







前言
为了解决传统Web开发模式带来的各种问题,我们进行了许多尝试,但由于前/后端的物理鸿沟,尝试的方案都大同小异。痛定思痛,今天我们重新思考了“前后端”的定义,引入前端同学都熟悉的NodeJS,试图探索一条全新的前后端分离模式。
随着不同终端(Pad/Mobile/PC)的兴起,对开发人员的要求越来越高,纯浏览器端的响应式已经不能满足用户体验的高要求,我们往往需要针对不同的终端开发定制的版本。为了提升开发效率,前后端分离的需求越来越被重视,后端负责业务/数据接口,前端负责展现/交互逻辑,同一份数据接口,我们可以定制开发多个版本。
这个话题最近被讨论得比较多,阿里有些BU也在进行一些尝试。讨论了很久之后,我们团队决定探索一套基于NodeJS的前后端分离方案,过程中有一些不断变化的认识以及思考,记录在这里,也希望看到的同学参与讨论,帮我们完善。
一、什么是前后端分离?
最开始组内讨论的过程中我发现,每个人对前后端分离的理解不一样,为了保证能在同一个频道讨论,先就什么是”前后端分离”达成一致。
大家一致认同的前后端分离的例子就是SPA(Single-page application),所有用到的展现数据都是后端通过异步接口(AJAX/JSONP)的方式提供的,前端只管展现。
从某种意义上来说,SPA确实做到了前后端分离,但这种方式存在两个问题:
- WEB服务中,SPA类占的比例很少。很多场景下还有同步/同步+异步混合的模式,SPA不能作为一种通用的解决方案。
- 现阶段的SPA开发模式,接口通常是按照展现逻辑来提供的,有时候为了提高效率,后端会帮我们处理一些展现逻辑,这就意味着后端还是涉足了View层的工作,不是真正的前后端分离。
SPA式的前后端分离,是从物理层做区分(认为只要是客户端的就是前端,服务器端的就是后端),这种分法已经无法满足我们前后端分离的需求,我们认为从职责上划分才能满足目前我们的使用场景:
- 前端:负责View和Controller层。
- 后端:只负责Model层,业务处理/数据等。
为什么去做这种职责的划分,后面会继续探讨。
二、为什么要前后端分离?
关于这个问题,玉伯的文章Web研发模式演变中解释得非常全面,我们再大概理一下:
2.1 现有开发模式的适用场景
玉伯提到的几种开发模式,各有各的适用场景,没有哪一种完全取代另外一种。
- 比如后端为主的MVC,做一些同步展现的业务效率很高,但是遇到同步异步结合的页面,与后端开发沟通起来就会比较麻烦。
- Ajax为主SPA型开发模式,比较适合开发APP类型的场景,但是只适合做APP,因为SEO等问题不好解决,对于很多类型的系统,这种开发方式也过重。
2.2 前后端职责不清
在业务逻辑复杂的系统里,我们最怕维护前后端混杂在一起的代码,因为没有约束,M-V-C每一层都可能出现别的层的代码,日积月累,完全没有维护性可言。
虽然前后端分离没办法完全解决这种问题,但是可以大大缓解。因为从物理层次上保证了你不可能这么做。
2.3 开发效率问题
淘宝的Web基本上都是基于MVC框架webx,架构决定了前端只能依赖后端。
所以我们的开发模式依然是,前端写好静态demo,后端翻译成VM模版,这种模式的问题就不说了,被吐槽了很久。
直接基于后端环境开发也很痛苦,配置安装使用都很麻烦。为了解决这个问题,我们发明了各种工具,比如VMarket,但是前端还是要写VM,而且依赖后端数据,效率依然不高。
另外,后端也没法摆脱对展现的强关注,从而专心于业务逻辑层的开发。
2.4 对前端发挥的局限
性能优化如果只在前端做空间非常有限,于是我们经常需要后端合作才能碰撞出火花,但由于后端框架限制,我们很难使用Comet、Bigpipe等技术方案来优化性能。
为了解决以上提到的一些问题,我们进行了很多尝试,开发了各种工具,但始终没有太多起色,主要是因为我们只能在后端给我们划分的那一小块空间去发挥。只有真正做到前后端分离,我们才能彻底解决以上问题。
三、怎么做前后端分离?
