






Elastic 官方文档:https://www.elastic.co/guide/index.html
elasticsearch github:https://github.com/elastic/elasticsearch
logstash github:https://github.com/elastic/logstash
kibana github:https://github.com/elastic/kibana
从 ELK 到 EFK:https://www.sohu.com/a/198596248_748431
Elasticsearch: 权威指南:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
ELK 快速指南:https://blog.csdn.net/bluetjs/article/details/78770447
ELK实时日志分析平台环境部署--完整记录:http://www.cnblogs.com/kevingrace/p/5919021.html
集中式日志分析平台 - ELK Stack - 部署篇:https://www.jianshu.com/p/934c457a333c
集中式日志系统 ELK 协议栈详解:https://www.ibm.com/developerworks/cn/opensource/os-cn-elk/
ELK+Filebeat 集中式日志解决方案详解:https://www.ibm.com/developerworks/cn/opensource/os-cn-elk-filebeat/index.html
ELK部署详解:https://segmentfault.com/a/1190000007728789
Centos7 之安装Logstash ELK stack 日志管理系统:https://www.cnblogs.com/hanyifeng/p/5509985.html
中小型研发团队架构实践七:集中式日志ELK:https://www.cnblogs.com/supersnowyao/p/8375926.html
ELK实时日志分析平台环境部署--完整记录:https://www.cnblogs.com/kevingrace/p/5919021.html
ELK 之Filebeat 结合Logstash 过滤出来你想要的日志:http://blog.51cto.com/seekerwolf/2110174
我的ELK搭建笔记(阿里云上部署):https://www.jianshu.com/p/797073c1913f
ELK 搭建篇:https://www.cnblogs.com/yuhuLin/p/7018858.html
通过ELK快速搭建一个你可能需要的集中化日志平台:https://www.cnblogs.com/huangxincheng/p/7918722.html
Logstat 输入插件配置:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
使用logstash的logstash-input-kafka插件读取kafka中的数据:https://blog.csdn.net/lvyuan1234/article/details/78653324
ELK Stack (系列文章):http://www.linuxe.cn/sort/elk
项目实战14—ELK 企业内部日志分析系统:https://www.cnblogs.com/along21/p/8509123.html
最新Centos7.6 部署ELK日志分析系统:https://segmentfault.com/a/1190000019799137
ELK日志系统浅析与部署:https://blog.csdn.net/qq_22211217/article/details/80764568
随笔分类 - ELK:https://www.cnblogs.com/workdsz/category/1257841.html
ELK 笔记:https://blog.csdn.net/ahri_j/category_7519196.html
ES基本概念与 API 操作:https://blog.csdn.net/Ahri_J/article/details/79720824
es 基本API操作使用:https://blog.csdn.net/zhangcongyi420/article/details/94362108
ELK、FILEBEAT日志分析平台搭建:https://shuwoom.com/?p=2300
ElasticSearch总结:https://www.cnblogs.com/aiqiqi/p/11451411.html
ELK 是 Elasticsearch、Logstash、Kibana的简称,这三者是核心套件,但并非全部。
- Elasticsearch 是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套开放 REST 和 JAVA API 等结构提供高效搜索功能,可扩展的分布式系统。它构建于 Apache Lucene 搜索引擎库之上。
- Logstash 是一个用来搜集、分析、过滤日志的工具。它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 RabbitMQ)和 JMX,它能够以多种方式输出数据,包括电子邮件、websockets 和 Elasticsearch。
- Kibana 是一个基于 Web 的图形界面,用于搜索、分析和可视化存储在 Elasticsearch 指标中的日志数据。它利用 Elasticsearch 的 REST 接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据

项目由来
(1)开发人员不能登录线上服务器查看详细日志,经过运维周转费时费力
(2)日志数据分散在多个系统,难以查找与整合
(3)日志数据量巨大,查询速度太慢,无法满足需求
(4)无法全局掌控项目运行状况
(5)日志数据查询不够实时
(6)数据分析人员不会写代码,无法分析统计数据
(7).........
框架里包含的组件
ELK 是 elastic 公司旗下三款产品 ElasticSearch 、Logstash 、Kibana 的首字母组合。
Logstash + Elasticsearch + Kibana(ELK)Logstash: 监控,过滤,收集日志。即传输和处理你的日志、事务或其他数据。Elasticsearch: 存储日志,提供搜索功能。ElasticSearch 是一个基于 Lucene 构建的开源,分布式,RESTful 搜索引擎。kibana: 提供web界面,支持查询,统计,和图表展现。即 将 Elasticsearch 的数据分析并渲染为可视化的报表。filebeat: 轻量级的日志收集工具。
很多公司都采用该架构构建分布式日志系统,包括 新浪微博,freewheel,畅捷通等
注意:在应用端收集日志时,建议用 filebeat 。
通过 ELK 这套解决方案,可以同时实现日志收集、日志搜索和日志分析的功能。
架构设计
如果日志量很大,Logstash 会遇到资源占用高的问题,为解决这个问题,引入了 Filebeat。Filebeat 是基于 logstash-forwarder 的源码改造而成,用 Golang 编写,无需依赖 Java 环境,效率高,占用内存和 CPU 比较少,非常适合作为 Agent 跑在服务器上。Filebeat 可以看做是新一代的 logstash-forward,但是性能超 logstash,部署简单,占用资源少,可以很方便的和logstash和ES对接,作为日志文件采集组件。Filebeat 是 Beats 家族的一员,后续可以使用 Packetbeat 进行网络数据采集、Winlogbeat 进行 Windosw事件采集、Heartbeat 进行心跳采集、Metricbeat 进行系统指标采集。这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
LogStash 可以用来对日志进行收集并进行过滤整理后输出到 ES 中,FileBeats 是一个更加轻量级的日志收集工具。现在最常用的方式是通过 FileBeats 收集目标日志,然后统一输出到 LogStash 做进一步的过滤,在由 LogStash 输出到 ES 中进行存储。
(1)使用filebeat架构设计1:filebeat --> logstash(parse) --> es集群(Elasticsearch 集群) --> kibana--ngix
缺点:如果 logstash 出问题会导致 filebeat 收集的数据丢失架构设计2:filebeat --> logstash(parse)[loadbalance] --> es集群 --> kibana--ngix
filebeat 和 logstash 耦合性太高架构设计3:filebeat(3台)--> redis --> logstash(parse) --> es集群 --> kibana -- ngix(可选)
里面 redis 是一个单线程的实例,redis 单线程每秒处理能力一般是 10W 次左右。架构设计4:filebeat --> redis/kafka --> logstash(parse) --> es --> kibana--ngix
filebeat1.3 版本不支持输出到 kafka,5.x 版本中支持输出到 kafka(2)不使用 filebeat
logstash --> kafka --> logstash(parse) --> es --> kibana--ngix
里面 kafka 支持水平扩展,可以使用多分区,支持多线程并行执行。
在应用端收集日志的话,logstash 比较重量级,性能消耗比 filebeat 大
(3)Filebeat 用于日志收集和传输,相比 Logstash 更加轻量级和易部署,对系统资源开销更小。
为什么做日志系统 ?
首先,什么是日志? 日志就是程序产生的,遵循一定格式(通常包含时间戳)的文本数据
通常日志由服务器生成,输出到不同的文件中,一般会有系统日志、 应用日志、安全日志。这些日志分散地存储在不同的机器上。
通常当系统发生故障时,工程师需要登录到各个服务器上,使用 grep、sed、awk 等 Linux 脚本工具去日志里查找故障原因。在没有日志系统的情况下,首先需要定位处理请求的服务器,如果这台服务器部署了多个实例,则需要去每个应用实例的日志目录下去找日志文件。每个应用实例还会设置日志滚动策略(如:每天生成一个文件),还有日志压缩归档策略等。
这样一系列流程下来,对于我们排查故障以及及时找到故障原因,造成了比较大的麻烦。因此,如果我们能把这些日志集中管理,并提供集中检索功能,不仅可以提高诊断的效率,同时对系统情况有个全面的理解,避免事后救火的被动。
日志数据在以下几方面具有非常重要的作用:
-
数据查找:通过检索日志信息,定位相应的 bug ,找出解决方案
-
服务诊断:通过对日志信息进行统计、分析,了解服务器的负荷和服务运行状态
-
数据分析:可以做进一步的数据分析,比如根据请求中的课程 id ,找出 TOP10 用户感兴趣课程。
针对这些问题,为了提供分布式的实时日志搜集和分析的监控系统,我们采用了业界通用的日志数据管理解决方案 - 它主要包括 Elasticsearch 、 Logstash 和 Kibana 三个系统。通常,业界把这套方案简称为 ELK,取三个系统的首字母,但是我们实践之后将其进一步优化为 EFK,F代表Filebeat,用以解决 Logstash 导致的问题。
Elasticsearch、Logstash、Kibana、Filebeat、Kafka
Elasticsearch 和 MySQL 对比:
终于有人把Elasticsearch原理讲透了:https://developer.51cto.com/art/201904/594615.htm


这一套软件可以当作一个 MVC 模型:logstash 是 controller 层,Elasticsearch 是一个 model 层,kibana 是 view 层。首先将数据传给 logstash,它将数据进行过滤和格式化(转成 JSON 格式),然后传给 Elasticsearch 进行存储、建搜索的索引,kibana提供前端的页面再进行搜索和图表可视化,它是调用 Elasticsearch 的接口返回的数据进行可视化。logstash 和 Elasticsearch 是用 Java 写的,kibana 使用node.js 框架。
这套软件官网有很详细的使用说明,https://www.elastic.co/,除了docs之外,还有视频教程。
友情提示:安装 ELK 时,三个应用请选择统一的版本,避免出现一些莫名其妙的问题。例如:由于版本不统一,导致三个应用间的通讯异常。
ELK 架构
ELK 技术栈 的一个架构图:

