转自:http://blog.csdn.net/Best_Coder/article/details/42127033
之前一直对这个算法搞不懂,看到这个博主写的一篇博文,感觉挺好的,就转过来了,再次感谢博主
介绍adaboost算法之前,首先介绍一下学习算法的强弱,这个是PAC定义的:弱学习算法---识别错误率小于1/2(即准确率仅比随机猜测略高的学习算法),强学习算法---识别准确率很高并能在多项式时间内完成的学习算法。
接着我就用我所理解的例子来介绍一下adaboost算法,相信看过这个计算过程大家对这个算法肯定有更深刻的理解,由于csdn插入公式比较困难,所以下面的步骤我就用word截图来表示了,对了先叙述一下adaboost算法的迭代过程吧,这样对后面的计算会理解的更深刻一些。
adaboost算法迭代过程:

有了adaboost算法的迭代过程,那么我们就可以利用已知的公式对上面的式子进行简化了,下面的公式应用的会更多一 些

推导部分就到这里好了,接下来就是用例子来帮助大家理解adaboost算法的过程了,恩,见证奇迹的时刻到来了



好了到了这里对adaboost算法的过程肯定是理解了吧,那么我接着来放一个code来实现一下这个过程,必定会加深大家对这个算法的理解,OK,开始。
- 01.
- 02.from __future__ import division
- 03.import numpy as np
- 04.import scipy as sp
- 05.from weakclassify import WEAKC
- 06.from dml.tool import sign
- 07.class ADABC:
- 08. def __init__(self,X,y,Weaker=WEAKC):
- 09. ''
-
-
-
-
-
- 15. self.X=np.array(X)
- 16. self.y=np.array(y)
- 17. self.Weaker=Weaker
- 18. self.sums=np.zeros(self.y.shape)
- 19. self.W=np.ones((self.X.shape[1],1)).flatten(1)/self.X.shape[1]
- 20. self.Q=0
- 21.
- 22. def train(self,M=4):
- 23. ''
-
-
- 26. self.G={}
- 27. self.alpha={}
- 28. for i in range(M):
- 29. self.G.setdefault(i)
- 30. self.alpha.setdefault(i)
- 31. for i in range(M):
- 32. self.G[i]=self.Weaker(self.X,self.y)
- 33. e=self.G[i].train(self.W)
- 34.
- 35. self.alpha[i]=1/2*np.log((1-e)/e)
- 36.
- 37. sg=self.G[i].pred(self.X)
- 38. Z=self.W*np.exp(-self.alpha[i]*self.y*sg.transpose())
- 39. self.W=(Z/Z.sum()).flatten(1)
- 40. self.Q=i
- 41.
- 42. if self.finalclassifer(i)==0:
- 43.
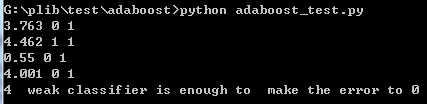
- 44. print i+1," weak classifier is enough to make the error to 0"
- 45. break
- 46. def finalclassifer(self,t):
- 47. ''
-
-
- 50. self.sums=self.sums+self.G[t].pred(self.X).flatten(1)*self.alpha[t]
- 51.
- 52. pre_y=sign(self.sums)
- 53.
- 54.
- 55.
- 56.
- 57.
- 58. t=(pre_y!=self.y).sum()
- 59. return t
- 60. def pred(self,test_set):
- 61. sums=np.zeros(self.y.shape)
- 62. for i in range(self.Q+1):
- 63. sums=sums+self.G[i].pred(self.X).flatten(1)*self.alpha[i]
- 64.
- 65. pre_y=sign(sums)
- 66. return pre_y
先试验下《统计学习方法》里面那个最简单的例子:
可以看到也是三个分类器就没有误分点了,权值的选择也是差不多的
其中后面那个-1 表示大于threshold分为负类,小于分为正类。1则相反
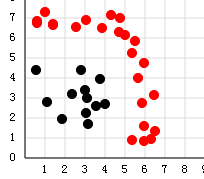
加一些其它数据试试:
结果:
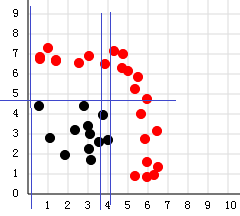
我们把图画出来就是:
基本还是正确的,这是四个子分类器的图,不是最后总分类器的图啊~~~




























 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









