







一、Java集合类
1. String、StringBuilder、StringBuffer
String为字符串常量,即在每次对 String 类型进行改变的时候,其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象;StringBuilder和StringBuffer均为字符串变量,是可以更改的。后两者的区别在于,StringBuilder是线程不安全的,而StringBuffer是线程安全的(StringBuffer中很多方法都带有synchronized关键字)。
- String:适用于对字符串进行少量修改操作的情况;
- StringBuilder:适用于单线程下对字符串进行大量修改操作的情况;
- StringBuffer:适用于多线程下对字符串进行大量修改操作的情况;
2. ArrayList、Vector、LinkedList
ArrayList,LinkedList,Vector这三个类都实现了java.util.List接口,但它们都有各自不同的特性。
- ArrayList:ArrayList是基于动态数组的数据结构,是有序集合,访问、更新元素的时间复杂度都是O(1),新增、删除元素的时间复杂度都是O(n);
- Vector:Vector使用方法和内部实现与ArrayList类似,区别在于Vector是线程同步的;ArrayList与Vector都有一个初始的容量大小,当存储进它们里面的元素的个数超过了容量时,Vector默认增长原来的一倍,ArrayList增加原来的0.5倍;
- LinkedList:LinkedList是基于链表的数据结构,是有序集合,访问、更新元素的时间复杂度都是O(n),新增、删除元素的时间复杂度都是O(1);
总结,ArrayList适用于单线程下需要对集合元素进行频繁访问、少量删增的情况,Vector适用于多线程下需要对集合元素进行频繁访问、少量删增的情况,LInkedList适用于单线程下需要对集合元素进行频繁删增、少量访问的情况。
3. HashMap、HashTable、TreeMap
HashMap、Hashtable、TreeMap都实现了Map接口,使用键值对的形式存储数据和操作数据。
- HashMap:HashMap是基于数组和链表的数据结构,非线程同步,支持key和value为null的情况,访问效率高;
- HashTable:HashTable类似于HashMap,主要区别在于HashTable是线程同步的,且不支持key和value为null的情况,访问开销大;
- TreeMap:TreeMap是基于红黑树的一种提供顺序访问的Map,使用方式类似于HashMap,get、put操作的时间复杂度是O(log(n));
4. HashSet、TreeSet、LinkedHashSet
HashSet实现了AbstractSet接口,TreeSet实现了AbstractSet接口和SortSet接口,LinkedHashSet是HashSet的子类。
- HashSet:HashSet是基于HashMap实现的,元素是无序的、不可重复的,添加、删除操作时间复杂度都是O(1);HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相等;可以存储null,但只能存储一个;
- TreeSet:TreeSet是基于TreeMap实现的,区别在于不能存储null,可以通过重写CompareTo方法来确定元素大小,从而进行升序排序;
- LinkedHashSet:LinkedHashSet是基于LinkedHashMap实现的,使用方式类似于HashSet,区别在于使用链表维护元素的次序,因此,在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet;
二、Java基础类
1. Java支持的8种基本数据类型
- 整型:byte(字节型)、short(短整型)、int(整型)、long(长整型)
- 浮点型:float(单精度浮点型)、double(双精度浮点型)
- 逻辑型:boolean(布尔型)
- 字符型:char(字符型)
| 数据类型 | 大小/字节 | 默认值 | 封装类 | 取值范围 |
|---|---|---|---|---|
| byte | 1(8位) | (byte)0 | java.lang.Byte | -27~27-1 |
| short | 2(16位) | (short)0 | java.lang.Short | -215~215-1 |
| int | 4(32位) | 0 | java.lang.Integer | -231~231-1 |
| long | 8(64位) | 0L | java.lang.Long | -263~263-1 |
| float | 4(32位) | 0.0F | java.lang.Float | 2-149~2128-1 |
| double | 8(64位) | 0.0D | java.lang.Double | 2-1074~21024-1 |
| boolean | 1或4 | false | java.lang.Boolean | true、false |
| char | 2(16位) | 空(’\u0000’) | java.lang.Character | \u0000 ~ \uffff |
2. new String()创建对象个数
首先,我们需要了解JVM的内存模型:

在Java中,String是字符串常量类型,String对象的引用会保存在字符串常量池(本质是一个HashSet<String>,这是一个纯运行时的结构,而且是惰性维护的)中,String对象本身还是会在堆中。
字符串常量池设计的目的就是为了减少字符串对象的创建分配,作为最基础的数据类型,大量频繁的创建字符串,极大程度地影响程序的性能。所以,JVM为了提高性能和减少内存开销,为字符串开辟了一个字符串常量池,类似于缓存区。在JDK1.6及之前版本,字符串常量池是放在Perm Gen区(也就是方法区)中。在JDK1.7版本,字符串常量池被移到了堆中了。
创建字符串常量对象时,首先,会检查字符串常量池是否存在该字符串的引用,如果存在,则返回引用实例;如果不存在,则先在堆中实例化该字符串对象,再把引用放入池中,并返回引用实例。
有了上面这些基础知识后,再来看看实际的问题:
- 代码1
public class MyTest3 {
public static void main(String[] args){
String s1 = new String("abc");
String s2 = "abc";
System.out.println(s1 == "abc");
System.out.println(s2 == "abc");
}
}
输出结果:
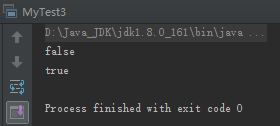
字符串“abc”最开始在字符串常量池中,并不存在,所以首先会创建一个“abc”字符串对象,然后会将引用传入到String的构造函数String(String s)中的s,之后会复制一个参数字符串s的副本对象,并将引用返回给s1,所以s1与“abc”的引用地址不同。对于s2,会直接将常量池中“abc”的引用赋予s2,故s2与“abc”的引用地址相同。
所以,总共创建了2个对象,一个是字符串常量池中的“abc”,另一个是“abc”的副本。
- 代码2:String s1 = “a” + “b” + “c” + “d”;
public static void main(String[] args){
String s1 = "a" + "b" + "c" + "d";
System.out.println(s1 == "abcd");
}
输出结果:

当一个字符串由多个字符串常量连接而成时,它自己也肯定是字符串常量,所以在编译期就会被JVM解析为一个字符串对象,即只创建了一个对象“abcd”,并把引用赋给s1。
- 代码3
public static void main(String[] args){
String s1 = "abc";
String s2 = "abcdef";
String s3 = s1 + "def";
System.out.println(s2 == s3);
}
输出结果:

JVM对于有字符串引用存在的字符串"+"连接中,由于引用的值在程序编译期是无法确定的,所以s1 + “def”无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给s3。 所以,这里会创建3个对象。
三、Java序列化
1. 什么是Java的序列化以及如何实现
- 定义
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。序列化即将Java对象转换为字节序列的过程。 - 实现
将需要被序列化的类实现Serializable接口(该接口没有需要实现的方法,只是为了标注该对象是可被序列化的),然后使用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着,使用ObjectOutputStream对象的writeObject(Object obj)方法就可以将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流。















 25万+
25万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









