






 本文使用Python分析了一年的微信聊天记录,通过时间维度统计、词云图和词频分析,揭示了发送者和接收者之间的交流模式,以及不同时间段的聊天趋势。
本文使用Python分析了一年的微信聊天记录,通过时间维度统计、词云图和词频分析,揭示了发送者和接收者之间的交流模式,以及不同时间段的聊天趋势。
大家好,我是蛋挞~
你们好不好奇,过去一年时间里,都和对象聊了些什么…(啥?你没对象 )
)
作为数据分析师,绝不能靠印象说话,要用数据。所以本文用Python分析过去一年和媳妇的微信聊天记录,从月、周、日、小时等时间维度做出一些统计分析及可视化,然后通过jieba分词、统计词频来绘制词云图。
有点意思呦,一起来看看吧!
一、获取数据并处理
- 首先,通过工具把微信聊天记录导出来,形成csv文件。
# 看看数据长啥样
msg_data = pd.read_csv('微信聊天记录.csv')
msg_data.head()

2.然后,取出2023年的数据,做一些前处理工作。
# 只取2023年的数据
msg_data['date'] = msg_data['StrTime'].str[:10]
msg_data['year'] = msg_data['StrTime'].str[:4]
msg_data['month'] = msg_data['StrTime'].str[5:7]
msg_data['hour'] = msg_data['StrTime'].str[11:13]
msg_data_2023 = msg_data[msg_data['year'] == '2023']
msg_data_2023.reset_index(drop=True, inplace=True)
# 计算是周几
msg_data_2023 = msg_data_2023.copy()
msg_data_2023.loc[:, 'time_datetime'] = pd.to_datetime(msg_data_2023.loc[:,'StrTime'])
msg_data_2023.loc[:, 'day_of_week_number'] = msg_data_2023.loc[:, 'time_datetime'].dt.dayofweek
day_names_zh = {0: '周一', 1: '周二', 2: '周三', 3: '周四', 4: '周五', 5: '周六', 6: '周日'}
msg_data_2023['day_of_week'] = msg_data_2023['day_of_week_number'].map(day_names_zh)
del msg_data_2023['time_datetime']
msg_data_2023['StrContent'] = msg_data_2023['StrContent'].astype(str)
msg_data_2023.head()
3.对Type列和IsSender列做一些转换
Type列为消息类型,比如1表示文本,3表示图片,49表示文件等。IsSender列,1表示自己,0表示对方。
二、简单的数据统计
1.2023年365天,我们聊了355天。
msg_data_2023['date'].nunique() # 355
2.2023年一共发了23784条消息,共161869字,平均每条消息8个字。其中,我发了11554条消息,她发了12230条消息。
# 行数统计
msg_data_2023.shape[0]
# 字数统计
total_chars_and_punctuation = msg_data_2023['StrContent'].apply(count_chinese_chars_and_punctuation).sum()
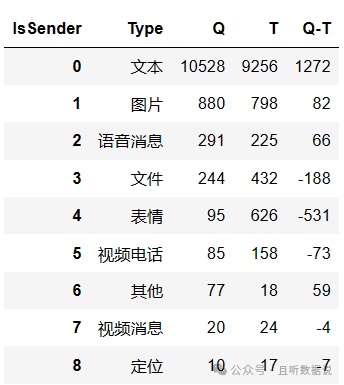
3.对各种消息类型进行统计
可以看出,她爱发文本消息,而我更爱打视频电话,足足多了73次,差不多是她的两倍,哈哈哈!另外,我好像特别特别爱发表情,她的6倍…
# 各自发的消息类型
msg_type_stat = msg_data_2023.groupby(['IsSender', 'Type'])['StrContent'].size().reset_index(name='count')
msg_type_stat = msg_type_stat.reset_index(drop=True)
msg_type_stat = msg_type_stat.pivot_table(index = ['Type'], columns= 'IsSender', values='count', fill_value=0)
msg_type_stat.reset_index(inplace=True)
sorted_msg_type_stat = msg_type_stat.sort_values(by='Q', ascending=False)
sorted_msg_type_stat.reset_index(drop=True, inplace=True)
sorted_msg_type_stat['Q-T'] = sorted_msg_type_stat['Q'] - sorted_msg_type_stat['T']
sorted_msg_type_stat
4.很好奇,哪次聊得最久
设定5分钟内回的消息都为1次聊天,超过了就不算。经计算发现:最长的时长为2368秒,即39分钟,发生在2023-04-20 22:00:12 ~ 2023-04-20 22:39:40。看来还是晚上有得聊些…