说明:以上是 ELK 技术栈的一个架构图。从图中可以清楚的看到数据流向。
- Beats (https://www.elastic.co/products/beats) 是单一用途的数据传输平台,它可以将多台机器的数据发送到 Logstash 或 ElasticSearch。但 Beats 并不是不可或缺的一环,所以本文中暂不介绍。
- Logstash:数据收集处理引擎。支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储以供后续使用。logstash 其实就是一个数据分析软件,主要目的是分析 log 日志。Logstash 是一个动态数据收集管道。支持以 TCP/UDP/HTTP 多种方式收集数据(也可以接受 Beats 传输来的数据),并对数据做进一步丰富或提取字段处理。
logstash 日志分析的配置和使用:https://www.cnblogs.com/yincheng/p/logstash.html
ELK 之 Logstash 安装与配置及使用: https://blog.csdn.net/CleverCode/article/details/78632887 - Kibana:可视化化平台。它能够搜索、展示存储在 Elasticsearch 中索引数据。使用它可以很方便的用图表、表格、地图展示和分析数据。Kibana 是一个基于浏览器页面的 Elasticsearch 前端展示工具,是 ELK 的用户界面,也是一个开源和免费的工具。它将收集的数据进行可视化展示(各种报表、图形化数据),并提供配置、管理 ELK 的界面。Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
- Elasticsearch:分布式搜索引擎。具有高可伸缩、高可靠、易管理等特点。可以用于全文检索、结构化检索和分析。Elasticsearch、Logstash 和 Kibana 这三个可以结合起来。Elasticsearch 基于 Lucene 开发,现在是使用最广的开源搜索引擎之一,Wikipedia 、StackOverflow、Github 等都基于它来构建自己的搜索引擎。ElasticSearch 是一个基于 JSON 的分布式的搜索和分析引擎。作为 ELK 的核心,它集中存储数据。
- Filebeat:轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。换句话说:Filebeat就是新版的 Logstash-fowarder,也会是 ELK Stack 在 shipper 端的第一选择。
ELK 工作原理展示图:

如上图:Logstash 收集 AppServer 产生的 Log,并存放到 ElasticSearch 集群中,而 Kibana 则从 ES 集群中查询数据生成图表,再返回给 Browser。
Logstash 工作原理:
Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。

Input:输入数据到logstash。
Logstash Reference:https://www.elastic.co/guide/en/logstash/current/index.html
一些常用的输入为:
Logstat 输入插件配置:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
file:从文件系统的文件中读取,类似于tial -f命令
syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析
redis:从redis service中读取
beats:从filebeat中读取
Filters:数据中间处理,对数据进行操作。
一些常用的过滤器为:
Logstat 过滤插件:https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。内置120多个解析语法。
mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
drop:丢弃一部分events不进行处理。
clone:拷贝 event,这个过程中也可以添加或移除字段。
geoip:添加地理信息(为前台kibana图形化展示使用)
Outputs:outputs是logstash处理管道的最末端组件。一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。
一些常见的outputs为:
Logstat 输出插件:https://www.elastic.co/guide/en/logstash/current/output-plugins.html
elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
file:将event数据保存到文件中。
graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。
Codecs:codecs 是基于数据流的过滤器,它可以作为input,output的一部分配置。Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。
一些常见的codecs:
Logstat codes :https://www.elastic.co/guide/en/logstash/current/codec-plugins.html
json:使用json格式对数据进行编码/解码。
multiline:将汇多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息。
简单版架构
图 1

图 2

这种架构下把 Logstash 实例与 Elasticsearch 实例直接相连。Logstash 实例直接通过 Input 插件读取数据源数据(比如 Java 日志, Nginx 日志等),经过 Filter 插件进行过滤日志,最后通过 Output 插件将数据写入到 ElasticSearch 实例中(Logstash部署在各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储)。Elasticsearch 再将数据以分片的形式压缩存储,并提供多种API供用户查询、操作。用户可以通过Kibana Web直观的对日志进行查询,并根据需求生成数据报表。
这个阶段,日志的收集、过滤、输出等功能,主要由这三个核心组件组成 Input 、Filter、Output
- Input:输入,输入数据可以是 File 、 Stdin(直接从控制台输入) 、TCP、Syslog 、Redis 、Collectd 等
- Filter:过滤,将日志输出成我们想要的格式。Logstash 存在丰富的过滤插件:Grok 正则捕获、时间处理、JSON 编解码、数据修改 Mutate 。Grok 是 Logstash 中最重要的插件,强烈建议每个人都要使用 Grok Debugger 来调试自己的 Grok 表达式:grok { match => ["message", "(?m)[%{LOGLEVEL:level}] [%{TIMESTAMP_ISO8601:timestamp}] [%{DATA:logger}] [%{DATA:threadId}] [%{DATA:requestId}] %{GREEDYDATA:msgRawData}"] }
- Output:输出,输出目标可以是 Stdout (直接从控制台输出)、Elasticsearch 、Redis 、TCP 、File 等
这是最简单的一种ELK架构方式,Logstash 实例直接与 Elasticsearch 实例连接。优点是搭建简单,易于上手。建议供初学者学习与参考,不能用于线上的环境。
集群版架构
图 1

此架构适合大型集群、海量数据的业务场景,它通过将前端Logstash Agent替换成filebeat,有效降低了收集日志对业务系统资源的消耗。同时,消息队列使用kafka集群架构,有效保障了收集数据的安全性和稳定性,而后端Logstash和Elasticsearch均采用集群模式搭建,从整体上提高了ELK系统的高效性、扩展性和吞吐量。
图 2

这种架构下我们采用多个 Elasticsearch 节点组成 Elasticsearch 集群,由于 Logstash 与 Elasticsearch 采用集群模式运行,集群模式可以避免单实例压力过重的问题,同时在线上各个服务器上部署 Logstash Agent,来满足数据量不大且可靠性不强的场景。
数据收集端:每台服务器上面部署 Logstash Shipper Agent 来收集当前服务器上日志,日志经过 Logstash Shipper 中 Input插件、Filter插件、Output 插件传输到 Elasticsearch 集群
数据存储与搜索:Elasticsearch 配置默认即可满足,同时我们看数据重要性来决定是否添加副本,如果需要的话,最多一个副本即可
数据展示:Kibana 可以根据 Elasticsearch 的数据来做各种各样的图表来直观的展示业务实时状况
这种架构使用场景非常有限,主要存在以下两个问题
-
消耗服务器资源:Logstash 的收集、过滤都在服务器上完成,这就造成服务器上占用系统资源较高、性能方面不是很好,调试、跟踪困难,异常处理困难
-
数据丢失:大并发情况下,由于日志传输峰值比较大,没有消息队列来做缓冲,就会导致 Elasticsearch 集群丢失数据
这个架构相对上个版本略微复杂,不过维护起来同样比较方便,同时可以满足数据量不大且可靠性不强的业务使用。
引入消息队列
图 1
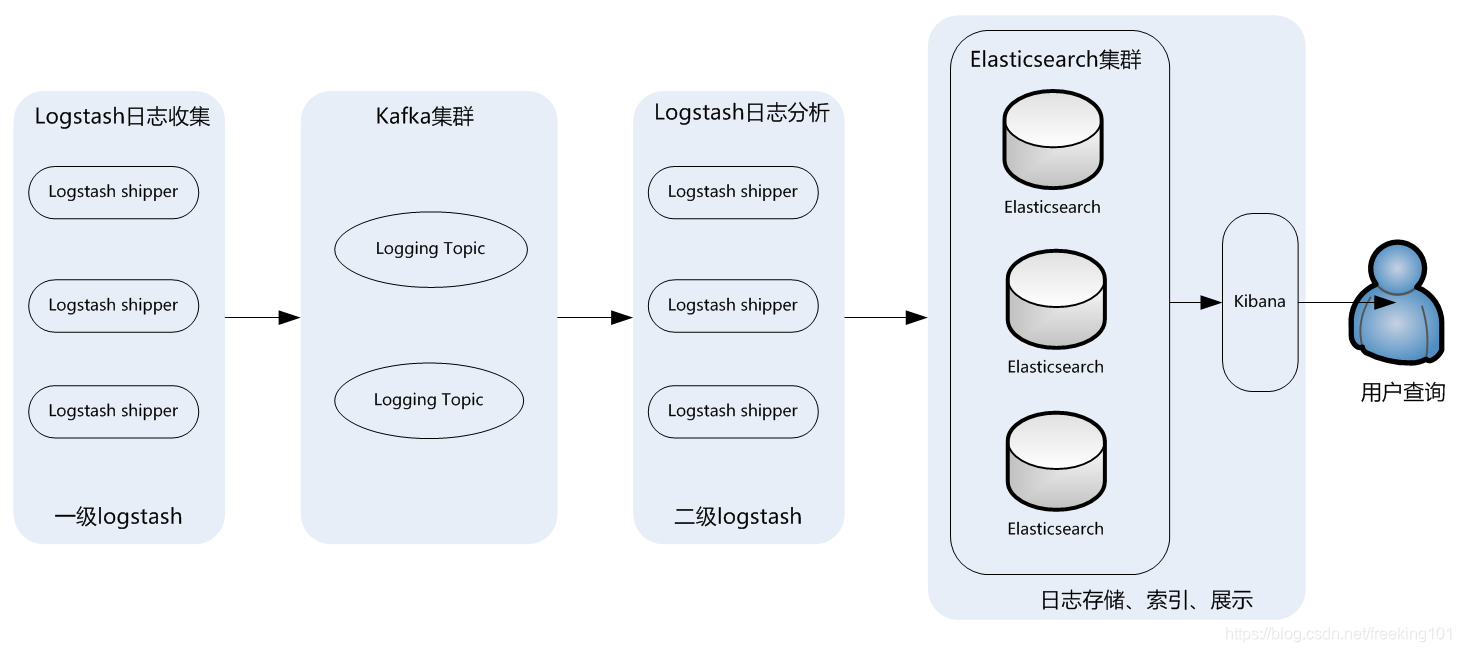
此架构主要特点是引入了消息队列机制,位于各个节点上的Logstash Agent(一级Logstash,主要用来传输数据)先将数据传递给消息队列(常见的有Kafka、Redis等),接着,Logstash server(二级Logstash,主要用来拉取消息队列数据,过滤并分析数据)将格式化的数据传递给Elasticsearch进行存储。最后,由Kibana将日志和数据呈现给用户。由于引入了Kafka(或者Redis)缓存机制,即使远端Logstash server因故障停止运行,数据也不会丢失,因为数据已经被存储下来了。
这种架构适合于较大集群、数据量一般的应用环境,但由于二级Logstash要分析处理大量数据,同时Elasticsearch也要存储和索引大量数据,因此它们的负荷会比较重,解决的方法是将它们配置为集群模式,以分担负载。
此架构的优点在于引入了消息队列机制,均衡了网络传输,从而降低了网络闭塞尤其是丢失数据的可能性,但依然存在Logstash占用系统资源过多的问题,在海量数据应用场景下,可能会出现性能瓶颈。
图 2

