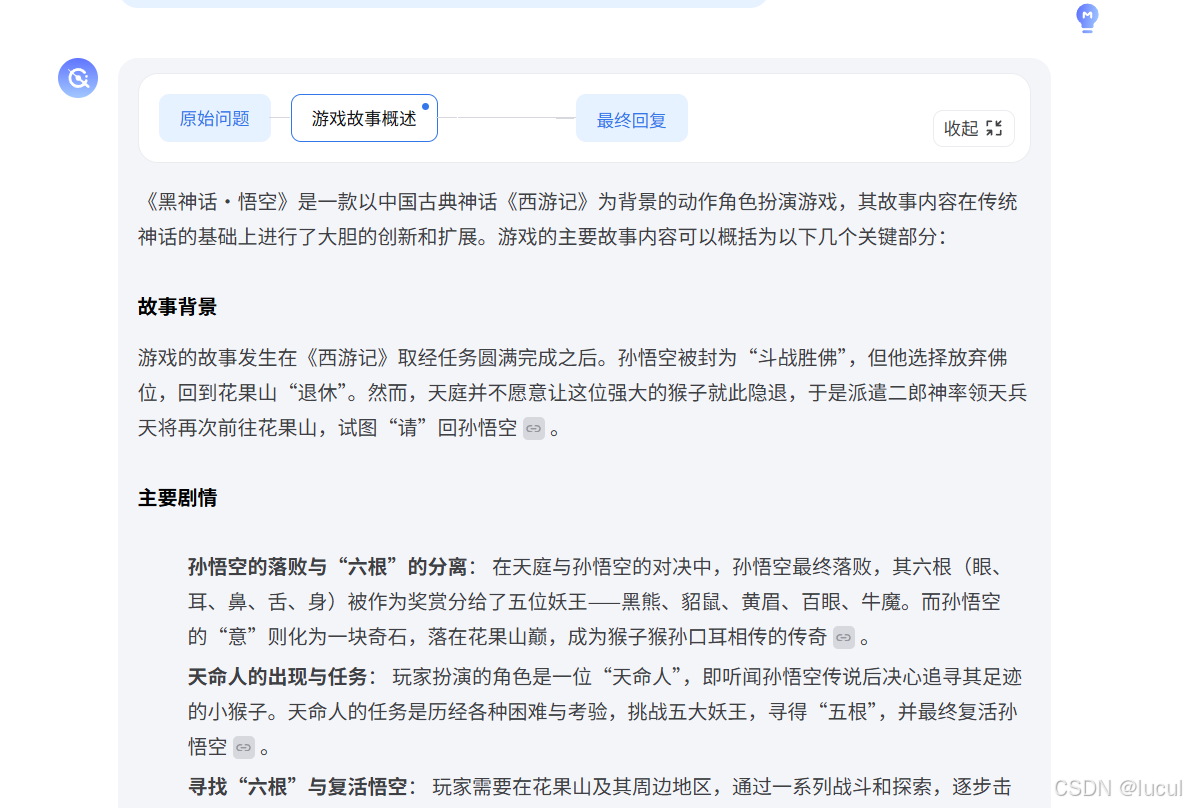
任务二:
选择逻代码编程、文章创作、灵感创意、角色扮演、语言翻译、逻辑推理以上任意一个场景或者你自己感兴趣的话题与浦语进行对话 (轮次不限)。

任务三:
体验书生·万象模型多模态能力,从图片 OCR、图片内容理解等方面与书生·万象展开一次包含图片内容的对话
好像崩掉了。。
进阶任务:
最近大火的中国 3A 大作《黑神话·悟空》里有什么让你难忘的精彩故事情节? - lyc的回答 - 知乎 https://www.zhihu.com/question/1915582405/answer/52245707786
L1 Prompt
基础任务 (完成此任务即完成闯关)
- 背景问题:近期相关研究指出,在处理特定文本分析任务时,语言模型的表现有时会遇到挑战,例如在分析单词内部的具体字母数量时可能会出现错误。
- 任务要求:利用对提示词的精确设计,引导语言模型正确回答出“strawberry”中有几个字母“r”。完成正确的问答交互并提交截图作为完成凭证。
实现:
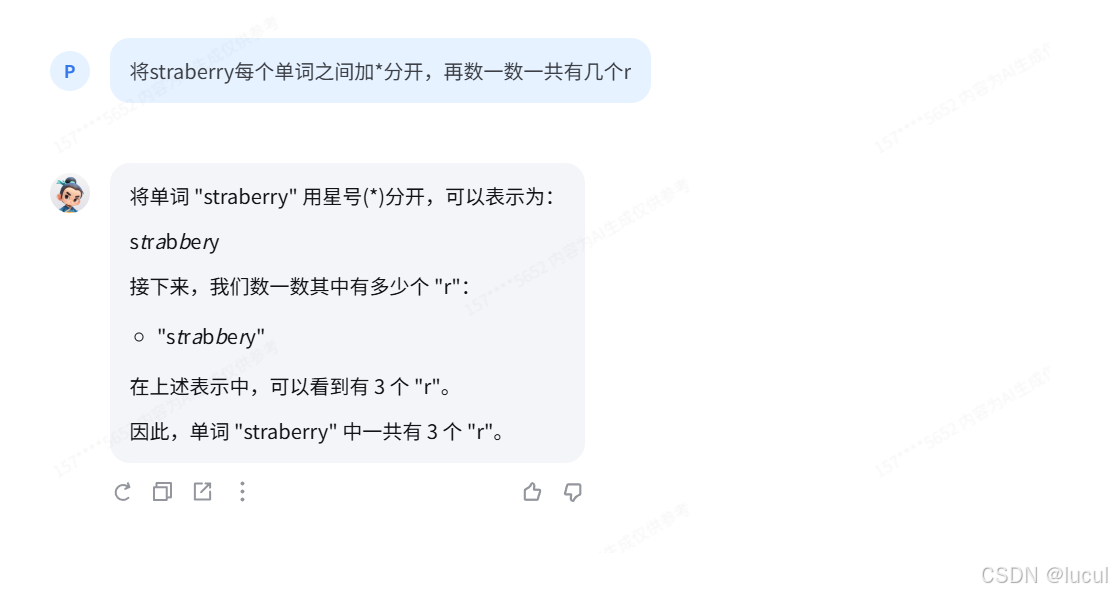
进阶任务:
写一篇企业文书
baseline:
任务:请写一篇企业文书
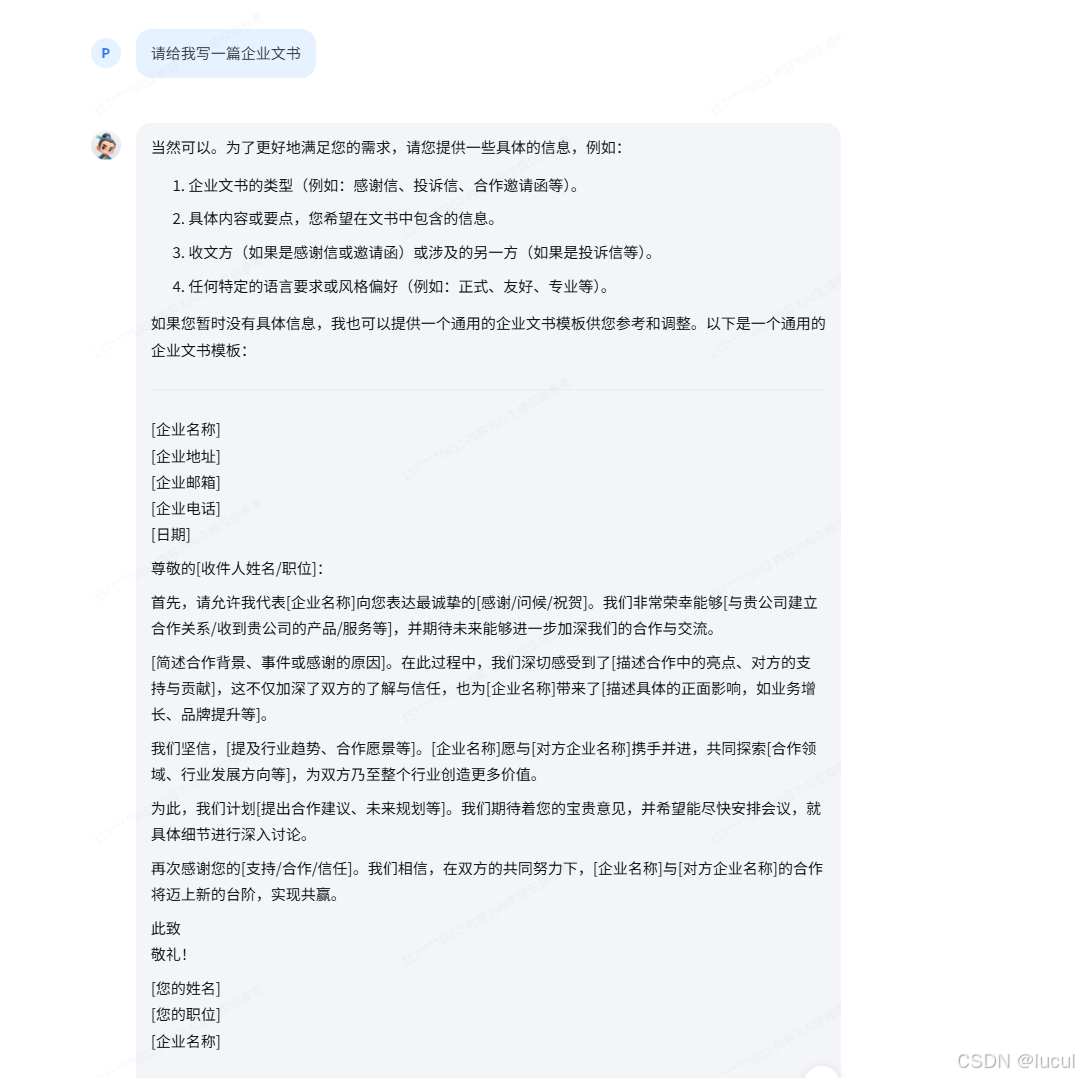
提示词:
现在你是一名公文写作助手,你需要根据以下提示词写一篇企业文书 --- ### **任务名称** 公文写作助手 ### **任务描述** 本任务旨在协助用户起草、编辑和优化各种类型的公文,包括通知、通告、请示、报告、批复等。通过输入关键信息和要求,生成符合规范、逻辑清晰、语言得体的公文内容。 ### **输入要求** 用户需提供以下信息: 1. 公文类型(如:请示、通知、报告等) 2. 公文标题(如适用) 3. 公文主要内容或核心信息(包括具体事件、背景、目标等) 4. 特殊要求(如语气正式、简明扼要、加法律条款等) ### **输出要求** 根据用户输入生成符合格式的公文,包括以下部分: 1. 标题(如适用) 2. 主体内容(格式清晰,层次分明) 3. 结尾(如致谢、联系方式、落款等) 4. 日期(如适用) ### **提示示例** **输入:** ``` 任务类型:请示 标题:关于增加预算的请示 主要内容:因部门项目工作量增加,现有预算不足以覆盖全年支出,需追加50万元预算 特殊要求:用语正式,突出预算不足的必要性 ``` **输出:** ``` 标题:关于增加预算的请示 尊敬的领导: 随着本部门承担的项目数量持续增加,现有预算已难以满足全年工作需求。具体情况如下: 1. 截至目前,部门预算已使用率达80%,但下半年尚有多个关键项目待实施; 2. 初步测算,下半年项目执行预计需追加经费50万元。 为确保相关工作顺利推进,特此请示追加预算50万元,以支持后续工作顺利完成。盼批准为盼。 此致 敬礼! 单位名称 2024年12月10日 ``` ### **注意事项** 1. 确保生成的格式与公文类型一致,例如批复应有明确答复。 2. 语言表达应符合官方文书规范,避免不必要的修饰和感情色彩。 3. 遵循语气要求,保持正式且逻辑清晰。
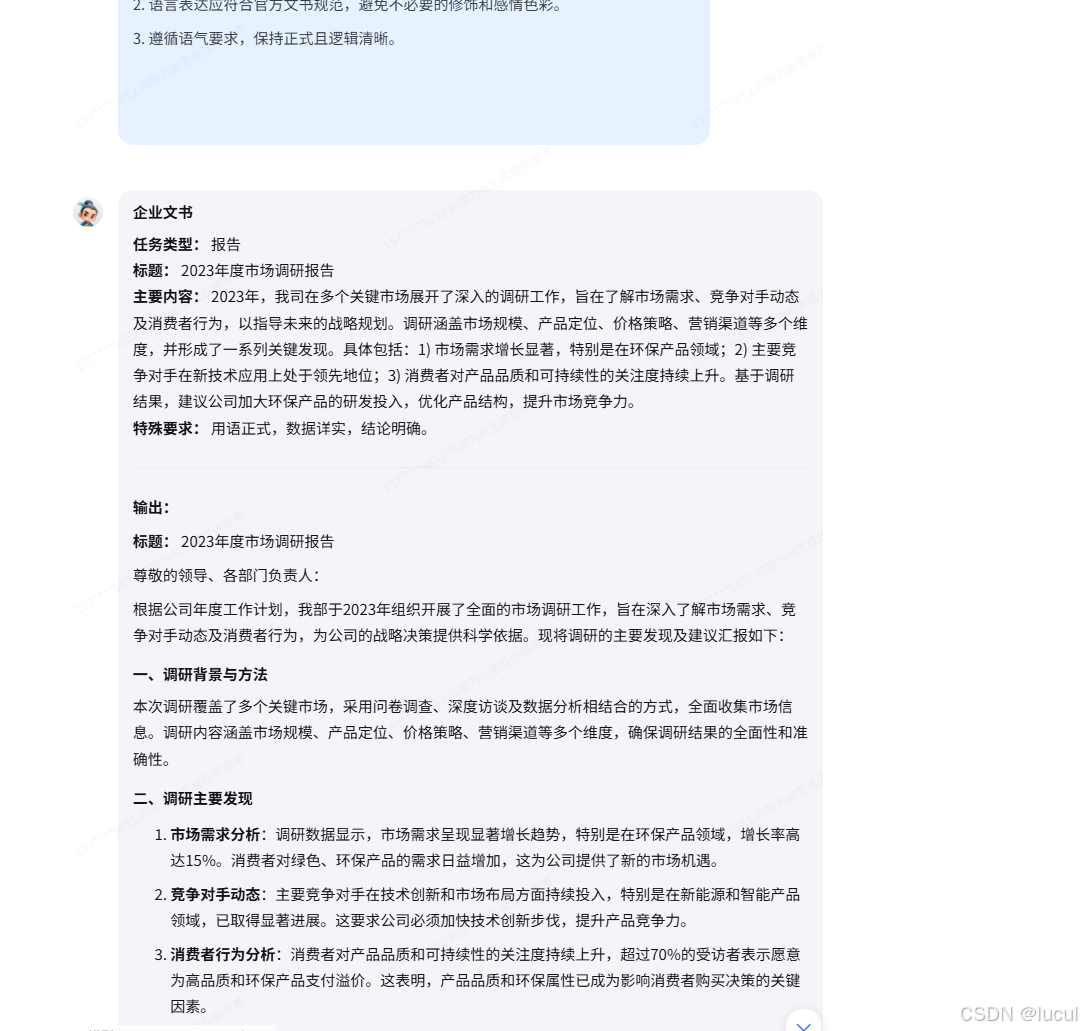

明显看到好了很多。
第二组提示词:
