




 本文全面介绍了计算机字符编码的发展历程,从ASCII编码到Unicode编码,涵盖了ISO-8859、BIG5、GB2312、GBK、GB18030等多种编码方案,并详细解释了UTF-8、UTF-16、UTF-32的不同实现。
本文全面介绍了计算机字符编码的发展历程,从ASCII编码到Unicode编码,涵盖了ISO-8859、BIG5、GB2312、GBK、GB18030等多种编码方案,并详细解释了UTF-8、UTF-16、UTF-32的不同实现。
“位”(bit)是计算机能够处理的最小单位,计算机领域一般说的“位”都是指二进制的“位”,我们实际生活中的“位”一般都是指十进制位。区别在于,是“逢几进一”,比如我们实际生活常用的都是十进制“逢十进一”,也就是说当“个位”上的数由9变成10时,表示方法是在“个位”上置0,在“十位”上加一。以此类推,相似地,二进制每个位上的值只能是0或1,是“逢二进一”。“字节”(Byte)是计算机用于计量存储容量的单位,通常8个二进制位组成1个字节。
一、ASCII编码
计算机起初是由美国研制出来供自己使用的,1个字节一共可以组合出256()种不同的组合。把所有基本常用的数学符号、0-9的数字、标点符号、大小写字母都用码表表示出来,一直编到第127号,这样计算机就可以用不同字节来存储英文文字了。其中把编号从0~31这32种状态分别规定了特殊的用途,把这32个0x20以下的字节状态称为"控制码"。 这个编码方案叫做“ASCII编码”(American Standard Code for Information Interchange,美国标准信息交换编码),码表如下:
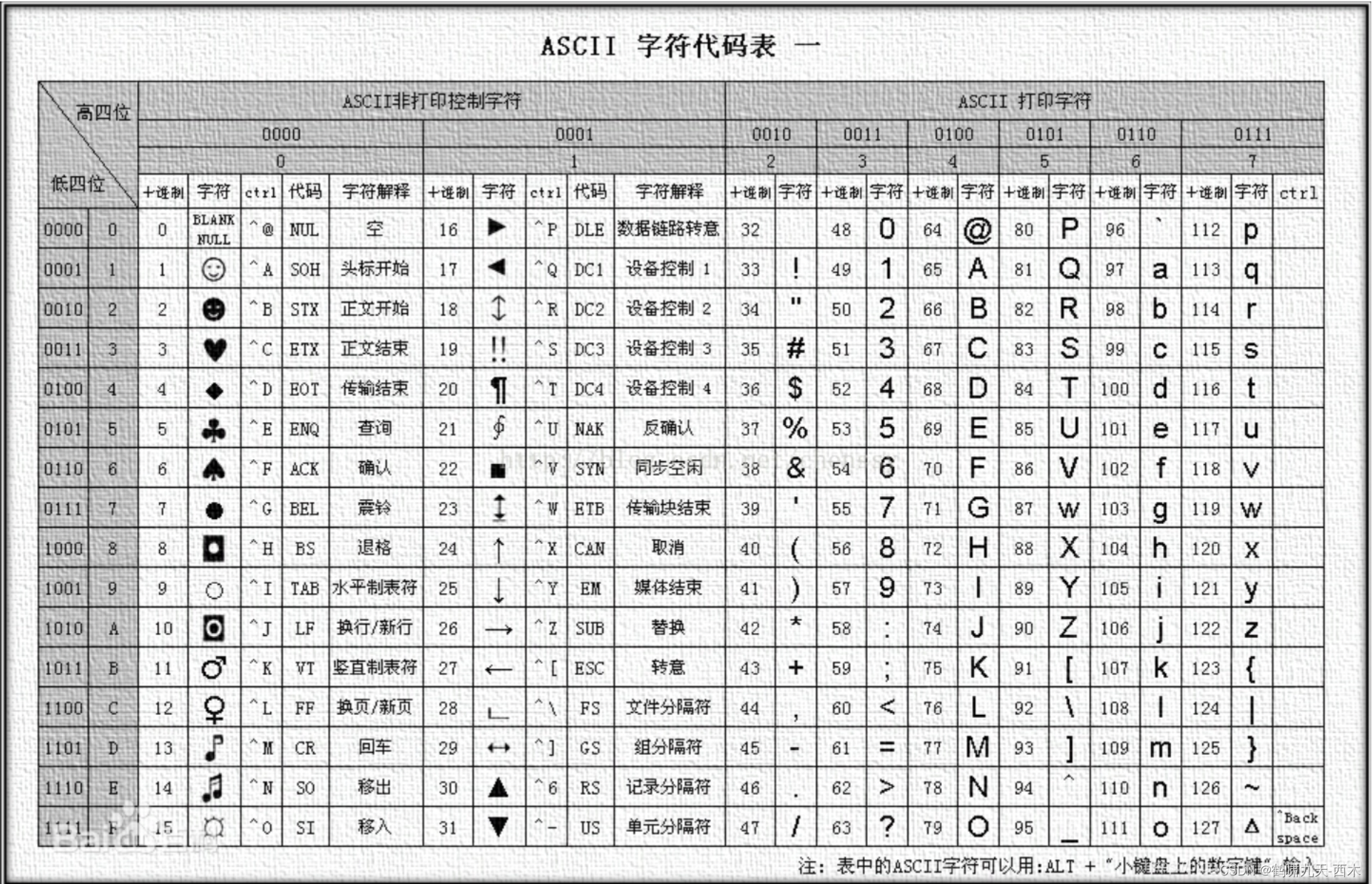
二、ISO-8859
随着计算机在世界的普及,很多国家用的不是英文,他们的字母里有许多是ASCII里没有的。为了支持多种地区的语言,各大组织机构或IT厂商开始发明它们自己的编码方案,以便弥补ASCII编码的不足。一时间,各种互不相容的字符编码方案成百花齐放之势。为了避免混乱,ISO组织(国际标准化组织 International Organization for Standardization,总部在瑞士)在1998年之后,陆续发表了一系列代号为8859的标准,作为ASCII编码的标准扩展,终于统一了单字节的字符编码方案。方案是采用127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。从128到255的字符集被称"扩展字符集"。ISO-8859标准是单字节编码标准,俗称“欧洲码”,包括:
ISO-8859-1(Latin1 - 西欧字符):覆盖了大多数西欧语言,包括:法国、西班牙、葡萄牙、意大利、荷兰、德国、丹麦、瑞典、挪威、芬兰、冰岛、爱尔兰、苏格兰、英格兰等,因而也涉及到了整个美洲大陆、澳大利亚和非洲很多国家的语言,后来被采纳为ISO-10646标准。
ISO-8859-2(Latin2 - 中、东欧字符)
