







转载一篇别人写的,非常详细,对陈超老师所讲的内容总结的很好,以下附上正文部分
Spark 概述与编程模型
概述,生态系统以及周边的配套
- 本地实现
- 线上 HDFS 实现
运行的时候
- 交互式 shell 编写
- IDE 编写
对Spark内核进行解析,结合源码,能写基本代码
对 transformation 了解,map(),能写代码
什么是 Spark ?
Apache Spark is an open source cluster computing system that aims to make data analytics fast — both fast to run and fast to write
不仅分析快,写代码也快
以下为 the Berkeley Data Analytics Stack (BDAS)
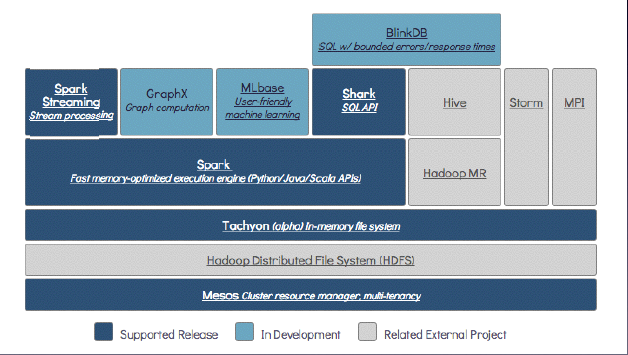
Mesos 与 yarn 功效类似,有效区别
国内用 yarn 比较多,生态系统 yarn 更多一些
Mesos 的上一层是 分布式文件系统 HDFS
Tachyan 是分布式内存文件系统,并不仅支持 spark,也支持map-reduce
hadoop2.3.0 的datanode 也支持 cache(重大改进)
Spark Streaming Stream processing 是实时流处理
GraphX 是个图处理
MLlib 是个机器学习库
Shark SQL API 相当于 Hive on Spark ,相当于在 spark 上面建立一个 SQL
BlinkDB是海量数据上运行交互式SQL查询的大规模并行查询引擎,它允许用户通过传衡数据精度提升查询响应时间,可以将查询时间限制在误差范围之内
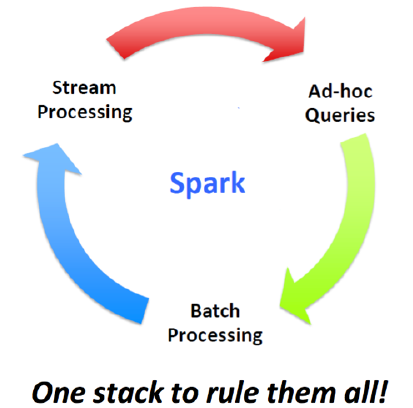
只需要一个站,就可以将所有都搞定了!无论是实时查询、流处理还是批处理,都可以实现
而以往的 Hadoop MapReduce来进行海量数据的分析,用 Strom 来进行实时流处理,Hive来做 SQL 处理,但维护这么多系统,必然会出现很多问题!spark 却不会出现这些问题,因为兼容好,原始设计的初衷也是这样。spark 是最有希望成为下一代分布式计算系统
回顾 Hadoop
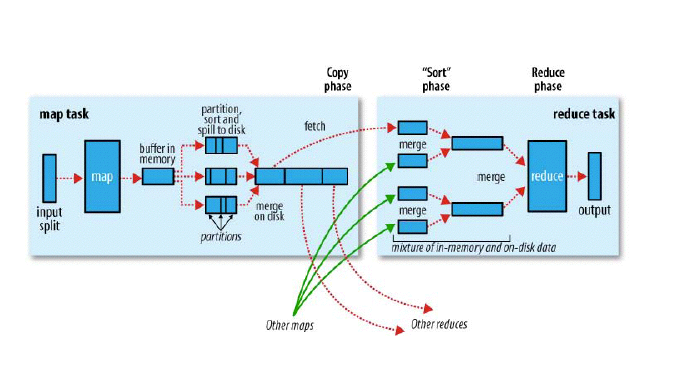
- 两个阶段,map / reduce
- 每个 map 从 HDFS 若干个数据处理,input split 。inputfomat,将 hdfs上的数据处理为 key-value。通过inputfomat 实现。可供用户的 map 程序执行。排序后的会不断的spilt到 disk 上
- 然后有一各分片的过程,partition过程 。map需要哪找 partiton 过程 , 可以指定分片被放在哪个 reduce 上。一个排好序的大文件
- combine 相当于在本地已经进行 reduce 的过程了。
- reduce 就是”要“数据,从map拿数据,数据量大放在磁盘上,数据量小,放在内存上。但由于小文件过多,全在内存,会爆。
面试必问题
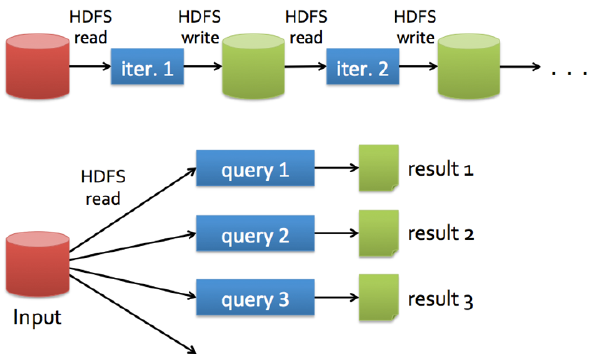
Hadoop的数据共享?慢
为什么慢???额外的复制,序列化和磁盘IO开销
每次迭代操作写入和写出都是在 hdfs 上完成的。然而数据挖掘和机器学习 迭代次数非常多
将来 spark 从 datanode(有 cache)上取数据将非常完美了
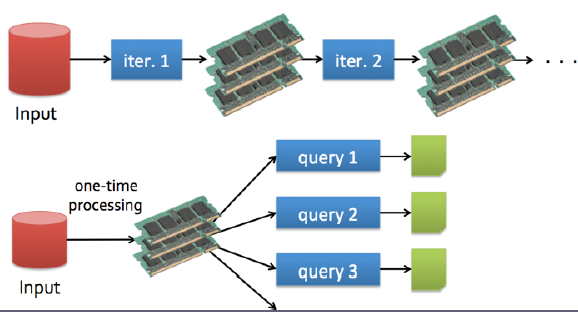
十几G和百来G很适合 spark
Spark的快只是因为内存?
- 内存计算
- DAG 是把整个执行过程做成一张图,然后再进行优化
很多优化措施其实是相通的,譬如说delay scheduling
比如 A节点上正在运行程序,当 B 节点需要从 A 节点上获取资源时,那么将延迟一段时间在执行。这样可以避免以往从忙碌的A节点上复制数据,这样是很耗费时间的,因为如果等待也许只需要几秒钟呢…
Spark API
- 支持3种语⾔言的API
- Scala(很好)
- Python(不错)
- Java(不建议)
通过哪些模式运行Spark呢
有4种模式可以运⾏
- local(多⽤用于测试)
- Standalone
- Mesos
- YARN(工作时)
一切都以RDD为基础
- A list of partitions(源代码里的注释里)一系列的分片
-
A function for computing each split
定义一个函数计算或迭代 -
A list of dependencies on other RDDs
一系列的依赖,RDD(a)->RDD(b)->RDD(c) ,则C 依赖 B ,B依赖A,这样就相互依赖 -
Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
告诉它怎么去分片的,利用小的技巧,可以避免很大的shuffle,避免宽依赖,优化成窄依赖 -
Optionally, a list of preferred locations to compute each split on(e.g. block locations for an HDFS file)
选择最优的计算机子来进行,
Spark runtime
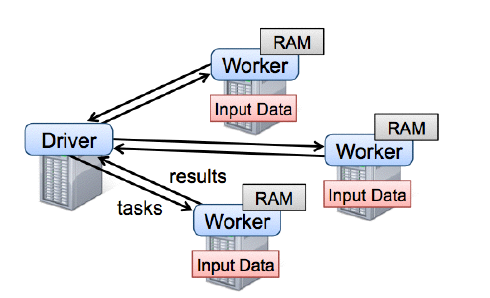
用户的 driver 程序,各个 worker 从分布式系统中获取数据并计算,把结果持久化。
流程图示意
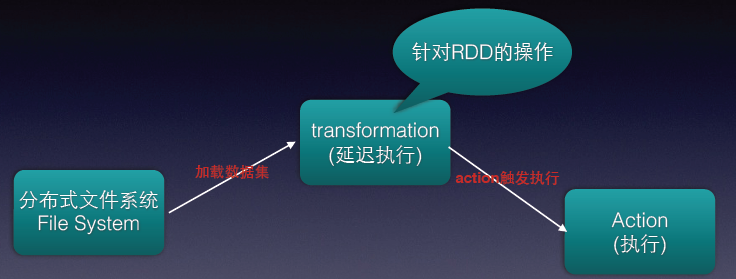
其中的 transformation 操作是针对 RDD 操作的,且是延迟执行的(比如 map()操作),spark 并不会真正执行,而是会在原数据下记录下即将对 A 进行 map 操作。到 action 才会执行。
RDD可以从集合直接转换⽽而来,也可以由从现存的任何Hadoop InputFormat⽽而来,亦或者HBase等等,但国内应用比较少
first demo

