






描述
数据虚拟化可以夸多个地理位置链接多个数据源,从而整合为一个本地逻辑视图供上层更方便使用提取其价值。
好处
在创建你的数据源后,企业可以更快的查看组织内部的所有数据。
这些虚拟化数据视图能够在不迁移数据,不复制数据,不通过ETL加工数据或者额外的存储需求就可以实时查看和分析,这样加速了处理速度。可以为企业带来实时的具有洞察力的结果,更快速响应和做出相应的决策。
安全
为了安全即使在可信任的环境,集中化认证和对平台用户访问数据的验证也需要被强制应用。
数据虚拟化管理者,工程师,支持者和用户角色提供了细粒度的对虚拟资产访问管理。
Cloud Pak for Data 中需要使用数据虚拟化功能的用户必须根据他们的工作内容来分配虚拟化角色进行安全管理
IT环境和应用之间的通信利用IBM坚固额技术进行了安全的加密,比如标准的协议进行的SSL/TLS加密。
平台支持
数据虚拟化支持标准的SQL查询,通过传统的接口比如R, Spark, Python, and Jupyter Notebooks.
另外,也支持很多普遍使用的分析应用工具,包括IBM的Watson Studio 和 Cognos Analytics.
分享
接下来,给大家分享几个在使用DV过程中经常遇到的问题和最佳实践:
一. 数据库与DV参数设置
检查源库db2mpp和DV有codepage设置是否一致
- 实例级别:数据库实例级别的代码页设置,它会影响 DB2相关应用程序对代码页转换时做出代码页判定。 查看命令: db2set –all