怎么做前后端分离,其实第一节中已经有了答案:
- 前端:负责View和Controller层。
- 后端:负责Model层,业务处理/数据等。
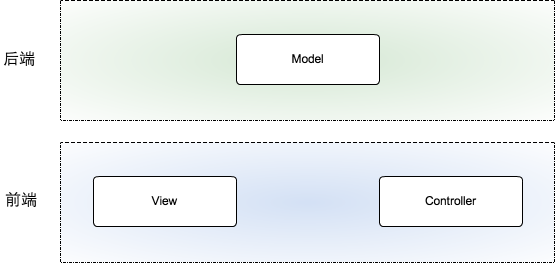
图1
试想一下,如果前端掌握了Controller,我们可以做url design,我们可以根据场景决定在服务端同步渲染,还是根据view层数据输出json数据,我们还可以根据表现层需求很容易的做Bigpipe,Comet,Socket等等,完全是需求决定使用方式。
3.1 基于NodeJS“全栈”式开发
如果想实现上图的分层,就必然需要一种web服务帮我们实现以前后端做的事情,于是就有了标题提到的“基于NodeJS的全栈式开发”。
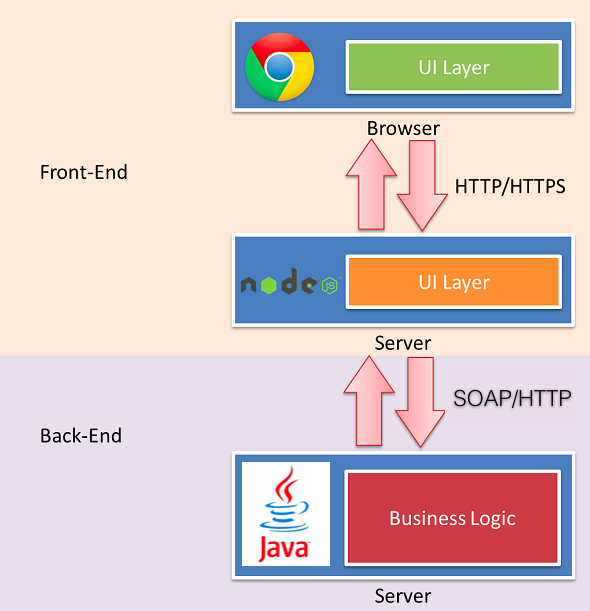
图2
这张图看起来简单而且很好理解,但没尝试过,会有很多疑问。
- SPA模式中,后端已供了所需的数据接口,view前端已经可以控制,为什么要多加NodeJS这一层?
- 多加一层,性能怎么样?
- 多加一层,前端的工作量是不是增加了?
- 多加一层就多一层风险,怎么破?
- NodeJS什么都能做,为什么还要JAVA?
这些问题要说清楚不容易,下面说下我的认识过程。
3.2 为什么要增加一层NodeJS?
现阶段我们主要以后端MVC的模式进行开发,这种模式严重阻碍了前端开发效率,也让后端不能专注于业务开发。
解决方案是让前端能控制Controller层,但是如果在现有技术体系下很难做到,因为不可能让所有前端都学Java,安装后端的开发环境,写VM。
NodeJS就能很好的解决这个问题,我们无需学习一门新的语言,就能做到以前开发帮我们做的事情,一切都显得那么自然。
3.3 性能问题
分层就涉及每层之间的通讯,肯定会有一定的性能损耗。但是合理的分层能让职责清晰、也方便协作,会大大提高开发效率。分层带来的损失,一定能在其他方面的收益弥补回来。
另外,一旦决定分层,我们可以通过优化通讯方式、通讯协议,尽可能把损耗降到最低。
举个例子:
淘宝宝贝详情页静态化之后,还是有不少需要实时获取的信息,比如物流、促销等等,因为这些信息在不同业务系统中,所以需要前端发送5,6个异步请求来回填这些内容。
有了NodeJS之后,前端可以在NodeJS中去代理这5个异步请求,还能很容易的做Bigpipe,这块的优化能让整个渲染效率提升很多。
可能在PC上你觉得发5,6个异步请求也没什么,但是在无线端,在客户手机上建立一个HTTP请求开销很大,有了这个优化,性能一下提升好几倍。
淘宝详情基于NodeJS的优化我们正在进行中,上线之后我会分享一下优化的过程。
3.4 前端的工作量是否增加了?