该场景下面,多个数据首先通过 Logstash Shipper Agent 来收集数据,然后经过 Output 插件将数据投递到 Kafka 集群中,这样当遇到 Logstash 接收数据的能力超过 Elasticsearch 集群处理能力的时候,就可以通过队列就能起到削峰填谷的作用, Elasticsearch 集群就不存在丢失数据的问题。
目前业界在日志服务场景中,使用比较多的两种消息队列为 :Kafka 和 Redis。尽管 ELK Stack 官网建议使用 Redis 来做消息队列,但是我们建议采用 Kafka 。主要从下面两个方面考虑:
-
数据丢失:Redis 队列多用于实时性较高的消息推送,并不保证可靠。Kafka保证可靠但有点延时。
-
数据堆积:Redis 队列容量取决于机器内存大小,如果超过设置的Max memory,数据就会抛弃。Kafka 的堆积能力取决于机器硬盘大小。
综合上述的理由,我们决定采用 Kafka 来缓冲队列。不过在这种架构下仍然存在一系列问题
-
Logstash shipper 收集数据同样会消耗 CPU 和内存资源
-
不支持多机房部署
这种架构适合较大集群的应用部署,通过消息队列解决了消息丢失、网络堵塞的问题。
多机房部署
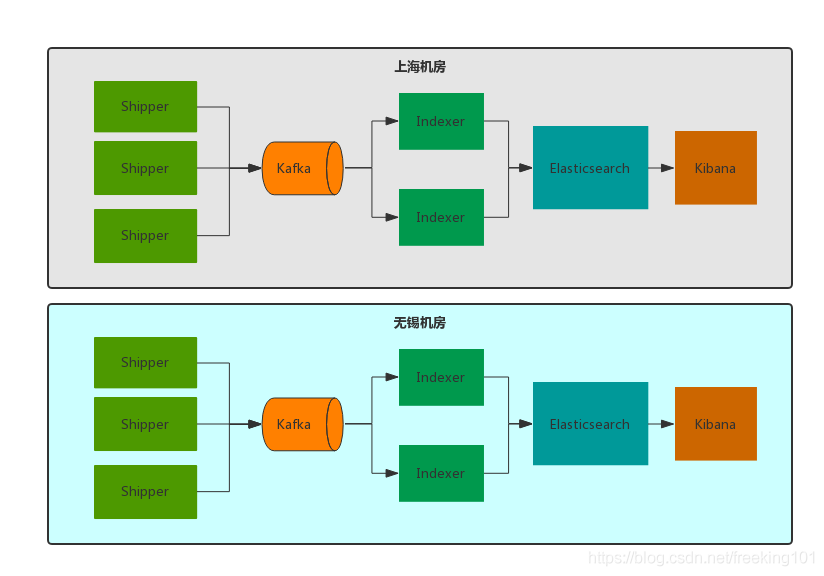
随着业务的飞速增长,单机房的架构已经不能满足需求,不可避免的需要将业务分布到不同机房中,对于日志服务来说也是不小的挑战。当然业界也有不少成熟的方法,比如阿里的单元化、腾讯的 SET 方案等等。单元化在这边不详细展开,大家可以参考微博的【单元化架构】。
最终我们决定采用单元化部署的方式来解决 ELK 多机房中遇到的问题(延时、专线流量过大等),从日志的产生、收集、传输、存储、展示都是在同机房里面闭环消化,不存在跨机房传输与调用的问题。因为交互紧密的应用尽量部署在同机房,所以这种方案并不会给业务查询造成困扰。
Logstash、Elasticsearch、Kafka、Kibana 四个集群都部署到同一机房中,每个机房都要每个机房自己的日志服务集群,比如A机房业务的日志只能传输给本机房 Kafka ,而A机房 Indexer 集群消费并写入到A机房 Elasticsearch 集群中,并由A机房 Kibana 集群展示,中间任何一个步骤不依赖B机房任何服务。
引入 Filebeat

如果日志量很大,Logstash 会遇到资源占用高的问题,为解决这个问题,引入了 Filebeat。Filebeat 是基于 logstash-forwarder 的源码改造而成,用 Golang 编写,无需依赖 Java 环境,效率高,占用内存 和 CPU 比较少,非常适合作为 Agent 跑在服务器上。
下面看看 Filebeat 的基本用法。编写配置文件,从 Nginx access.log 中解析日志数据:
# filebeat.ymlfilebeat.prospectors:- input_type: log paths: /var/log/nginx/access.log json.message_key:output.elasticsearch: hosts: ["localhost"] index: "filebeat-nginx-%{+yyyy.MM.dd}"
我们来看看压测数据:
压测环境
-
虚拟机 8 cores 64G内存 540G SATA盘
-
Logstash 版本 2.3.1
-
Filebeat 版本 5.5.0
压测方案
Logstash / Filebeat 读取 350W 条日志 到 console,单行数据 580B,8个进程写入采集文件
压测结果
| 项目 | workers | cpu usr | 总共耗时 | 收集速度 |
|---|---|---|---|---|
| Logstash | 8 | 53.7% | 210s | 1.6w line/s |
| Filebeat | 8 | 38.0% | 30s | 11w line/s |
Filebeat 所消耗的CPU只有 Logstash 的70%,但收集速度为 Logstash 的7倍。从我们的应用实践来看,Filebeat 确实用较低的成本和稳定的服务质量,解决了 Logstash 的资源消耗问题。
最后,分享给大家一些血泪教训,希望大家以我为鉴。
1. Indexer 运行一段时间后自动挂掉
突然有一天监控发现日志不消费了,排查下来发现消费 Kafka 数据的 indexer 挂掉了。所以,Indexer 进程也是需要用 supervisor 来监控的,保证它时刻都在运行。
2. Java异常日志输出
开始我们在通过 grok 切割日志的时候,发现 Java 的 Exception 日志输出之后,会出现换行的问题。后来使用 Logstash codec/multiline插件来解决。
input { stdin { codec => multiline { pattern => "^[" negate => true what => "previous" } }} 3. 由于时区导致日志8小时时差
Logstash 2.3版本 date插件配置如下,查看解析结果发现@timestamp比中国时间早了8小时。
解决方案 Kibana 读取浏览器的当前时区,然后在页面上转换时间内容的显示。
date { match => [ "log_timestamp", "YYYY-MM-dd HH:mm:ss.SSS" ] target => "@timestamp" } 4.Grok parse failure
我们遇到线上 node 日志突然有几天日志查看不出来。后来拉出原始日志对比才发现生成出来的日志格式不正确,同时包含 JSON 格式和非 JSON 格式的日志。但是我们用grok解析的时候采用是 json 格式。建议大家输出日志保证格式一致同时不要出现空格等异常字符,可以使用在线 grok debug (http://grokdebug.herokuapp.com/) 来调试正则。
总结
基于 ELK stack 的日志解决方案的优势主要体现于:
-
可扩展性:采用高可扩展性的分布式系统架构设计,可以支持每日 TB 级别的新增数据。
-
使用简单:通过用户图形界面实现各种统计分析功能,简单易用,上手快
-
快速响应:从日志产生到查询可见,能达到秒级完成数据的采集、处理和搜索统计。
-
界面炫丽:Kibana 界面上,只需要点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表板。

参考资料
安装
ELK 要求本地环境中安装了 JDK 。如果不确定是否已安装,可使用下面的命令检查:java -version
友情提示:安装 ELK 时,三个应用请选择统一的版本,避免出现一些莫名其妙的问题。
例如:由于版本不统一,导致三个应用间的通讯异常。
安装 FAQ
elasticsearch 不允许以 root 权限来运行。
问题:在 Linux 环境中,elasticsearch 不允许以 root 权限来运行。如果以 root 身份运行 elasticsearch,会提示这样的错误:can not run elasticsearch as root
解决方法:使用非 root 权限账号运行 elasticsearch
# 创建用户组
groupadd elk
# 创建新用户,-g elk 设置其用户组为 elk,-p elk 设置其密码为 elk
useradd elk -g elk -p elk
# 更改 /opt 文件夹及内部文件的所属用户及组为 elk:elk
chown -R elk:elk /opt # 假设你的 elasticsearch 安装在 opt 目录下
# 切换账号
su elkvm.max_map_count 不低于 262144
问题:vm.max_map_count 表示虚拟内存大小,它是一个内核参数。elasticsearch 默认要求 vm.max_map_count 不低于 262144。
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决方法:你可以执行以下命令,设置 vm.max_map_count ,但是重启后又会恢复为原值。
sysctl -w vm.max_map_count=262144持久性的做法是在 /etc/sysctl.conf 文件中修改 vm.max_map_count 参数:
echo "vm.max_map_count=262144" > /etc/sysctl.conf
sysctl -p注意:如果运行环境为 docker 容器,可能会限制执行 sysctl 来修改内核参数。这种情况下,你只能选择直接修改宿主机上的参数了。
nofile 不低于 65536
问题: nofile 表示进程允许打开的最大文件数。elasticsearch 进程要求可以打开的最大文件数不低于 65536。
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
解决方法:在 /etc/security/limits.conf 文件中修改 nofile 参数
echo "* soft nofile 65536" > /etc/security/limits.conf
echo "* hard nofile 131072" > /etc/security/limits.confnproc 不低于 2048
问题: nproc 表示最大线程数。elasticsearch 要求最大线程数不低于 2048。
max number of threads [1024] for user [user] is too low, increase to at least [2048]
解决方法:在 /etc/security/limits.conf 文件中修改 nproc 参数
echo "* soft nproc 2048" > /etc/security/limits.conf
echo "* hard nproc 4096" > /etc/security/limits.confKibana No Default Index Pattern Warning
问题:安装 ELK 后,访问 kibana 页面时,提示以下错误信息:
Warning No default index pattern. You must select or create one to continue.
...
Unable to fetch mapping. Do you have indices matching the pattern?
这就说明 logstash 没有把日志写入到 elasticsearch。
解决方法:检查 logstash 与 elasticsearch 之间的通讯是否有问题,一般问题就出在这。
Elasticsearch
安装步骤:
确定机器已经安装了 Java 环境后,就可以安装 ES 了。官网提供了压缩包可以直接下载,
1. elasticsearch 官方下载地址下载所需版本包并解压到本地。本次安装以Ubuntu为例。