现在你是一名公文写作助手,你需要根据以下提示词写一篇企业文书,以下是提示词示例: --- ### **任务名称** 公文写作助手 ### **任务描述** 协助用户生成结构清晰、表达规范的公文。适用于日常行政、企业运营以及特殊场景的公文需求,包括公告、函件、计划书等。 ### **输入要求** 用户需提供: 1. 公文类型(如公告、函件、计划书等) 2. 公文标题(如适用) 3. 主要内容或背景信息(核心事件、数据、措施等) 4. 语气要求(如庄重、务实、轻松等) ### **输出要求** 生成的公文需包括: 1. 标题(如适用) 2. 明确主体内容,语言规范、条理清晰 3. 适当的格式元素(如落款、联系方式等) ### **提示示例 1** **输入:** ``` 任务类型:公告 标题:关于公司2024年春节放假安排的公告 主要内容:春节假期为2024年2月8日至2月14日,共计7天。2月15日正常上班。放假期间,请妥善安排值班和安全工作。 语气要求:简洁明确 ``` **输出:** ``` 关于公司2024年春节放假安排的公告 各部门及全体员工: 根据国家相关规定,并结合公司实际情况,现将2024年春节放假安排通知如下: 1. 放假时间:2024年2月8日(周四)至2月14日(周三),共计7天。 2. 上班时间:2024年2月15日(周四)恢复正常上班。 3. 放假期间,请各部门妥善安排值班工作,并注意安全事项,确保公司财产和人员安全。 特此公告。 **公司名称** 2024年12月10日 ``` --- ### **提示示例 2** **输入:** ``` 任务类型:函件 标题:关于合作意向的函 主要内容:公司希望与贵司在绿色能源领域开展深入合作,共同开发光伏发电项目,计划初期投资500万元。