






背景
有这样一个案例。客户备库意外宕机,从集群日志只看出发生了主备切换,备库一直持续恢复备库没有成功,从数据库日志看到如下报错:
terminating connection because of crash of another server process
DETAIL: The kingbase has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
根据报错提示,怀疑当时并发太高,或者业务繁忙导致shared_buffer不够用,进而导致数据库宕机。由于V8R3版本数据库没有办法收集kwr报告,所以不容易定位这个判断。
分析
现在模拟实验:
测试环境:
[
shared_buffer 设置成16MB
max_wal_size 设置成32MB
create table test01(id integer, val char(1024));
insert into test01 values(generate_series(1,2888600),repeat( chr(int4(random()*26)+65),1024));
TEST=# create table test01(id integer, val char(1024));
CREATE TABLE
TEST=# insert into test01 values(generate_series(1,2888600),repeat( chr(int4(random()*26)+65),1024));
等待......
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.[
ps命令看到了每个process,其中process13674占用了大量内存
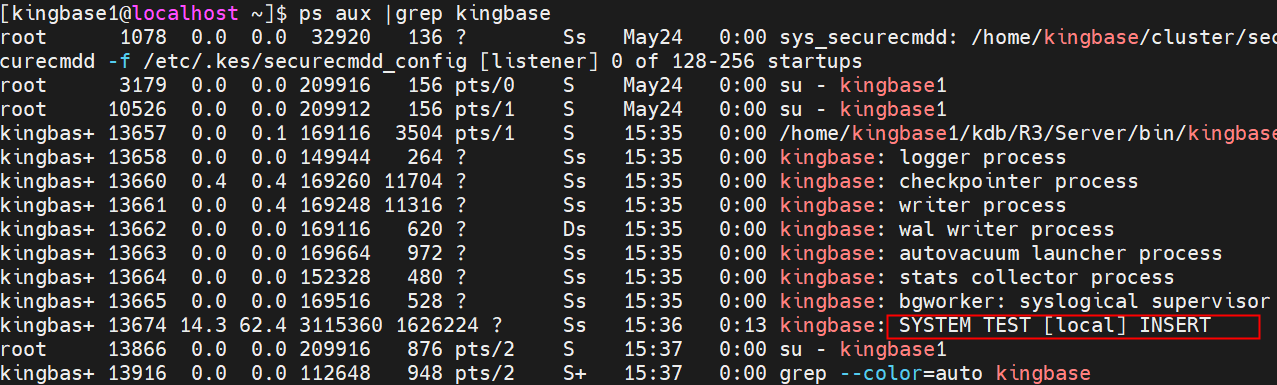
数据库日志警告发生corrupted shared memory 。实例崩溃,发生重启。
在这之前触发了大量检查点,这也符合预期,因为已经把max_wal_size调的足够小。需要不断写出page以保证足够的shared_buffer满足insert。
数据库也给出了合理建议增加参数“max_wal_size”大小。
[
2022-05-25 15:38:04 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:05 CST LOG: checkpoints are occurring too frequently (1 second apart)
2022-05-25 15:38:05 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:05 CST LOG: checkpoints are occurring too frequently (0 seconds apart)
2022-05-25 15:38:05 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:06 CST LOG: checkpoints are occurring too frequently (1 second apart)
2022-05-25 15:38:06 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:07 CST LOG: checkpoints are occurring too frequently (1 second apart)
2022-05-25 15:38:07 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:07 CST LOG: checkpoints are occurring too frequently (0 seconds apart)
2022-05-25 15:38:07 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:07 CST LOG: checkpoints are occurring too frequently (0 seconds apart)
2022-05-25 15:38:07 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:09 CST LOG: checkpoints are occurring too frequently (2 seconds apart)
2022-05-25 15:38:09 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:09 CST LOG: checkpoints are occurring too frequently (0 seconds apart)
2022-05-25 15:38:09 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:10 CST LOG: checkpoints are occurring too frequently (1 second apart)
2022-05-25 15:38:10 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:12 CST LOG: checkpoints are occurring too frequently (2 seconds apart)
2022-05-25 15:38:12 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:12 CST LOG: checkpoints are occurring too frequently (0 seconds apart)
2022-05-25 15:38:12 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:12 CST LOG: checkpoints are occurring too frequently (0 seconds apart)
2022-05-25 15:38:12 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:13 CST LOG: checkpoints are occurring too frequently (1 second apart)
2022-05-25 15:38:13 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:14 CST LOG: checkpoints are occurring too frequently (1 second apart)
2022-05-25 15:38:14 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:15 CST LOG: checkpoints are occurring too frequently (1 second apart)
2022-05-25 15:38:15 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:15 CST LOG: checkpoints are occurring too frequently (0 seconds apart)
2022-05-25 15:38:15 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:15 CST LOG: checkpoints are occurring too frequently (0 seconds apart)
2022-05-25 15:38:15 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:16 CST LOG: checkpoints are occurring too frequently (1 second apart)
2022-05-25 15:38:16 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:17 CST LOG: checkpoints are occurring too frequently (1 second apart)
2022-05-25 15:38:17 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:17 CST LOG: checkpoints are occurring too frequently (0 seconds apart)
2022-05-25 15:38:17 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:18 CST LOG: checkpoints are occurring too frequently (0 seconds apart)
2022-05-25 15:38:18 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:18 CST LOG: checkpoints are occurring too frequently (1 second apart)
2022-05-25 15:38:18 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:18 CST LOG: checkpoints are occurring too frequently (0 seconds apart)
2022-05-25 15:38:18 CST HINT: Consider increasing the configuration parameter "max_wal_size".
