






From:http://blog.csdn.net/u010977122/article/details/52958330
From:http://blog.163.com/xychenbaihu@yeah/blog/static/13222965520101023104745738/
linux下动态与静态链接库的使用及区别:http://blog.csdn.net/shreck66/article/details/49583057
Linux下动态库(.so)和静态库(.a):http://blog.csdn.net/felixit0120/article/details/7652907
http://www.latelee.org/programming-under-linux/library-on-linux.html
从源代码到可执行代码
今天我们主要来说说Linux系统下基于动态库(.so)和静态(.a)的程序那些猫腻。在这之前,我们需要了解一下源代码到可执行程序之间到底发生了什么神奇而美妙的事情。
在linux操作系统中,普遍使用ELF格式作为可执行程序或者程序生成过程中的中间格式。ELF(Executable and Linking Format,可执行连接格式)是UNIX系统实验室(USL)作为应用程序二进制接口(Application BinaryInterface,ABI)而开发和发布的。工具接口标准委员会(TIS)选择了正在发展中的ELF标准作为工作在32位Intel体系上不同操作系统之间可移植的二进制文件格式。本文不对ELF文件格式及其组成做太多解释,以免冲淡本文的主题,大家只要知道这么个概念就行。以后再详解Linux中的ELF格式。源代码到可执行程序的转换时需要经历如下图所示的过程:


编译是指把用高级语言编写的程序转换成相应处理器的汇编语言程序的过程。从本质上讲,编译是一个文本转换的过程。对嵌入式系统而言,一般要把用C语言编写的程序转换成处理器的汇编代码。编译过程包含了c语言的语法解析和汇编码的生成两个步骤。编译一般是逐个文件进行的,对于每一个C语言编写的文件,可能还需要进行预处理。
汇编是从汇编语言程序生成目标系统的二进制代码(机器代码)的过程。机器代码的生成和处理器有密切的联系。相对于编译过程的语法解析,汇编的过程相对简单。这是因为对于一款特定的处理器,其汇编语言和二进制的机器代码是一一对应的。汇编过程的输入是汇编代码,这个汇编代码可能来源于编译过程的输出,也可以是直接用汇编语言书写的程序。
连接是指将汇编生成的多段机器代码组合成一个可执行程序。一般来说,通过编译和汇编过程,每一个源文件将生成一个目标文件。连接器的作用就是将这些目标文件组合起来,组合的过程包括了代码段、数据段等部分的合并,以及添加相应的文件头。
GCC是Linux下主要的程序生成工具,它除了编译器、汇编器、连接器外,还包括一些辅助工具。在下面的分析过程中我会教大家这些工具的基本使用方法,Linux的强大之处在于,对于不太懂的命令或函数,有一个很强大的“男人”时刻stand by your side,有什么不会的就去命令行终端输入:man [命令名或函数名] 。
对于最后编译出来的可执行程序,当我们执行它的时候,操作系统又是如何反应的呢?我们先从宏观上来个总体把握,如图2所示:

作为UNIX操作系统的一种,Linux的操作系统提供了一系列的接口,这些接口被称为系统调用(System Call)。在UNIX的理念中,系统调用"提供的是机制,而不是策略"。C语言的库函数通过调用系统调用来实现,库函数对上层提供了C语言库文件的接口。在应用程序层,通过调用C语言库函数和系统调用来实现功能。一般来说,应用程序大多使用C语言库函数实现其功能,较少使用系统调用。那么最后的可执行文件到底是什么样子呢?前面已经说过,这里我们不深入分析ELF文件的格式,只是给出它的一个结构图和一些简单的说明,以方便大家理解。ELF文件格式包括三种主要的类型:可执行文件、可重定向文件、共享库。
- 可执行文件(应用程序)。可执行文件包含了代码和数据,是可以直接运行的程序。
- 可重定向文件(*.o)。可重定向文件又称为目标文件,它包含了代码和数据(这些数据是和其他重定位文件和共享的object文件一起连接时使用的)。 *.o文件参与程序的连接(创建一个程序)和程序的执行(运行一个程序),它提供了一个方便有效的方法来用并行的视角看待文件的内容,这些*.o文件的活动可以反映出不同的需要。
Linux下,我们可以用gcc -c编译源文件时可将其编译成*.o格式。 - 共享文件(*.so)。也称为动态库文件,它包含了代码和数据(这些数据是在连接时候被连接器ld和运行时动态连接器使用的)。动态连接器可能称为ld.so.1,libc.so.1或者 ld-linux.so.1。我的CentOS6.0系统中该文件为:/lib/ld-2.12.so
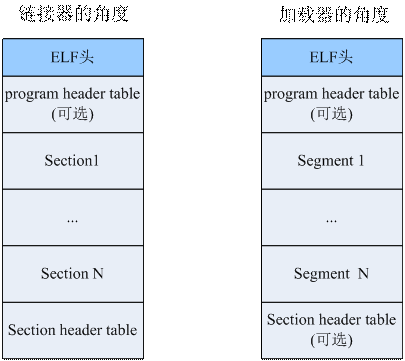
一个ELF文件从连接器(Linker)的角度看,是一些节的集合;从程序加载器(Loader)的角度看,它是一些段(Segments)的集合。ELF格式的程序和共享库具有相同的结构,只是段的集合和节的集合上有些不同。
那么到底什么是库呢?
库从本质上来说是一种可执行代码的二进制格式,可以被载入内存中执行。库分静态库和动态库两种。
静态库:这类库的名字一般是 libxxx.a,xxx为库的名字。利用静态函数库编译成的文件比较大,因为整个函数库的所有数据都会被整合进目标代码中,他的优点就显而易见了,即编译后的执行程序不需要外部的函数库支持,因为所有使用的函数都已经被编译进去了。当然这也会成为他的缺点,因为如果静态函数库改变了,那么你的程序必须重新编译。
动态库:这类库的名字一般是libxxx.M.N.so,同样的xxx为库的名字,M是库的主版本号,N是库的副版本号。当然也可以不要版本号,但名字必须有。相对于静态函数库,动态函数库在编译的时候并没有被编译进目标代码中,你的程序执行到相关函数时才调用该函数库里的相应函数,因此动态函数库所产生的可执行文件比较小。由于函数库没有被整合进你的程序,而是程序运行时动态的申请并调用,所以程序的运行环境中必须提供相应的库。动态函数库的改变并不影响你的程序,所以动态函数库的升级比较方便。linux系统有几个重要的目录存放相应的函数库,如/lib /usr/lib。
库文件的命名
在 linux 下,库文件一般放在/usr/lib和/lib下,
静态库的名字一般为 libxxxx.a,其中 xxxx 是该lib的名称;
动态库的名字一般为 libxxxx.so.major.minor,xxxx 是该lib的名称,major是主版本号,minor是副版本号
当要使用静态的程序库时,连接器会找出程序所需的函数,然后将它们拷贝到执行文件,由于这种拷贝是完整的,所以一旦连接成功,静态程序库也就不再需要了。然而,对动态库而言,就不是这样。动态库会在执行程序内留下一个标记指明当程序执行时,首先必须载入这个库。由于动态库节省空间,linux下进行连接的缺省操作是首先连接动态库,也就是说,如果同时存在静态和动态库,不特别指定的话,将与动态库相连接。
Linux 下标准库链接的三种方式(全静态 , 半静态 (libgcc,libstdc++), 全动态)
三种标准库链接方式的选项及区别
| 标准库连接方式 | 示例连接选项 | 优点 | 缺点 |
|---|---|---|---|
| 全静态 | -static -pthread -lrt -ldl | 不会发生应用程序在 不同 Linux 版本下的标准库不兼容问题。 | 生成的文件比较大, 应用程序功能受限(不能调用动态库等) |
| 全动态 | -pthread -lrt -ldl | 生成文件是三者中最小的 | 比较容易发生应用程序在 不同 Linux 版本下标准库依赖不兼容问题。 |
| 半静态 (libgcc,libstdc++) | -static-libgcc -L. -pthread -lrt -ldl | 灵活度大,能够针对不同的标准库采取不同的链接策略, 从而避免不兼容问题发生。 结合了全静态与全动态两种链接方式的优点。 | 比较难识别哪些库容易发生不兼容问题, 目前只有依靠经验积累。 某些功能会因选择的标准库版本而丧失。 |
上述三种标准库链接方式中,比较特殊的是 半静态链接方式。
如何判断一个程序有没有链接动态库?
file命令、ldd命令
(1)file命令。file程序是用来判断文件类型的,啥文件一看都清楚明了。
(2)ldd命令。使用ldd命令来查看程序都依赖哪些动态库。如果目标程序没有链接动态库,则打印“not a dynamic executable” (不是动态可执行文件)
obj文件的格式和组成可能是系统差异性的一大体现,比如windows下的PE、linux和一些unix下的elf、macos的mach-o、aix下的xcoff。
查看obj文件的符号表信息,可以通过nm objdump readelf等方法。
Linux下库文件是如何产生的?
静态库
(1)静态库。静态库的后缀是.a 文件,它的产生分两步
Step 1: 由源文件编译生成一堆.o 文件,每个.o 文件里都包含这个编译单元的符号表
Step 2: ar命令 将很多.o转换成.a,即生成的静态库
静态库的制作和使用


