







想要抓取http://www.biquge.la/book/3564/的内容,并解析出该小说的更新时间来提醒自己小说更新了,这样就不用时刻自己动手去刷网页,特别是不用在经历那种小说不更新的失落感了.可是在抓取该网页的过程中,却发现中文出现了乱码,虽然说不影响解析,但是不把它调整过来总觉着心里有根刺在卡着,于是便动手解决了这个问题,在这个过程中,还发现了其他的问题,乱码也有可能是gzip过,于是便想一一记录下来,以备不时之需.
简单的抓取程序:
#_*_coding:utf-8_*_
import urllib2
response = urllib2.urlopen('http://www.biquge.la/book/3564/')
cont = response.read()
file1 = open("./1.txt","w")
file1.write(cont)
file1.close()1.编码问题
我使用的ubuntu 14.04.4使用的默认编码是UTF-8,而抓取的上述网页的编码格式是gbk(通过打开网页,鼠标右键使用Inspect Element查看)

此时下载网页的数据为:
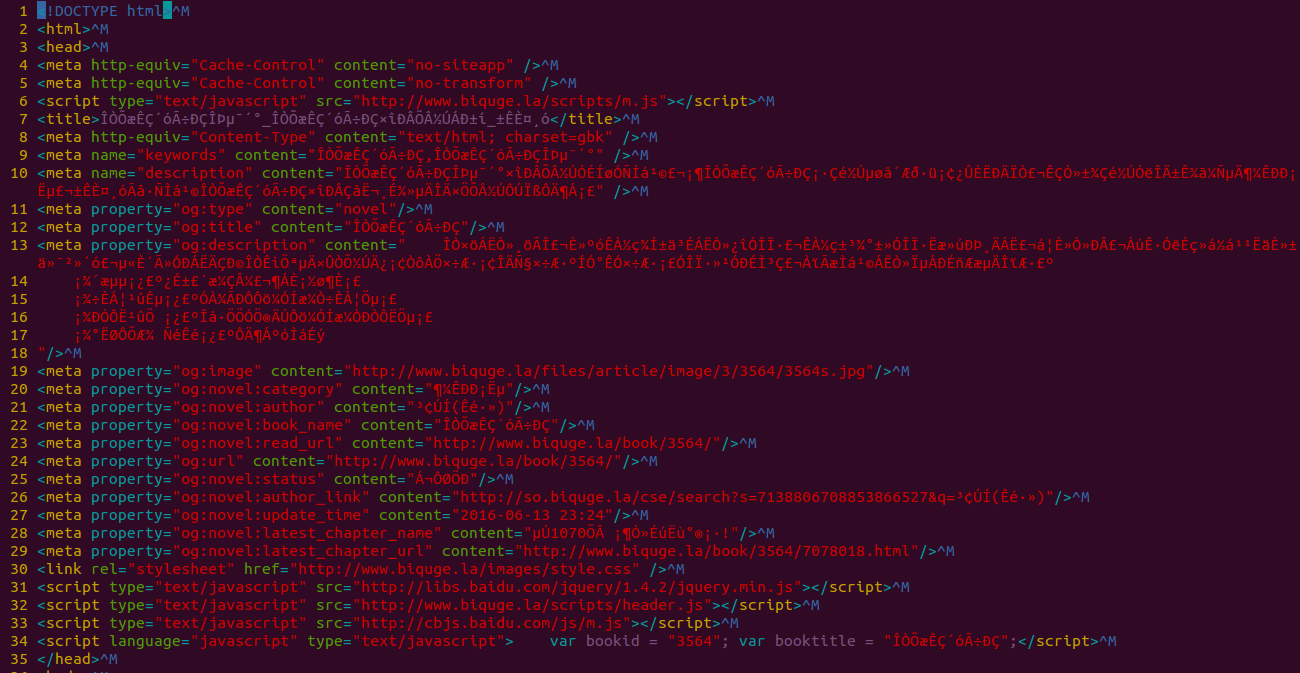
由于可以知道是编码引起的问题,所以使用下面的命令
response.read().decode("gbk").encode("utf-8")先用gbk对下载内容进行解码,然后再对解码之后的内容进行utf-8进行编码,这样输出的内容的编码和系统默认编码一致,这样就不会出现编码问题了.
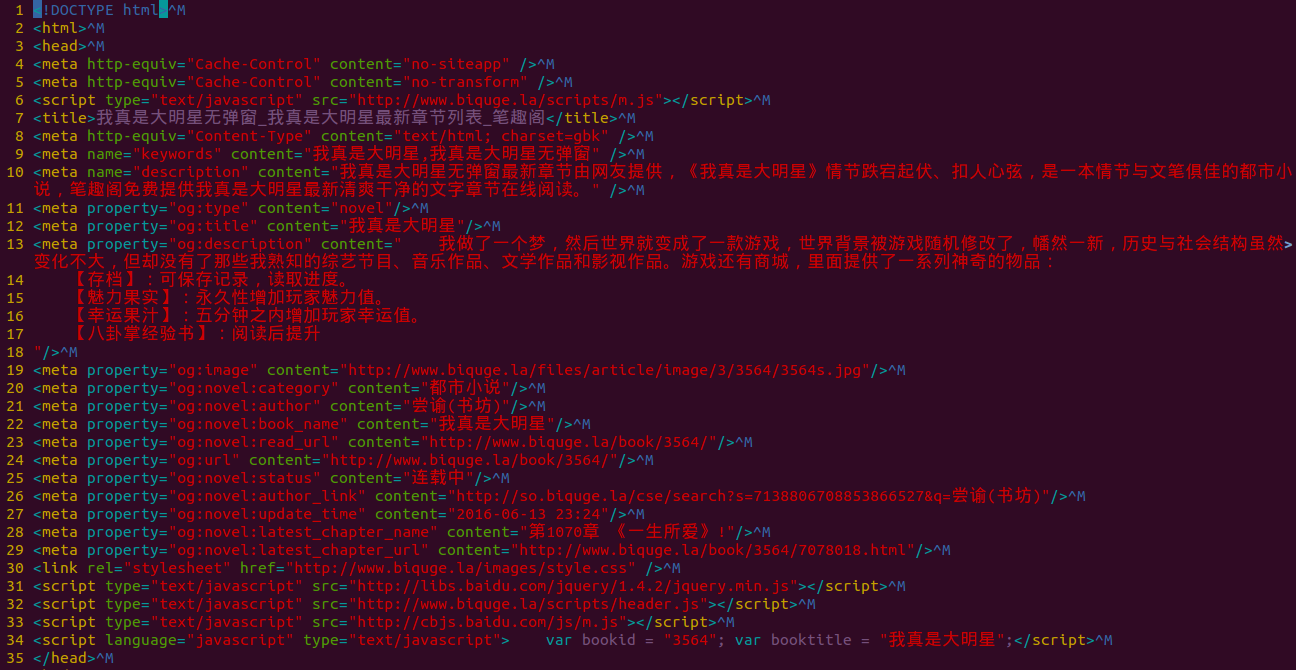
2.gzip问题
request = urllib2.Request(url)
request.add_header('Accept-encoding', 'gzip')
opener = urllib2.build_opener()
response = opener.open(request)html = response.read()
gzipped = response.headers.get('Content-Encoding')
if gzipped:
html = zlib.decompress(html, 16+zlib.MAX_WBITS)
print html3.python中文编码处理















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









