







本章介绍在数据可获得的情况下,输入建模常用的拟合概率分布法,以及如何在建模时体现变量间的相关性。
使用到的数据:链接:https://pan.baidu.com/s/132MhiYHNQzo9RbMI2-o-NQ
提取码:2ch3
在数据可获得的情况下,输入建模的三种方法:
- 使用分析概率分布(拟合概率分布法)
- 使用历史数据(与模拟相比,有大量的历史数据)
- 重采样(与模拟相比,数据较少)
历史数据法(如:直接使用历史数据表示模型中的需求)和重采样(如:从历史销售数据中随机选择一个值来表示模型中的需求)法较为简单,实践中也经常使用。但需注意,因为均使用的是历史数据,因此结果永远不能超出观察到的数据。这可能会限制预测可能发生的不确定事件。此外,很难在输入中反映依赖关系。
拟合概率分布法
第1步:找到代表数据的概率分布,并将该分布与数据相匹配
第2步:通过测试(拟合优度检验)和图形分析检查与数据的匹配情况:
1. 拟合优度检验:
- 卡方检验
- 科尔莫戈罗夫-斯米尔诺夫(KS)试验
- 安德森-达林(AD)测试
- AIC/BIC测试
卡方检验提供直方图(对于连续数据)或折线图(对于离散数据)与拟合密度(对于连续数据)或质量函数(对于离散数据)的正式比较;KS 和 AD 检验将经验分布函数与假设分布的分布函数进行比较。AD 测试检测到尾部的差异,并且比 KS 测试具有更高的功效;AIC 和 BIC 使用似然函数来找到最适合手头数据的分布;KS、AD 和 AIC/BIC 测试仅在存在从连续来源中提取的数据时才有用。对于离散数据,我们必须使用卡方检验。
2. 图形比较:
- 基于直方图的绘图
- 概率图
- P-P图
- Q-Q图
基于直方图的图比较(以图形方式)数据的直方图与拟合分布的密度函数。它们对我们在形成直方图时如何对数据进行分组很敏感。另一方面,概率图以图形方式将数据真实分布函数的估计值与拟合的分布函数进行比较;QQ (PP) 图 放大了模型尾部(中间)与样本分布函数之间的差异。如果选择的分布拟合良好,则 QQ 和 PP 图将近似线性(即位于 y=x 线上)。
处理相关数据
在使用拟合概率分布法后,我们可以得到数据的分布。但是在输入建模的过程中,往往涉及多个变量,在找到这些变量对应的分布后,我们还需要考虑这些变量之前的相关性。即在建模时将相关性也纳入考量。
案例:
呼叫中心正在检查其关于呼叫者投诉的数据。确定了两个投诉领域:由于与代理商交谈的等待时间过长而投诉的客户,以及由于代理商经验不足而投诉的客户。每个数据集包括每周的投诉数量。Excel文件Assignment3_Problem1_数据包括这两个类别去年的投诉数据。数据如下:
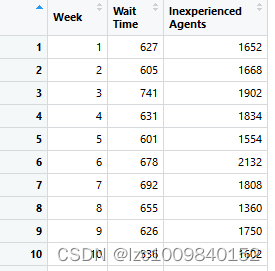
目标:
a、 每类每周投诉的分布情况如何?确定分布的名称及其平均值和标准偏差。拟合数据的连续分布,并使用K-S检验作为拟合优度标准。
b、 这两类每周投诉是否相互关联?如果是,请描述它们的相关性。
创建模拟,包括两个输入变量:
1. 与代理交谈的等待时间导致的每周投诉;2. 于由经验不足的代理导致的每周投诉。
使用(a)中确定的已确定分布。如果投诉类型之间存在相关性,请将其包含模型中。使用仿真模型,回答以下问题。
c、 每周投诉总数的平均值和标准差是多少?
d、 每周平均投诉的95%置信区间是多少?解释这个时间间隔。
e、 一周内投诉总数少于600的概率是多少?
f、 一周内投诉总数超过2600起的可能性有多大?
问题a
每类每周投诉的分布情况如何?确定分布的名称及其平均值和标准偏差。拟合数据的连续分布,并使用K-S检验作为拟合优度标准。
读取数据:
library(matrixcalc)
library(Matrix)
library(MultiRNG)
library(tidyverse)
library(fitdistrplus)
library(extraDistr)
library(readxl)
setwd("C:/Users/10098/Desktop/AD616/616a3")
data <- read_excel("metad616_Assignment3_Problem1_Data.xlsx")先找等待时间最合适的概率分布,由于不知道是哪个概率分布,因此把最有可能的几个都试试(如:正态分布,逻辑分布,柯西分布,指数正态分布,韦伯分布)
#finding distributions of `Wait Time`
nw <- fitdist(data$`Wait Time`,'norm') # 正态分布
lw <- fitdist(data$`Wait Time`,'logis') # 逻辑分布
cw <- fitdist(data$`Wait Time`,'cauchy') # 柯西分布
lnw <- fitdist(data$`Wait Time`,'lnorm') # 指数正态分布
ww <- fitdist(data$`Wait Time`,'weibull') # 韦伯分布
gofstat(list(nw,lw,cw,lnw,ww)) #norm is the best
nw$estimate #mean is 606.75000, sd is 82.73913 根据K-S检验(第一行),如果检验统计量D大于从表中获得的临界值,则拒绝关于分布形式的假设。其余几行是别的拟合优度检验,比如四五行对应AIC/BIC测试。由于题目要求按K-S检验,所以我们只看第一行。