- sc 即为 sparkcontents
- lines 代表取了很多数据
- .filter() 过滤,再次强调这里的 transformation 延迟
- 有count 就是代表执行的操作
缓存策略
<code class="hljs fsharp has-numbering"><span class="hljs-keyword">class</span> StorageLevel <span class="hljs-keyword">private</span>(!
<span class="hljs-keyword">private</span> var useDisk_ : Boolean,!
<span class="hljs-keyword">private</span> var useMemory_ : Boolean,!
<span class="hljs-keyword">private</span> var deserialized_ : Boolean,!
<span class="hljs-keyword">private</span> var replication_ : Int = <span class="hljs-number">1</span>)!
<span class="hljs-keyword">val</span> NONE = <span class="hljs-keyword">new</span> StorageLevel(<span class="hljs-keyword">false</span>, <span class="hljs-keyword">false</span>, <span class="hljs-keyword">false</span>)!
<span class="hljs-keyword">val</span> DISK_ONLY = <span class="hljs-keyword">new</span> StorageLevel(<span class="hljs-keyword">true</span>, <span class="hljs-keyword">false</span>, <span class="hljs-keyword">false</span>)!
<span class="hljs-keyword">val</span> DISK_ONLY_2 = <span class="hljs-keyword">new</span> StorageLevel(<span class="hljs-keyword">true</span>, <span class="hljs-keyword">false</span>, <span class="hljs-keyword">false</span>, <span class="hljs-number">2</span>)!
<span class="hljs-keyword">val</span> MEMORY_ONLY = <span class="hljs-keyword">new</span> StorageLevel(<span class="hljs-keyword">false</span>, <span class="hljs-keyword">true</span>, <span class="hljs-keyword">true</span>)!
<span class="hljs-keyword">val</span> MEMORY_ONLY_2 = <span class="hljs-keyword">new</span> StorageLevel(<span class="hljs-keyword">false</span>, <span class="hljs-keyword">true</span>, <span class="hljs-keyword">true</span>, <span class="hljs-number">2</span>)!
<span class="hljs-keyword">val</span> MEMORY_ONLY_SER = <span class="hljs-keyword">new</span> StorageLevel(<span class="hljs-keyword">false</span>, <span class="hljs-keyword">true</span>, <span class="hljs-keyword">false</span>)!
<span class="hljs-keyword">val</span> MEMORY_ONLY_SER_2 = <span class="hljs-keyword">new</span> StorageLevel(<span class="hljs-keyword">false</span>, <span class="hljs-keyword">true</span>, <span class="hljs-keyword">false</span>, <span class="hljs-number">2</span>)!
<span class="hljs-keyword">val</span> MEMORY_AND_DISK = <span class="hljs-keyword">new</span> StorageLevel(<span class="hljs-keyword">true</span>, <span class="hljs-keyword">true</span>, <span class="hljs-keyword">true</span>)!
<span class="hljs-keyword">val</span> MEMORY_AND_DISK_2 = <span class="hljs-keyword">new</span> StorageLevel(<span class="hljs-keyword">true</span>, <span class="hljs-keyword">true</span>, <span class="hljs-keyword">true</span>, <span class="hljs-number">2</span>)!
<span class="hljs-keyword">val</span> MEMORY_AND_DISK_SER = <span class="hljs-keyword">new</span> StorageLevel(<span class="hljs-keyword">true</span>, <span class="hljs-keyword">true</span>, <span class="hljs-keyword">false</span>)!
<span class="hljs-keyword">val</span> MEMORY_AND_DISK_SER_2 = <span class="hljs-keyword">new</span> StorageLevel(<span class="hljs-keyword">true</span>, <span class="hljs-keyword">true</span>, <span class="hljs-keyword">false</span>, <span class="hljs-number">2</span>)</code><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li><li>6</li><li>7</li><li>8</li><li>9</li><li>10</li><li>11</li><li>12</li><li>13</li><li>14</li><li>15</li><li>16</li><li>17</li></ul><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li><li>6</li><li>7</li><li>8</li><li>9</li><li>10</li><li>11</li><li>12</li><li>13</li><li>14</li><li>15</li><li>16</li><li>17</li></ul>
其中 cache默认
<code class="hljs fsharp has-numbering"> <span class="hljs-keyword">val</span> MEMORY_ONLY = <span class="hljs-keyword">new</span> StorageLevel(<span class="hljs-keyword">false</span>, <span class="hljs-keyword">true</span>, <span class="hljs-keyword">true</span>)!</code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>
transformation & action
Scala 操作和 spark 操作一样的