动态库
(2)动态库。动态库的后缀是.so,它由gcc加特定参数编译产生。
动态库的后缀为.so,一般存放在/lib, /usr/lib等目录下,可以使用ldd命令来查看一个可执行程序使用了哪些动态库。

动态库是由操作系统运行程序时调用的,既然是程序,那按照Linux的风格,肯定有对应的配置文件来设置。动态链接库的配置文件位于/etc/ld.so.conf,具体内容如下:

从上图可以知道,系统搜索动态链接库的路径位于特定的目录。Linux系统为了提高动态链接库的运行性能,把一些常用的动态链接库放在/etc/ld.so.cache这个文件中去。如何更新这个动态链接库的缓存文件呢?Linux提供了ldconfig命令来更新,这个命令主要搜索/lib和/usr/lib以及配置文件ld.so.conf.d/目录下的可用的动态链接库文件,然后重新创建新的动态链接程序/lib/ld-linux.so.2所需的连接和更新动态链接库缓存文件ld.so.cache.
ldconfig –p | head or grep XX : 查看系统中有哪些动态链接库ldconfig –v 输出动态链接库扫描目录并且刷新ld.so.cache缓存执行ldconfig需要root权限。
LD_LIBRARY_PATH:这个环境变量指示动态连接器可以装载动态库的路径。
当然如果有root权限的话,可以修改/etc/ld.so.conf文件,然后调用 /sbin/ldconfig来达到同样的目的,
不过如果没有root权限,那么只能采用修改LD_LIBRARY_PATH环境变量的方法了。
静态链接库 和 动态连接库 的环境变量
LIBRARY_PATH环境变量:指定程序静态链接库文件搜索路径LD_LIBRARY_PATH环境变量:指定程序动态链接库文件搜索路径
静态库,动态库文件在linux下是如何生成的:
以下面的代码为例,生成上面用到的hello库:
/* hello.c */
#include "hello.h"
void sayhello()
{
printf("hello,world ");
}
首先用gcc编绎该文件,在编绎时可以使用任何合法的编绎参数,例如-g加入调试代码等:
gcc -c hello.c -o hello.o
1、生成静态库 生成静态库使用ar工具,其实ar是archive的意思
ar cqs libhello.a hello.o
2、生成动态库 用gcc来完成,由于可能存在多个版本,因此通常指定版本号:
gcc -shared -o libhello.so.1.0 hello.o
可执行程序在执行的时候如何定位共享库(动态库)文件
当系统加载可执行代码(即库文件)的时候, 能够知道其所依赖的库的名字,但是还需要知道绝对路径,此时就需要系统动态载入器(dynamic linker/loader)。
对于 elf 格式的可执行程序,是由 ld-linux.so* 来完成的,它先后搜索 elf 文件的DT_RPATH 段-->环境变量LD_LIBRARY_PATH—->/etc/ld.so.cache 文件列表--> /lib/,/usr/lib 目录找到库文件后将其载入内存
如: export LD_LIBRARY_PATH=`pwd` 将当前文件目录添加为共享目录。( 反引号 就是 键盘上 esc 按键下面的那个符号)
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:`pwd` //最好使用这条命令
使用ldd工具,查看可执行程序依赖那些动态库或着动态库依赖于那些动态库:
ldd 命令可以查看一个可执行程序依赖的共享库,
例如 # ldd /bin/lnlibc.so.6
=> /lib/libc.so.6 (0×40021000)/lib/ld-linux.so.2
=> /lib/ld- linux.so.2 (0×40000000)
可以看到 ln 命令依赖于 libc 库和 ld-linux 库
使用nm工具,查看静态库和动态库中有那些函数名;
(T类表示函数是当前库中定义的,U类表示函数是被调用的,在其它库中定义的,W类是当前库中定义,被其它库中的函数覆盖)。:
有时候可能需要查看一个库中到底有哪些函数,nm工具可以打印出库中的涉及到的所有符号,这里的库既可以是静态的也可以是动态的。
nm列出的符号有很多, 常见的有三种::
T类:是在库中定义的函数,用T表示,这是最常见的;
U类:是 在库中被调用,但并没有在库中定义(表明需要其他库支持), 用U表示;W类:是所谓的“弱态”符号,它们虽然在库中被定义,但是可能被其他库中的同名符号覆盖,用W表示。
例如,假设开发者希望知道上文提到的hello库中是否引用了 printf():
nm libhello.so | grep printf
发现printf是U类符号,说明printf被引用,但是并没有在库中定义。
由此可以推断,要正常使用hello库,必须有其它库支持,使用ldd工具查看hello依赖于哪些库:
ldd libhello.so
libc.so.6=>/lib/libc.so.6(0x400la000)
/lib/ld-linux.so.2=>/lib/ld-linux.so.2 (0x40000000)
从上面的结果可以继续查看printf最终在哪里被定义,有兴趣可以go on
使用ar工具,可以生成静态库,同时可以查看静态库中包含那些.o文件,即有那些源文件构成。
可以使用 ar -t libname.a 来查看一个静态库由那些.o文件构成。
可以使用 ar q libname.a xxx1.o xxx2.o xxx3.o ... xxxn.o 生成静态库
如何查看动态库和静态库是32位,还是64位下的库:
如果是动态库,可以使用file *.so;
如果是静态哭,可以使用objdump -x *.a
使用动态库和静态库
既然是动态链接库,那就是需要开发出来给其他人使用的。按照C语言的风格,h头文件提供函数库的接口说明,就像stdio.h头文件一样,我们用到的输入输出,都必须包含这个头文件。要使用我们自己的动态链接库,那就要包含动态链接库提供的头文件。

