







1. 背景
在项目中,我们通常会把查询频率高的查询结构进行缓存。比如说首页的一些数据,热搜文章等。当大量用户发起查询是,借助缓存提高查询效率,降低数据库雅丽。
常见的缓存有很多,比如Redis, Memcached, Guava, Caffeine等
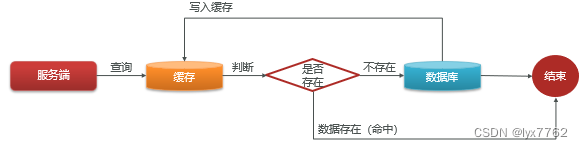
在引入缓存之后,查询的步骤如下
- 当用户发起查询,会先从缓存中查询数据。
- 如果数据存在,则直接返回数据
- 如果数据不存在,则需要到数据库中查询数据。查询完成后,将结果保存到缓存中,并且返回数据
2. 问题分析
在使用缓存时,代码往往遵循下面的写法

这种方式存在的诸多的问题:
- 代码繁杂重复,操作缓存的代码和核心的业务代码融合在一起
- 都是硬编码操作,后续一旦变更缓存数据源,那么所有的代码都需要重写。
针对上述的问题,我们可以很好的利用Spring中的AOP特性解决。
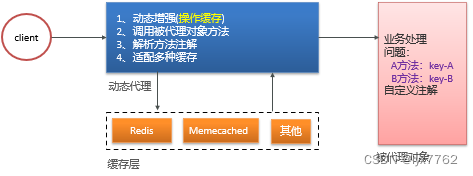
利用动态代理的方式,在代理类中处理缓存的相关操作,同时调用被代理类中的方法,从而可以使操作缓存的代码和业务代码分离,并且后期修改缓存数据源,也只需要修改代理类中的方法即可。
以上就是Spring Cache的原理。Spring Cache是Spring提供的通用缓存框架。它利用了AOP,实现了基于注解的缓存功能,使开发者不用关心底层使用了什么缓存框架,只需要简单地加一个注解,就能实现缓存功能了。用户使用Spring Cache,可以快速开发一个很不错的缓存功能。
3. Spring Cache的使用
3.1 使用步骤
Spring Cache的使用步骤由一下三步:
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
开启缓存
在启动类上添加@EnableCaching注解
配置注解
注意:Spring Cache默认的缓存时ConcurrentHashMap
3.2 常见的注解
3.2.1 @Cacheable
@Cacheable注解表示这个方法有了缓存的功能,方法的返回值会被缓存下来,下一次调用该方法前,会去检查是否缓存中已经有值,如果有就直接返回,不调用方法。如果没有,就调用方法,然后把结果缓存起来。
/**
* value:名称空间(分组)
* key: 支持springel
* redis-key的命名规则:
* value + "::" + key
*/
@Cacheable(value="user" , key = "'test' + #id")
public User findById(Long id) {
return userDao.findById(id);
}
3.2.2 @CachePut
加了@CachePut注解的方法,会把方法的返回值put到缓存里面缓存起来,供其它地方使用。
@CachePut(value="user" , key = "'test' + #id")
public User findById(Long id) {
return userDao.findById(id);
}
注意:
@CachePut注解只会将方法的返回值添加到缓存中,本身并不会去访问缓存
3.2.3 @CacheEvit
使用了@CacheEvict注解的方法,会清空指定缓存。可以清空命名空间下的所有的缓存,也可以清空指定key的缓存。
@CacheEvict(value="user" , key = "'test' + #id")
public void update(Long id) {
userDao.update(id);
}
3.2.4 @CacheEvit
Java代码中,同个方法,一个相同的注解只能配置一次。如若操作多个缓存,可以使用@Caching
同时删除test+userId和userId两个key
@Caching(
evict = {
@CacheEvict(value="user" , key = "'test' + #id"),
@CacheEvict(value="user" , key = "#id")
}
)
public void update(Long id) {
userDao.update(id);
}















 1247
1247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