- map 指的是对每个函数经过函数转换后的所有值,得到新的分布式数据集
- filter是经过函数计算,返回 true
- flatMap: 先压扁,再map
- sample: 返回一个样本子集
- groupByKey:在键值对数据上调用,将相同的 key 的值都组合起来,返回一个序列
- reduceByKey:相对于groupByKey, function 会作用在具有相同 key的 value 上面,返回的是一个值
- union :两个数据联合起来
- join :就是一个显示
- cogroup:会生成两个序列
- mapValue : 会保存 partition,key 不变,只改变 value
- sort: 用的最多还是 sortByKey 函数。 原始 API 不提供 sortByValue, 相应的解决办法就是将 key 和value 的位置相互调换,再用 sortByKey 函数
Action:
- count: 取出多少行
- colletc:取出一部分
- loohup:在 map 中 look 出一个 key 一样
- save :会将结果保存到存储系统,如 HDFS
运行几行代码
进入 spark下的 bin 目录,启动 spark-shell
<code class="hljs lasso has-numbering">cd /home/hadoop/software/spark<span class="hljs-subst">-</span><span class="hljs-number">1.0</span><span class="hljs-number">.2</span><span class="hljs-attribute">-bin</span><span class="hljs-attribute">-hadoop2</span>/bin <span class="hljs-built_in">.</span>/spark<span class="hljs-attribute">-shell</span></code><ul class="pre-numbering" style=""><li>1</li><li>2</li></ul><ul class="pre-numbering" style=""><li>1</li><li>2</li></ul>
1. 分别执行以下命令(新手)
<code class="hljs fix has-numbering"><span class="hljs-attribute">val rdd </span>=<span class="hljs-string"> sc.parallelize(List(1,2,34,5,6))</span></code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>

<code class="hljs fix has-numbering"><span class="hljs-attribute">val mapRdd </span>=<span class="hljs-string"> rdd.map(2 * _)</span></code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>
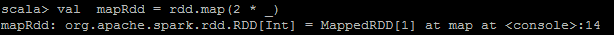
<code class="hljs avrasm has-numbering">mapRdd<span class="hljs-preprocessor">.collect</span></code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>

<code class="hljs fix has-numbering"><span class="hljs-attribute">val filterRdd </span>=<span class="hljs-string"> mapRdd.filter(_ > 5)</span></code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>
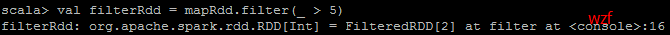
<code class="hljs avrasm has-numbering">filterRdd<span class="hljs-preprocessor">.collect</span></code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>

2. 一步到位(老手)
<code class="hljs avrasm has-numbering">val filterRdd = sc<span class="hljs-preprocessor">.parallelize</span>(List(<span class="hljs-number">1</span>,<span class="hljs-number">2</span>,<span class="hljs-number">34</span>,<span class="hljs-number">5</span>,<span class="hljs-number">6</span>))<span class="hljs-preprocessor">.map</span>(<span class="hljs-number">2</span> * _)<span class="hljs-preprocessor">.filter</span>(_ > <span class="hljs-number">5</span>)<span class="hljs-preprocessor">.collect</span></code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>
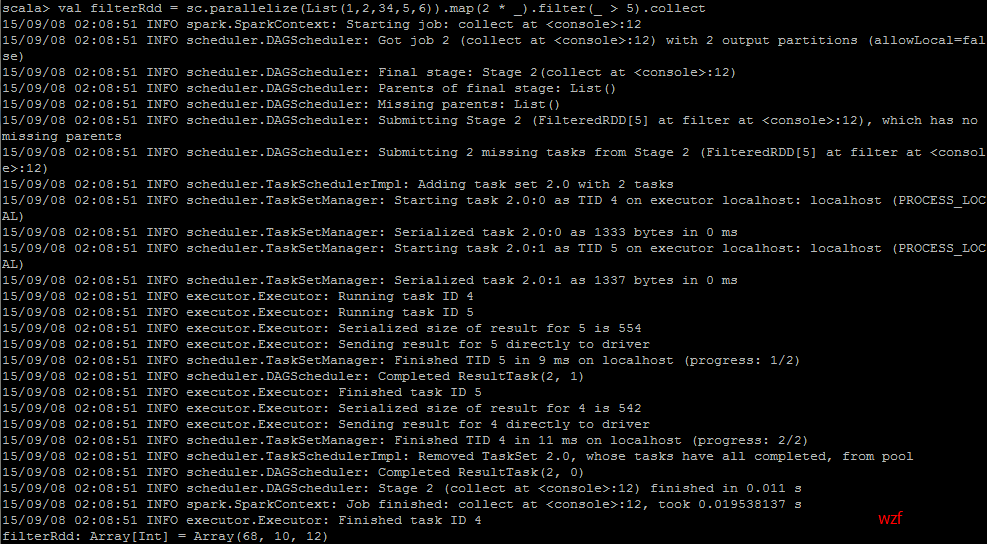
运行 wordcount 程序
- 准备数据,首先新建文件inputWord
<code class="hljs has-numbering">vim ~/inputWord</code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>
内容如下:

- 将本地文件上传到HDFS中
<code class="hljs ruby has-numbering">hadoop fs -put ~<span class="hljs-regexp">/inputWord /data</span><span class="hljs-regexp">/wordcount/</span></code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>
- 可以查看上传后的文件情况,执行如下命令
<code class="hljs haskell has-numbering"><span class="hljs-title">hadoop</span> fs -ls /<span class="hljs-typedef"><span class="hljs-keyword">data</span>/wordcount</span> <span class="hljs-title">hadoop</span> fs -text /<span class="hljs-typedef"><span class="hljs-keyword">data</span>/wordcount/inputWord</span></code><ul class="pre-numbering" style=""><li>1</li><li>2</li></ul><ul class="pre-numbering" style=""><li>1</li><li>2</li></ul>
进入 spark 的 sbin 目录下
<code class="hljs lasso has-numbering">cd /home/hadoop/software/spark<span class="hljs-subst">-</span><span class="hljs-number">1.0</span><span class="hljs-number">.2</span><span class="hljs-attribute">-bin</span><span class="hljs-attribute">-hadoop2</span>/sbin <span class="hljs-built_in">.</span>/start<span class="hljs-attribute">-master</span><span class="hljs-built_in">.</span>sh</code><ul class="pre-numbering" style=""><li>1</li><li>2</li></ul><ul class="pre-numbering" style=""><li>1</li><li>2</li></ul>
显示如下:
<code class="hljs avrasm has-numbering">starting org<span class="hljs-preprocessor">.apache</span><span class="hljs-preprocessor">.spark</span><span class="hljs-preprocessor">.deploy</span><span class="hljs-preprocessor">.master</span><span class="hljs-preprocessor">.Master</span>, logging to /home/hadoop/software/spark-<span class="hljs-number">1.0</span><span class="hljs-number">.2</span>-bin-hadoop2/sbin/../logs/spark-hadoop-org<span class="hljs-preprocessor">.apache</span><span class="hljs-preprocessor">.spark</span><span class="hljs-preprocessor">.deploy</span><span class="hljs-preprocessor">.master</span><span class="hljs-preprocessor">.Master</span>-<span class="hljs-number">1</span>-master<span class="hljs-preprocessor">.out</span></code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>