三、数据可视化
- 消息数按月统计
msg_month = msg_data_2023.groupby(['month'])['StrContent'].size().reset_index(name='count')
# 绘制柱状图
plt.figure(figsize=(10, 6))
plt.bar(msg_month['month'], msg_month['count'], color='orange', width=0.5, edgecolor='black', label='Values')
plt.legend()
plt.title('消息数按月统计')
plt.xlabel('月份')
plt.ylabel('消息数量')
plt.grid(axis='y', alpha=0.75)
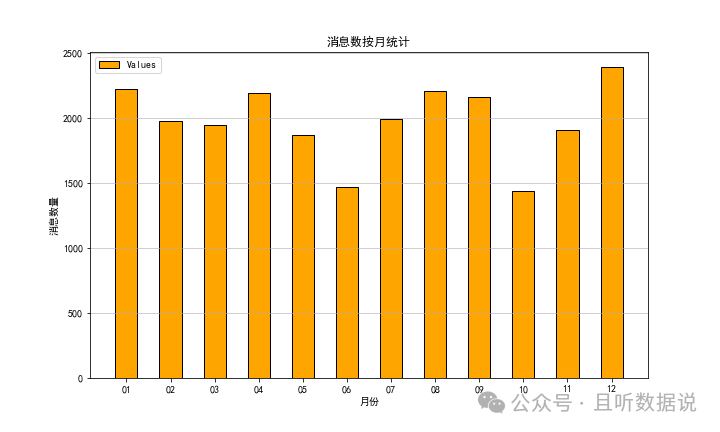
10月份聊得最少,因为有个国庆节,天天在一起,消息数自然少,数据正常。而12月消息数最多,也是非常合理的,因为那时快临近我们的婚期了,太多的事情需要沟通了。
2.消息数按周统计
msg_week = msg_data_2023.groupby(['day_of_week', 'day_of_week_number'])['StrContent'].size().reset_index(name='count')
sorted_msg_week = msg_week.sort_values(by='day_of_week_number', ascending=True)
sorted_msg_week.reset_index(drop=True, inplace=True)
# 雷达图
labels = sorted_msg_week['day_of_week'].values
data_week = list(sorted_msg_week['count'].values)
angles = np.linspace(0, 2 * np.pi, len(labels), endpoint=False).tolist()
data = np.concatenate((data_week, [data_week[0]]))
angles = np.concatenate((angles, [angles[0]]))
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, data, 'o-', linewidth=2)
ax.fill(angles, data, alpha=0.25)
ax.set_thetagrids((angles * 180/np.pi)[:7], labels)
ax.set_title("消息数按周几统计")
plt.show()
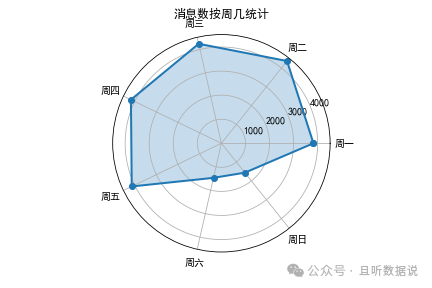
可以看到,周一到周五消息数非常平均,周末数量骤减。是的,你没猜错,我们是周末夫妻,工作日在两地上班,周末才会相聚。
3.消息数按日统计
msg_day = msg_data_2023.groupby(['date'])['StrContent'].size().reset_index(name='count')
msg_day.loc[:, 'date_datetime'] = pd.to_datetime(msg_day.loc[:,'date'])
del msg_day['date']
# 设置日期为索引
msg_day.set_index('date_datetime', inplace=True)
date_range = pd.date_range(start='2023-01-01', end='2023-12-31', freq='D')
msg_day_resampled = msg_day.asfreq(freq='D', fill_value=0)
msg_day_resampled.reset_index(inplace=True)
# 绘制每日热力图,没聊天的日期置为0
year = msg_day_resampled['date_datetime'].dt.year.unique()[0] # 假设所有日期都在同一年
week_number = msg_day_resampled['date_datetime'].dt.isocalendar().week
day_of_week = msg_day_resampled['date_datetime'].dt.dayofweek # 0代表周一,6代表周日
heatmap_data = msg_day_resampled.pivot_table(index=week_number, columns=day_of_week, values='count', aggfunc='sum').fillna(0)
fig = plt.figure(figsize=(12, 6))
pink_cmap = sns.diverging_palette(240, 10, as_cmap=True)
sns.heatmap(heatmap_data, cmap=pink_cmap, annot=False, fmt='d', linewidths=0.5)
plt.xlabel('周几 (0=Mon, 6=Sun)')
plt.ylabel('周数')
plt.title('消息数每日热力图')