ISO-8859-3(Latin3 - 南欧字符)
ISO-8859-4(Latin4 - 北欧字符)
ISO-8859-5(Cyrillic - 斯拉夫语)
ISO-8859-6(Arabic - 阿拉伯语)
ISO-8859-7(Greek - 希腊语)
ISO-8859-8(Hebrew - 希伯来语)
ISO-8859-9(Latin5)
ISO-8859-10(Latin6)
ISO-8859-11(Thai - 泰国语)
ISO-8859-12(保留)
ISO-8859-13(Latin7)
ISO-8859-14(Latin8)
ISO-8859-15(Latin9)
遗憾的是ISO-8859系列标准的字符编码之间是互不相容,不能同时使用的,而且ISO-8859系列标准的字符和多字节的编码方案(比如中文编码GB2312和BIG5)也是不相容的。
三、BIG5
等到亚洲人使用计算机时,1个字节8位二进制位里已经没有可以利用的位置来表示亚洲国家的字符(光中国就有6000多个常用汉字)。于是ISO组织又制定了ISO-2022标准(Character code structure and extension techniques),提供了7位与8位编码字符集的扩充方法的标准。一些亚洲国家和地区也制定了各自的字符编码标准,如日本的JIS0208,韩国的KSC5601,台湾地区的CNS11643等。
BIG5是从CNS11643的早期版本发展而来的,虽然没有包括CNS11643的全部内容,但却是目前台湾、香港地区普遍使用的一种繁体汉字的编码标准,包括440个符号,一级汉字5401个、二级汉字7652个,共计13060个汉字。
四、GB2312
根据ISO组织制定的ISO-2022标准(Character code structure and extension techniques),我国制定了国家标准GB2312。我们把ASCII编码中127号之后的奇异字符直接取消并规定:小于128的字符意义与原来相同,但两个大于127的字符连在一起就表示一个汉字,前面的一个字节(高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字。在这些编码里,还把数学符号、罗马希腊的字母、日文的假名都编进去了,连 ASCII 里本来就有的数字、标点、字母都统统重新编了双字节的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。 这种汉字编码方案就是 "GB2312"。GB2312 是对 ASCII 的简体中文扩展,共收录6763个简体汉字、682个符号,其中汉字部分:一级字3755,以拼音排序,二级字3008,以偏旁排序。该标准的制定和应用为规范、推动中文信息化进程起了很大作用。
五、GBK