查看相应的 log 文件
<code class="hljs avrasm has-numbering">cat logs/spark-hadoop-org<span class="hljs-preprocessor">.apache</span><span class="hljs-preprocessor">.spark</span><span class="hljs-preprocessor">.deploy</span><span class="hljs-preprocessor">.master</span><span class="hljs-preprocessor">.Master</span>-<span class="hljs-number">1</span>-master<span class="hljs-preprocessor">.out</span></code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>
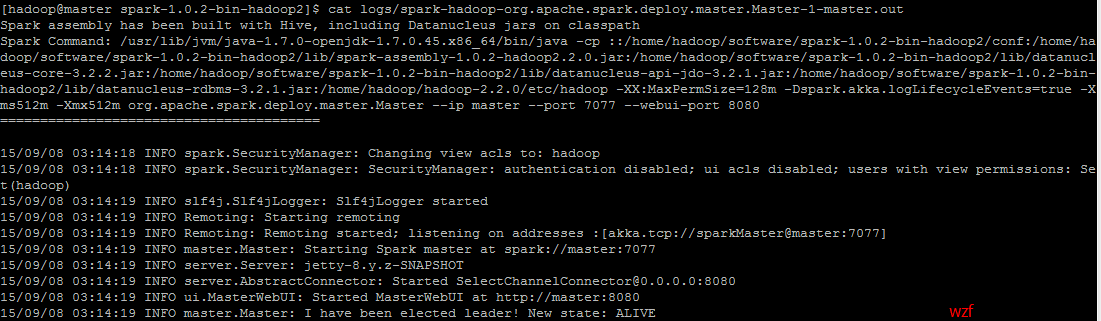
可以看到输出的几条重要的信息,spark端口 7077,ui端口8080等,并且当前node通过选举,确认自己为leader,这个时候,我们可以通过 http://localhost:8080/ 来查看到当前master的总体状态
<code class="hljs avrasm has-numbering">val rdd = sc<span class="hljs-preprocessor">.textFile</span>(<span class="hljs-string">"/data/wordcount/"</span>) rdd<span class="hljs-preprocessor">.cache</span> rdd<span class="hljs-preprocessor">.count</span></code><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li></ul><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li></ul>
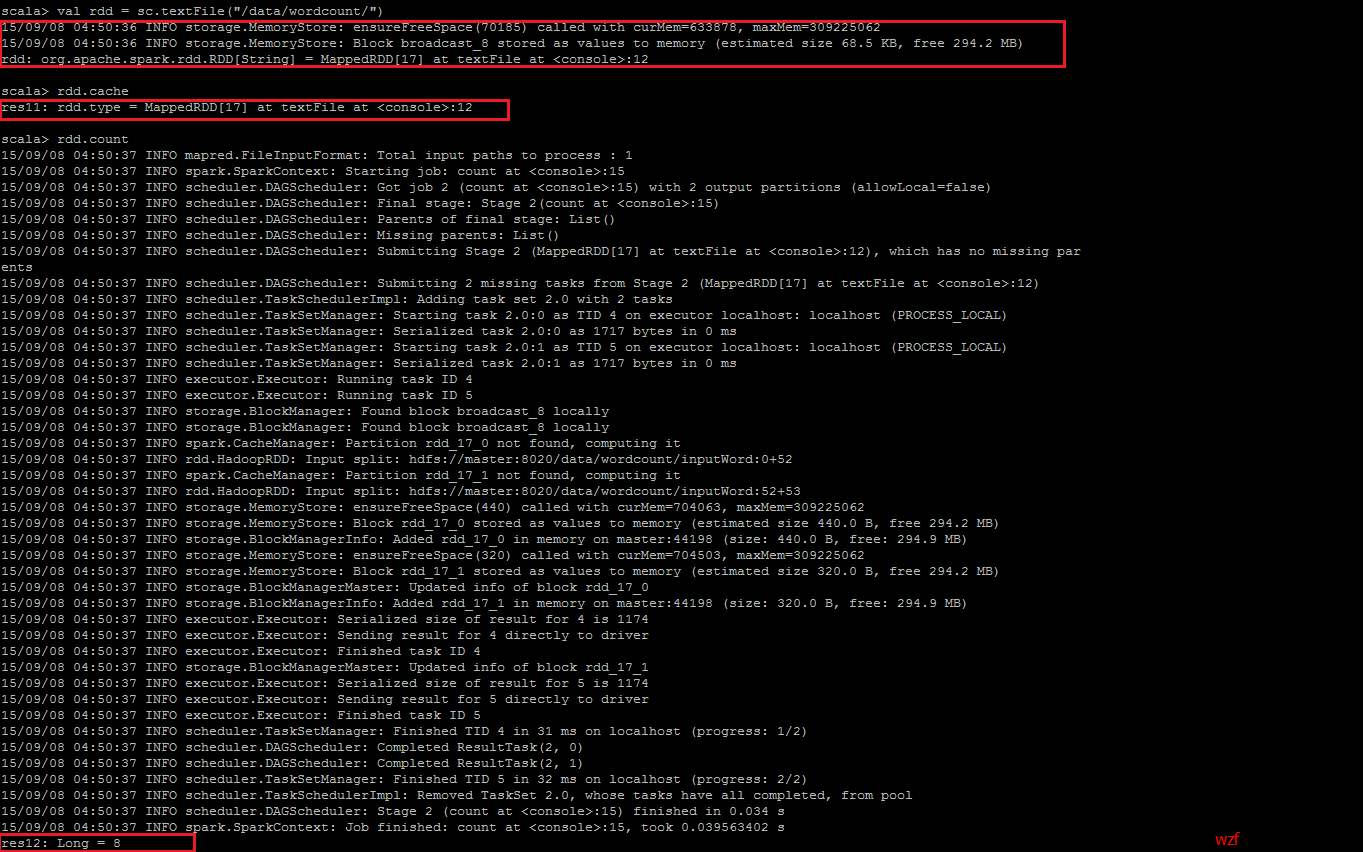
Note:暂时只会从 HDFS上取数据,而不会从本地上取数据。在 HDFS 上的路径应是文件的上一层路径,不应包含文件名!切记!
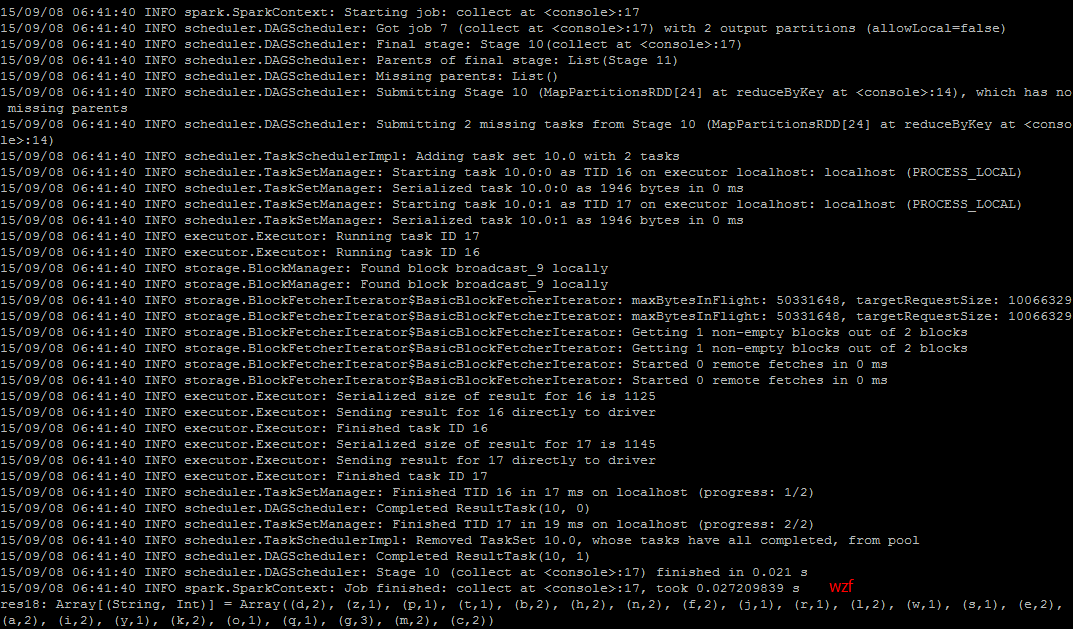
<code class="hljs avrasm has-numbering">val wordcount = rdd<span class="hljs-preprocessor">.flatMap</span>(_<span class="hljs-preprocessor">.split</span>(<span class="hljs-string">' '</span>))<span class="hljs-preprocessor">.map</span>((_,<span class="hljs-number">1</span>))<span class="hljs-preprocessor">.reduceByKey</span>(_+_)</code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>