相对于只切页面/做demo,肯定是增加了一点,但是当前模式下有联调、沟通环节,这个过程非常花时间,也容易出bug,还很难维护。
所以,虽然工作量会增加一点,但是总体开发效率会提升很多。
另外,测试成本可以节省很多。以前开发的接口都是针对表现层的,很难写测试用例。如果做了前后端分离,甚至测试都可以分开,一拨人专门测试接口,一拨人专注测试UI(这部分工作甚至可以用工具代替)。
3.5 增加Node层带来的风险怎么控制?
随着Node大规模使用,系统/运维/安全部门的同学也一定会加入到基础建设中,他们会帮助我们去完善各个环节可能出现的问题,保障系的稳定性。
3.6 Node什么都能做,为什么还要JAVA?
我们的初衷是做前后端分离,如果考虑这个问题就有点违背我们的初衷了。即使用Node替代Java,我们也没办法保证不出现今天遇到的种种问题,比如职责不清。我们的目的是分层开发,专业的人,专注做专业的事。基于JAVA的基础架构已经非常强大而且稳定,而且更适合做现在架构的事情。
四、淘宝基于Node的前后端分离
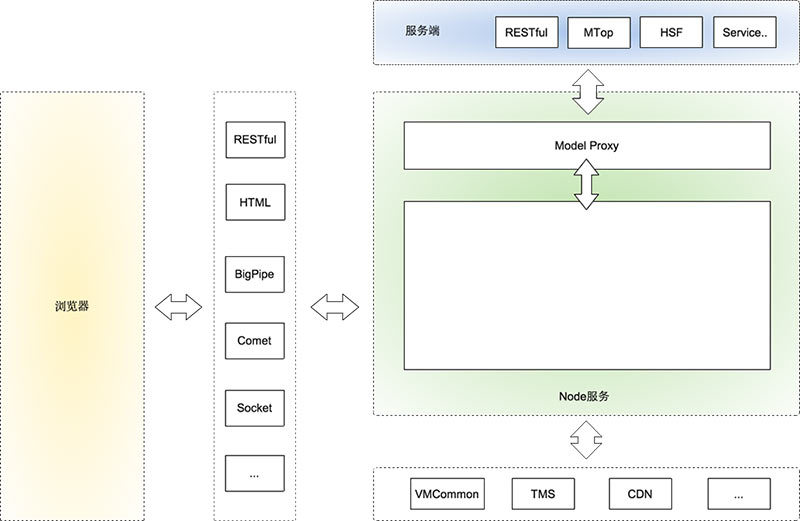
图3
上图是我理解的淘宝基于Node的前后端分离分层,以及Node的职责范围。简单解释下:
- 最上端是服务端,就是我们常说的后端。后端对于我们来说,就是一个接口的集合,服务端提供各种各样的接口供我们使用。因为有Node层,也不用局限是什么形式的服务。对于后端开发来说,他们只用关心业务代码的接口实现。
- 服务端下面是Node应用。
- Node应用中有一层Model Proxy与服务端进行通讯。这一层主要目前是抹平我们对不同接口的调用方式,封装一些view层需要的Model。
- Node层还能轻松实现原来vmcommon,tms(引用淘宝内容管理系统)等需求。
- Node层要使用什么框架由开发者自己决定。不过推荐使用express+xTemplate的组合,xTemplate能做到前后端公用。
- 怎么用Node大家自己决定,但是令人兴奋的是,我们终于可以使用Node轻松实现我们想要的输出方式:JSON/JSONP/RESTful/HTML/BigPipe/Comet/Socket/同步、异步,想怎么整就怎么整,完全根据你的场景决定。
- 浏览器层在我们这个架构中没有变化,也不希望因为引入Node改变你以前在浏览器中开发的认知。
- 引入Node,只是把本该就前端控制的部分交由前端掌控。
这种模式我们已经有两个项目在开发中,虽然还没上线,但是无论是在开发效率,还是在性能优化方面,我们都已经尝到了甜头。
五、我们还需要要做什么?