第一行有5个分布对应的检验统计量(0.055,0.065,0.096,0.056,0.722)。如何看呢:
KS 检验 P 值表
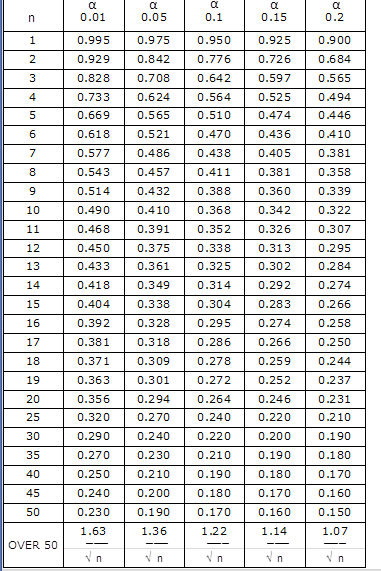
我们这里n是52,对于5%的α水平,P值是1.36/根号下52,为0.188。(0.055,0.065,0.096,0.056,0.722)即正态分布,逻辑分布,柯西分布,指数正态分布都被接受。但0.055最小,因此这里选正态分布。利用nw$estimate 可得到分布的参数:mean is 606.75000, sd is 82.73913
可以观察一下数据和正态分布的拟合图片比较
plot(nw) #提供正态分布的图片比教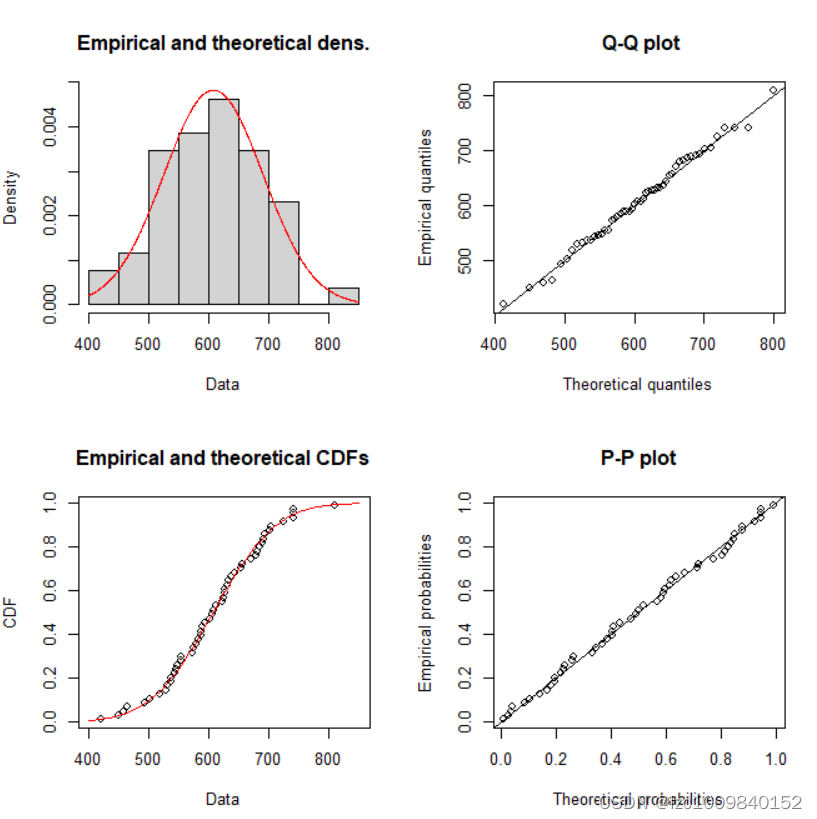
对‘经验不足的代理商投诉’也是同样的操作,结果为逻辑分布最合适。得到分布的参数:location is 1609.7146, scale is 143.2525
#finding distributions of `Inexperienced Agents`
ni <- fitdist(data$`Inexperienced Agents`,'norm')
li <- fitdist(data$`Inexperienced Agents`,'logis')
ci <- fitdist(data$`Inexperienced Agents`,'cauchy')
lni <- fitdist(data$`Inexperienced Agents`,'lnorm')
wi <- fitdist(data$`Inexperienced Agents`,'weibull')
gofstat(list(ni,li,ci,lni,wi)) #logis is the best
plot(li)
li$estimate #location is 1609.7146, scale is 143.2525问题b
这两类每周投诉是否相互关联?如果是,请描述它们的相关性。
首先,为什么要判断两类每周投诉的相关性?
案例中有两个投诉领域:
1. 由于与代理商交谈的等待时间过长而投诉的客户
2. 由于代理商经验不足而投诉的客户。
我们可以发现,与代理商交谈的等待时间过长很可能正是因为代理商经验不足导致的,即数据2和数据1之间本身就有可能有很强的相关性。而我们使用拟合概率分布法,虽然找到了这两类数据的概率分布,但是丧失了之间的相关性。进而我们在模型数据输入的时候,可能产生和实际较大的偏差。因此,我们需要观察相关性。
cor(data$`Wait Time`, data$`Inexperienced Agents`, method = "spearman") ![]()
协方差为0.66,因此有较强的相关性。
问题c→f
设置按周计算投诉总数的模拟。模拟(模拟的内容在前面的章节中)中包括两个输入变量: 一个用于与代理交谈的等待时间导致的每周投诉,另一个用于由经验不足的代理导致的每周投诉。使用(a)中确定的已确定分布。如果投诉类型之间存在相关性,请将其包含模型中。使用仿真模型,回答以下问题。
c、 每周投诉总数的平均值和标准差是多少?
d、 每周平均投诉的95%置信区间是多少?解释这个时间间隔。
e、 一周内投诉总数少于600的概率是多少?
f、 一周内投诉总数超过2600起的可能性有多大?
按照要求,我们需要建立一个模型,其中两个变量既符合问题a中的分布,又符合问题b中的相关性。换言之,我们在输入建模的时候,需要使输入符合代表数据的特征(分布和相关性)
先保证相关性,创建相关性矩阵(利用问题b得到的协方差)
cm <- matrix(c(1 , 0.6612163 ,
0.6612163 , 1),
2,2)
检查一下相关性矩阵
is.positive.semi.definite(cm) # 检查是否为半正定的
这一步是常规操作,检查一下协方差矩阵是否正确(是否半正定),如果为否,则需要
psd_mat <- nearPD(cm, corr = T)$mat %>% as.matrix()建模:
n <- 1000
Udf <- draw.d.variate.uniform(n,2,cm) %>% as.data.frame()
colnames(Udf) <- c('Wait_Time','Inexperienced')
df <- data.frame(dW = qnorm(p = Udf$Wait_Time,
mean = nw$estimate['mean'],
sd = nw$estimate['sd']) %>% round(),
dI = qlogis(p = Udf$Inexperienced,
location = li$estimate['location'],
scale=li$estimate['scale']) %>% round()) 其中,draw.d.variate.uniform(n,2,cm)是产生n行,2个变量,符合cm相关性矩阵的随机数。效果如下:

然后利用生成的Udf,作为df中两个变量产生对应分布的分位数
如qnorm(0.85,mean=70,sd=3) 是找到平均值为 70 且标准差为 3 的正态分布的第 85 个百分位数
代码中 dW = qnorm(p = Udf$Wait_Time, mean = nw$estimate['mean'], sd = nw$estimate['sd'])
是找到平均值为 606.75000, 标准差为 82.73913(在问题a得到,mean = nw$estimate['mean'], sd = nw$estimate['sd'])的正态分布的第 Udf$Wait_Time 个百分位数。
加上round()四舍五入(因为投诉事件都是整数)。df 如下:
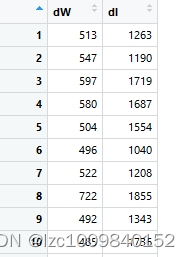
按照要求,现在dW和dI就是分别符合正态分布和逻辑分布,且相关性为0.6612163。
我们可以检查一下:

稍有误差,相关性为0.6665053,不过由于产生的本来就是随机数,且误差不大,在正常范围内。
开始回答c-f问题
c、 每周投诉总数的平均值和标准差是多少?
df$total <- df$dW + df$dI
mean(df$total) #2207.177
sd(df$total) #312.094d、 每周平均投诉的95%置信区间是多少?
margin <- qnorm(0.95)*sd(df$total)/sqrt(n)
lowerinterval <- mean(df$total) - margin #2190.943
upperinterval <- mean(df$total) + margin #2223.411e、 一周内投诉总数少于600的概率是多少?
f、 一周内投诉总数超过2600起的可能性有多大?
#e
sum(df2$total < 600)/n # 0
#f
sum(df2$total > 2600)/n #0.076大功告成!
内容源于波士顿大学,感谢教授David Ritt
















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











