






在完成查询任务的时候,查询需要在不同的地方花费时间,包括网络,CPU计算,生成统计信息和执行计划、锁等待(互斥等待)等操作,尤其是向底层存储引擎检索数据的调用操作,这些调用需要在内存操作、CPU操作和内存不足时导致的I/O操作上耗时间。根据存储引擎不同,可能还会产生大量的上下文切换以及系统调用。
在每一个消耗大量时间的查询案例中,我们都能看到一些不必要的额外操作,某些操作被额外地重复了很多次,某些操作执行的太慢等。优化查询的目的就是减少和消除这些操作所花费的时间。
再次申明一点,对于一个查询的全部生命周期,上面列的并不完整。这里我们只是想说明:了解查询的生命周期、清楚查询的时间消耗情况对于优化查询有很大的意义。有了这些概念,我们再一起看看如何优化查询。
在我们explain的时候,一般MYSQL能够使用如下三种方式应用WHERE条件,从好到坏依次是:
- 在索引中使用WHERE条件来过滤不匹配的记录。这是在存储引擎层完成的。
- 使用索引覆盖扫描(在Extra列中出现了Using index)来返回记录,直接从索引中过滤不需要的记录并返回命中的结果。这是在MySQL服务器层完成的,但无需再回表查询结果。
- 从数据表中返回数据,然后过滤不满足条件的记录(在Extra列中出现Using Where)。这在MySQL服务器层完成,MySQL需要先从数据表读出记录然后过滤。
有很多时候,我们explain的时候看到,MySQL扫描了大量的数据,但只返回了少数的行,那么通常可以尝试下面的技巧去优化它:
- 使用索引覆盖扫描,使用覆盖索引
- 改变库表结构。例如使用单独的汇总表(这是我们在第4章中讨论的办法)
- 重写这个复杂的查询,让MySQL优化器能够以更优化的方式执行这个查询。
重构查询的方式
1.一个复杂查询还是多个简单查询
设计查询的时候一个需要考虑的问题是,是否需要将一个复杂的查询分成多个简单的查询。在传统实现中,总是强调需要数据库层完成尽可能多的工作,这样做的逻辑在于以前总是认为网络通信,查询解析和优化是一件代价很高的额事情。但是这样的想法对于MySQL并不适用,MySQL从设计上让连接和断开连接都很轻量级,在返回一个小的查询结果方面很高效。现代的网络速度比以前要快很多,无论是带宽还是延迟。早某些版本的MySQL上,即使在一个通用服务器上,也能够运行每秒超过10万的查询,即使是一个千兆网卡也能轻松满足每秒超过2000次的查询。所以运行多个小查询现在已经不是大问题了。
不过,在应用设计的时候,如果一个查询能够胜任时还写成多个独立查询是不明智的。例如,我们看到有些应用对一个数据表做10次独立的查询来返回10行数据,每个查询返回一条结果,查询10次!
查询执行的基础
当优化MySQL能够以更高的性能运行查询时,最好的办法就是弄清楚MySQL是如何优化和执行查询的。一旦理解这一点,很多查询工作实际上就i时遵循一些原则让优化器能够按照预想的合理方式进行。
换句话说,是时候回头看看我们前面讨论的内容了:MySQL执行一个查询的过程。根据下图我们可以看到当向MySQL发送一个请求的时候,MySQL道理做了些什么:
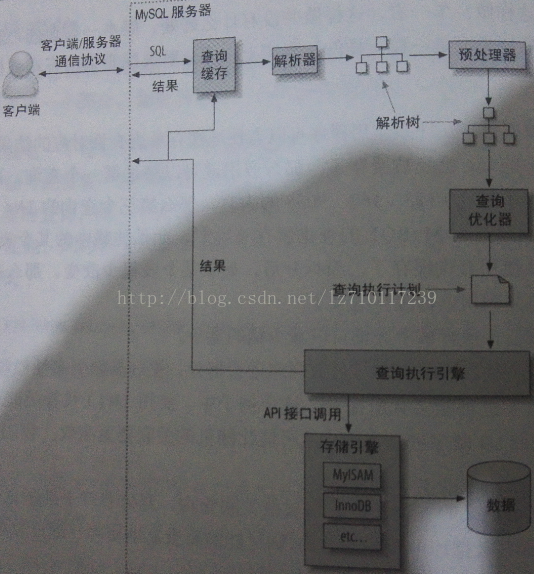
- 客户端发送一条查询给服务器。
- 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一个阶段
- 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
- MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询。
- 将结果返回给客户端
上面的每一步都比想象的复杂。我们在后续的博客中再进行讨论。我们会看到在每个阶段查询处于何种状态。查询优化器是其中特别复杂也特别难理解的部分。还有很多的例外情况,例如,当查询使用绑定变量后,执行路径会有所不同,我们后面会进行讨论。














 1761
1761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