- 把Node的开发流程集成到淘宝现有的SCM流程中。
- 基础设施建设,比如session,logger等通用模块。
- 最佳开发实践
- 线上成功案例
- 大家对Node前后端分离概念的认识
- 安全
- 性能
- …
技术上不会有太多需要去创新和研究的,已经有非常多现成的积累。其实关键是一些流程的打通和通用解决方案的积累,相信随着更多的项目实践,这块慢慢会变成一个稳定的流程。
六、“中途岛”
虽然“基于NodeJS的全栈式开发”模式很让人兴奋,但是把基于Node的全栈开发变成一个稳定,让大家都能接受的东西还有很多路要走,我们正在进行的“中途岛”项目就是为了解决这个问题。虽然我们起步不久,但是离目标已经越来越近!!
基于前后端分离的模版探索
前言
在做前后端分离时,第一个关注到的问题就是渲染,也就是 View 这个层面的工作。
在传统的开发模式中,浏览器端与服务器端是由不同的前后端两个团队开发,但是模版却又在这两者中间的模糊地带。因此模版上面总不可避免的越来越多复杂逻辑,最终难以维护。
而我们选择了NodeJS,作为一个前后端的中间层。试图藉由NodeJS,来疏理 View 层面的工作。
使得前后端分工更明确,让专案更好维护,达成更好的用户体验。
本文
渲染这块工作,对于前端开发者的日常工作来说,佔了非常大的比例,也是最容易与后端开发纠结不清的地方。
回首过去前端技术发展的这几年, View 这个层面的工作,经过了许多次的变革,像是:
- Form Submit 全页刷新 => AJAX局部刷新
- 服务端续染 + MVC => 客户端渲染 + MVC
- 传统换页跳转 => 单页面应用
可以观察到在这几年,大家都倾向将渲染这件事,从服务器端端移向了浏览器端。
而服务器端则专注于服务化 ,提供数据接口。
浏览器端渲染的好处
浏览器端渲染的好处,我们都很清楚,像是
- 摆脱业务逻辑与呈现逻辑在Java模版引擎中的耦合与混乱。
- 针对多终端应用,更容易以接口化的形式。在浏览器端搭配不同的模版,呈现不同的应用。
- 页面呈现本来就不仅是html,在前端的渲染可以更轻易的以组件化形式 (html + js + css)提供功能,使得前端组件不需依赖于服务端产生的html结构。
- 脱离对于后端开发、发佈流程的依赖。
- 方便联调。
浏览器端渲染造成的坏处
但是在享受好处的同时,我们同样的也面临了浏览器端渲染所带来的坏处,像是:
- 模版分离在不同的库。有的模版放在服务端 (JAVA),而有的放在浏览器端 (JS)。前后端模版语言不相通。
- 需要等待所有模版与组件在浏览器端载入完成后才能开始渲染,无法即开即看。
- 首次进入会有白屏等待渲染的时间,不利于用户体验
- 开发单页面应用时,前端Route与服务器端Route不匹配,处理起来很麻烦。
- 重要内容都在前端组装,不利于SEO
反思前后端的定义
其实回头想想,在我们把渲染的工作从服务端(Java) 抽出来放到浏览器端(js) 的时候,我们的目的只是明确的前后端职责划分,并不是非浏览器渲染不可 。
只是因为在传统的开发模式中,出了服务器就到了浏览器,所以前端的工作内容只能被限制在浏览器端。
也因此很多人认定了后端 = 服务端,前端 = 浏览器端 ,就像下面这张图。
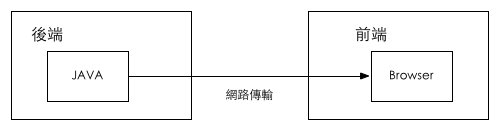
图4
而在淘宝UED目前进行的 中途岛Midway 项目中,藉由在 JAVA – Browser中间搭建一个NodeJS中间层,试图把这个前后端的分割线,重新针对工作职责 去区分,而分针对硬体环境去区分(服务器 & 浏览器)。