但是中国的汉字太多了,GB2312只是编了常用字,那些不常用的以及生僻字还是没办法存储。于是不得不继续把 GB2312 没有用到的码位找出来用上,结果还是不够用。于是干脆不再要求低字节一定是ASCII编码中127号之后的字节,只要高字节是大于127就表示这是一个汉字的开始,不管后面跟的是不是ASCII扩展字符集里的内容,这种编码方案被称为 GBK 标准。GBK 包括了GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号,包含21003个汉字,也包含了ISO 10646中的全部中日韩文字、汉字简、繁体字。严格说,GBK不算是国家标准,最多算是一个商业标准。
六、GB18030
随着计算机在中国的普及,少数民族语言字符也需要编码,GBK扩成了GB18030。至此中华民族的文化就可以通过计算机传承了,而GB18030才成为真正的国家标准。
七、ISO-10646
汉字字符编码的特点是双字节的汉字字符和单字节的英文字符并存于同一套编码方案中,而当时各个国家都像中国这样搞了一套自己的编码标准,结果各个国家谁也不支持其他国家的编码。为此,ISO组织又制定了UCS标准(Universal Multiple-Octet Coded Character Set),也就是 ISO-10646 标准。
八、Unicode编码
在ISO-10646的基础上,Unicode学术学会(The Unicode Consortium)和ISO同步制定了Unicode编码方案。此时计算机的存储容量已经极大提升,存储空间再也不是问题,于是规定了使用双字节表示所有字符,对于ASCII编码里的前128个字符,Unicode编码中保持其编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码,16位共可以组合出65536个不同的字符。由于ASCII编码里的前128个字符只需要用到低8位,所以其高8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。至此从 Windows NT 开始,微软把操作系统都改用Unicode编码方式,无需加装各种本土语言系统就可以显示全世界上所有国家的字符了。
Unicode在制订时没有与已有字符编码方案的兼容,所以不同编码之间转化时只能通过查码表来进行转化,一般每种编程语言都有现成的方法可直接调用进行转化。Unicode常用的编码方式有:
1、UTF-32:
用32位二进制(即4个字节)表示一个字符,缺点也显而易见,如果是英文字符,实际只需1个字节,前3个字节都是0,造成存储浪费。比如字母A(ASCII码十进制是65,二进制是01000001)存储如下:
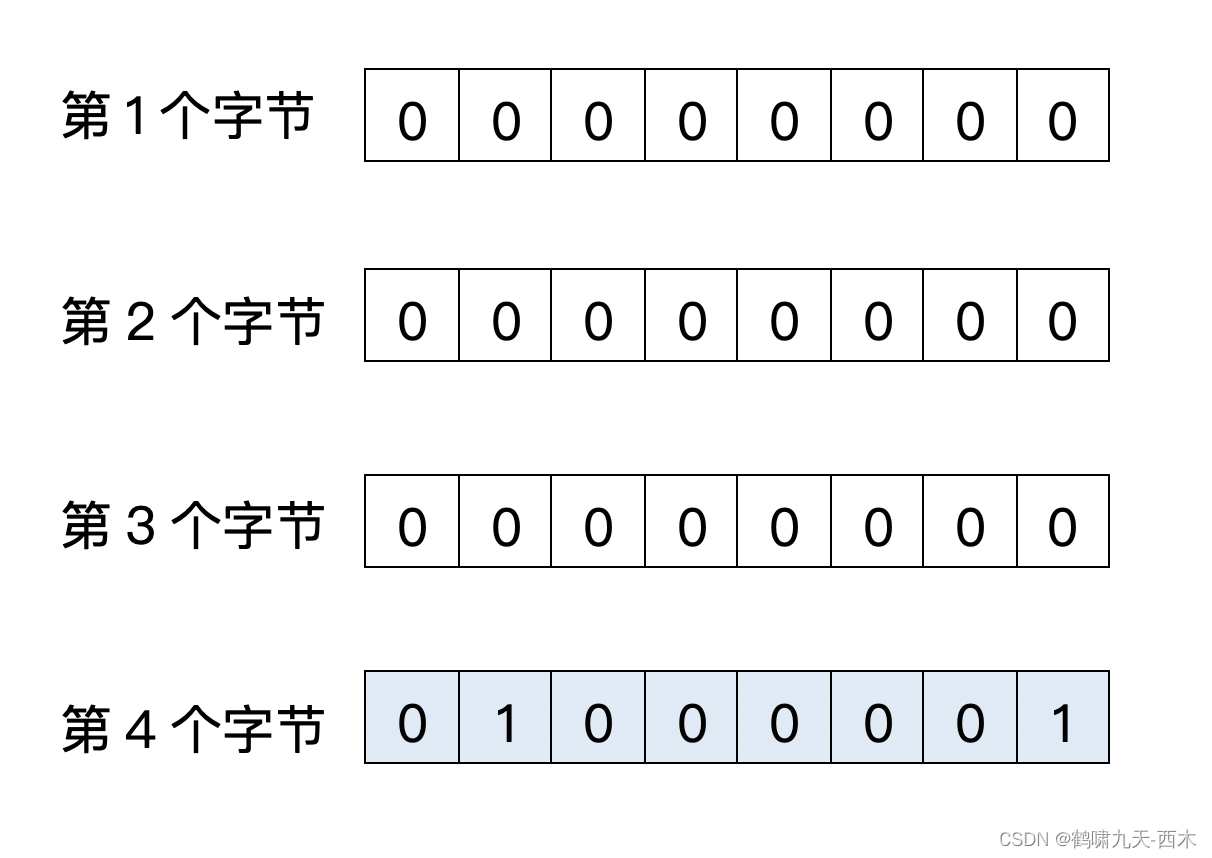
2、UTF-16:
鉴于UTF-32浪费存储空间的问题,基于UCS-2编码而产生了UTF-16编码,是Unicode最早的编码方式。UCS-2编码方式使用固定的2个字节保存字符编码,也就是0x0000~0xFFFF之间的字符,但如果是超过0xFFFF的字符就不能支持了。而UTF-16则可以表示0x0000~0x10FFFF之间的字符。处理方式是根据字符实际的编码长度,采用2个字节或者4个字节的方式进行存储。编码方法如下:
在2个字节(0x0000~0xFFFF)中,保留码值(0xD800~0xDFFF)不使用,其他的码值表示1个字符(用2个字节表示的字符)。不使用的这些码值共2048()个,如下图。如果是以下图11011开头的2个字节,则表示需要和另外以11011开头的2个字节共同表示1个字符。

这分别的2个字节,1个叫高代理码点,1个叫低代理码点,区别是第6个二进制位,如下图:
①高代理码点/码元(0xD800~0xDBFF)1024()个

②低代理码点/码元(0xDC00~0xDFFF) 1024()个

以码点(code point)为U+10437(不能用2个字节表示)的字符为例,按以下步骤转化:
❶将码点值减去0x10000(能用2字节表示的字符0x0000~0xFFFF的数量),得到一个20位长的二进制数:
作差:0x10437 - 0x10000=0x437,
二进制为:0100 0011 0111,
不足位补0,共20位:0000 0000 0100 0011 0111,
❷将20位从中间分成2个10位二进制:
数值高位:0000 0000 01
数值低位:00 0011 0111
❸0xD800与数据高位相加得到高代理码点,0xDC00与数据低位相加得到低代理码点
高代理码点 = 11011000 00000000 + 00000000 00000001 = 11011000 00000001 = 0xD801
低代理码点 = 11011100 00000000 + 00000000 00110111 = 11011100 00110111 = 0xDC37
所以最终码点为U+10437的字符UTF-16的编码是0xD801 0xDC37
3、UTF-8:
UTF-8是变长的编码方式,根据字符实际的编码长度,可以是1个字节,2个字节,3个字节或4个字节,所以就需要用标识位来标记当前这个字节是作为单独的字节编码存在的,还是和其他字节共同组成一个字符(或双字节,或三字节,或四字节)。编码方法如下:
| 字符占用的 字节数 | 字符实际使用的 二进制位数 | 字符使用的 最小二进制 | 字符使用的 最大二进制 | 第一个字节 | 第二个字节 | 第三个字节 | 第四个字节 |
|---|---|---|---|---|---|---|---|
| 1 | 7 | 0x0000 | 0x007F | 0XXXXXXX | 无 | 无 | 无 |
| 2 | 11 | 0x0080 | 0x07FF | 110XXXXX | 10XXXXXX | 无 | 无 |
| 3 | 16 | 0x0800 | 0xFFFF | 1110XXXX | 10XXXXXX | 10XXXXXX | 无 |
| 4 | 21 | 0x10000 | 0x10FFFF
| 11110XXX | 10XXXXXX | 10XXXXXX | 10XXXXXX |
规则如下:
①如果字节的最高位是0,说明当前字节是单独的1个字节表示1个字符