右键选择 复制链接地址 ,使用 wget 下载 Filebeat.tar.gz 压缩包。然后使用 tar -zxvf 命令解压。
# 下载压缩包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.2.tar.gz
# 解压
tar -xzf elasticsearch-6.2.2.tar.gz
# 进入文件
cd elasticsearch-6.2.2/Windows、MAC、Linux 下载安装:
Linux 上可以执行下面的命令来下载压缩包:
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.0.0.tar.gz
Mac 上可以执行以下命令来进行安装:
brew install elasticsearch
Windows 上可以选择 MSI 可执行安装程序,将应用安装到本地2. 解压完成后进入目录,启动命令在 bin 目录下,直接运行命令就可以启动了。
Linux 下运行 bin/elasticsearch ( Windows 上运行 bin\elasticsearch.bat)
注意:在 Linux 环境中,elasticsearch 不允许以 root 权限来运行。使用非 root 权限账号运行 elasticsearch
# 创建用户组
groupadd elk
# 创建新用户,-g elk 设置其用户组为 elk,-p elk 设置其密码为 elk
useradd elk -g elk -p elk
# 更改 /opt 文件夹及内部文件的所属用户及组为 elk:elk
chown -R elk:elk /opt # 假设你的 elasticsearch 安装在 opt 目录下
# 切换账号
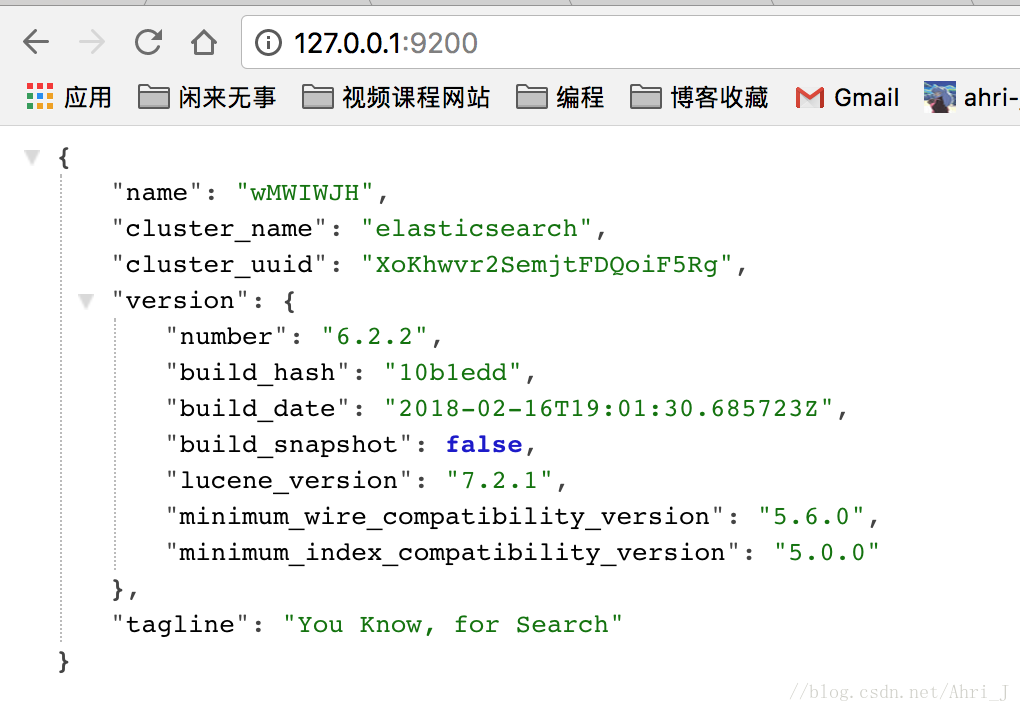
su elk3. 验证运行成功:linux 上可以执行 curl http://localhost:9200/ ;windows 上可以用访问 REST 接口的方式来访问 http://localhost:9200/

上图表示Elasticsearch正常启动。
ElasticSearch 的默认启动端口是 9200。手动访问出现如下信息说明启动成功。
Logstash
安装步骤:
1. 在 logstash 官方下载地址下载所需版本包并解压到本地。

右键 选择 复制链接地址,使用 wget 下载 tar.gz 压缩包。然后使用 tar 解压
tar -zxvf logstash-6.2.2.tar.gz
# 进入目录
cd logstash-6.2.22.配置 logstash。需要创建一个配置文件,并指定要使用的插件和每个插件的设置。我们创建名为 logstash-simple.conf 的文件并将其保存在与Logstash相同的目录中。LogStash 的运行需要指定一个配置文件,来指定数据的流向。
创建配置文件
cd logstash-6.4.0/
vi logstash-simple.conf在 logstash-simple.conf 中输入以下内容
input { stdin { } }
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}或者:
# 配置输入为 beats
input {
beats {
port => "5044"
}
}
# 数据过滤
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
geoip {
source => "clientip"
}
}
# 输出到本机的 ES
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}3. 上面配置了 LogStash 输出日志到 ES 中,具体字段在后面的笔记中会详细介绍,这里先用起来再说。
配置完成后就可以通过如下方式启动 LogStash 了(Linux 下运行 bin/logstash -f logstash-simple.conf (Windows 上运行bin/logstash.bat -f logstash-simple.conf))
bin/logstash -f logstash-simple.conf --config.reload.automatic可以看到命令行会打印出如下信息, 可以看到 LogStash 默认端口为 5044:
[2018-03-08T23:12:44,087][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2018-03-08T23:12:44,925][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.2.2"}
[2018-03-08T23:12:45,623][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2018-03-08T23:12:49,960][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>4, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50}
[2018-03-08T23:12:50,882][INFO ][logstash.outputs.elasticsearch] Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[2018-03-08T23:12:50,894][INFO ][logstash.outputs.elasticsearch] Running health check to see if an Elasticsearch connection is working {:healthcheck_url=>http://localhost:9200/, :path=>"/"}
[2018-03-08T23:12:51,303][WARN ][logstash.outputs.elasticsearch] Restored connection to ES instance {:url=>"http://localhost:9200/"}
[2018-03-08T23:12:51,595][INFO ][logstash.outputs.elasticsearch] ES Output version determined {:es_version=>nil}
[2018-03-08T23:12:51,604][WARN ][logstash.outputs.elasticsearch] Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>6}
[2018-03-08T23:12:51,641][INFO ][logstash.outputs.elasticsearch] Using mapping template from {:path=>nil}
[2018-03-08T23:12:51,676][INFO ][logstash.outputs.elasticsearch] Attempting to install template {:manage_template=>{"template"=>"logstash-*", "version"=>60001, "settings"=>{"index.refresh_interval"=>"5s"}, "mappings"=>{"_default_"=>{"dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword", "ignore_above"=>256}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date"}, "@version"=>{"type"=>"keyword"}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}}
[2018-03-08T23:12:51,773][INFO ][logstash.outputs.elasticsearch] New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["//localhost:9200"]}
[2018-03-08T23:12:52,176][INFO ][logstash.filters.geoip ] Using geoip database {:path=>"/Users/zouyingjie/soft/study/ELK/logstash-6.2.2/vendor/bundle/jruby/2.3.0/gems/logstash-filter-geoip-5.0.3-java/vendor/GeoLite2-City.mmdb"}
[2018-03-08T23:12:53,026][INFO ][logstash.inputs.beats ] Beats inputs: Starting input listener {:address=>"0.0.0.0:5044"}
[2018-03-08T23:12:53,195][INFO ][logstash.pipeline ] Pipeline started succesfully {:pipeline_id=>"main", :thread=>"#<Thread:0x66461e40 run>"}
[2018-03-08T23:12:53,290][INFO ][org.logstash.beats.Server] Starting server on port: 5044
[2018-03-08T23:12:53,401][INFO ][logstash.agent ] Pipelines running {:count=>1, :pipelines=>["main"]}FileBeats
FileBeats 也提供了下载包,地址为 https://www.elastic.co/downloads/beats/filebeat 。找到系统对应的包下载后解压即可。