<code class="hljs avrasm has-numbering">wordcount<span class="hljs-preprocessor">.collect</span></code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>
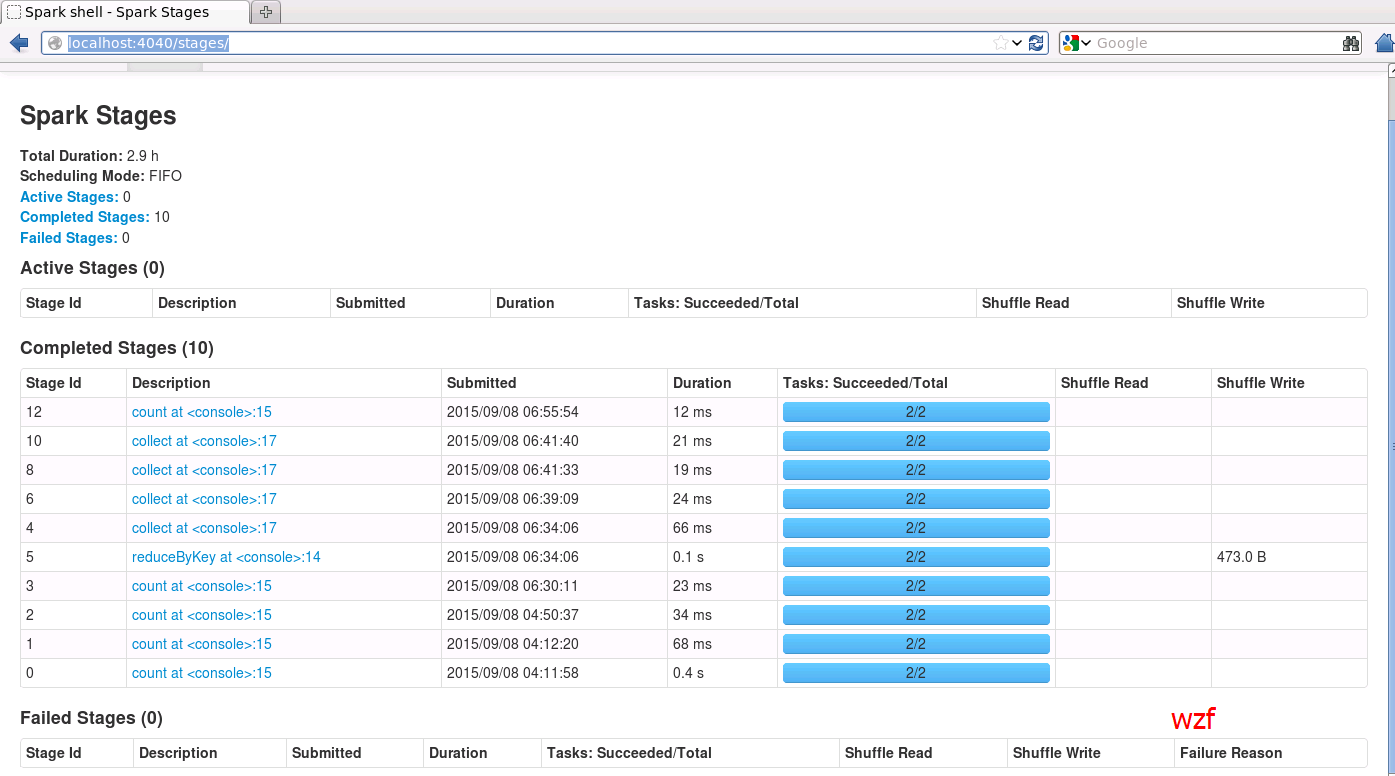
期间,我们可以通过UI看到job列表和状态:
http://localhost:4040/stages/
<code class="hljs fsharp has-numbering"><span class="hljs-keyword">val</span> rdd1 = sc.parallelize(List((<span class="hljs-attribute">'a</span>',<span class="hljs-number">1</span>),(<span class="hljs-attribute">'a</span>',<span class="hljs-number">2</span>))) <span class="hljs-keyword">val</span> rdd2 = sc.parallelize(List((<span class="hljs-attribute">'b</span>',<span class="hljs-number">1</span>),(<span class="hljs-attribute">'b</span>',<span class="hljs-number">2</span>))) <span class="hljs-keyword">val</span> result = rdd1 union rdd2 result.collect</code><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li><li>4</li></ul><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li><li>4</li></ul>
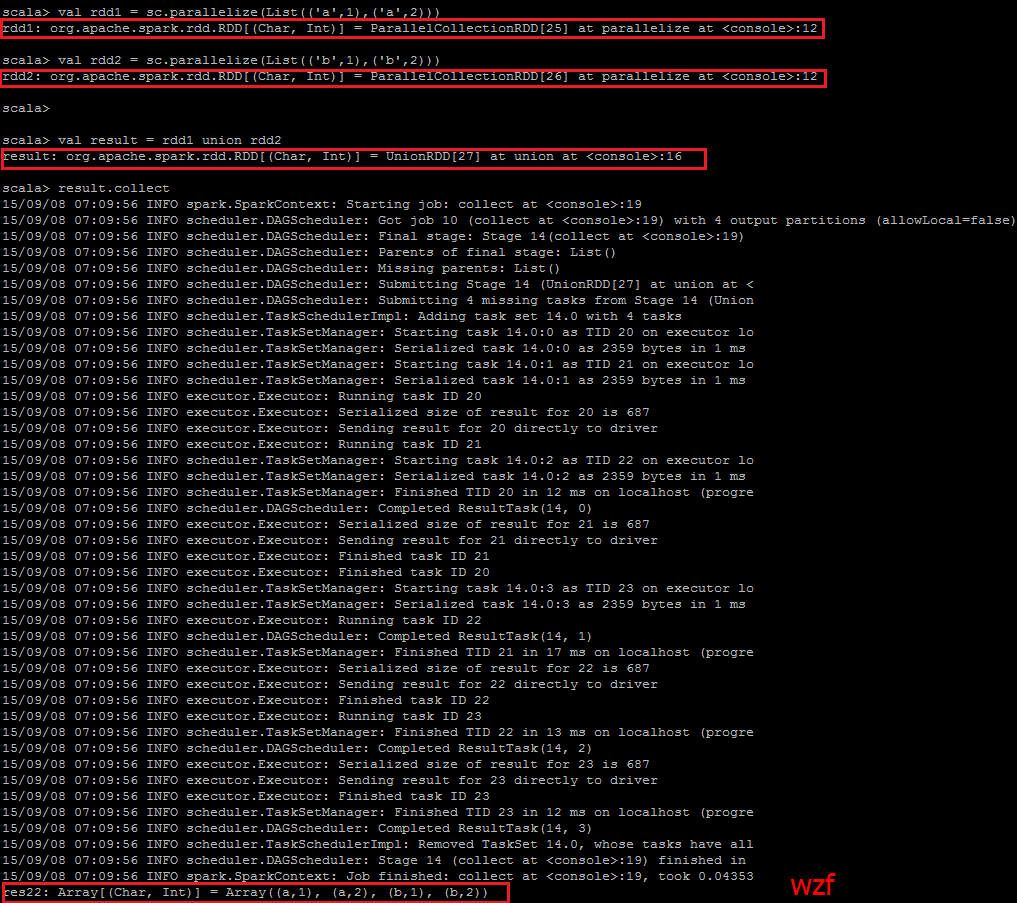
<code class="hljs avrasm has-numbering">val rdd1 = sc<span class="hljs-preprocessor">.parallelize</span>(List((<span class="hljs-string">'a'</span>,<span class="hljs-number">1</span>),(<span class="hljs-string">'a'</span>,<span class="hljs-number">2</span>),(<span class="hljs-string">'b'</span>,<span class="hljs-number">3</span>),(<span class="hljs-string">'b'</span>,<span class="hljs-number">4</span>))) val rdd2 = sc<span class="hljs-preprocessor">.parallelize</span>(List((<span class="hljs-string">'a'</span>,<span class="hljs-number">5</span>),(<span class="hljs-string">'a'</span>,<span class="hljs-number">6</span>),(<span class="hljs-string">'b'</span>,<span class="hljs-number">7</span>),(<span class="hljs-string">'b'</span>,<span class="hljs-number">8</span>))) rdd1 join rdd2 res12<span class="hljs-preprocessor">.collect</span></code><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li><li>4</li></ul><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li><li>4</li></ul>
最终出现以下结果