②如果字节的最高位是1,说明当前字节是和其他字节共同组合表示1个字符的
❶当从字节的高位往低位连续出现1的次数是1时(也就是字节的次高位是0),说明当前字节是低字节,需要和高字节共同表示1个字符;
❷当从字节的高位往低位连续出现1的次数大于1时,说明当前字节是高字节,1的个数表示是几个字节共同表示1个字符;
所以:
双字节字符编码如下:
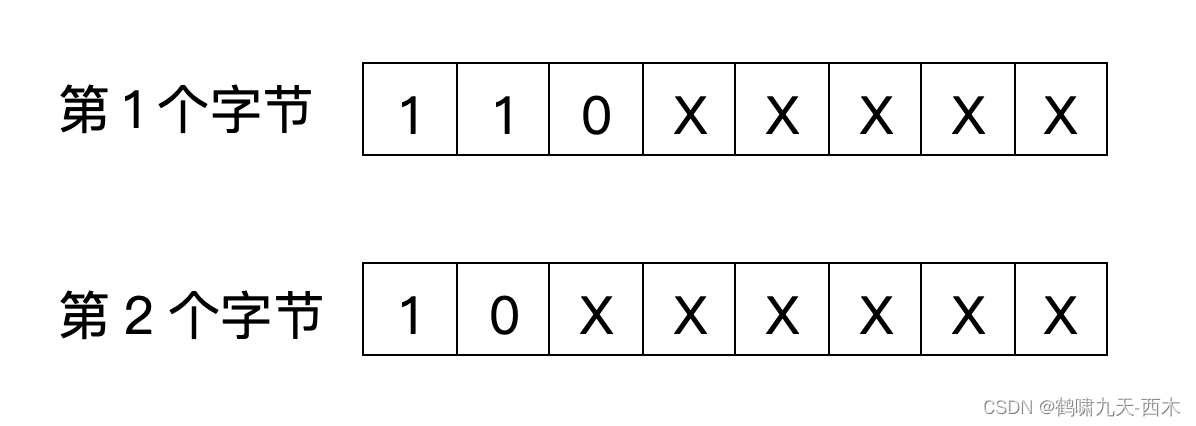
三字节字符编码如下:
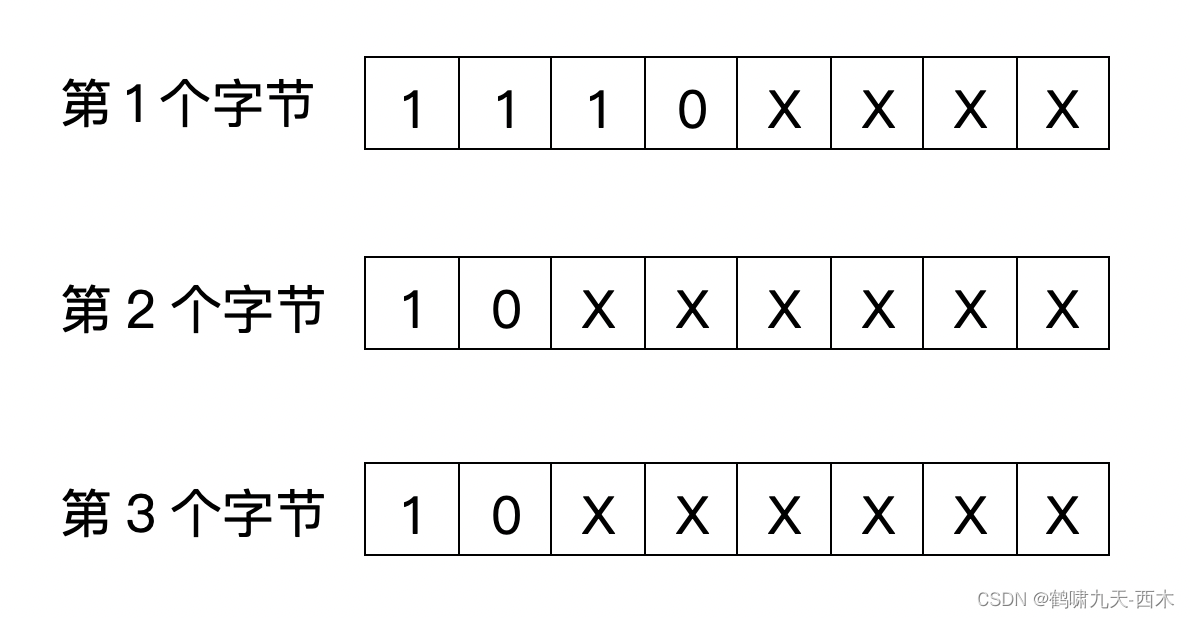
四字节字符编码如下:
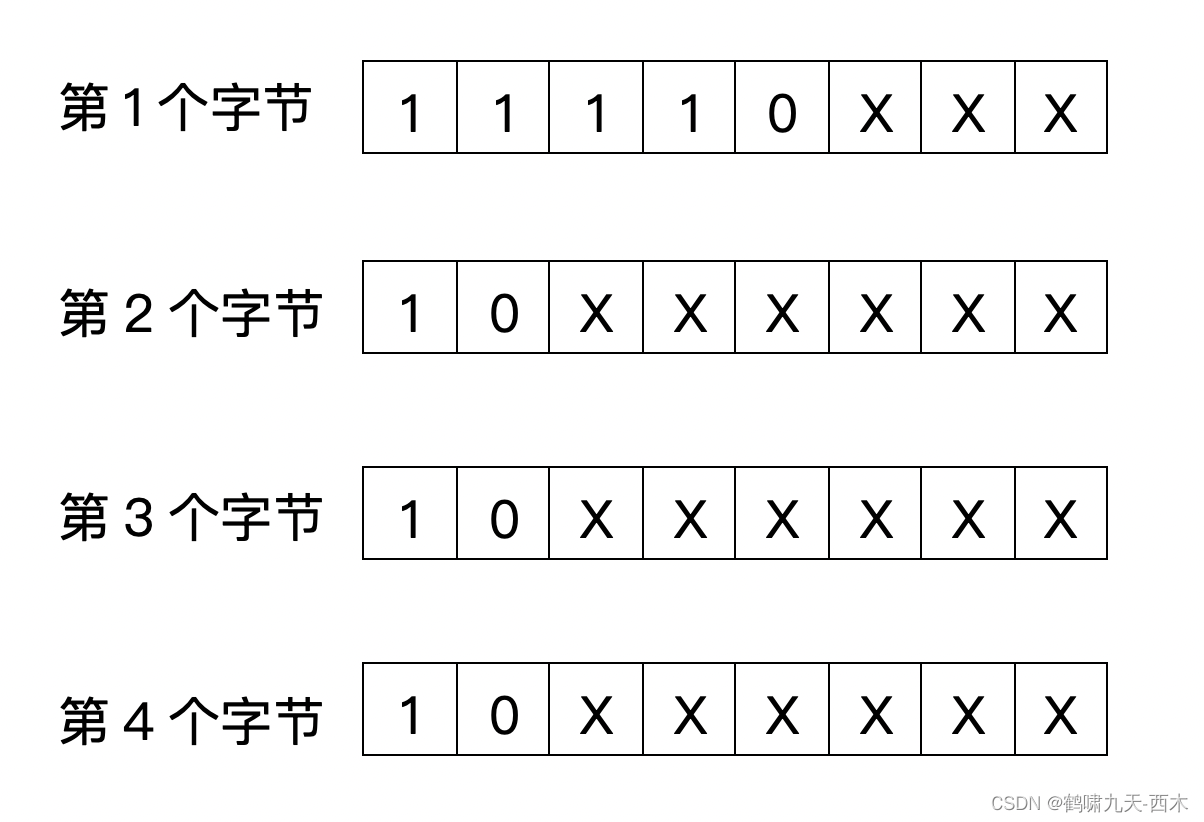
将以上方式中这些字节中的X位里的二进制按顺序拼接起来就是字符实际的二进制位表示。同时以此类推,还可以扩展为5字节、6字节字符编码等等。
九、BOM:
对于位数大于8位的处理器(例如16位或32位的处理器),由于寄存器宽度大于1个字节,那么寄存器必然存着多个字节,也就存在字节高低排序的问题,所以就有了大小端之分:
1、大端:内存的低地址中保存数据的高位,内存的高地址中保存数据的低位;
2、小端:内存的低地址中保存数据的低位,内存的高地址中保存数据的高位;
BOM(Byte Order Mark)是字节高底顺序的标识符号,一般出现在以Unicode字符编码的文件的开始,作为该文件的编码标识。以下是字符编码与BOM的对应关系:
| 字符编码 | BOM(十六进制) |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16(BE)大端 | FE FF |
| UTF-16(LE)小端 | FF FE |
| UTF-32(BE)大端 | 00 00 FE FF |
| UTF-32(LE)小端 | FF FE 00 00 |
| GB-18030 | 84 31 95 33 |
Windows中的编辑器保存成UTF-8时,一般都会自动添加0xEF0xBB0xBF。在Windows中用编辑器查看UTF-8文本时,可能由于文本中没有0xEF0xBB0xBF可能会导致乱码。
十、说明:
1、Windows用记事本输入“联通”保存后关闭,再打开内容就会变成空白。原因是保存时默认使用ANSI编码(类似GBK编码),编码后正好是UTF-8的“双字节”110-10这种格式,导致打开时编辑器检测到UTF-8的标记后就用UTF-8编码进行解析,导致解析不出来;
2、Windows系统默认的字符集是GBK,Linux系统默认的字符集是UTF-8;
3、JDK中的系统属性:文件内容的字符集与file.encoding有关,文件名的字符集与sun.jnu.encoding有关。JDK的部分版本如v1.4可用-D命令对该属性修改,但有的版本修改该属性不成功,解决方法可参考4;