右键 选择 复制链接地址 使用 wget 下载 Filebeat.tar.gz 压缩包。
然后使用 tar -zxvf 命令解压。
tar -zxvf filebeat-6.2.2-darwin-x86_64.tar.gz
cd filebeat-6.2.2-darwin-x86_64进入目录编辑 filebeat.yml 找到对应的配置项,配置如下
- type: log
# Change to true to enable this prospector configuration.
enabled: True
# Paths that should be crawled and fetched. Glob based paths.
# 读取 Nginx 的日志
paths:
- /usr/local/nginx/logs/*.log
#----------------------------- Logstash output --------------------------------
# 输出到本机的 LogStash
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]配置完成后执行如下命令,启动 FileBeat 即可
# FileBeat 需要以 root 身份启动,因此先更改配置文件的权限
sudo chown root filebeat.yml
sudo ./filebeat -e -c filebeat.yml -d "publish"Kibana
百度 kibana 使用教程
Kibana查询语言增强功能:https://www.elastic.co/guide/en/kibana/6.3/kuery-query.html#kuery-query
Kibana 用户手册:https://www.elastic.co/guide/cn/kibana/current/index.html
安装步骤:
- 在 kibana 官方下载地址下载所需版本包并解压到本地。
- 修改
config/kibana.yml配置文件,设置elasticsearch.url指向 Elasticsearch 实例。设置 server.host: "0.0.0.0" - 运行
bin/kibana(Windows 上运行bin\kibana.bat) - 在浏览器上访问 http://localhost:5601
Kibana 也提供了对应的安装包下载,链接为 https://www.elastic.co/downloads/kibana , Mac、Linux、Win 都有对应的安装包,直接下载解压即可
tar zxvf kibana-6.2.2-darwin-x86_64.tar.gz
cd kibana-6.2.2-darwin-x86_64
# 直接启动即可
bin/kibanaKibana 默认链接了本机的 9200 端口,其绑定的端口为 5601,启动成功后直接访问 127.0.0.1:5601 端口即可,界面如下。我因为安装了 x-pack 插件因此显示的项可能会多一些,这个暂时忽略.
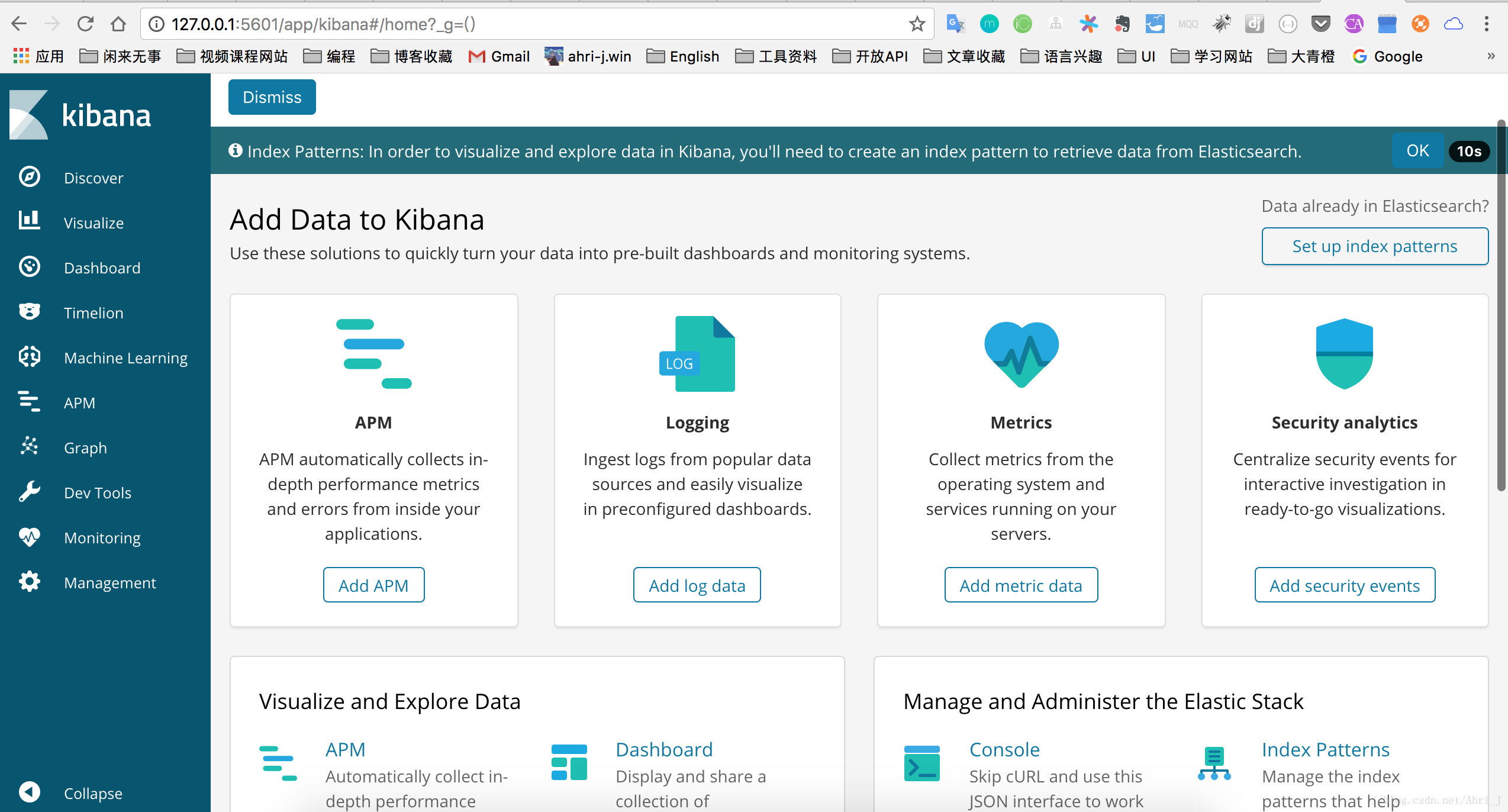
点击右上方的 Discover. 界面会提示创建索引模式,通过这个来检索 ES 中的索引,可以看到已经有一个 Logstash 的索引了,输入名称进行完全匹配,
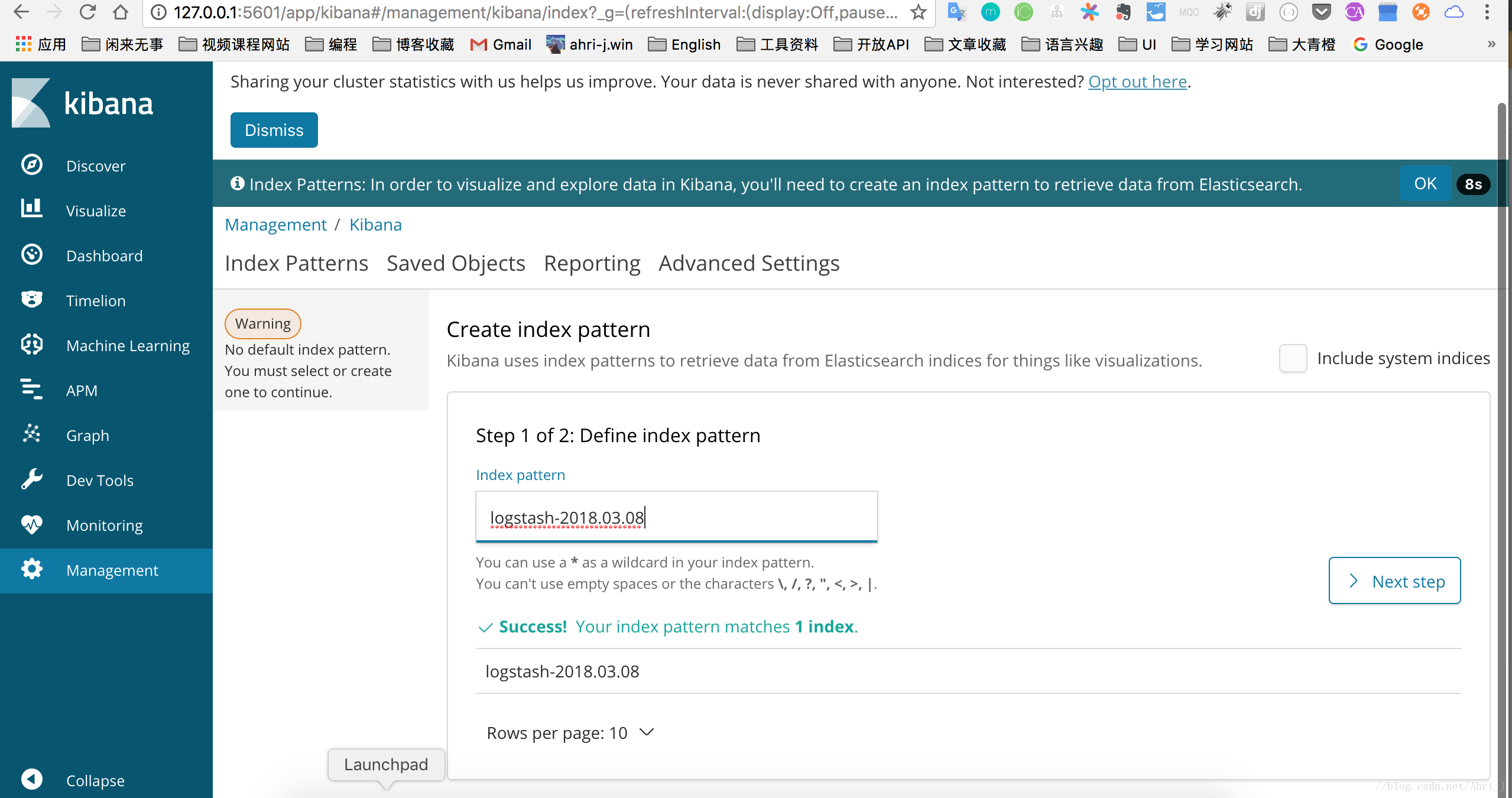
这里选定一个时间戳,使用默认的 timestamp 即可,设置完成后我们可以根据时间范围筛选数据。
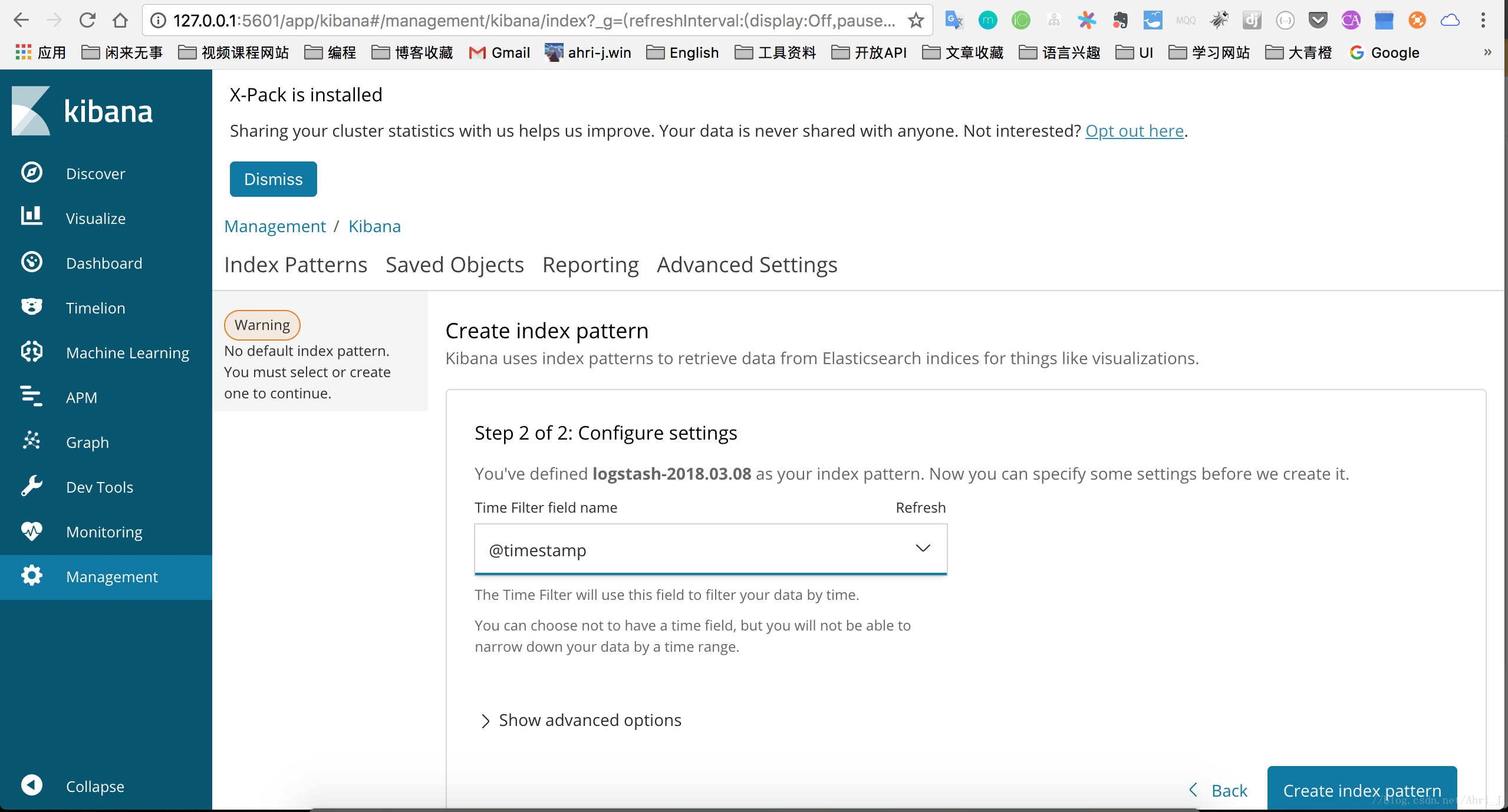
设置完成后创建后显示如下
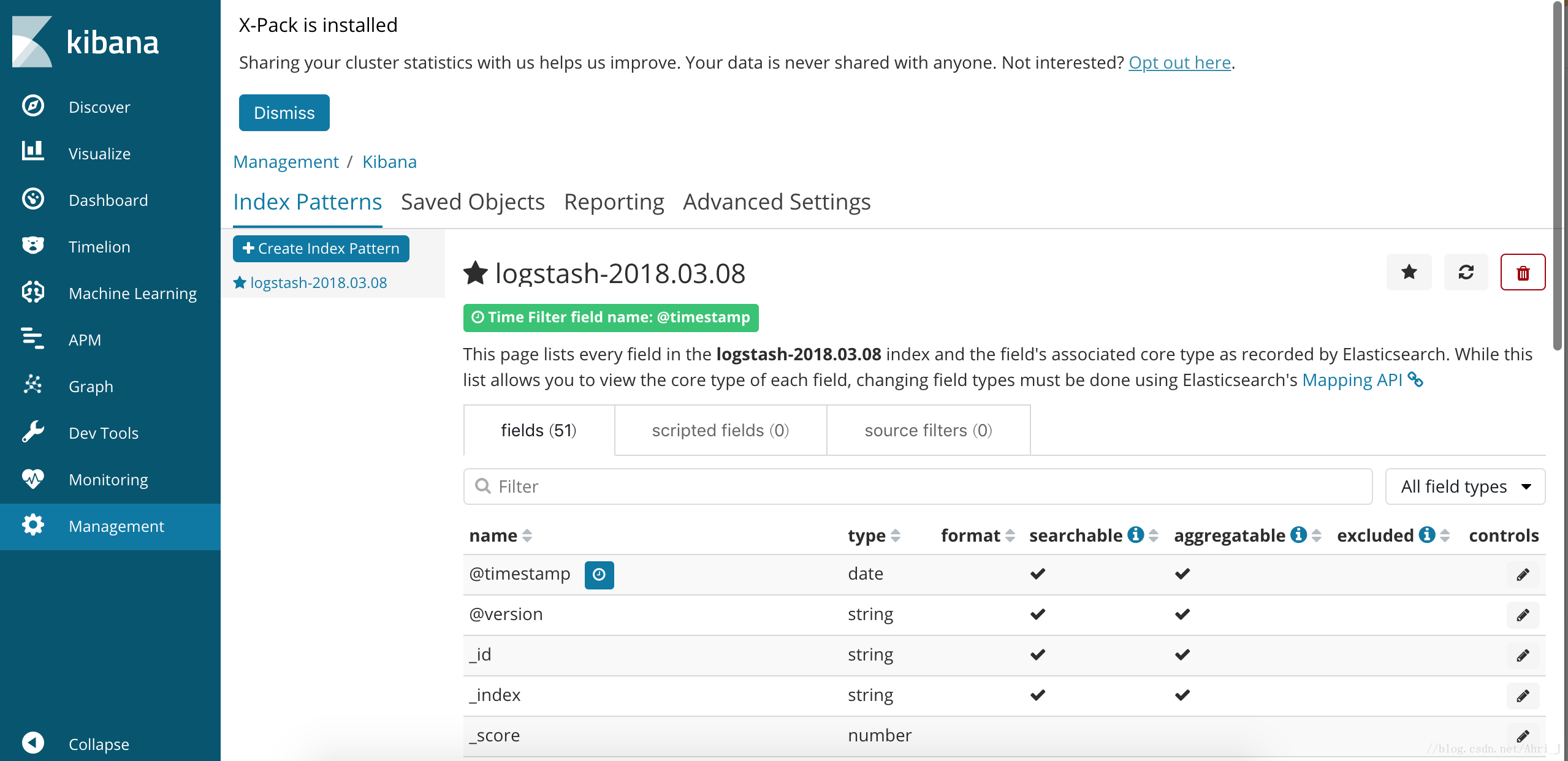
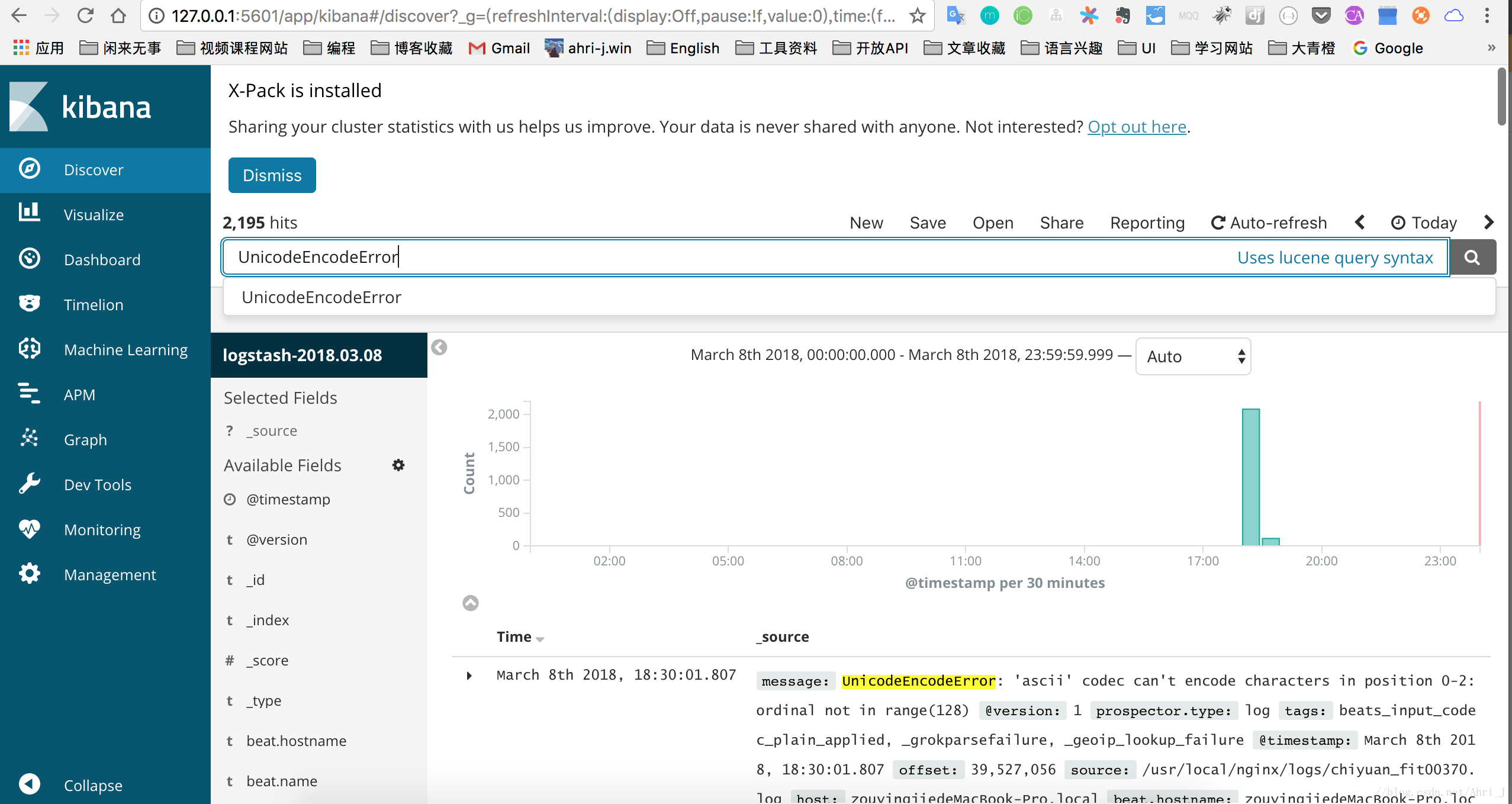
这时在点击 Discover 就可以看到我们创建的索引了,此时输入 UnicodeEncodeError 已经返回了匹配到的日志信息。
至此就完成了简单的日志分析平台的搭建。OK,关于安装就介绍到这里,后面正式开始对整个 ELK Stack 的学习。
注意:如果在 discover 里面找不到数据,有可能是时区的问题,可以通过 Management -> Advanced Settings -> dateFormat:tz 更改时区,改为 UTC 即可。


