




1.调用库函数
从0开始查找第一次出现目标字符或者串的位置,找到返回位置,未找到返回string::npos。
#include <iostream>
#include <string>
using namespace std;
int main(){
string str1="Alpha Beta Gamma Delta";
int loc = str1.find('t');//查找单个字符,从0开始
int loc2=str1.find("ph");//查找字符串
if( loc != string::npos )
cout << "Found Be at " << loc << endl;//输出字符位置
else
cout << "Didn't find Be" << endl;
if( loc2 != string::npos )//输出字符串位置
cout << "Found ph at " << loc2 << endl;
else
cout << "Didn't find ph" << endl;
return 0;
}
2.简单匹配
从主串的第一位起和模式串的第一个字符开始比较,如果相等,则继续逐一比较后续字符;否则从主串的第二个字符开始重新比较,以此类推,直到比较完模式串的所有字符,匹配成功返回模式串的位置,不成功返回“0”。
#include <iostream>
#include <string>
using namespace std;
//简单匹配
int easy_find(string str,string substr){
int i=0,j=0,k=i;//k记录主串匹配位置
while(i<str.length()&&j<substr.length()){
if(str[i]==substr[j]){
++i;
++j;
}else{
j=0;//子串回首位
i=++k;//主串右移
}
}
if(j==substr.length()){
return k;//返回位置
}else{
return 0;//未找到
}
}
int main(){
string s="abdefg";
string subs1="ef";
string subs2="deg";
cout<<easy_find(s,subs1)<<endl;
cout<<easy_find(s,subs2)<<endl;
return 0;
}
3.KMP算法
(1)

首先,主串"BBC ABCDAB ABCDABCDABDE"的第一个字符与模式串"ABCDABD"的第一个字符,进行比较。因为 B 与 A 不匹配,所以模式串后移一位。
(2) 因为 B 与 A 又不匹配,模式串再往后移。
因为 B 与 A 又不匹配,模式串再往后移。
(3)
就这样,直到主串有一个字符,与模式串的第一个字符相同为止。
(4)
接着比较主串和模式串的下一个字符,还是相同。
(5)
直到主串有一个字符,与模式串对应的字符不相同为止。
(6)
这时,最自然的反应是,将模式串整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。
(7)
一个基本事实是,当空格与 D 不匹配时,你其实是已经知道前面六个字符是"ABCDAB"。KMP 算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,而是继续把它向后移,这样就提高了效率。
(8)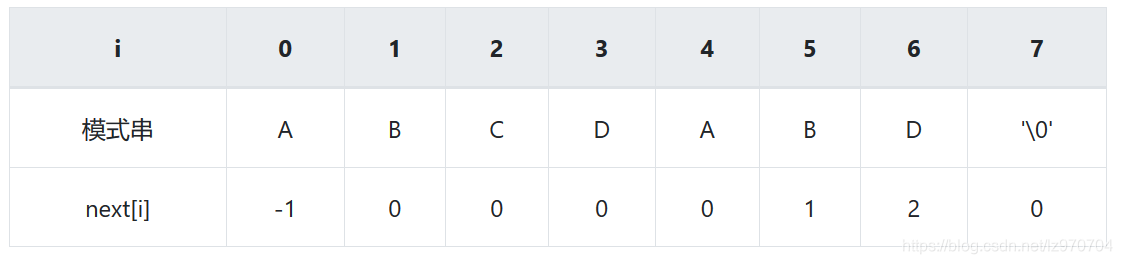