因此我们有机会做到模版与路由的共享,也是一个前后端分工中最理想的状态。
淘宝中途岛 Midway
在中途岛项目中,我们把前后端分界的那条线,从浏览器端移回到了服务器端。
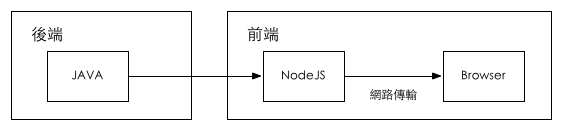
图5
藉由一个由前端 轻松掌控 且 与浏览器共通 的Nodejs层,可以更清晰的完成了前后端分离。
也可以让前端开发针对不同的情况,自行决定 最适当的解决方案 。而不是所有事情 都在浏览器端来处理 。
职责划分
中途岛并不是前端试图抢后端饭碗的项目,目的只是把 模版 这个模糊地带切割清楚,取得更明确的职责划分。
- 后端 (JAVA),专注于
- 服务层
- 数据格式、数据稳定
- 业务逻辑
- 前端,专注于
- UI层
- 控只逻辑、渲染逻辑
- 交互、用户体验
而不再拘泥于服务端或浏览器端的差异。
模版共享
在传统的开发模式中,浏览器端与服务器端是由不同的前后端两个团队开发,但是模版却又在这两者中间的模糊地带。因此模版上面总不可避免的越来越多复杂逻辑,最终难以维护。
有了NodeJS,后端同学可以在JAVA层专注于业务逻辑与数据的开发。而前端同学则专注于控制逻辑与渲染的开发。并且自行选择这些模版是要在 服务端 (NodeJS) 或是 浏览器端 做渲染。
用著一样的模版语言 XTemplate ,一样的渲染引擎 JavaScript
在 不同的渲染环境 (Server-side、PC Browser、Mobile Browser、Web View、etc.) 渲染出一样的结果 。
路由共享
也因为有了NodeJS这一层,可以更细致的控制路由。
假如需要在前端做浏览器端路由时,可以同时配置服务器端的路由,使其在 浏览器端换页 或是 服务端换页 ,都可以得到一致的渲染效果。
同时也处理了SEO的问题。
模版共享的实践
通常我们在浏览器端渲染一份模版时,流程不外乎是
- 在浏览器端載入模版引擎 (xtmpleate, juicer, handlerbar, etc.)
- 在浏览器端载入模版档案,方法可能有
- 使用
<script type="js/tpl"> ... </script>印在页面上 - 使用模块载入工具,载入模版档案 (KISSY, requireJS, etc.)
- 其他
- 使用
- 取得数据,使用模版引擎产生html
- 将html插入到指定位置。
從以上的流程可以觀察到,要想要做到模版的跨端共享,重点其实在 一致的模块选型 这件事。
市面上流行很多种模块标准,例如 KMD、AMD、CommonJS,只要能将NodeJS的模版档案透过一致模块规范输出到NodeJS端,就可以做基本的模版共享了。
而后续的系列文章会针对Model的proxy与共享,做进一步的探讨。
案例探讨
因为有了中途岛这中间层,针对过往的一些问题都有了更好的解答,例如说
案例一 复杂交互应用 (如购物车、下单页面)
- 状况:全部的HTML都是在前端渲染完成,服务端仅提供接口。
- 问题:进入页面时,会有短暂白屏。
- 解答:
- 首次进入页面,在NodeJS端进行 全页渲染 ,并在背景下载相关的模版。
- 后续交互操作,在浏览器端完成 局部刷新
- 用的是 同一份模版 , 产生 一样的结果
案例二 单页面应用
- 状况:使用Client Side MVC框架,在浏览器换页。
