







简介
Sentinel 机制,用于当主节点出现故障时,自动完成故障发现、故障转移等操作,保证 redis 的高可用性。
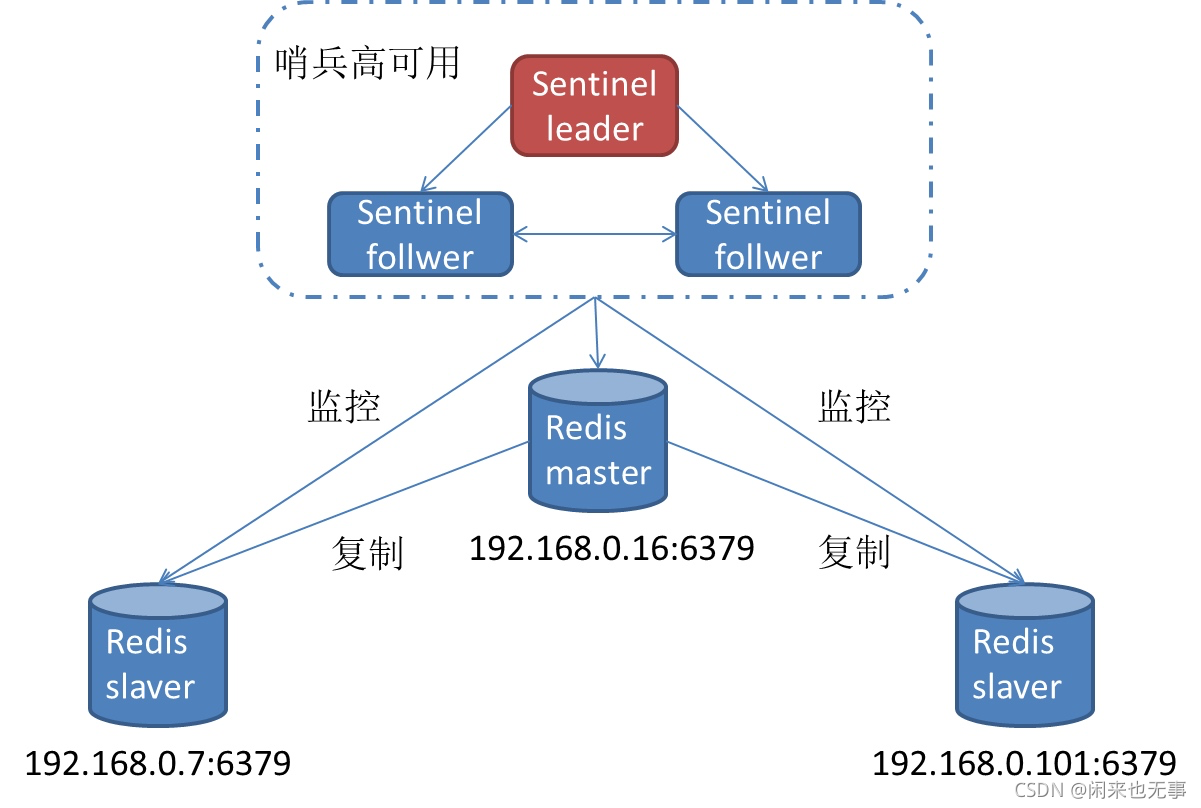
2、 监控与故障发现
Sentinel 通过 pub/sub 机制、以及定时任务实现:
- 监控主从拓扑信息:每隔10秒,Sentinel 向 master、slave发送 INFO 命令获取最新的拓扑结构
- Sentinel 节点信息交换:每隔 2 秒,Sentinel 向 redis 数据节点的 sentinel:hello 频道上,发送自身的信息,以及对主节点的判断信息。这样,Sentinel节点之间就可以交换信息
- 节点状态监控:每隔 1 秒,Sentinel 向 master、slave、其它 Sentinel 节点发送 PING 命令做心跳检测,来确认这些节点当前是否可达
3、下线判断
分为主观下线和客观下线
- sdown:Sentinel 每隔1秒对数据节点发送 ping 命令做心跳检测,超过 down-after-milliseconds 没有进行有效回复时,则认为其下线
- odown:根据 quorum 判定,大多数 Sentinel 认为 master 宕机。如 Sentinel 为3,大多数就是 3/2+1=2 个,如Sentinel 为 5,大多数就是 5/2+1=3 个
4、选举 Sentinel Leader
客观下线后,Sentinel 会选举出一个 Sentinel Leader 负责故障转移
- 首先,当某个 Sentinel 认为 Master 节点宕机后,向其他 Sentinel 发送 sentinel is-master-down-by-addr命令,要求自己成为Leader
- 其次,收到命令的 Sentinel 节点,如果没有同意过其他 Sentinel 成为 Leader 命令,将同意该请求,否则拒绝(注意:每个Sentinel节点只有1票);
- 最后,当某个 Sentinel 的票数超过 MAX(quorum, num(sentinels) / 2 + 1) 则成为 Sentinel Leader;如果该轮选举没有产生Leader 则进行下一次选举
5、故障转移
选举出的 Leader Sentinel 节点将负责故障转移,也就是进行 master / slave 节点的主从切换。从Slave中筛选新的 Master,需要考虑的因素依次有:
- 与 master 断开时长(超过了down-after-milliseconds的10倍,则不会被选举为master)
- slave priority
- offset
- run id
选举出新的 Master 后,由 Leader Sentinel首先将其设置为新的 Master(slaveof no one 命令),然后将其余的 Slave 设置为新 Master 的 Slave 节点(slave of 命令),最后继续监控原 Master 节点,当其恢复后从新 Master 复制数据即可
















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