- 数据库级别:DB2 数据库级别的代码页设置,必须在建库时进行设置codeset xxx,它是针对于此数据库对字符的内部编码。查看命令:db2 get db cfg | grep code ; 不可修改
CREATE DATABASE TESTDB1 USING CODESET UTF-8 TERRITORY CN
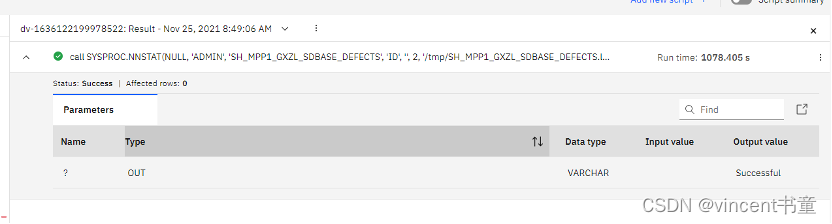
二. DV收集统计信息
call SYSPROC.NNSTAT(NULL,
'ADMIN',
'SH_MPP2_GXZL_SDBASE_DEFECTS_NEW',
'ID',
'',
2,
'/tmp/SH_MPP2_GXZL_SDBASE_DEFECTS_NEW.log',
?,
1);
速度:69亿数据量大概需要1000S
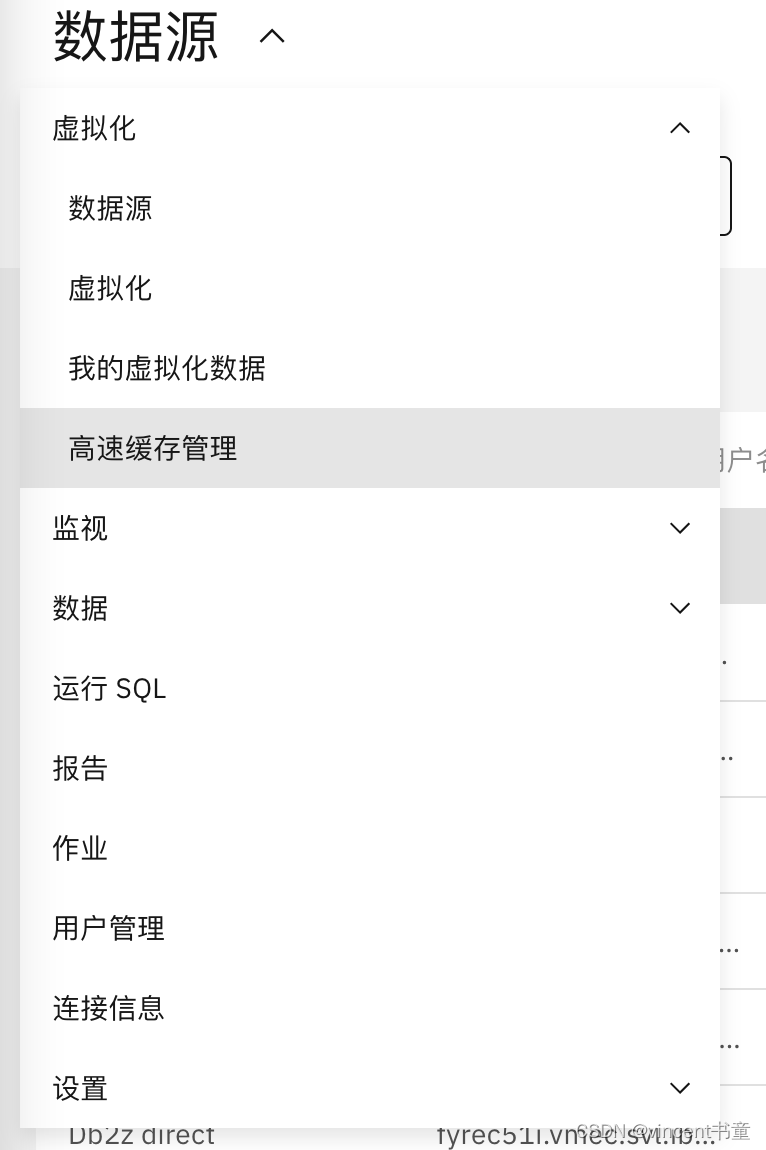
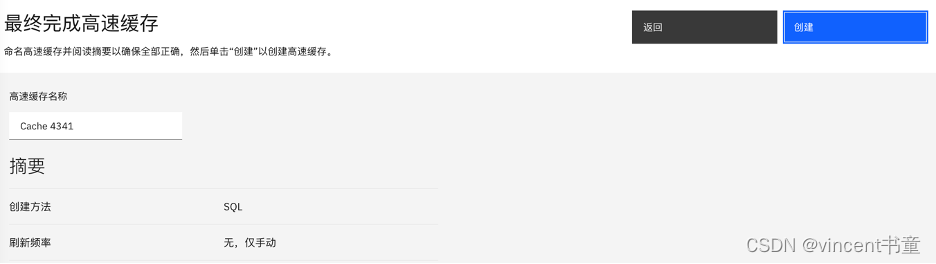
如何使用Cache
1.进入菜单 高速缓存管理
2. 点击 右下角的 添加新的高速缓存
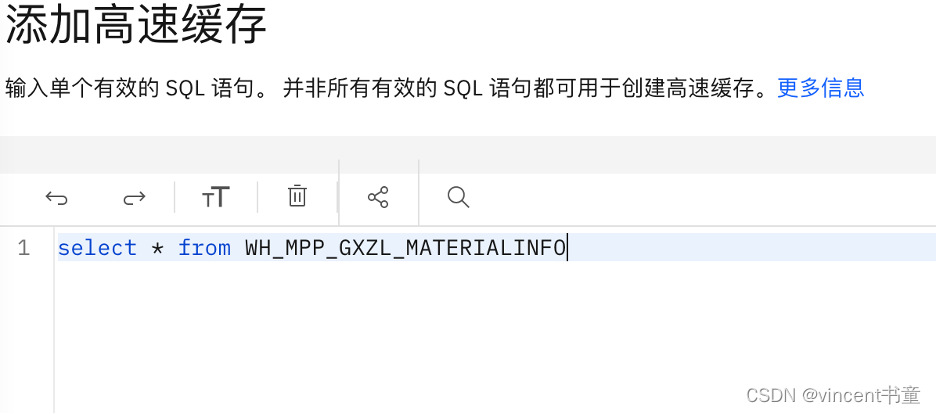
3. 输入需要cache的表
4. 点击 下一步 直到 最后点击 创建,完成创建
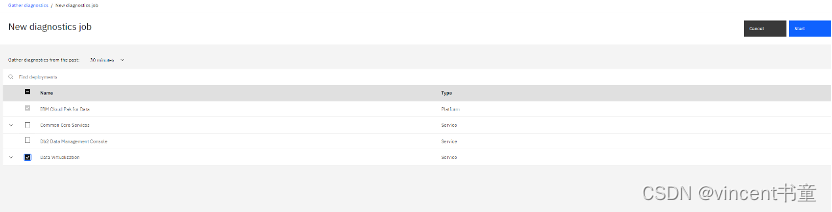
DV收集日志
在菜单support里面的诊断子菜单下,进去后选择DV,然后start收集完了下载成zip文件
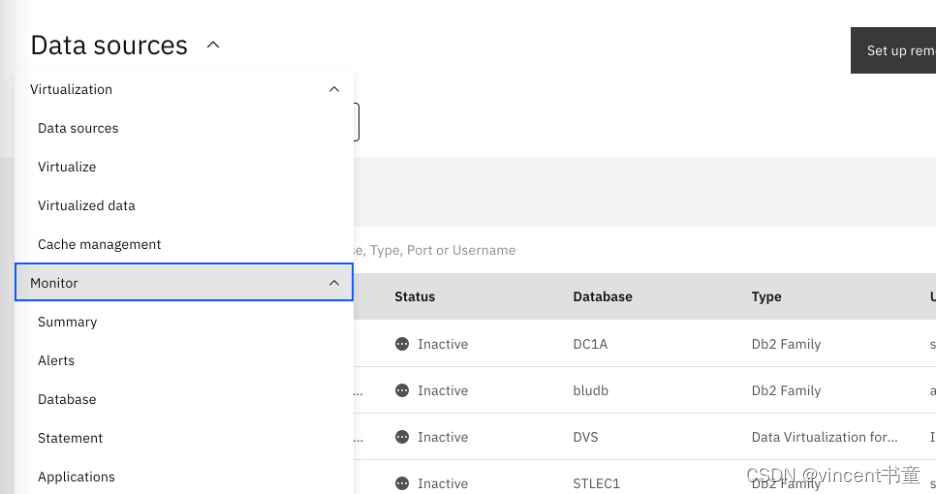