4、在eclipse控制台输入汉字,print打印为乱码,但如果直接print打印字符串汉字显示正常。这种现象一般是由于printf打印时所采用平台的字符集与控制台显示汉字的字符集不一致所致。print打印过程实际是打印的字符转成字节传到控制台,控制台再转成字符进行显示,此时需要修改eclipse的初始化参数,即在eclipse安装根目录下的eclipse.ini文件中添加:-Dfile.encoding=UTF-8(Windows默认是GBK);
5、 在DOS命令下编译java文件时报无法映射字符集,可使用-encoding utf-8参数指定字符集,也可以在环境变量中配置JAVA_TOOL_OPTIONS:-Dfile.encoding=UTF-8;
6、附字符集编号表
| 标识符 | 名称 | 备注 |
|---|---|---|
| 37 | IBM037 | IBM EBCDIC(美国 - 加拿大) |
| 437 | IBM437 | OEM 美国 |
| 500 | IBM500 | IBM EBCDIC(国际) |
| 708 | ASMO-708 | 阿拉伯字符 (ASMO 708) |
| 720 | DOS-720 | 阿拉伯字符 (DOS) |
| 737 | ibm737 | 希腊字符 (DOS) |
| 775 | ibm775 | 波罗的海字符 (DOS) |
| 850 | ibm850 | 西欧字符 (DOS) |
| 852 | ibm852 | 中欧字符 (DOS) |
| 855 | IBM855 | OEM 西里尔语 |
| 857 | ibm857 | 土耳其字符 (DOS) |
| 858 | IBM00858 | OEM 多语言拉丁语 I |
| 860 | IBM860 | 葡萄牙语 (DOS) |
| 861 | ibm861 | 冰岛语 (DOS) |
| 862 | DOS-862 | 希伯来字符 (DOS) |
| 863 | IBM863 | 加拿大法语 (DOS) |
| 864 | IBM864 | 阿拉伯字符 (864) |
| 865 | IBM865 | 北欧字符 (DOS) |
| 866 | cp866 | 西里尔字符 (DOS) |
| 869 | ibm869 | 现代希腊字符 (DOS) |
| 870 | IBM870 | IBM EBCDIC(多语言拉丁语 2) |
| 874 | windows-874 | 泰语 (Windows) |
| 875 | cp875 | IBM EBCDIC(现代希腊语) |
| 932 | shift_jis | 日语 (Shift-JIS) |
| 936 | GBK | 简体中文 (GBK) |
| 949 | ks_c_5601-1987 | 朝鲜语 |
| 950 | big5 | 繁体中文 (Big5) |
| 1026 | IBM1026 | IBM EBCDIC(土耳其拉丁语 5) |
| 1047 | IBM01047 | IBM 拉丁语 1 |
| 1140 | IBM01140 | IBM EBCDIC(美国 - 加拿大 - 欧洲) |
| 1141 | IBM01141 | IBM EBCDIC(德国 - 欧洲) |