快速搭建ELK日志分析系统
From:https://blog.csdn.net/e_wsq/article/details/81303713
环境
2 台 Centos 主机
IP:192.168.1.202 安装: elasticsearch、logstash、Kibana、Nginx、Http、Redis
192.168.1.201 安装: logstash安装
安装elasticsearch的yum源的密钥(这个需要在所有服务器上都配置)
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
配置elasticsearch的yum源
# vim /etc/yum.repos.d/elasticsearch.repo
在elasticsearch.repo文件中添加如下内容
[elasticsearch-5.x]
name=Elasticsearch repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md安装elasticsearch的环境
安装elasticsearch
# yum install -y elasticsearch
安装java环境(java环境必须是1.8版本以上的)
wget http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.rpm
rpm -ivh jdk-8u131-linux-x64.rpm
验证java安装成功
java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)创建elasticsearch data的存放目录,并修改该目录的属主属组
# mkdir -p /data/es-data (自定义用于存放data数据的目录)
# chown -R elasticsearch:elasticsearch /data/es-data修改elasticsearch的日志属主属组
# chown -R elasticsearch:elasticsearch /var/log/elasticsearch/修改elasticsearch的配置文件
# vim /etc/elasticsearch/elasticsearch.yml
找到配置文件中的cluster.name,打开该配置并设置集群名称
cluster.name: demon
找到配置文件中的node.name,打开该配置并设置节点名称
node.name: elk-1
修改data存放的路径
path.data: /data/es-data
修改logs日志的路径
path.logs: /var/log/elasticsearch/
配置内存使用用交换分区
bootstrap.memory_lock: true
监听的网络地址
network.host: 0.0.0.0
开启监听的端口
http.port: 9200
增加新的参数,这样head插件可以访问es (5.x版本,如果没有可以自己手动加)
http.cors.enabled: true
http.cors.allow-origin: "*"
启动elasticsearch服务启动服务
/etc/init.d/elasticsearch start
Starting elasticsearch: Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000085330000, 2060255232, 0) failed; error='Cannot allocate memory' (errno=12)
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 2060255232 bytes for committing reserved memory.
# An error report file with more information is saved as:
# /tmp/hs_err_pid2616.log
[FAILED]
这个报错是因为默认使用的内存大小为2G,虚拟机没有那么多的空间
修改参数:
vim /etc/elasticsearch/jvm.options
-Xms512m
-Xmx512m
再次启动
/etc/init.d/elasticsearch start
查看服务状态,如果有报错可以去看错误日志 less /var/log/elasticsearch/demon.log(日志的名称是以集群名称命名的)
创建开机自启动服务
# chkconfig elasticsearch on注意事项
需要修改几个参数,不然启动会报错
vim /etc/security/limits.conf
在末尾追加以下内容(elk为启动用户,当然也可以指定为*)
elk soft nofile 65536
elk hard nofile 65536
elk soft nproc 2048
elk hard nproc 2048
elk soft memlock unlimited
elk hard memlock unlimited
继续再修改一个参数
vim /etc/security/limits.d/90-nproc.conf
将里面的1024改为2048(ES最少要求为2048)
* soft nproc 2048
另外还需注意一个问题(在日志发现如下内容,这样也会导致启动失败,这一问题困扰了很久)
[2017-06-14T19:19:01,641][INFO ][o.e.b.BootstrapChecks ] [elk-1] bound or publishing to a non-loopback or non-link-local address, enforcing bootstrap checks
[2017-06-14T19:19:01,658][ERROR][o.e.b.Bootstrap ] [elk-1] node validation exception
[1] bootstrap checks failed
[1]: system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
解决:修改配置文件,在配置文件添加一项参数(目前还没明白此参数的作用)
vim /etc/elasticsearch/elasticsearch.yml
bootstrap.system_call_filter: false通过浏览器请求下9200的端口,看下是否成功
先检查9200端口是否起来
netstat -antp |grep 9200
tcp 0 0 :::9200 :::* LISTEN 2934/java
浏览器访问测试是否正常(以下为正常)
# curl http://127.0.0.1:9200/
{
"name" : "linux-node1",
"cluster_name" : "demon",
"cluster_uuid" : "kM0GMFrsQ8K_cl5Fn7BF-g",
"version" : {
"number" : "5.4.0",
"build_hash" : "780f8c4",
"build_date" : "2017-04-28T17:43:27.229Z",
"build_snapshot" : false,
"lucene_version" : "6.5.0"
},
"tagline" : "You Know, for Search"
}如何和elasticsearch交互
JavaAPI
RESTful API
Javascript,.Net,PHP,Perl,Python
利用API查看状态
# curl -i -XGET 'localhost:9200/_count?pretty'
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
content-length: 95
{
"count" : 0,
"_shards" : {
"total" : 0,
"successful" : 0,
"failed" : 0
}
}安装插件
安装elasticsearch-head插件
安装docker镜像或者通过github下载elasticsearch-head项目都是可以的,1或者2两种方式选择一种安装使用即可
1. 使用docker的集成好的elasticsearch-head
# docker run -p 9100:9100 mobz/elasticsearch-head:5
docker容器下载成功并启动以后,运行浏览器打开http://localhost:9100/
2. 使用git安装elasticsearch-head
# yum install -y npm
# git clone git://github.com/mobz/elasticsearch-head.git
# cd elasticsearch-head
# npm install
# npm run start
检查端口是否起来
netstat -antp |grep 9100
浏览器访问测试是否正常
http://IP:9100/截图:

LogStash的使用
安装Logstash环境:
官方安装手册:
https://www.elastic.co/guide/en/logstash/current/installing-logstash.html
下载yum源的密钥认证:
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
利用yum安装logstash
# yum install -y logstash
查看下logstash的安装目录
# rpm -ql logstash
创建一个软连接,每次执行命令的时候不用在写安装路劲(默认安装在/usr/share下)
ln -s /usr/share/logstash/bin/logstash /bin/
执行logstash的命令
# logstash -e 'input { stdin { } } output { stdout {} }'
运行成功以后输入:
nihao
stdout返回的结果:截图:

注:
-e 执行操作
input 标准输入
{ input } 插件
output 标准输出
{ stdout } 插件
通过rubydebug来输出下更详细的信息
# logstash -e 'input { stdin { } } output { stdout {codec => rubydebug} }'
执行成功输入:
nihao
stdout输出的结果:
如果标准输出还有elasticsearch中都需要保留应该怎么玩,看下面
# /usr/share/logstash/bin/logstash -e 'input { stdin { } } output { elasticsearch { hosts => ["192.168.1.202:9200"] } stdout { codec => rubydebug }}'
运行成功以后输入:
I am elk
返回的结果(标准输出中的结果):
logstash使用配置文件
官方指南:
https://www.elastic.co/guide/en/logstash/current/configuration.html
创建配置文件01-logstash.conf
# vim /etc/logstash/conf.d/elk.conf
文件中添加以下内容
input { stdin { } }
output {
elasticsearch { hosts => ["192.168.1.202:9200"] }
stdout { codec => rubydebug }
}
使用配置文件运行logstash
# logstash -f ./elk.conf
运行成功以后输入以及标准输出结果
logstash的数据库类型
1. Input插件
权威指南:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
file插件的使用
# vim /etc/logstash/conf.d/elk.conf
添加如下配置
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "system-%{+YYYY.MM.dd}"
}
}
运行logstash指定elk.conf配置文件,进行过滤匹配
#logstash -f /etc/logstash/conf.d/elk.conf
来一发配置安全日志的并且把日志的索引按类型做存放,继续编辑elk.conf文件
# vim /etc/logstash/conf.d/elk.conf
添加secure日志的路径
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
file {
path => "/var/log/secure"
type => "secure"
start_position => "beginning"
}
}
output {
if [type] == "system" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-system-%{+YYYY.MM.dd}"
}
}
if [type] == "secure" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-secure-%{+YYYY.MM.dd}"
}
}
}
运行logstash指定elk.conf配置文件,进行过滤匹配
# logstash -f ./elk.conf
这些设置都没有问题之后,接下来安装下kibana,可以让在前台展示
Kibana的安装及使用
安装kibana环境
官方安装手册:https://www.elastic.co/guide/en/kibana/current/install.html
下载kibana的tar.gz的软件包
# wget https://artifacts.elastic.co/downloads/kibana/kibana-5.4.0-linux-x86_64.tar.gz
解压kibana的tar包
# tar -xzf kibana-5.4.0-linux-x86_64.tar.gz
进入解压好的kibana
# mv kibana-5.4.0-linux-x86_64 /usr/local
创建kibana的软连接
# ln -s /usr/local/kibana-5.4.0-linux-x86_64/ /usr/local/kibana
编辑kibana的配置文件
# vim /usr/local/kibana/config/kibana.yml
修改配置文件如下,开启以下的配置
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://192.168.1.202:9200"
kibana.index: ".kibana"
安装screen,以便于kibana在后台运行(当然也可以不用安装,用其他方式进行后台启动)
# yum -y install screen
# screen
# /usr/local/kibana/bin/kibana
netstat -antp |grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 17007/node
打开浏览器并设置对应的index
http://IP:5601