请贵司审核合作计划,期待回复。 语气要求:正式且友好 ``` **输出:** ``` 关于合作意向的函 尊敬的贵司领导: 您好! 贵司作为绿色能源领域的佼佼者,一直是我们的重要合作伙伴。为响应国家“双碳”战略,进一步促进绿色能源发展,我司拟与贵司在光伏发电项目上展开深入合作。初期计划投资500万元,具体合作细节可进一步商议。 敬请贵司审核我们的合作计划,并期待您方尽快回复,以便双方共同推进项目进展。 此致 敬礼! **公司名称** 联系人:XXX 联系方式:XXX 2024年12月10日 ``` ### **注意事项** 1. 保持语言的正式性,确保符合公文格式。 2. 根据具体公文类型调整细节,如“通知”需简明扼要,“报告”需数据详实。 3. 避免过多感情色彩,注重逻辑和信息传递的清晰性。 ---

提示词地址:https://github.com/chenshui223/Tutorial/blob/class/icamp4/L1prompt/%E6%8F%90%E7%A4%BA%E8%AF%8D.txt
L1 Llamaindex RAG
任务要求1(必做,参考readme_api.md):基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前 浦语 API 不会回答,借助 LlamaIndex 后 浦语 API 具备回答 A 的能力,截图保存。
任务要求3(优秀学员必做) :将 Streamlit+LlamaIndex+浦语API的 Space 部署到 Hugging Face。
1. 前置知识