如何监控
打开DV菜单里面的Monitor > Statements > Inflight executions
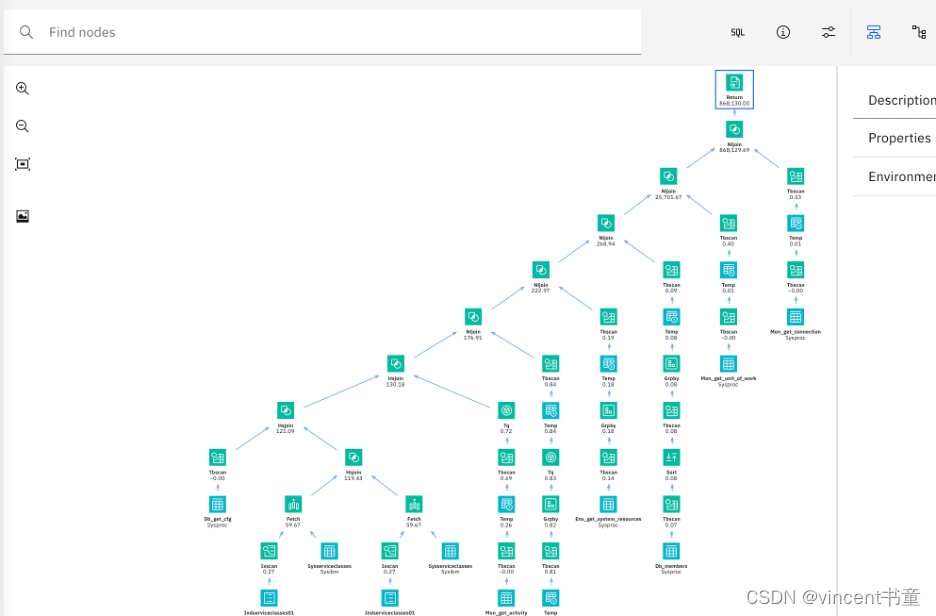
 根据对应问题的条目生成SQL的执行计划,找到问题根因
根据对应问题的条目生成SQL的执行计划,找到问题根因
TroubleShooting
Response code:08001 -4499
Response message:com.ibm.db2.jcc.am.DisconnectNonTransientConnectionException: [jcc][t4][2030][11211][4.27.25] A communication error occurred during operations on the connection's underlying socket, socket input stream,
or socket output stream. Error location: Reply.fill() - insufficient data (-1). Message: Insufficient data. ERRORCODE=-4499, SQLSTATE=08001
solution:
- 收集合适的统计信息
- 索引设计也不好
- 使用Cache















 4279
4279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