plt.show()
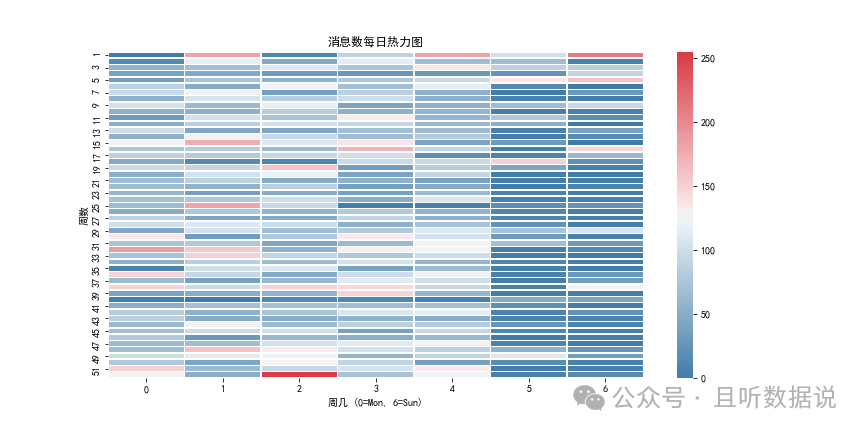 工作日每天消息数差不多,偶尔几天会多点,周末的颜色较深,表示消息数明显少些。颜色为红色的几天都聊了些啥,不会是吵架了吧
工作日每天消息数差不多,偶尔几天会多点,周末的颜色较深,表示消息数明显少些。颜色为红色的几天都聊了些啥,不会是吵架了吧
4.消息数按小时统计
msg_hour = msg_data_2023.groupby(['hour'])['StrContent'].size().reset_index(name='count')
categories = list(msg_hour['hour'].values)
values = list(msg_hour['count'].values)
# 创建颜色映射并提取颜色
colormap = cm.get_cmap('Reds', 24)
colors = [colormap(i / 23) for i in range(24)]
N = len(categories)
angles = np.linspace(0, 2 * np.pi, N, endpoint=False).tolist()
values = values + values[:1]
angles = angles + angles[:1]
# 创建极坐标图
fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(polar=True))
for i in range(N):
ax.bar(angles[i], values[i], width=0.20, bottom=0.0, color=colors[i % len(colors)])
ax.set_yticklabels([])
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories)
plt.gca().spines['polar'].set_visible(False)
plt.title('消息数按小时统计', va='bottom')
plt.show()
这里采用了南丁格尔玫瑰图****!
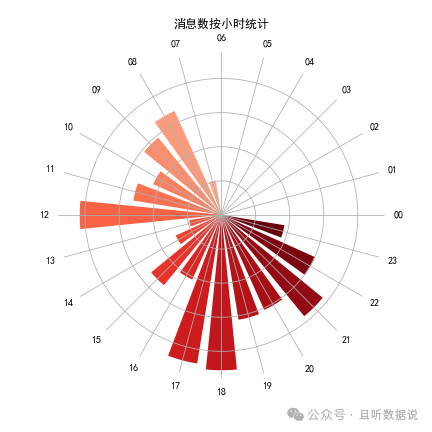
可以看出来,12点,17、18点,21点多的时间聊得比较多,基本都是饭点或者是晚上下班后,非常符合日常的聊天习惯。
四、最有趣的词云
- 先把聊天记录合在一起
msg_T = filtered_df[filtered_df['IsSender'] == 'T'].loc[:, 'StrContent'].to_frame()
msg_Q = filtered_df[filtered_df['IsSender'] == 'Q'].loc[:, 'StrContent'].to_frame()
msg_all = ','.join(map(str, filtered_df['StrContent']))
msg_join_T = ','.join(map(str, msg_T['StrContent']))
msg_join_Q = ','.join(map(str, msg_Q['StrContent']))
2.先绘制总的词云,然后绘制各自的词云
# 使用jieba进行分词
words_list_jieba = jieba.lcut(msg_all)
words_list = [x for x in words_list_jieba if x not in excluded_words]
# 使用Counter进行词频统计
word_counter = Counter(words_list)
sorted_file = word_counter.most_common()
mask = np.array(Image.open("7.jpg"))
# 生成词云时指定遮罩
tmp_wordcloud = WordCloud(font_path='C:\Windows\Fonts\simhei.ttf',
background_color='white',
mask=mask)
wordcloud = tmp_wordcloud.generate_from_frequencies(dict(sorted_file))
# 显示词云图
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
所有聊天记录的词云,我们是最大的两个字,划重点,要考!

她聊天记录的词云,我们依然是第一位,然后是……买买买,哈哈哈。和我了解的她一模一样,爱购物,乐观积极。

最后再来看看我的词云,重点词:我们、下班、买。看来下班真是件幸福的事,几乎每次下班都说一声!
关于买字,我需要狡辩解释一下 一般都是我让她买,不是我买,毕竟经济大权在她那。
一般都是我让她买,不是我买,毕竟经济大权在她那。

以上就是本次分享的全部内容。如果你有兴趣,后台回复【聊天分析】,即可获得完整的代码。
我是蛋挞,我们下期见~
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python70个实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】
















 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