| 1142 | IBM01142 | IBM EBCDIC(丹麦 - 挪威 - 欧洲) |
| 1143 | IBM01143 | IBM EBCDIC(芬兰 - 瑞典 - 欧洲) |
| 1144 | IBM01144 | IBM EBCDIC(意大利 - 欧洲) |
| 1145 | IBM01145 | IBM EBCDIC(西班牙 - 欧洲) |
| 1146 | IBM01146 | IBM EBCDIC(英国 - 欧洲) |
| 1147 | IBM01147 | IBM EBCDIC(法国 - 欧洲) |
| 1148 | IBM01148 | IBM EBCDIC(国际 - 欧洲) |
| 1149 | IBM01149 | IBM EBCDIC(冰岛语 - 欧洲) |
| 1200 | utf-16 | Unicode (UTF-16) |
| 1201 | unicodeFFFE | Unicode (Big-Endian) |
| 1250 | windows-1250 | 中欧字符 (Windows) |
| 1251 | windows-1251 | 西里尔字符 (Windows) |
| 1252 | Windows-1252 | 西欧字符 (Windows) |
| 1253 | windows-1253 | 希腊字符 (Windows) |
| 1254 | windows-1254 | 土耳其字符 (Windows) |
| 1255 | windows-1255 | 希伯来字符 (Windows) |
| 1256 | windows-1256 | 阿拉伯字符 (Windows) |
| 1257 | windows-1257 | 波罗的海字符 (Windows) |
| 1258 | windows-1258 | 越南字符 (Windows) |
| 1361 | Johab | 朝鲜语 (Johab) |
| 10000 | macintosh | 西欧字符 (Mac) |
| 10001 | x-mac-japanese | 日语 (Mac) |
| 10002 | x-mac-chinesetrad | 繁体中文 (Mac) |
| 10003 | x-mac-korean | 朝鲜语 (Mac) |
| 10004 | x-mac-arabic | 阿拉伯字符 (Mac) |
| 10005 | x-mac-hebrew | 希伯来字符 (Mac) |
| 10006 | x-mac-greek | 希腊字符 (Mac) |
| 10007 | x-mac-cyrillic | 西里尔字符 (Mac) |
| 10008 | x-mac-chinesesimp | 简体中文 (Mac) |
| 10010 | x-mac-romanian | 罗马尼亚语 (Mac) |
| 10017 | x-mac-ukrainian | 乌克兰语 (Mac) |
| 10021 | x-mac-thai | 泰语 (Mac) |
