







如何设计一个通用的通知机制
通知分类
- 以发送通知和接收通知的对象来区分的话大致可以分为用户对用户也就是用户事件触发(包含各种社交通知如点赞,关注等)、系统对用户(如财务通知等)、管理员触发三大类
- 如果以通知方式进行区分可以分为:站内信、公司内 IM 工具如 lark、钉钉等、 SMS、EMAIL 这几种方式
通知优先级
- 既然已经有了通知的分类,此时也就有了通知的优先级,比如涉及到财产的一般认为是优先推送的。
- 基于 1 的优先级,通知方式的优先级同样有区分,再比如财务信息一般需要四种通知方式都涉及。
通知内容格式
通常有不同消息类型的模板,比如就站内信而言,用户的关注和点赞都是通用的多语言模板,其他通知方式亦然。
通知的广播范围
- 全员广播
- 特定组广播
- 特定人广播
通知处理
通知控制
- 权限控制:黑白名单过滤
- 频控:发送消息的频控以及用户接收的频控(或者可以理解为延迟消费)
- 内容审查
通知聚合
A 修改了 项目P,但是如果B又修改了项目P,组内用户如果再收到一条通知,B修改了项目P,用户就会收到垃圾消息,因此需要聚合为:A 和 B 修改了项目 P,更多比如推特「xx 和 xx 点赞了你的推文」等。
用户行为
如确认,回复,忽略,删除或者已读、未读状态的变更。
技术实现
整体方案:采用消息队列
关于采用消息队列的一些关键技术点:
- 消费幂等:即解决重复消费问题
- 备注:消息队列无法保证消费幂等,可以使用 redis 做锁来保证。
- 中断消费:主要应用于中断大规模群发消息
- 备注:上一条提到可以用 redis 做锁,那么这里中断消息时即可以提前将消息的 id 扔入 redis 中,这样就可以避免消费某条消息。
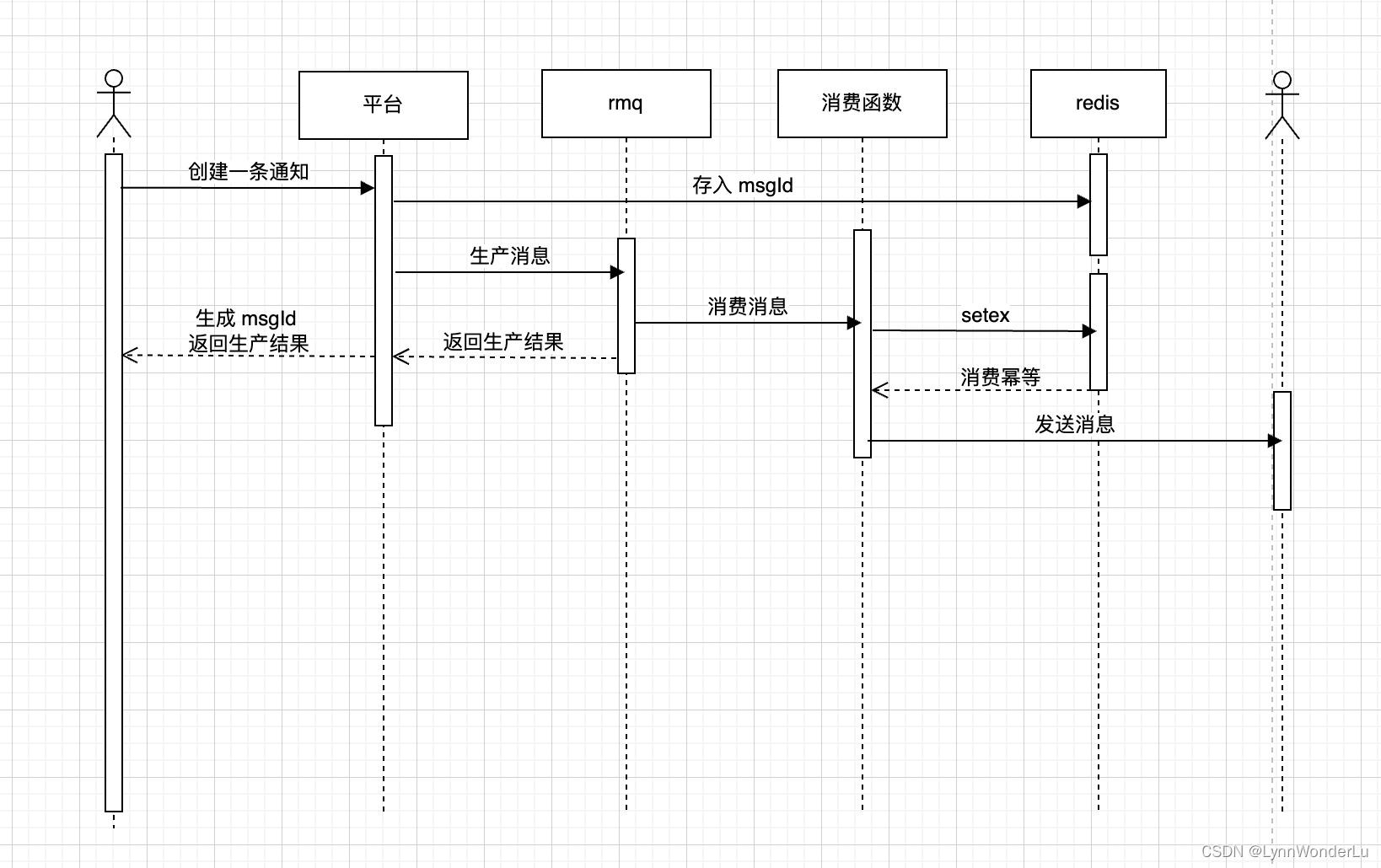
关于站内信
维护两张表:msg 和 userMsg
-
对于非全员信息,写入 msg 同时写入 userMsg,以 msgId 进行关联
-
对于全员信息,只写入 msg,在前端具体用户拉取的时候才存入 userMsg,再进行联表查询。(这是一种很高效的方案,避免了一次将所有通知写入 userMsg,msg 表也只是写入一条数据)
压测
- 其实在展开讲具体技术实现之前应该明白我们为什么要进行压测?
- 网站压测方法使用多线程技术,模仿很多用户同时访问服务器的情形,同时向服务器发出浏览清求,并监测服务器的反应。通过测试得到存放网页的服务器能够支持的最大用户数,从而助开发人员掌握在经历了一次大的访问量的增长后,服务器是否还能够正常提供服务。
基于以上,对于发送全员通知或者多 subscriber 同时发送的场景,必须要提前做好压测。
- 既然确定了要进行压测,那么我们要测什么,有哪些指标是我们真正关注的?
- producer 吞吐量
- consumer 吞吐量
- 消息完整性
- 消息积压状况
一般互联网公司会提供压测平台,此时根据压测平台的设置进行压测即可。而有时公司的此平台只能测试线上环境,因此也有一些其他的方式来实现压测
- 有哪些便捷压测方法?
- 公司已有的压测平台
- 使用 ab: Apache Benchmark(简称ab) 是Apache安装包中自带的压力测试工具 (mac 无需安装且使用 ab -h 即可查看相关命令)

















 6252
6252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