怎么做到这一点呢?可以针对模式串,设置一个跳转数组int next[],这个数组是怎么计算出来的,后面再介绍,这里只要会用就可以了。
(9)
已知空格与 D 不匹配时,前面六个字符"ABCDAB"是匹配的。根据跳转数组可知,不匹配处 D 的 next 值为 2,因此接下来从模式串下标为 2 的位置开始匹配。
(10)
因为空格与 C 不匹配,C 处的 next 值为 0,因此接下来模式串从下标为 0 处开始匹配。
(11)
因为空格与 A 不匹配,此处 next 值为 -1,表示模式串的第一个字符就不匹配,那么直接往后移一位。
(12)
逐位比较,直到发现 C 与 D 不匹配。于是,下一步从下标为 2 的地方开始匹配。
(13)
逐位比较,直到模式串的最后一位,发现完全匹配,于是搜索完成。
next数组:
next 数组的求解基于“真前缀”和“真后缀”,即next[i]等于P[0]…P[i - 1]最长的相同真前后缀的长度(请暂时忽视 i 等于 0 时的情况,下面会有解释)。
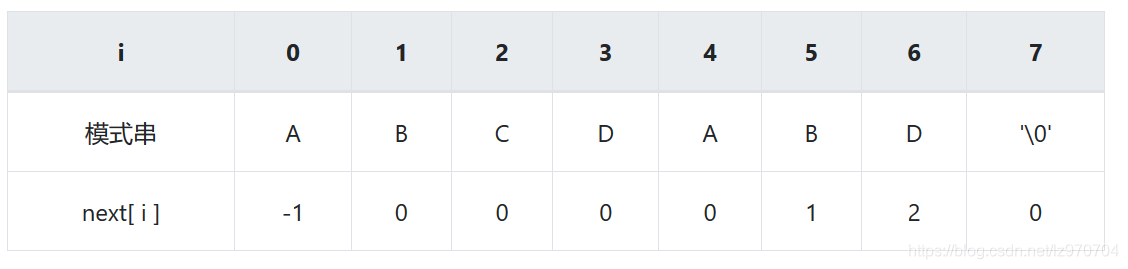
i = 0,对于模式串的首字符,我们统一为next[0] = -1;
i = 1,前面的字符串为A,其最长相同真前后缀长度为 0,即next[1] = 0;
i = 2,前面的字符串为AB,其最长相同真前后缀长度为 0,即next[2] = 0;
i = 3,前面的字符串为ABC,其最长相同真前后缀长度为 0,即next[3] = 0;
i = 4,前面的字符串为ABCD,其最长相同真前后缀长度为 0,即next[4] = 0;
i = 5,前面的字符串为ABCDA,其最长相同真前后缀为A,即next[5] = 1;
i = 6,前面的字符串为ABCDAB,其最长相同真前后缀为AB,即next[6] = 2;
i = 7,前面的字符串为ABCDABD,其最长相同真前后缀长度为 0,即next[7] = 0。
那么,为什么根据最长相同真前后缀的长度就可以实现在不匹配情况下的跳转呢?举个代表性的例子:假如i = 6时不匹配,此时我们是知道其位置前的字符串为ABCDAB,仔细观察这个字符串,首尾都有一个AB,既然在i = 6处的 D 不匹配,我们为何不直接把i = 2处的 C 拿过来继续比较呢,因为都有一个AB啊,而这个AB就是ABCDAB的最长相同真前后缀,其长度 2 正好是跳转的下标位置。
有的读者可能存在疑问,若在i = 5时匹配失败,按照我讲解的思路,此时应该把i = 1处的字符拿过来继续比较,但是这两个位置的字符是一样的啊,都是B,既然一样,拿过来比较不就是无用功了么?其实不是我讲解的有问题,也不是这个算法有问题,而是这个算法还未优化,关于这个问题在下面会详细说明,不过建议读者不要在这里纠结,跳过这个,下面你自然会恍然大悟。
思路如此简单,接下来就是代码实现了,如下:
/* P 为模式串,下标从 0 开始 */
void GetNext(string P, int next[])
{
int p_len = P.size();
int i = 0; // P 的下标
int j = -1;
next[0] = -1;
while (i < p_len)
{
if (j == -1 || P[i] == P[j])
{
i++;
j++;
next[i] = j;
}
else
j = next[j];
}
}
一脸懵逼,是不是。。。上述代码就是用来求解模式串中每个位置的next[]值。
下面具体分析,我把代码分为两部分来讲:
(1)i 和 j 的作用是什么?
i 和 j 就像是两个”指针“,一前一后,通过移动它们来找到最长的相同真前后缀。
(2)if…else语句里做了什么?