- 问题:渲染与换页都在浏览器端完成,直接输入网址进入或f5刷新时,无法直接呈现同样的内容。
- 解答:
- 在浏览器端与NodeJS端共享 同样的Route 设定
- 浏览器端换页时,在浏览器端进行Route变更与 页面内容渲染
- 直接输入同样的网址时,在NodeJS端进行 页面框架 + 页面内容渲染
- 不管是浏览器端换页,或直接输入同样的网址,看到的内容都是 一样的 。
- 除了增加体验、减少逻辑複杂度外。更解决了 SEO 的问题
案例三 纯浏览型页面
- 状况:页面仅提供资讯,较少或没有交互
- 问题:html在服务端产生,css与js放在另外一个位置,彼此间有依赖。
- 解答:
- 透过NodeJS,统一管理html + css + js
- 日后若需要扩展成复杂应用或是单页面应用,也可以轻易转移。
案例四 跨终端页面
- 状况:同样的应用要在不同端点呈现不同的介面与交互
- 问题:html管理不易,常常会在服务端产生不一样的html,浏览器端又要做不一样的处理
- 解答:
- 跨终端的页面是渲染的问题,统一由前端来处理。
- 透过NodeJS层与后端服务化,可以针对这类型复杂应用,设计最佳的解决方案。
总结
过去的AJAX、Client-side MVC、SPA、Two-way Data Binding 等技术的出现,都是试图要解决当时的前端开发遇到的瓶颈。
而NodeJS中间层的出现,也是在试图解决现今前端被侷限在浏览器端的一个限制。
这边文章专注于前后端模版共享,也希望能抛砖引玉,与大家一起讨论如何在NodeJS中间层这个架构下,我们可以怎样的改善我们的工作流程,怎样的跟 后端配合,来把 前端 这个工作做得更好。
Midway-ModelProxy — 轻量级的接口配置建模框架
前言
使用Node做前后端分离的开发模式带来了一些性能及开发流程上的优势(见《前后端分离的思考与实践 一》), 但同时也面临不少挑战。在淘宝复杂的业务及技术架构下,后端必须依赖Java搭建基础架构,同时提供相关业务接口供前端使用。Node在整个环境中最重要的工作之一就是代理这些业务接口,以方便前端(Node端和浏览器端)整合数据做页面渲染。如何做好代理工作,使得前后端开发分离之后,仍然可以在流程上无缝衔接,是我们需要考虑的问题。本文将就该问题做相关探讨,并提出解决方案。
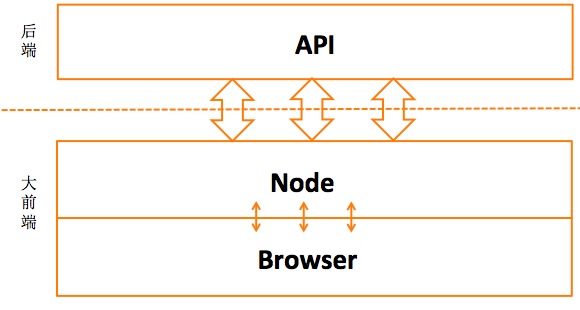
图6
由于后端提供的接口方式可能多种多样,同时开发人员在编写Node端代码访问这些接口的方式也有可能多种多样。如果我们在接口访问方式及使用上不做统一架构处理,则会带来以下一些问题:
2. 每一个开发人员编写自己的mock数据方式,开发完毕之后,需要手工修改代码移除mock。
3. 每一个开发人员为了实现接口的不同环境切换(日常,预发,线上),可能各自维护了一些配置文件。
4. 数据接口调用方式无法被各个业务model非常方便地复用。
5. 对于数据接口的描述约定散落在代码的各个角落,有可能跟后端人员约定的接口文档不一致。
6. 整个项目分离开发之后,对于接口的联调或者测试回归成本依然很高,需要涉及到每一个接口提供者和使用者。
于是我们希望有这样一个框架,通过该框架提供的机制去描述工程项目中依赖的所有外部接口,对他们进行统一管理,同时提供灵活的接口建模及调用方式,并且提供便捷的线上环境和生产环境切换方法,使前后端开发无缝结合。ModelProxy就是满足这样要求的轻量级框架,它是Midway Framework 核心构件之一,也可以单独使用。使用ModelProxy可以带来如下优点:
2. 框架内部采用工厂+单例模式,实现接口一次配置多次复用。并且开发者可以随意定制组装自己的业务Model(依赖注入)。
3. 可以非常方便地实现线上,日常,预发环境的切换。
4. 内置 river-mock和 mockjs等mock引擎,提供mock数据非常方便。
5. 使用接口配置文件,对接口的依赖描述做统一的管理,避免散落在各个代码之中。
6. 支持浏览器端共享Model,浏览器端可以使用它做前端数据渲染。整个代理过程对浏览器透明。
7. 接口配置文件本身是结构化的描述文档,可以使用 river工具集合,自动生成文档。也可使用它做相关自动化接口测试,使整个开发过程形成一个闭环。
ModelProxy工作原理图及相关开发过程图览
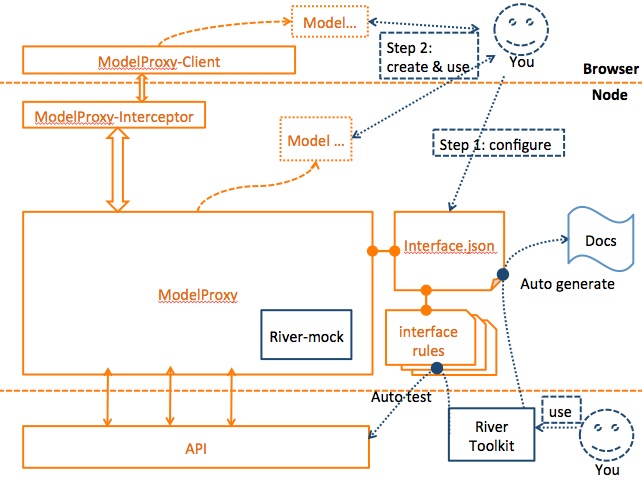
图7
在上图中,开发者首先需要将工程项目中所有依赖的后端接口描述,按照指定的json格式,写入interface.json配置文件。必要时,需要对每个接口编写一个规则文件,也即图中interface rules部分。该规则文件用于在开发阶段mock数据或者在联调阶段使用River工具集去验证接口。规则文件的内容取决于采用哪一种mock引擎(比如 mockjs, river-mock 等等)。配置完成之后,即可在代码中按照自己的需求创建自己的业务model。
下面是一个简单的例子:
【例一】
- 第一步 在工程目录中创建接口配置文件interface.json, 并在其中添加主搜接口json定义
- 第二步 在代码中创建并使用model
ModelProxy的功能丰富性在于它支持各种形式的profile以创建需要业务model:
- 使用接口ID创建>生成的对象会取ID最后’.'号后面的单词作为方法名
- 使用键值JSON对象>自定义方法名: 接口ID
- 使用数组形式>取最后 . 号后面的单词作为方法名
下例中生成的方法调用名依次为: Cart_getItem, getItem, suggest, getName
- 前缀形式>所有满足前缀的接口ID会被引入对象,并取其后半部分作为方法名
同时,使用这些Model,你可以很轻易地实现合并请求或者依赖请求,并做相关模板渲染
【例二】 合并请求
【例三】 依赖请求
此外ModelProxy不仅在Node端可以使用,也可以在浏览器端使用。只需要在页面中引入官方包提供的modelproxy-client.js即可。
【例四】浏览器端使用ModelProxy
同时,ModelProxy可以配合Midway另一核心组件Midway-XTPL一起使用,实现数据和模板以及相关渲染过程在浏览器端和服务器端的全共享。关于ModelProxy的详细教程及文档请移步https://github.com/purejs/modelproxy
总结
ModelProxy以一种配置化的轻量级框架存在,提供友好的接口model组装及使用方式,同时很好的解决前后端开发模式分离中的接口使用规范问题。在整个项目开发过程中,接口始终只需要定义描述一次,前端开发人员即可引用,同时使用River工具自动生成文档,形成与后端开发人员的契约,并做相关自动化测试,极大地优化了整个软件工程开发过程。














 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