二、ELK实战篇
好,现在索引也可以创建了,现在可以来输出nginx、apache、message、secrue的日志到前台展示(Nginx有的话直接修改,没有自行安装)
编辑nginx配置文件,修改以下内容(在http模块下添加)
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domian":"$host",'
'"host":"$server_addr",'
'"size":"$body_bytes_sent",'
'"responsetime":"$request_time",'
'"referer":"$http_referer",'
'"ua":"$http_user_agent"'
'}';
修改access_log的输出格式为刚才定义的json
access_log logs/elk.access.log json;
继续修改apache的配置文件
LogFormat "{ \
\"@timestamp\": \"%{%Y-%m-%dT%H:%M:%S%z}t\", \
\"@version\": \"1\", \
\"tags\":[\"apache\"], \
\"message\": \"%h %l %u %t \\\"%r\\\" %>s %b\", \
\"clientip\": \"%a\", \
\"duration\": %D, \
\"status\": %>s, \
\"request\": \"%U%q\", \
\"urlpath\": \"%U\", \
\"urlquery\": \"%q\", \
\"bytes\": %B, \
\"method\": \"%m\", \
\"site\": \"%{Host}i\", \
\"referer\": \"%{Referer}i\", \
\"useragent\": \"%{User-agent}i\" \
}" ls_apache_json
一样修改输出格式为上面定义的json格式
CustomLog logs/access_log ls_apache_json
编辑logstash配置文件,进行日志收集
vim /etc/logstash/conf.d/full.conf
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
file {
path => "/var/log/secure"
type => "secure"
start_position => "beginning"
}
file {
path => "/var/log/httpd/access_log"
type => "http"
start_position => "beginning"
}
file {
path => "/usr/local/nginx/logs/elk.access.log"
type => "nginx"
start_position => "beginning"
}
}
output {
if [type] == "system" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-system-%{+YYYY.MM.dd}"
}
}
if [type] == "secure" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-secure-%{+YYYY.MM.dd}"
}
}
if [type] == "http" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-http-%{+YYYY.MM.dd}"
}
}
if [type] == "nginx" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-nginx-%{+YYYY.MM.dd}"
}
}
}
运行看看效果如何
logstash -f /etc/logstash/conf.d/full.conf
可以发现所有创建日志的索引都已存在,接下来就去Kibana创建日志索引,进行展示(按照上面的方法进行创建索引即可),看下展示的效果

接下来再来一发MySQL慢日志的展示
由于MySQL的慢日志查询格式比较特殊,所以需要用正则进行匹配,并使用multiline能够进行多行匹配(看具体配置)
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
file {
path => "/var/log/secure"
type => "secure"
start_position => "beginning"
}
file {
path => "/var/log/httpd/access_log"
type => "http"
start_position => "beginning"
}
file {
path => "/usr/local/nginx/logs/elk.access.log"
type => "nginx"
start_position => "beginning"
}
file {
path => "/var/log/mysql/mysql.slow.log"
type => "mysql"
start_position => "beginning"
codec => multiline {
pattern => "^# User@Host:"
negate => true
what => "previous"
}
}
}
filter {
grok {
match => { "message" => "SELECT SLEEP" }
add_tag => [ "sleep_drop" ]
tag_on_failure => []
}
if "sleep_drop" in [tags] {
drop {}
}
grok {
match => { "message" => "(?m)^# User@Host: %{USER:User}\[[^\]]+\] @ (?:(?<clienthost>\S*) )?\[(?:%{IP:Client_IP})?\]\s.*# Query_time: %{NUMBER:Query_Time:float}\s+Lock_time: %{NUMBER:Lock_Time:float}\s+Rows_sent: %{NUMBER:Rows_Sent:int}\s+Rows_examined: %{NUMBER:Rows_Examined:int}\s*(?:use %{DATA:Database};\s*)?SET timestamp=%{NUMBER:timestamp};\s*(?<Query>(?<Action>\w+)\s+.*)\n# Time:.*$" }
}
date {
match => [ "timestamp", "UNIX" ]
remove_field => [ "timestamp" ]
}
}
output {
if [type] == "system" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-system-%{+YYYY.MM.dd}"
}
}
if [type] == "secure" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-secure-%{+YYYY.MM.dd}"
}
}
if [type] == "http" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-http-%{+YYYY.MM.dd}"
}
}
if [type] == "nginx" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-nginx-%{+YYYY.MM.dd}"
}
}
if [type] == "mysql" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-mysql-slow-%{+YYYY.MM.dd}"
}
}
}查看效果(一条慢日志查询会显示一条,如果不进行正则匹配,那么一行就会显示一条)

具体的日志输出需求,进行具体的分析
三:ELK终极篇
安装reids
# yum install -y redis
修改redis的配置文件
# vim /etc/redis.conf
修改内容如下
daemonize yes
bind 192.168.1.202
启动redis服务
# /etc/init.d/redis restart
测试redis的是否启用成功
# redis-cli -h 192.168.1.202
输入info如果有不报错即可
redis 192.168.1.202:6379> info
redis_version:2.4.10
....
编辑配置redis-out.conf配置文件,把标准输入的数据存储到redis中
# vim /etc/logstash/conf.d/redis-out.conf
添加如下内容
input {
stdin {}
}
output {
redis {
host => "192.168.1.202"
port => "6379"
password => 'test'
db => '1'
data_type => "list"
key => 'elk-test'
}
}
运行logstash指定redis-out.conf的配置文件
# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/redis-out.conf运行成功以后,在logstash中输入内容(查看下效果)

编辑配置redis-in.conf配置文件,把reids的存储的数据输出到elasticsearch中
# vim /etc/logstash/conf.d/redis-out.conf
添加如下内容
input{
redis {
host => "192.168.1.202"
port => "6379"
password => 'test'
db => '1'
data_type => "list"
key => 'elk-test'
batch_count => 1 #这个值是指从队列中读取数据时,一次性取出多少条,默认125条(如果redis中没有125条,就会报错,所以在测试期间加上这个值)
}
}
output {
elasticsearch {
hosts => ['192.168.1.202:9200']
index => 'redis-test-%{+YYYY.MM.dd}'
}
}
运行logstash指定redis-in.conf的配置文件
# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/redis-out.conf
把之前的配置文件修改一下,变成所有的日志监控的来源文件都存放到redis中,然后通过redis在输出到elasticsearch中
更改为如下,编辑full.conf
input {
file {
path => "/var/log/httpd/access_log"
type => "http"
start_position => "beginning"
}
file {
path => "/usr/local/nginx/logs/elk.access.log"
type => "nginx"
start_position => "beginning"
}
file {
path => "/var/log/secure"
type => "secure"
start_position => "beginning"
}
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
if [type] == "http" {
redis {
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_http'
}
}
if [type] == "nginx" {
redis {
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_nginx'
}
}
if [type] == "secure" {
redis {
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_secure'
}
}
if [type] == "system" {
redis {
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_system'
}
}
}
运行logstash指定shipper.conf的配置文件
# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/full.conf
在redis中查看是否已经将数据写到里面(有时候输入的日志文件不产生日志,会导致redis里面也没有写入日志)
把redis中的数据读取出来,写入到elasticsearch中(需要另外一台主机做实验)
编辑配置文件
# vim /etc/logstash/conf.d/redis-out.conf
添加如下内容
input {
redis {
type => "system"
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_system'
batch_count => 1
}
redis {
type => "http"
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_http'
batch_count => 1
}
redis {
type => "nginx"
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_nginx'
batch_count => 1
}
redis {
type => "secure"
host => "192.168.1.202"
password => 'test'
port => "6379"
db => "6"
data_type => "list"
key => 'nagios_secure'
batch_count => 1
}
}
output {
if [type] == "system" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-system-%{+YYYY.MM.dd}"
}
}
if [type] == "http" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-http-%{+YYYY.MM.dd}"
}
}
if [type] == "nginx" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-nginx-%{+YYYY.MM.dd}"
}
}
if [type] == "secure" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-secure-%{+YYYY.MM.dd}"
}
}
}
注意:
input是从客户端收集的
output是同样也保存到192.168.1.202中的elasticsearch中,如果要保存到当前的主机上,可以把output中的hosts修改成localhost,如果还需要在kibana中显示,需要在本机上部署kabana,为何要这样做,起到一个松耦合的目的
说白了,就是在客户端收集日志,写到服务端的redis里或是本地的redis里面,输出的时候对接ES服务器即可
运行命令看看效果
# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/redis-out.conf效果是和直接往ES服务器输出一样的(这样是先将日志存到redis数据库,然后再从redis数据库里取出日志)

上线 ELK
1. 日志分类
系统日志 rsyslog logstash syslog插件
访问日志 nginx logstash codec json
错误日志 file logstash mulitline
运行日志 file logstash codec json
设备日志 syslog logstash syslog插件
Debug日志 file logstash json 或者 mulitline
2. 日志标准化
路径 固定
格式 尽量json
3. 系统个日志开始-->错误日志-->运行日志-->访问日志因为ES保存日志是永久保存,所以需要定期删除一下日志,下面命令为删除指定时间前的日志
curl -X DELETE http://xx.xx.com:9200/logstash-*-`date +%Y-%m-%d -d "-$n days"`













 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









