python项目之 爬虫爬取煎蛋jandan的妹子图-下
函数如下
- 读取全部单个txt组合成一个TXT文件,并把网址保存在all_imag_urls中
read_write_txt_to_main() - 读取单个TXT件的网址
get_url() - 每一个图片保存在本地
get_imags(all_imag_urls)
最终结果如下
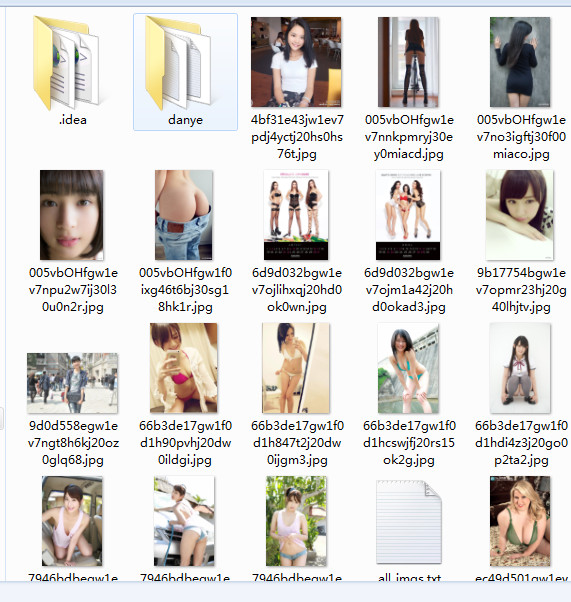
源码如下
import requests
import os
import time
import random
from bs4 import BeautifulSoup
import threading
ips = []
all_imag_urls = []
with open('ip2.txt', 'r') as f:
lines = f.readlines()
for line in lines:
ip_one = "http://" + line.strip()
ips.append(ip_one)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/42.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Referer': 'http://jandan.net/ooxx/',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
}
def read_write_txt_to_main():
for i in range(1520, 1881):
filename = str(i) + ".txt"
if os.path.exists(filename):
print(filename + "OK")
with open(filename, 'r') as f:
urls = f.readlines()
for url in urls:
all_imag_urls.append(url)
with open("all_imgs.txt", 'w+') as fw:
for url in all_imag_urls:
fw.write(url + "")
print("write file ok!!!!!")
def get_url():
with open("all_imgs.txt", 'r') as fw:
urls = fw.readlines()
for url in urls:
all_imag_urls.append(url.strip("\n"))
def get_imags(urls):
for url in urls:
url_a = url.strip("\n")
filename = url_a[28:]
if os.path.exists(filename):
pass
else:
host = url_a[7:21]
headers['Host'] = host
single_ip_addr = random.choice(ips)
proxies = {'http': single_ip_addr}
try:
res = requests.get(url, headers=headers, proxies=proxies, stream=True)
print(res.status_code)
if res.status_code == 200:
text = res.content
with open(filename, 'wb') as jpg:
jpg.write(text)
print(filename + " OK")
else:
print(filename + " not ok")
except:
print(filename + " not ok")
''' 读取全部单个txt组合成一个TXT文件,并把网址保存在all_imag_urls中。 '''
''' 读取单个TXT件的网址 '''
get_url()
''' 每一个图片保存在本地 '''
get_imags(all_imag_urls)
print("所有的妹子图保存完毕,请尽情享受!!")

























 9976
9976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