<code class="hljs avrasm has-numbering">val rdd1 = sc<span class="hljs-preprocessor">.parallelize</span>(List((<span class="hljs-string">'a'</span>,<span class="hljs-number">1</span>),(<span class="hljs-string">'a'</span>,<span class="hljs-number">2</span>),(<span class="hljs-string">'b'</span>,<span class="hljs-number">3</span>),(<span class="hljs-string">'b'</span>,<span class="hljs-number">4</span>))) rdd1<span class="hljs-preprocessor">.lookup</span>(<span class="hljs-string">'a'</span>)</code><ul class="pre-numbering" style=""><li>1</li><li>2</li></ul><ul class="pre-numbering" style=""><li>1</li><li>2</li></ul>

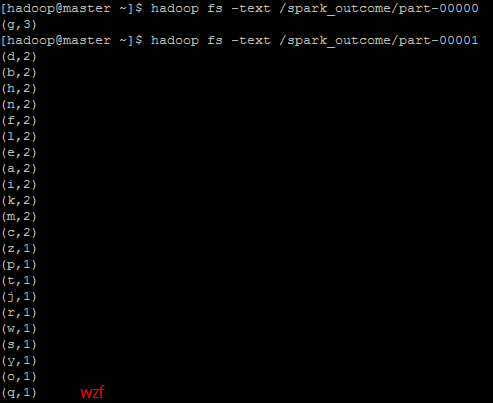
<code class="hljs avrasm has-numbering"> val rdd = sc<span class="hljs-preprocessor">.textFile</span>(<span class="hljs-string">"/data/spark_wordcount"</span>) val wordcount = rdd<span class="hljs-preprocessor">.flatMap</span>(_<span class="hljs-preprocessor">.split</span>(<span class="hljs-string">' '</span> ))<span class="hljs-preprocessor">.map</span>((_,<span class="hljs-number">1</span>))<span class="hljs-preprocessor">.reduceByKey</span>(_+_)<span class="hljs-preprocessor">.map</span>(<span class="hljs-built_in">x</span> => (<span class="hljs-built_in">x</span>._2,<span class="hljs-built_in">x</span>._1))<span class="hljs-preprocessor">.sortByKey</span>(false)<span class="hljs-preprocessor">.map</span>(<span class="hljs-built_in">x</span> => (<span class="hljs-built_in">x</span>._2,<span class="hljs-built_in">x</span>._1))<span class="hljs-preprocessor">.saveAsTextFile</span>(<span class="hljs-string">"/spark_outcome/"</span>)</code><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li></ul><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li></ul>
程序执行成功之后,在另外一个终端输入命令以查看最终的结果
<code class="hljs lasso has-numbering">hadoop fs <span class="hljs-attribute">-ls</span> <span class="hljs-attribute">-R</span> /spark_outcome</code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>

<code class="hljs livecodeserver has-numbering">hadoop fs -<span class="hljs-keyword">text</span> /spark_outcome/part-<span class="hljs-number">00000</span> hadoop fs -<span class="hljs-keyword">text</span> /spark_outcome/part-<span class="hljs-number">00001</span></code><ul class="pre-numbering" style=""><li>1</li><li>2</li></ul><ul class="pre-numbering" style=""><li>1</li><li>2</li></ul>
Lineage
每个子RDD都依赖前一个 RDD,一般会在中间制作个拷贝,防止最后的时刻某个 RDD 挂了
容错
<code class="hljs avrasm has-numbering">val logs = sc<span class="hljs-preprocessor">.textFile</span>(…)<span class="hljs-preprocessor">.filter</span>(_<span class="hljs-preprocessor">.contains</span>(“spark”))<span class="hljs-preprocessor">.map</span>(_<span class="hljs-preprocessor">.split</span>(‘\t’)(<span class="hljs-number">1</span>))</code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>