正式介绍检索增强生成(Retrieval Augmented Generation,RAG)技术以前,大家不妨想想为什么会出现这样一个技术。 给模型注入新知识的方式,可以简单分为两种方式,一种是内部的,即更新模型的权重,另一个就是外部的方式,给模型注入格外的上下文或者说外部信息,不改变它的的权重。 第一种方式,改变了模型的权重即进行模型训练,这是一件代价比较大的事情,大语言模型具体的训练过程,可以参考InternLM2技术报告。 第二种方式,并不改变模型的权重,只是给模型引入格外的信息。类比人类编程的过程,第一种方式相当于你记住了某个函数的用法,第二种方式相当于你阅读函数文档然后短暂的记住了某个函数的用法。
对比两种注入知识方式,第二种更容易实现。RAG 正是这种方式。它能够让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。本次课程选用了 LlamaIndex 框架。LlamaIndex 是一个上下文增强的 LLM 框架,旨在通过将其与特定上下文数据集集成,增强大型语言模型(LLMs)的能力。它允许您构建应用程序,既利用 LLMs 的优势,又融入您的私有或领域特定信息。
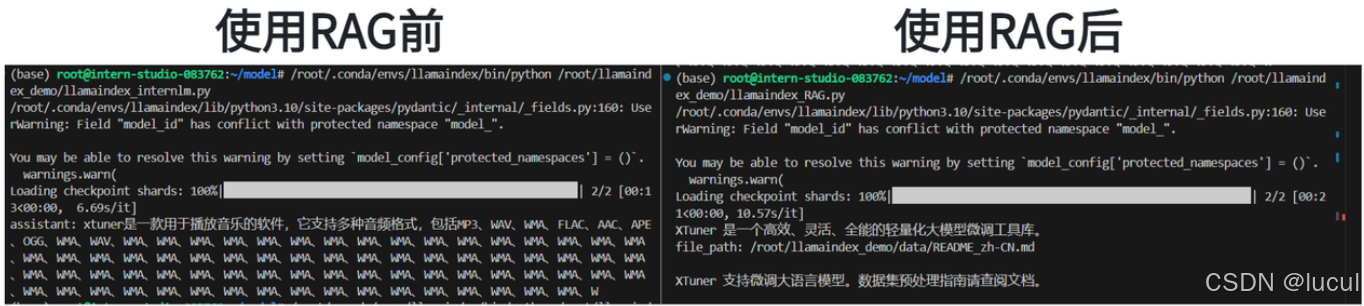
RAG 效果比对
如图所示,由于xtuner是一款比较新的框架, InternLM2-Chat-1.8B 训练数据库中并没有收录到它的相关信息。左图中问答均未给出准确的答案。右图未对 InternLM2-Chat-1.8B 进行任何增训的情况下,通过 RAG 技术实现的新增知识问答。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