然后是编译生成动态链接库

使用动态链接库

OK,有了这些知识,接下来大家就可以弄明白我所做的事情是干什么了。都说例子是最好老师,我们就从例子入手。
静态链接库
我们先制作自己的静态链接库,然后再使用它。制作静态链接库的过程中要用到gcc和ar命令。
准备两个库的源码文件st1.c和st2.c,用它们来制作库libmytest.a,如下:
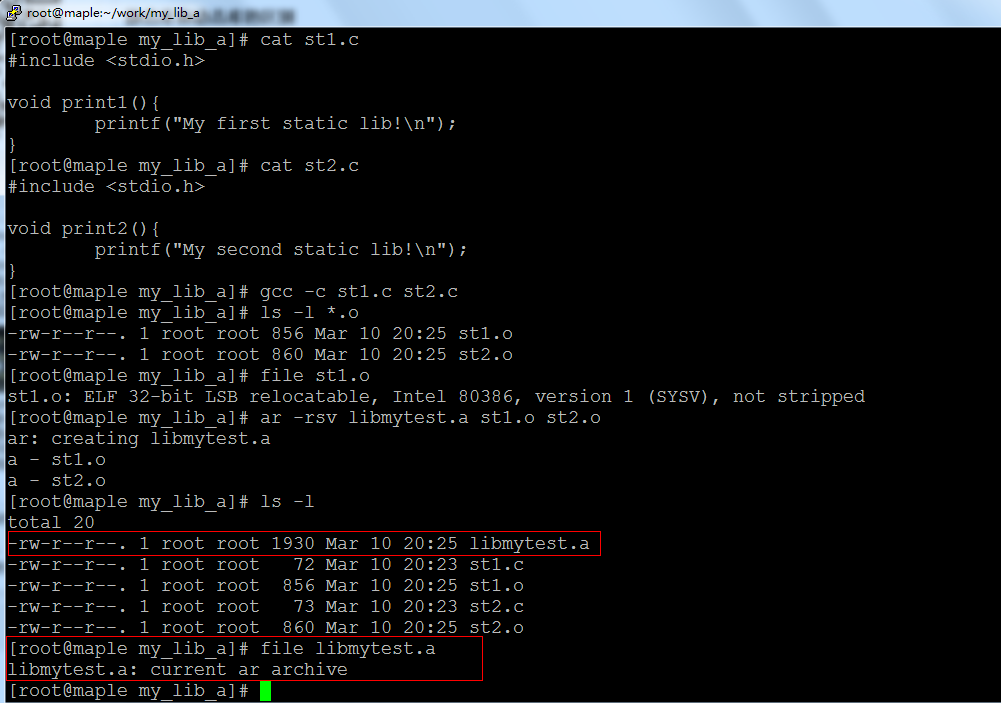
静态库文件libmytest.a已经生成,用file命令查看其属性,发现它确实是归档压缩文件。用ar -t libmytest.a可以查看一个静态库包含了那些obj文件:

接下来我们就写个测试程序来调用库libmytest.a中所提供的两个接口print1()和print2()。
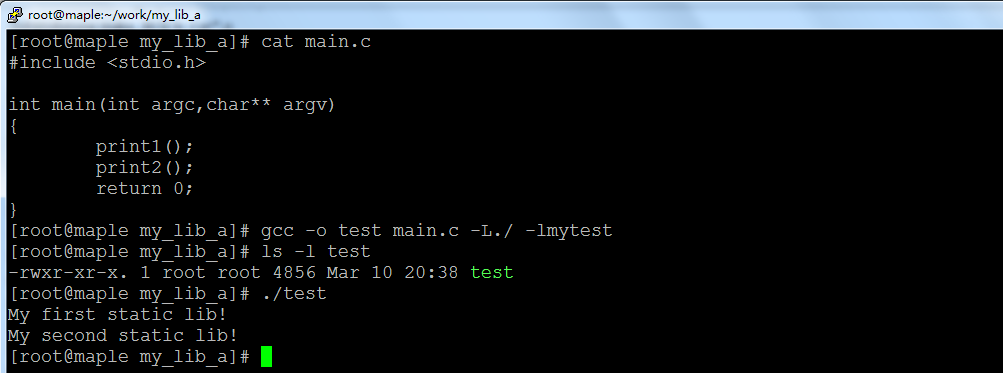
看到没,静态库的编写和调用就这么简单,学会了吧。这里gcc的参数-L是告诉编译器库文件的路径是当前目录,-l是告诉编译器要使用的库的名字叫mytest。
动态库
静态库*.a文件的存在主要是为了支持较老的a.out格式的可执行文件而存在的。目前用的最多的要数动态库了。
动态库的后缀为*.so。在Linux发行版中大多数的动态库基本都位于/usr/lib和/lib目录下。在开发和使用我们自己动态库之前,请容许我先落里罗嗦的跟大家唠叨唠叨Linux下和动态库相关的事儿吧。
有时候当我们的应用程序无法运行时,它会提示我们说它找不到什么样的库,或者哪个库的版本又不合它胃口了等等之类的话。
那么应用程序它是怎么知道需要哪些库的呢?
可以使用 ldd 命令来查看一个程序文件到底依赖了那些so库文件。
Linux系统中动态链接库的配置文件一般在/etc/ld.so.conf文件内,它里面存放的内容是可以被Linux共享的动态联库所在的目录的名字。我的系统中,该文件的内容如下:

然后/etc/ld.so.conf.d/目录下存放了很多*.conf文件,如下:

其中每个conf文件代表了一种应用的库配置内容,以MySQL为例:

如果您是和我一样装的CentOS6.0的系统,那么细心的读者可能会发现,在/etc目录下还存在一个名叫ld.so.cache的文件。从名字来看,我们知道它肯定是动态链接库的什么缓存文件。
对,您说的一点没错。为了使得动态链接库可以被系统使用,当我们修改了/etc/ld.so.conf或/etc/ld.so.conf.d/目录下的任何文件,或者往那些目录下拷贝了新的动态链接库文件时,都需要运行一个很重要的命令:ldconfig,该命令位于/sbin目录下,主要的用途就是负责搜索/lib和/usr/lib,以及配置文件/etc/ld.so.conf里所列的目录下搜索可用的动态链接库文件,然后创建出动态加载程序/lib/ld-linux.so.2所需要的连接和(默认)缓存文件/etc/ld.so.cache(此文件里保存着已经排好序的动态链接库名字列表)。
也就是说:当用户在某个目录下面创建或拷贝了一个动态链接库,若想使其被系统共享,可以执行一下"ldconfig目录名"这个命令。此命令的功能在于让ldconfig将指定目录下的动态链接库被系统共享起来,即:在缓存文件/etc/ld.so.cache中追加进指定目录下的共享库。请注意:如果此目录不在/lib,/usr/lib及/etc/ld.so.conf文件所列的目录里面,则再次单独运行ldconfig时,此目录下的动态链接库可能不被系统共享了。单独运行ldconfig时,它只会搜索/lib、/usr/lib以及在/etc/ld.so.conf文件里所列的目录,用它们来重建/etc/ld.so.cache。
因此,等会儿我们自己开发的共享库就可以将其拷贝到/lib、/etc/lib目录里,又或者修改/etc/ld.so.conf文件将我们自己的库路径添加到该文件中,再执行ldconfig命令。
非了老半天功夫,终于把基础打好了,猴急的您早已按耐不住激情的想动手尝试了吧!哈哈。。。OK,说整咱就开整,接下来我就带领大家一步一步来开发自己的动态库,然后教大家怎么去使用它。
我们有一个头文件my_so_test.h和三个源文件test_a.c、test_b.c和test_c.c,将他们制作成一个名为libtest.so的动态链接库文件:
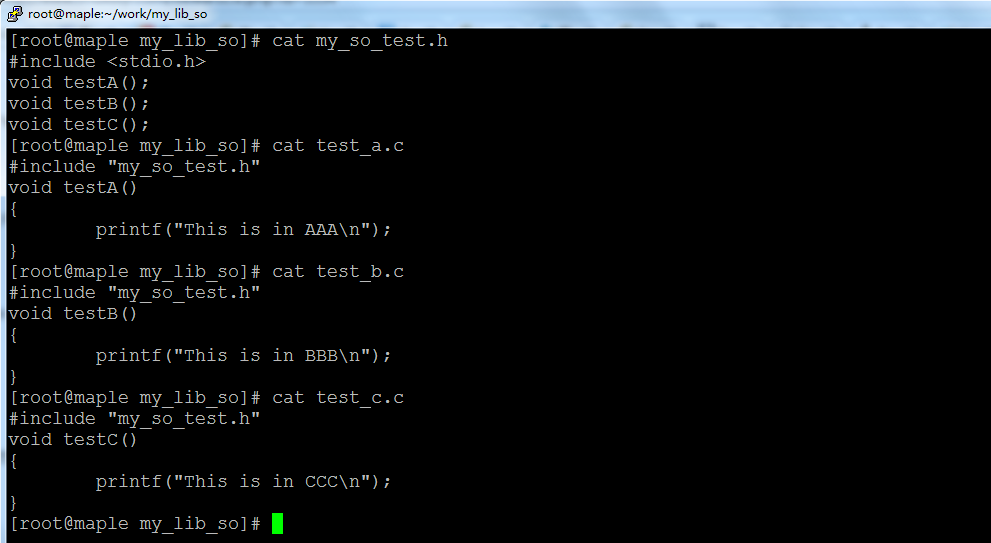
OK,万事俱备,只欠东风。如何将这些文件编译成一个我们所需要的so文件呢?可以分两步来完成,也可以一步到位:
方法一:
1、先生成目标.o文件:
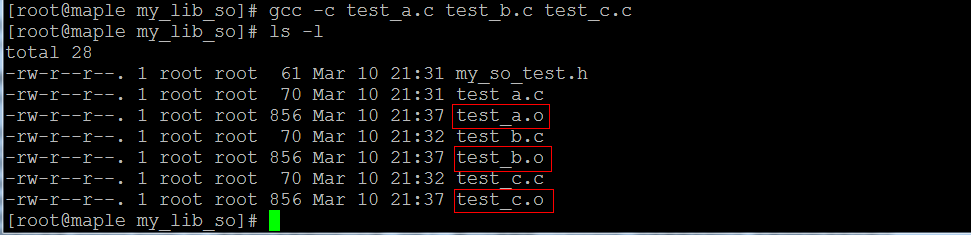
2、再生成so文件:

-shared该选项指定生成动态连接库(让连接器生成T类型的导出符号表,有时候也生成弱连接W类型的导出符号),不用该标志外部程序无法连接。相当于一个可执行文件。
-fPIC:表示编译为位置独立的代码,不用此选项的话编译后的代码是位置相关的,当动态载入时是通过代码拷贝的方式来满足不同进程的需要,而不能达到真正代码段共享的目的。
方法二:一步到位。

至此,我们制作的动态库文件libtest.so就算大功告成了。
接下来,就是如何使用这个动态库了。动态链接库的使用有两种方法:既可以在运行时对其进行动态链接,又可以动态加载在程序中是用它们。接下来,我就这两种方法分别对其介绍。
==================================================
方法1
1. 直接使用点c文件生成点so文件gcc -fpic -shared -o xxx.so *.c
2. 调用gcc -o mainapp main.c ./xxx.so
方法2 生成动态库(共享库)
1. 先生成与位置无关的 .O(小写o)文件. gcc –fpic -c *.c
(或者把所有的c文件都写出来,或者点c文件一个一个生成点o文件)
2. 再使用点o文件生成动态库 gcc –shared –o libmylib.so *.o
3. 使用库生成可执行文件 gcc main.c –o app –l mylib –L ./ -I ./
===================================================
+++动态库的使用+++
用法一:动态链接。

使用“-ltest”标记来告诉GCC驱动程序在连接阶段引用共享函数库libtest.so。“-L.”标记告诉GCC函数库可能位于当前目录。否则GNU连接器会查找标准系统函数目录。
这里我们注意,ldd的输出它说我们的libtest.so它没找到。还记得我在前面动态链接库一节刚开始时的那堆唠叨么,现在你应该很明白了为什么了吧。因为我们的libtest.so既不在/etc/ld.so.cache里,又不在/lib、/usr/lib或/etc/ld.so.conf所指定的任何一个目录中。怎么办?还用我告诉你?管你用啥办法,反正我用的 ldconfig `pwd`搞定的:

执行结果如下:

库环境变量设置
偶忍不住又要罗嗦一句了,相信俺,我的唠叨对大家是有好处。我为什么用这种方法呢?因为我是在给大家演示动态库的用法,完了之后我就把libtest.so给删了,然后再重构ld.so.cache,对我的系统不会任何影响。倘若我是开发一款软件,或者给自己的系统DIY一个非常有用的功能模块,那么我更倾向于将libtest.so拷贝到/lib、/usr/lib目录下,或者我还有可能在/usr/local/lib/目录下新建一文件夹xxx,将so库拷贝到那儿去,并在/etc/ld.so.conf.d/目录下新建一文件mytest.conf,内容只有一行“/usr/local/lib/xxx/libtest.so”,再执行ldconfig。如果你之前还是不明白怎么解决那个“not found”的问题,那么现在总该明白了吧。
其实原因就是:因为在动态函数库使用时,会查找/usr/lib、/lib目录下的动态函数库,而此时我们生成的库不在里边。
这个时候有好几种方法可以让他成功运行:
(LD_LIBRARY_PATH 就是 lib_dynamic_library_path 缩写,只不过都是大写。)(1)最直接最简单的方法就是把so拉到/usr/lib或/lib中去,但这好像有点污染环境吧?(2)export LD_LIBRARY_PATH=$(pwd) 或者 上面的 ldconfig `pwd`
或者 export LD_LIBRARY_PATH=/库的绝对路径
LD_LIBRARY_PATH变量中库的路径是以分号分割的。可以 echo $LD_LIBRARY_PATH 查看。
推荐使用 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:`pwd`
$ export LD_LIBRARY_PATH=.:$LD_LIBRARY_PATH // LD_LIBRARY_PATH只对当前终端有效,再启动一个终端无效
(3)可以在/etc/ld.so.conf文件里加入我们生成的库的目录,然后/sbin/ldconfig
运行期间查找动态库
运行期间,系统需要知道到哪里去查找动态库,这是通过/etc/ld.so.conf配置的。ldconfig用于配置运行时动态库查找路径,实际是更新/etc/ld.so.cache。另外一些环境变量也可以影响查找:(Linux/Solaris: LD_LIBRARY_PATH, SGI: LD_LIBRARYN32_PATH, AIX: LIBPATH, Mac OS X: DYLD_LIBRARY_PATH, HP-UX: SHLIB_PATH)
静态库链接时搜索路径顺序:
1. ld会去找GCC命令中的参数-L
2. 再找gcc的环境变量LIBRARY_PATH
3. 再找内定目录 /lib /usr/lib /usr/local/lib 这是当初compile gcc时写在程序内的
动态链接时、执行时搜索路径顺序:
1. 编译目标代码时指定的动态库搜索路径;2. 环境变量LD_LIBRARY_PATH指定的动态库搜索路径;3. 配置文件/etc/ld.so.conf中指定的动态库搜索路径;4. 默认的动态库搜索路径/lib;5. 默认的动态库搜索路径/usr/lib。gcc中链接 -lxxx库时,默认会从/lib/和/usr/lib这两个地方去找链接库,不需要额外设置,若需要加入其他链接库可以通过三种方式:1.在/etc/目录下有ld.so.conf、ld.so.cache和ld.so.conf.d/,其中ld.so.conf.d目录下又有多个*.conf的配置文件。在ld.so.conf文件中只有一句include /etc/ld.so.conf.d/*.conf,包含ld.so.conf.d目录下所有的配置文件,需要只需要将自己新增的链接库目录加入任何一个配置文件,或新建一个自己的配置文件。只修改配置文件还不行,因为为了提高搜索的效率,所以系统预先对所有配置文件生成了一个二进制的处理文件,也就是ld.so.cache,所以需要运行ldconfig手动更新这个文件。2.设置LD_LIBRARY_PATH参数,利用export $LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/xxx增加自己的库路径3. 在编译gcc参数时直接利用-L参数指明链接库路径这里插一句,有一次将/lib目录下的libc.so.6误删了,其实这一个软链接,指向的是实际的glibc库文件,本想将其指向一个版本更高的库文件,结果删除这个链接后发现所有的命令都不能执行,都依赖这个库文件,所以使用LD_PRELOAD=/lib/libc-2.6.1.so ln -s libc2.6.1.so libc.so.6.这里LD_PRELOAD就是预加载指定的库文件。关于LD_PRELOAD,后面链接还有一篇有意思的文章。示例操作(设置共享库加载路径)打开共享库路径配置文件:sudo vi /etc/ld.so.conf最后一行添加mycal路径:/home/username/calc更新共享库加载路径:sudo ldconfig -v此时可以看到自动创建出来了soname libcalc.so.1手动添加link name:ln -s libcalc.so.1.10 libcalc.so关于/etc/ld.so.conf/etc/ld.so.conf里面存放的是链接器和加载器搜索共享库时要检查的目录,默认是从/usr/lib /lib中读取的,所以想要顺利运行,我们也可以把我们库的目录加入到这个文件中并执行/sbin/ldconfig 。关于/etc/ld.so.cache/etc/ld.so.cache里面保存了常用的动态函数库,且会先把他们加载到内存中,因为内存的访问速度远远大于硬盘的访问速度,这样可以提高软件加载动态函数库的速度了。使用了第(2)种方法解决问题