每个RDD都会记录⾃自⼰己依赖于哪个(哪些)RDD,万⼀一某个RDD的某些 partition挂了,可以通过其它RDD并⾏行计算迅速恢复出来
依赖
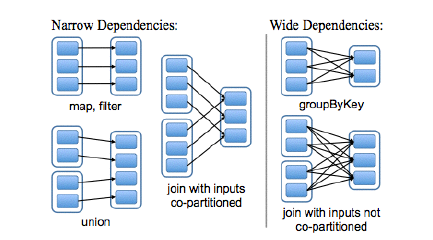
大的框称之为 RDD,而小的实心矩形为 partition
窄依赖:一个 partition 最多只能被子 RDD 的一个 partion 所使用
宽依赖:一个 partition 可以被子 RDD 的多个 partion 所使用
map,filter 会导致窄依赖,而 join 会导致宽依赖。co-partition 也可以被认为是窄依赖
在一个节点上把所有的 partition 全部搞定,宽依赖只有等所有的副partition全部传输到节点上以后才开始计算。在宽依赖中,如果某个节点失效了,那么将重新计算,计算代价相当的大
左边的 RDD 计算出的结果,会存在 map端所在的磁盘
集群配置
spark-env.sh
<code class="hljs rust has-numbering"><span class="hljs-keyword">export</span> JAVA_HOME= <span class="hljs-keyword">export</span> SPARK_MASTER_IP= <span class="hljs-keyword">export</span> SPARK_WORKER_CORES= <span class="hljs-comment">// 分配给spark的CPU数量 </span> <span class="hljs-keyword">export</span> SPARK_WORKER_INSTANCES= <span class="hljs-comment">// 划分出来的实例,普通的一个就够了</span> <span class="hljs-keyword">export</span> SPARK_WORKER_MEMORY= <span class="hljs-comment">// 给 spark 分配的内存</span> <span class="hljs-keyword">export</span> SPARK_MASTER_PORT= <span class="hljs-comment">// 设置的端口</span> <span class="hljs-keyword">export</span> SPARK_JAVA_OPTS=<span class="hljs-string">"-verbose:gc -XX:-PrintGCDetails -XX:+PrintGCTimeStamps”</span></code><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li><li>6</li><li>7</li></ul><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li><li>6</li><li>7</li></ul>
slaves
xx.xx.xx.2
xx.xx.xx.3
xx.xx.xx.4
xx.xx.xx.5
版本选择
- ⾃己编译 — 可能会遇到某些问题
网络好就可以尝试,否则就算了 - pre-built版本
下载相应 hadoop2.2.0 版本的 spark
interactive shell & programming in IDE
shell运行
/sbin 是存放一些启动和关闭集群的一些脚本
/bin 是存放 spark 启动关闭的程序,例如 spark-shell
<code class="hljs livecodeserver has-numbering">MASTER=<span class="hljs-built_in">local</span>[<span class="hljs-number">4</span>] ADD_JARS=code.jar ./spark-<span class="hljs-built_in">shell</span></code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>
其中 local [4] 表示的是 几个本地线程
如果只是简单的启动,后面没有跟任何参数,那么默认是以 standalone 的方式启动
<code class="hljs fix has-numbering"><span class="hljs-attribute">MASTER</span>=<span class="hljs-string">spark://host:port </span></code><ul class="pre-numbering" style=""><li>1</li><li>2</li></ul><ul class="pre-numbering" style=""><li>1</li><li>2</li></ul>
<code class="hljs bash has-numbering">指定executor内存:<span class="hljs-keyword">export</span> SPARK_MEM=<span class="hljs-number">25</span>g</code><ul class="pre-numbering" style=""><li>1</li></ul><ul class="pre-numbering" style=""><li>1</li></ul>
这个指定的 application 能用多少内存(这个命名可能将来会被废除)
spark-shell注意
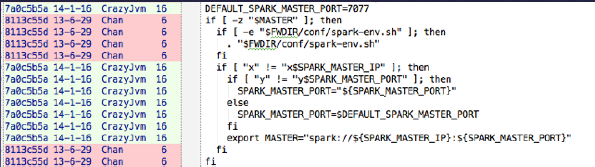
spark-shell intends to set MASTER automatically if we do not provide the option when we start the shell , but there’s a problem. The condition is “if [[ “x” != “x$SPARK_MASTER_IP” && “y” != “y $SPARK_MASTER_PORT” ]];” we sure will set SPARK_MASTER_IP explicitly, the SPARK_MASTER_PORT option, however, we probably do not set just using spark default port 7077. So if we do not set PARK_MASTER_PORT, the condition will never be true. We should just use default port if users do not set port explicitly I think.
IDE
- 推荐Intellij IDEA
- 加⼊依赖

有时还要把 hadoop 版本加进去
- coding
- 打包
- 运⾏
Spark 1.0相关变动
- spark-defaults.conf 默认参数
<code class="hljs avrasm has-numbering">spark<span class="hljs-preprocessor">.master</span> spark://server1:<span class="hljs-number">8888</span> spark<span class="hljs-preprocessor">.local</span><span class="hljs-preprocessor">.dir</span> /data/tmp_spark_dir/ // shuffle 过程中的临时目录 spark<span class="hljs-preprocessor">.executor</span><span class="hljs-preprocessor">.memory</span> <span class="hljs-number">10</span>g // 设置内存</code><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li></ul><ul class="pre-numbering" style=""><li>1</li><li>2</li><li>3</li></ul>
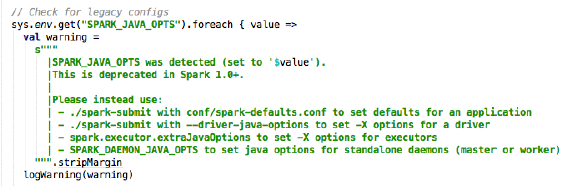
- 注意:SPARK_MEM已被弃⽤
- SPARK_JAVA_OPTS不建议再使⽤用
- SPARK_SUBMIT_OPTS为替代者


http://spark.apache.org/docs/latest/configuration.html
- 使⽤用spark-submit来提交任务(推荐)
- 其它也可⾏行,如sbt run, java -jar 等等
















 4760
4760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









