







 超级会员免费看
超级会员免费看
 在科研文献计量中,数据清洗是关键步骤,尤其是处理Scopus数据库下载的数据时。本文介绍两种方法:1) 使用pybibx库处理bibx文件,2) 直接处理纯文本数据,来剔除作者为'UNKNOWN'的文献。通过示例代码展示如何实现并验证数据清洗效果,确保数据的准确性和可用性。
在科研文献计量中,数据清洗是关键步骤,尤其是处理Scopus数据库下载的数据时。本文介绍两种方法:1) 使用pybibx库处理bibx文件,2) 直接处理纯文本数据,来剔除作者为'UNKNOWN'的文献。通过示例代码展示如何实现并验证数据清洗效果,确保数据的准确性和可用性。
剔除来自unknown的机构与作者文献文献——数据清洗
背景
有时在研究过程中,会遇到不同类型的文献,但是有些文献中的数据会有部分缺失,常见的比如机构,作者和年份等字段,因此为了使用科研工具进行有效的文献计量,数据清洗就显着十分重要
实例
以Scopus数据库下载的数据为例,这里使用pybibx论文提供的数据集,其中是没有数据确实。构造缺失数据集,这里就是将前两条文献中的作者Author字段原来内容替换为UNKOWN(为了保证原始数据的准确性,建议备份一份文件操作),如下。
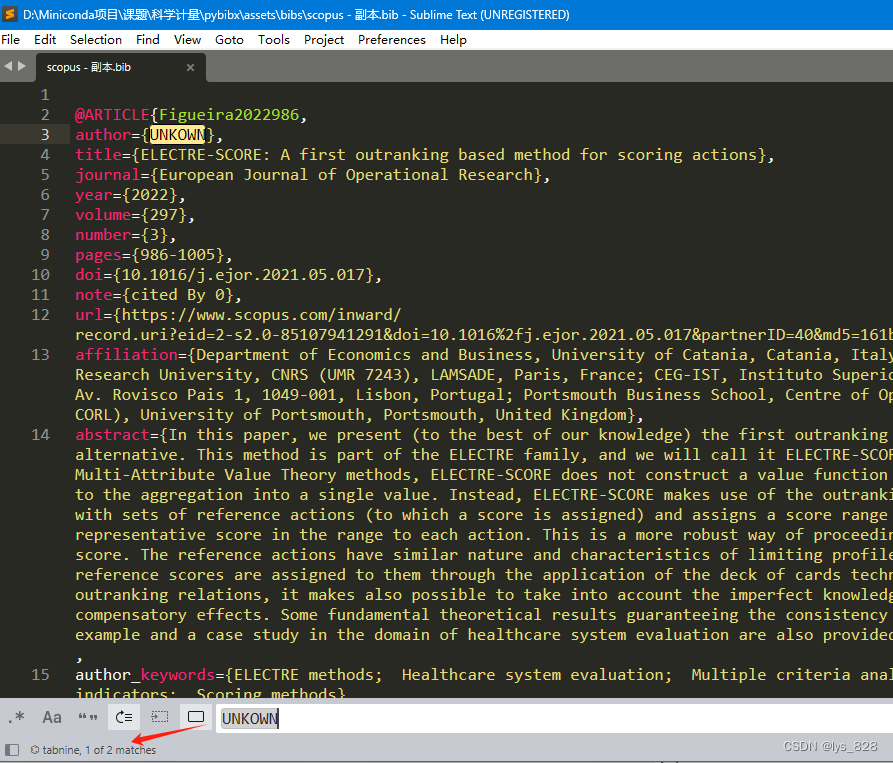
打开python软件,导入相关的库,对数据进行加载
# 加载第三方库
import numpy as np
import pandas 
 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