方法二:动态加载。
动态加载是非常灵活的,它依赖于一套Linux提供的标准API来完成。在源程序里,你可以很自如的运用API来加载、使用、释放so库资源。以下函数在代码中使用需要包含头文件:dlfcn.h
| 函数原型 | 说明 |
| const char *dlerror(void) | 当动态链接库操作函数执行失败时,dlerror可以返回出错信息,返回值为NULL时表示操作函数执行成功。 |
| void *dlopen(const char *filename, int flag) | 用于打开指定名字(filename)的动态链接库,并返回操作句柄。调用失败时,将返回NULL值,否则返回的是操作句柄。 |
| void *dlsym(void *handle, char *symbol) | 根据动态链接库操作句柄(handle)与符号(symbol),返回符号对应的函数的执行代码地址。由此地址,可以带参数执行相应的函数。 |
| int dlclose (void *handle) | 用于关闭指定句柄的动态链接库,只有当此动态链接库的使用计数为0时,才会真正被系统卸载。2.2在程序中使用动态链接库函数。 |
dlsym(void *handle, char *symbol)
filename:如果名字不以“/”开头,则非绝对路径名,将按下列先后顺序查找该文件。
(1)用户环境变量中的LD_LIBRARY值;
(2)动态链接缓冲文件/etc/ld.so.cache
(3)目录/lib,/usr/lib
flag表示在什么时候解决未定义的符号(调用)。取值有两个:
1) RTLD_LAZY : 表明在动态链接库的函数代码执行时解决。
2) RTLD_NOW :表明在dlopen返回前就解决所有未定义的符号,一旦未解决,dlopen将返回错误。
dlsym(void *handle, char *symbol)
dlsym()的用法一般如下:
void(*add)(int x,int y); /*说明一下要调用的动态函数add */
add=dlsym("xxx.so","add"); /* 打开xxx.so共享库,取add函数地址 */
add(89,369); /* 带两个参数89和369调用add函数 */
看我出招:
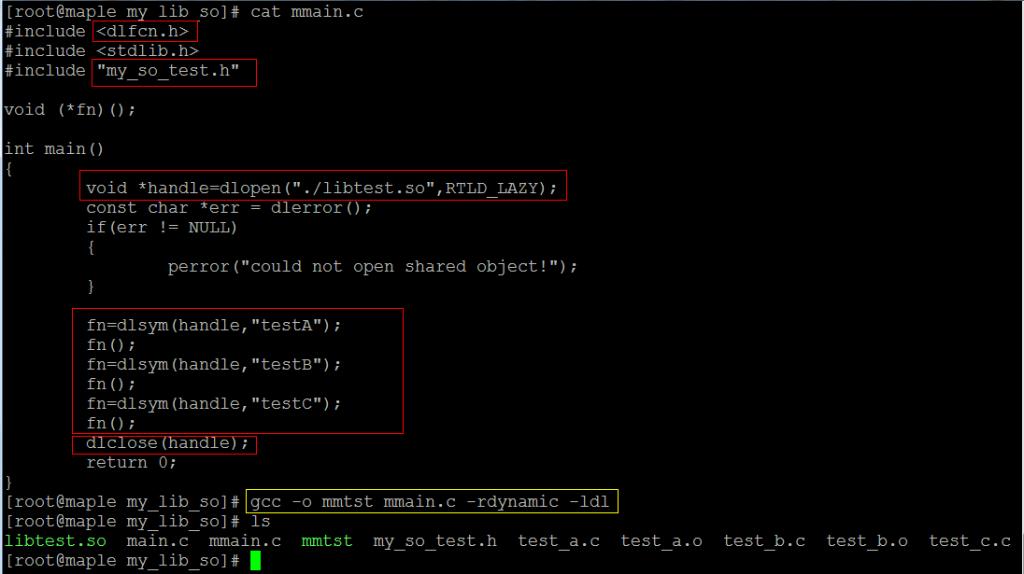
执行结果:

OK,通过本文的指导、练习相信各位应该对Linux的库机制有了些许了解,最主要的是会开发使用库文件了。由于本人知识所限,文中某些观点如果不到位或理解有误的地方还请各位个人不吝赐教。
动态加载和卸载的库
如果需要把应用程序设计成插件化的架构,这就需要可以动态加载和卸载库的机制。与动态链接不同的是,动态加载的意思是,编译期间可以对动态库的存在一无所知,而是在运行期间通过用户程序尝试加载进来的。通过 dlfcn.h 中的 dlopen 、dlsym 和 dlclose 等函数实现此种功能。另外,使用到dlfcn 机制的可执行文件需要使用 -rdynamic 选项,它将指示连接器把所有符号(而不仅仅只是程序已使用到的外部符号,但不包括静态符号,比如被static修饰的函数)都添加到动态符号表(即.dynsym表)里。
***********************************************************************************
ldconfig、ldd 命令工具
一、ldconfig
ldconfig是一个动态链接库管理命令。为了让动态链接库为系统所共享,需运行动态链接库的管理命令--ldconfig。 ldconfig 命令的用途,主要是在默认搜寻目录(/lib和/usr/lib)以及动态库配置文件/etc/ld.so.conf内所列的目录下,搜索出可共享的动态链接库(格式lib*.so*),进而创建出动态装入程序(ld.so)所需的连接和缓存文件。缓存文件默认为 /etc/ld.so.cache,此文件保存已排好序的动态链接库名字列表,为了让动态链接库为系统所共享,需运行动态链接库的管理命令ldconfig,此执行程序存放在/sbin目录下。ldconfig通常在系统启动时运行,而当用户安装了一个新的动态链接库,修改了ld.so.conf时,就需要手工运行这个命令。
linux下的共享库机制采用了类似于高速缓存的机制,将库信息保存在/etc/ld.so.cache里边。程序连接的时候首先从这个文件里边查找,然后再到ld.so.conf的路径里边去详细找
ldconfig命令行用法如下:
ldconfig [-v|--verbose] [-n] [-N] [-X] [-f CONF] [-C CACHE] [-rROOT] [-l] [-p|--print-cache]
[-c FORMAT] [--format=FORMAT] [-V] [-?|--help|--usage] path...
ldconfig可用的选项说明如下:
(1) -v或--verbose : 用此选项时,ldconfig将显示正在扫描的目录及搜索到的动态链接库,还有它所创建的链接的名字.
(2) -n : 用此选项时,ldconfig仅扫描命令行指定的目录,不扫描默认目录(/lib,/usr/lib),也不扫描配置文件/etc/ld.so.conf所列的目录.
(3) -N : 此选项指示ldconfig不重建缓存文件(/etc/ld.so.cache).若未用-X选项,ldconfig照常更新文件的连接.
(4) -X : 此选项指示ldconfig不更新文件的连接.若未用-N选项,则缓存文件正常更新.
(5) -f CONF : 此选项指定动态链接库的配置文件为CONF,系统默认为/etc/ld.so.conf.
(6) -C CACHE : 此选项指定生成的缓存文件为CACHE,系统默认的是/etc/ld.so.cache,此文件存放已排好序的可共享的动态链接库的列表.
(7) -r ROOT : 此选项改变应用程序的根目录为ROOT(是调用chroot函数实现的).选择此项时,系统默认的配置文件 /etc/ld.so.conf,实际对应的为 ROOT/etc/ld.so.conf.如用-r /usr/zzz时,打开配置文件 /etc/ld.so.conf时,实际打开的是/usr/zzz/etc/ld.so.conf文件.用此选项,可以大大增加动态链接库管理的灵活性.
(8) -l : 通常情况下,ldconfig搜索动态链接库时将自动建立动态链接库的连接.选择此项时,将进入专家模式,需要手工设置连接.一般用户不用此项.
(9) -p或--print-cache : 此选项指示ldconfig打印出当前缓存文件所保存的所有共享库的名字.
(10) -c FORMAT 或 --format=FORMAT : 此选项用于指定缓存文件所使用的格式,共有三种: ld(老格式),new(新格式)和compat(兼容格式,此为默认格式).
(11) -V : 此选项打印出ldconfig的版本信息,而后退出.
(12) -? 或 --help 或--usage : 这三个选项作用相同,都是让ldconfig打印出其帮助信息,而后退出.
ldconfig几个需要注意的地方
1. 往/lib和/usr/lib里面加东西,是不用修改/etc/ld.so.conf的,但是完了之后要调一下ldconfig,不然这个library会找不到
2. 想往上面两个目录以外加东西的时候,一定要修改/etc/ld.so.conf,然后再调用ldconfig,不然也会找不到
比如安装了一个MySQL到/usr/local/MySQL,mysql有一大堆library在/usr/local/mysql/lib下面,这时 就需要在/etc/ld.so.conf下面加一行/usr/local/mysql/lib,保存过后ldconfig一下,新的library才能在 程序运行时被找到。
3. 如果想在这两个目录以外放lib,但是又不想在/etc/ld.so.conf中加东西(或者是没有权限加东西)。那也可以,就是export一个全局变 量LD_LIBRARY_PATH,然后运行程序的时候就会去这个目录中找library。一般来讲这只是一种临时的解决方案,在没有权限或临时需要的时 候使用。
4. ldconfig做的这些东西都与运行程序时有关,跟编译时一点关系都没有。编译的时候还是该加-L就得加,不要混淆了。
5. 总之,就是不管做了什么关于library的变动后,最好都ldconfig一下,不然会出现一些意想不到的结果。不会花太多的时间,但是会省很多的事。
ldconfig提示“is not asymbolic link”的解决方法
在编译的时候会出现以下错误:
ldconfig
ldconfig: /lib/libdb-4.7.so is not a symbolic link
这是因为正常情况下libdb-4.7.so是一个符号连接,而不是一个实体文件,因此只需要把它改成符号连接即可
mv libdb-4.7.so libdb-4.so.7
ln -s libdb-4.so.7 libdb-4.7.so
二、ldd
作用:用来查看程序运行所需的共享库,常用来解决程序因缺少某个库文件而不能运行的一些问题。
语法:ldd(选项)(参数)
选项:
--version:打印指令版本号;
-v:详细信息模式,打印所有相关信息;
-u:打印未使用的直接依赖;
-d:执行重定位和报告任何丢失的对象;
-r:执行数据对象和函数的重定位,并且报告任何丢失的对象和函数;
--help:显示帮助信息。
参数:文件:指定可执行程序或者文库。
ldd命令原理介绍:
1、首先ldd不是一个可执行程序,而只是一个shell脚本
2、ldd能够显示可执行模块的dependency,其原理是通过设置一系列的环境变量,如下:LD_TRACE_LOADED_OBJECTS、LD_WARN、LD_BIND_NOW、LD_LIBRARY_VERSION、LD_VERBOSE等。当
LD_TRACE_LOADED_OBJECTS环境变量不为空时,任何可执行程序在运行时,它都会只显示模块的dependency,而程序并不真正执行。要不你可以在shell终端测试一下,如下:
(1) export LD_TRACE_LOADED_OBJECTS=1
(2) 再执行任何的程序,如ls等,看看程序的运行结果
3、ldd显示可执行模块的dependency的工作原理,其实质是通过ld-linux.so(elf动态库的装载器)来实现的。我们知道,ld-linux.so模块会先于executable模块程序工作,并获得控制权,因此当上述的那些环境变量被设置时,ld-linux.so选择了显示可执行模块的dependency。
4、实际上可以直接执行ld-linux.so模块,如:/lib/ld-linux.so.2 --list program(这相当于ldd program)
向大家推荐一个linux下系统命令帮助查阅的网站,网站是中文的,拯救了一大波英文不好的,而且介绍很齐全,排版很简洁:
Linux下进行程序设计时,关于库的使用
一、gcc/g++命令中关于库的参数:
-shared:
该选项指定生成动态连接库;
-fPIC:
表示编译为位置独立(地址无关)的代码,不用此选项的话,编译后的代码是位置相关的,
所以动态载入时,是通过代码拷贝的方式来满足不同进程的需要,而不能达到真正代码段共享的目的。
-L:指定链接库的路径,
-L. 表示要连接的库在当前目录中
-ltest:
指定链接库的名称为test,编译器查找动态连接库时有隐含的命名规则,
即在给出的名字前面加上lib,后面加上.so来确定库的名称
-Wl,-rpath:
记录以来so文件的路径信息。
LD_LIBRARY_PATH:
这个环境变量指示动态连接器可以装载动态库的路径。
当然如果有root权限的话,可以修改/etc/ld.so.conf文件,然后调用 /sbin/ldconfig来达到同样的目的,
不过如果没有root权限,那么只能采用修改LD_LIBRARY_PATH环境变量的方法了。 调用动态库的时候,有几个问题会经常碰到:
有时,明明已经将库的头文件所在目录 通过 “-I” include进来了,库所在文件通过 “-L”参数引导,并指定了“-l”的库名,但通过ldd命令察看时,就是死活找不到你指定链接的so文件,这时你要作的就是通过修改 LD_LIBRARY_PATH或者/etc/ld.so.conf文件来指定动态库的目录。通常这样做就可以解决库无法链接的问题了。
二、静态库链接时搜索路径的顺序
1. ld会去找gcc/g++命令中的参数-L;
2. 再找gcc的环境变量LIBRARY_PATH,它指定程序静态链接库文件搜索路径;
export LIBRARY_PATH=$LIBRARY_PATH:data/home/billchen/lib