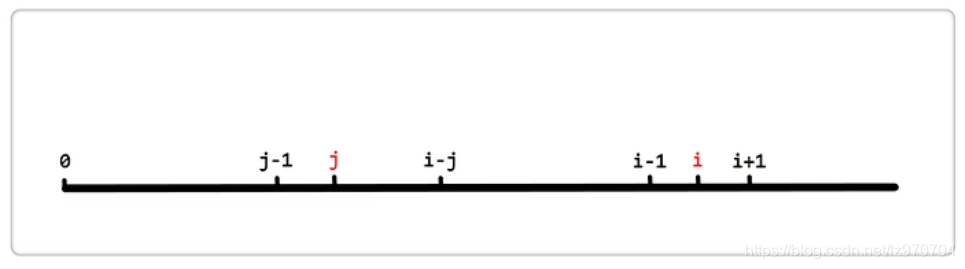
假设 i 和 j 的位置如上图,由next[i] = j得,也就是对于位置 i 来说,区段 [0, i - 1] 的最长相同真前后缀分别是 [0, j - 1] 和 [i - j, i - 1],即这两区段内容相同。
按照算法流程,if (P[i] == P[j]),则i++; j++; next[i] = j;;若不等,则j = next[j],见下图:
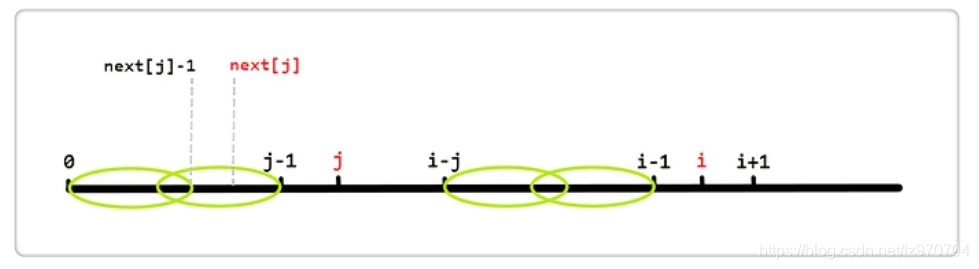
next[j]代表 [0, j - 1] 区段中最长相同真前后缀的长度。如图,用左侧两个椭圆来表示这个最长相同真前后缀,即这两个椭圆代表的区段内容相同;同理,右侧也有相同的两个椭圆。所以 else 语句就是利用第一个椭圆和第四个椭圆内容相同来加快得到 [0, i - 1] 区段的相同真前后缀的长度。
细心的朋友会问 if 语句中j == -1存在的意义是何?第一,程序刚运行时,j 是被初始为 -1,直接进行P[i] == P[j]判断无疑会边界溢出;第二,else 语句中j = next[j],j 是不断后退的,若 j 在后退中被赋值为 -1(也就是j = next[0]),在P[i] == P[j]判断也会边界溢出。综上两点,其意义就是为了特殊边界判断。
完整代码:
#include <iostream>
#include <string>
using namespace std;
/* P 为模式串,下标从 0 开始 */
void GetNext(string P, int next[])
{
int p_len = P.size();
int i = 0; // P 的下标
int j = -1;
next[0] = -1;
while (i < p_len)
{
if (j == -1 || P[i] == P[j])
{
i++;
j++;
next[i] = j;
}
else
j = next[j];
}
}
/* 在 S 中找到 P 第一次出现的位置 */
int KMP(string S, string P, int next[])
{
GetNext(P, next);
int i = 0; // S 的下标
int j = 0; // P 的下标
int s_len = S.size();
int p_len = P.size();
while (i < s_len && j < p_len) // 因为末尾 '\0' 的存在,所以不会越界
{
if (j == -1 || S[i] == P[j]) // P 的第一个字符不匹配或 S[i] == P[j]
{
i++;
j++;
}
else
j = next[j]; // 当前字符匹配失败,进行跳转
}
if (j == p_len) // 匹配成功
return i - j;
return -1;
}
int main()
{
int next[100] = { 0 };
cout << KMP("bbc abcdab abcdabcdabde", "abcdabd", next) << endl; // 15
return 0;
}
优化:
/* P 为模式串,下标从 0 开始 */
void GetNextval(string P, int nextval[])
{
int p_len = P.size();
int i = 0; // P 的下标
int j = -1;
nextval[0] = -1;
while (i < p_len)
{
if (j == -1 || P[i] == P[j])
{
i++;
j++;
if (P[i] != P[j])
nextval[i] = j;
else
nextval[i] = nextval[j]; // 既然相同就继续往前找真前缀
}
else
j = nextval[j];
}
}

















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