2022-05-25 15:38:19 CST LOG: server process (PID 13674) was terminated by signal 9: Killed
2022-05-25 15:38:19 CST DETAIL: Failed process was running: insert into test01 values(generate_series(1,2888600),repeat( chr(int4(random()*26)+65),1024));
2022-05-25 15:38:19 CST LOG: terminating any other active server processes
2022-05-25 15:38:19 CST WARNING: terminating connection because of crash of another server process
2022-05-25 15:38:19 CST DETAIL: The kingbase has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
2022-05-25 15:38:19 CST HINT: In a moment you should be able to reconnect to the database and repeat your command.
2022-05-25 15:38:19 CST LOG: all server processes terminated; reinitializing
2022-05-25 15:38:19 CST LOG: database system was interrupted; last known up at 2022-05-25 15:38:19 CST
2022-05-25 15:38:19 CST LOG: database system was not properly shut down; automatic recovery in progress
2022-05-25 15:38:19 CST LOG: redo starts at 0/8F050338
2022-05-25 15:38:19 CST LOG: redo wal segment count 1
2022-05-25 15:38:19 CST LOG: invalid record length at 0/8FA6C178: wanted 24, got 0
2022-05-25 15:38:19 CST LOG: complete: 1/1
2022-05-25 15:38:19 CST LOG: redo done at 0/8FA6C108
2022-05-25 15:38:19 CST LOG: MultiXact member wraparound protections are now enabled
2022-05-25 15:38:19 CST LOG: redo done at 0/8FA6C108
2022-05-25 15:38:19 CST LOG: MultiXact member wraparound protections are now enabled
2022-05-25 15:38:19 CST LOG: database system is ready to accept connections
2022-05-25 15:38:19 CST LOG: autovacuum launcher started
2022-05-25 15:38:19 CST LOG: starting syslogical supervisor
2022-05-25 15:38:19 CST LOG: starting syslogical database manager for database TEST
2022-05-25 15:38:19 CST LOG: manager worker [13929] at slot 0 generation 1 detaching cleanly
2022-05-25 15:38:20 CST LOG: starting syslogical database manager for database TEMPLATE1
2022-05-25 15:38:20 CST LOG: manager worker [13930] at slot 0 generation 2 detaching cleanly
2022-05-25 15:38:20 CST LOG: starting syslogical database manager for database TEMPLATE2
2022-05-25 15:38:20 CST LOG: manager worker [13932] at slot 0 generation 3 detaching cleanly
2022-05-25 15:38:20 CST LOG: starting syslogical database manager for database SAMPLES
2022-05-25 15:38:20 CST LOG: manager worker [13935] at slot 0 generation 4 detaching cleanly
2022-05-25 15:38:20 CST LOG: starting syslogical database manager for database SECURITY
2022-05-25 15:38:20 CST LOG: manager worker [13940] at slot 0 generation 5 detaching cleanly[
再查看那个占用内存高的进程已经被干掉。
需要说明的是同样的环境,我在KingbaseV8R6上并没有复现,也没有发生宕机。能看到插入时间比较慢,看到进程占用内存没有如此之高。
总结:
由于突然性大并发导致数据库资源使用上限是常有之事,我们尽量和业务协商保持业务稳定,如有新上业务要提前评估内存,cpu,io使用情况后做决定。是否有可用内存以供增加,不然很容易像以上例子导致数据库崩溃。
尽量升级到高版本规避此问题。或在系统级限定资源消费上限。















 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