3. 再找默认库目录 /lib /usr/lib /usr/local/lib,这是当初compile gcc时写在程序内的。
三、动态链接时、执行时搜索路径顺序
1. 编译目标代码时指定的动态库搜索路径;
2. 环境变量LD_LIBRARY_PATH指定动态库搜索路径,它指定程序动态链接库文件搜索路径;
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:data/home/billchen/lib
3. 配置文件/etc/ld.so.conf中指定的动态库搜索路径;
4. 默认的动态库搜索路径/lib;
5. 默认的动态库搜索路径/usr/lib。
四、静态库和动态链接库同时存在时,gcc/g++默认链接的是动态库
当一个库同时存在静态库和动态库时,比如 libmysqlclient.a 和 libmysqlclient.so 同时存在时:
在Linux下,动态库和静态库同时存在时,gcc/g++的链接程序,默认链接的动态库。
可以使用下面的方法,给连接器ld传递参数,看是否链接动态库还是静态库。 -Wl,-Bstatic -llibname //指定让gcc/g++链接静态库 使用: gcc/g++ test.c -o test -Wl,-Bstatic -llibname -Wl,-Bdynamic -lm -lc -Wl,-Bdynamic -llibname //指定让gcc/g++链接动态库 使用: gcc/g++ test.c -o test -Wl,-Bdynamic -llibname
如果要完全静态加载,使用-static参数,即将所有的库以静态的方式链入可执行程序,这样生成的可执行程序,不再依赖任何库,同时出现的问题是,这样编译出来的程序非常大,占用空间。
如果不适用-Wl,-Bdynamic -lm -c会有如下错误:
[chenbaihu@build17 lib]$ ls libtest.a libtest.so t t.cc test.cc test.h test.o [chenbaihu@build17 lib]$ g++ -Wall -g t.cc -o t -L./ -Wl,-Bstatic -ltest -Wl,-Bdynamic -lm -lc [chenbaihu@build17 lib]$ g++ -Wall -g t.cc -o t -L./ -Wl,-Bstatic -ltest /usr/bin/ld: cannot find -lm collect2: ld 返回 1
参考:
http://lists.gnu.org/archive/html/help-gnu-utils/2004-03/msg00009.html
五、有关环境变量
LIBRARY_PATH环境变量:指定程序静态链接库文件搜索路径 LD_LIBRARY_PATH环境变量:指定程序动态链接库文件搜索路径
六、库的依赖问题
比如我们有一个基础库libbase.a,还有一个依赖libbase.a编译的库叫做libchild.a。在我们编译程序时,一定要先-lchild再-lbase。 如果使用 -lbase -lchild,在编译时将出现一些函数undefined,而这些函数实际上已经在base中已经定义;
为什么会有库的依赖问题?
一、静态库解析符号引用: 链接器ld是如何使用静态库来解析引用的。在符号解析阶段,链接器从左至右,依次扫描可重定位目标文件(*.o)和静态库(*.a)。 在这个过程中,链接器将维持三个集合: 集合E:可重定位目标文件(*.o文件)的集合。 集合U:未解析(未定义)的符号集,即符号表中UNDEF的符号。 集合D: 已定义的符号集。 初始情况下,E、U、D均为空。
1、对于每个输入文件f,如果是目标文件(.o),则将f加入E,并用f中的符号表修改U、D(在文件f中定义实现的符号是D,在f中引用的符号是U),然后继续下个文件。
2、如果f是一个静态库(.a),那么链接器将尝试匹配U中未解析符号与静态库成员(静态库的成员就是.o文件)定义的符号。如果静态库中某个成员m(某个.o文件)定义了一个符号来解析U中引用,那么将m加入E中, 同时使用m的符号表,来更新U、D。对静态库中所有成员目标文件反复进行该过程,直至U和D不再发生变化。此时,静态库f中任何不包含在E中的成员目标文件都将丢弃,链接器将继续下一个文件。
3、当所有输入文件完成后,如果U非空,链接器则会报错,否则合并和重定位E中目标文件,构建出可执行文件。 到这里,为什么会有库的依赖问题已经得到解答: 因为libchild.a依赖于libbase.a,但是libbase.a在libchild.a的左边,导致libbase.a中的目标文件(*.o)根本就没有被加载到E中,所以解决方法就是交换两者的顺序。当然也可以使用-lbase -lchild -lbase的方法。
参考文章:http://pananq.com/index.php/page/3/
七、动态库升级问题
在动态链接库升级时,不能使用cp newlib.so oldlib.so,这样有可能会使程序core掉;
而应该使用: rm oldlib.so 然后 cp newlib.so oldlib.so
或者 mv oldlib.so oldlib.so_bak 然后 cp newlib.so oldlib.so
为什么不能用cp newlib.so oldlib.so ?
在替换so文件时,如果在不停程序的情况下,直接用 cp new.so old.so 的方式替换程序使用的动态库文件会导致正在运行中的程序崩溃。
解决方法:
解决的办法是采用“rm+cp” 或“mv+cp” 来替代直接“cp” 的操作方法。
linux系统的动态库有两种使用方法:运行时动态链接库,动态加载库并在程序控制之下使用。
1、为什么在不停程序的情况下,直接用 cp 命令替换程序使用的 so 文件,会使程序崩溃? 很多同学在工作中遇到过这样一个问题,在替换 so 文件时,如果在不停程序的情况下,直接用cp new.so old.so的方式替换程序使用的动态库文件会导致正在运行中的程序崩溃,退出。这与 cp 命令的实现有关,cp 并不改变目标文件的 inode,cp 的目标文件会继承被覆盖文件的属性而非源文件。实际上它是这样实现的: strace cp libnew.so libold.so 2>&1 |grep open.*lib.*.so open("libnew.so", O_RDONLY|O_LARGEFILE) = 3 open("libold.so", O_WRONLY|O_TRUNC|O_LARGEFILE) = 4 在 cp 使用“O_WRONLY|O_TRUNC” 打开目标文件时,原 so 文件的镜像被意外的破坏了。这样动态链接器 ld.so 不能访问到 so 文件中的函数入口。从而导致 Segmentation fault,程序崩溃。ld.so 加载 so 文件及“再定位”的机制比较复杂。
2、怎样在不停止程序的情况下替换so文件,并且保证程序不会崩溃? 答案是采用“rm+cp” 或“mv+cp” 来替代直接“cp” 的操作方法。在用新的so文件 libnew.so 替换旧的so文件 libold.so 时,如果采用如下方法: rm libold.so //如果内核正在使用libold.so,那么inode节点不会立刻别删除掉。 cp libnew.so libold.so 采用这种方法,目标文件 libold.so 的 inode 其实已经改变了,原来的 libold.so 文件虽然不能用"ls"查看到,但其inode并没有被真正删除,直到内核释放对它的引用。(即: rm libold.so,此时,如果ld.so正在加在libold.so,内核就在引用libold.so的inode节点,rm libold.so的inode并没有被真正删除,当ld.so对libold.so的引用结束,inode才会真正删除。这样程序就不会崩溃,因为它还在使用旧的libold.so,当下次再使用libold.so时,已经被替换,就会使用新的libold.so)
同理,mv只是改变了文件名,其 inode 不变,新文件使用了新的 inode。这样动态链接器 ld.so 仍然使用原来文件的 inode 访问旧的 so 文件。因而程序依然能正常运行。(即: mv libold.so ***后,如果程序使用动态库,还是使用旧的inode节点,当下次再使用libold.so时,就会使用新的libold.so)
到这里,为什么直接使用“cp new_exec_file old_exec_file”这样的命令时,系统会禁止这样的操作,并且给出这样的提示“cp: cannot create regular file `old': Text file busy”。
这时,我们采用的办法仍然是用“rm+cp”或者“mv+cp”来替代直接“cp”,这跟以上提到的so文件的替换有同样的道理。
但是,为什么系统会阻止cp覆盖可执行程序,而不阻止覆盖so文件呢?
这是因为 Linux 有个 Demand Paging 机制,所谓“Demand Paging”,简单的说,就是系统为了节约物理内存开销,并不会程序运行时就将所有页(page)都加载到内存中,而只有在系统有访问需求时才将其加载。“Demand Paging”要求正在运行中的程序镜像(注意,并非文件本身)不被意外修改,因此内核在启动程序后会锁定这个程序镜像的 inode。
对于 so 文件,它是靠 ld.so 加载的,而ld.so毕竟也是用户态程序,没有权利去锁定inode,也不应与内核的文件系统底层实现耦合。
========================
GNU Binutils:http://www.gnu.org/software/binutils/
GNU Binutils详解:http://www.crifan.com/files/doc/docbook/binutils_intro/release/html/binutils_intro.html
交叉编译详解:http://www.crifan.com/files/doc/docbook/cross_compile/release/html/cross_compile.html
Binutils工具集 解析:http://blog.csdn.net/zqixiao_09/article/details/50783007
gcc
gcc - GNU project C and C++ compiler
Linux 下 程序从源文件到编译成可执行文件流程

gcc部分选项

-E 预处理.预处理之后的代码将送往标准输出
-S 编译为汇编代码-c 编译为目标文件,不连接库
上面三个选项可以记忆为:ESc ,就是键盘上的取消按键
-Wwarn...
设置警告,可以设置的警告开关很多,通常用 -Wall 开启所有的警告
-Olevel
设置优化级别,level可以是0,1,2,3或者s,默认-O0,即不进行优化。.
-Dname=definition...
在命令行上定义宏,有两种方式,-Dname或者-Dname=definition.
在命令行上设置宏定义的目的主要是为了在调试的时候设定一些开关,
而在发布的时候再关闭或者打开这些开关即可,
当然宏定义也用来对代码进行有选择地编译.另外也还有其他的一些作用.
-Uname
取消宏定义name,作用和上面的正好相反.
-Idir...
把dir加到头文件的搜索路径中,而且gcc会在搜索标准头文件之前先搜索dir.
-llibrary
在连接的时候搜索library库,库是一些archieve文件--其成员是目标文件.
如果有文件引用library,library在命令行的位置应该在那个文件之后,因此,越底层的库越要放在后面.
比如如果你要连接pcap库,那么你就需要使用-lpcap对源文件进行编译.
-Ldir...
把dir加到库文件的搜索路径中,而且gcc会在搜索标准库文件之前先搜索dir.
-pthread
通过pthreads库加入对多线程的支持,这为预处理和连接设置了标志.pthread是POSIX指定的标准线程库.
-std=standard
设置采用的标准,该选项是针对C语言的,比如-std=c99表示编译器遵循C99标准.该选项较少使用.而且有时反而会把你搞糊涂.
-o outfile
指定输出文件的文件名,默认为a.out
-mmachine-option...
指定所用的平台.gcc常用选项总结
常规选项
1、没有任何选项:gcc helloworld.c
结果会在与helloworld.c相同的目录下产生一个a.out的可执行文件。
2、-o选项,指定输出文件名:gcc -o helloworld helloworld.c
-o 意思是Output即需要指定输出的可执行文件的名称。这里的名称为helloworld。
3、-c选项,只编译,不汇编连接:gcc -c helloworld.c
-c 意思就是Compile,产生一个叫helloworld.o的目标文件
4、-S选项,产生汇编源文件:gcc -S helloworld.c
-S 意思就是aSsemble,产生一个叫helloworld.s的汇编源文件
5、-E选项,预处理C源文件:gcc -E helloworld.c
-E意思就是prEprocess。输出不是送到一个文件而是标准输出。当然可以对它进行重定向:
gcc -E helloworld.c > helloworld.txt
-llibrary 指定所需要的额外库
-Ldir: 指定库搜索路径
-static: 静态链接所有库
-static-libgcc: 静态链接 gcc 库
-static-libstdc++: 静态链接 c++ 库
关于上述命令的详细说明,请参阅 GCC 技术手册
-std=c++11 指定使用C++11标准进行编译。因为上一个代码中使用了C++11中的std::array 等特性
-I[Dir] (大写的字母 i ) 指定头文件目录的搜索目录 -L[Dir] (大写的字母 L) 指定动态链接库的搜索目录 -l[lib] (小写的字母 L) 指定具体的静态库、动态库是哪个
如果头文件和源文件在同一目录下,编译时 -I(注意是大写的i)可省略 。gcc 头文件寻找次序:gcc会在程序当前目录、/usr/include和/usr/local/include目录下查找add.h文件。-I是用来告诉gcc去哪里找头文件的。-L实际上也很类似, 它是用来告诉gcc去哪里找库文件。 通常来讲, gcc默认会在程序当前目录、/lib、/usr/lib和/usr/local/lib下找对应的库。-l(注意是小写的L)的作用就是用来指定具体的静态库、动态库是哪个。
使用示例:
假设在 /tmp/project/ 目录下有三个文件:test.c 、log.c、log.h
现在进入project 目录下编译:gcc -o main test.c log.c -I./
或者
先把log.c 和 log.h 编译成 目标文件:gcc -o log.o log.c 再把 log.o 和 test.c 编译成可执行文件:gcc -o main log.o test.c
优化选项
1) -O选项,基本优化:gcc -O helloworld.c
-O意思就是Optimize,产生一个经过优化的叫作a.out的可执行文件。也可以同时使用-o选项,以指定输出文件名。
如:gcc -O -o test helloworld.c
即会产生一个叫test的经过优化的可执行文件。
2) -O2选项,最大优化:gcc -O2 helloworld.c
产生一个经过最大优化的叫作a.out的可执行文件。调试选项
1) -g选项,产生供gdb调试用的可执行文件:gcc -g helloworld.c
产生一个叫作a.out的可执行文件,大小明显比只用-o选项编译汇编连接后的文件大。
2) -pg选项,产生供gprof剖析用的可执行文件:gcc -pg helloworld.c
产生一个叫作a.out的执行文件,大小明显比用-g选项后产生的文件还大。
Gcc的错误类型及对策
Gcc编译器如果发现源程序中有错误,就无法继续进行,也无法生成最终的可执行文件。为了便于修改,gcc给出错误资讯,我们必须对这些错误资讯逐个进行分析、处理,并修改相应的语言,才能保证源代码的正确编译连接。gcc给出的错误资讯一般可以分为四大类,下面我们分别讨论其产生的原因和对策。第一类∶C语法错误
错误资讯∶文件source.c中第n行有语法错误(syntex errror)。这种类型的错误,一般都是C语言的语法错误,应该仔细检查源代码文件中第n行及该行之前的程序,有时也需要对该文件所包含的头文件进行检查。有些情况下,一个很简单的语法错误,gcc会给出一大堆错误,我们最主要的是要保持清醒的头脑,不要被其吓倒,必要的时候再参考一下C语言的基本教材。第二类∶头文件错误
错误资讯∶找不到头文件head.h(Can not find include file head.h)。这类错误是源代码文件中的包含头文件有问题,可能的原因有头文件名错误、指定的头文件所在目录名错误等,也可能是错误地使用了双引号和尖括号。第三类∶档案库错误
错误资讯∶连接程序找不到所需的函数库,例如∶
ld: -lm: No such file or directory
这类错误是与目标文件相连接的函数库有错误,可能的原因是函数库名错误、指定的函数库所在目录名称错误等,检查的方法是使用find命令在可能的目录中寻找相应的函数库名,确定档案库及目录的名称并修改程序中及编译选项中的名称。第四类∶未定义符号
错误资讯∶有未定义的符号(Undefined symbol)。这类错误是在连接过程中出现的,可能有两种原因∶一是使用者自己定义的函数或者全局变量所在源代码文件,没有被编译、连接,或者干脆还没有定义,这需要使用者根据实际情况修改源程序,给出全局变量或者函数的定义体;二是未定义的符号是一个标准的库函数,在源程序中使用了该库函数,而连接过程中还没有给定相应的函数库的名称,或者是该档案库的目录名称有问题,这时需要使用档案库维护命令ar检查我们需要的库函数到底位于哪一个函数库中,确定之后,修改gcc连接选项中的-l和-L项。
排除编译、连接过程中的错误,应该说这只是程序设计中最简单、最基本的一个步骤,可以说只是开了个头。这个过程中的错误,只是我们在使用C语言描述一个算法中所产生的错误,是比较容易排除的。我们写一个程序,到编译、连接通过为止,应该说刚刚开始,程序在运行过程中所出现的问题,是算法设计有问题,说得更玄点是对问题的认识和理解不够,还需要更加深入地测试、调试和修改。一个程序,稍为复杂的程序,往往要经过多次的编译、连接和测试、修改。















 3454
3454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