| 10029 | x-mac-ce | 中欧字符 (Mac) |
| 10079 | x-mac-icelandic | 冰岛语 (Mac) |
| 10081 | x-mac-turkish | 土耳其字符 (Mac) |
| 10082 | x-mac-croatian | 克罗地亚语 (Mac) |
| 12000 | utf-32 | Unicode (UTF-32) |
| 12001 | utf-32BE | Unicode (UTF-32 Big-Endian) |
| 20000 | x-Chinese-CNS | 繁体中文 (CNS) |
| 20001 | x-cp20001 | TCA 台湾 |
| 20002 | x-Chinese-Eten | 繁体中文 (Eten) |
| 20003 | x-cp20003 | IBM5550 台湾 |
| 20004 | x-cp20004 | TeleText 台湾 |
| 20005 | x-cp20005 | Wang 台湾 |
| 20105 | x-IA5 | 西欧字符 (IA5) |
| 20106 | x-IA5-German | 德语 (IA5) |
| 20107 | x-IA5-Swedish | 瑞典语 (IA5) |
| 20108 | x-IA5-Norwegian | 挪威语 (IA5) |
| 20127 | us-ascii | US-ASCII |
| 20261 | x-cp20261 | T.61 |
| 20269 | x-cp20269 | ISO-6937 |
| 20273 | IBM273 | IBM EBCDIC(德国) |
| 20277 | IBM277 | IBM EBCDIC(丹麦 - 挪威) |
| 20278 | IBM278 | IBM EBCDIC(芬兰 - 瑞典) |
| 20280 | IBM280 | IBM EBCDIC(意大利) |
| 20284 | IBM284 | IBM EBCDIC(西班牙) |
| 20285 | IBM285 | IBM EBCDIC(英国) |
| 20290 | IBM290 | IBM EBCDIC(日语片假名) |
| 20297 | IBM297 | IBM EBCDIC(法国) |
| 20420 | IBM420 | IBM EBCDIC(阿拉伯语) |
| 20423 | IBM423 | IBM EBCDIC(希腊语) |
| 20424 | IBM424 | IBM EBCDIC(希伯来语) |
| 20833 | x-EBCDIC-KoreanExtended | IBM EBCDIC(朝鲜语扩展) |
| 20838 | IBM-Thai | IBM EBCDIC(泰语) |
| 20866 | koi8-r | 西里尔字符 (KOI8-R) |
| 20871 | IBM871 | IBM EBCDIC(冰岛语) |
| 20880 | IBM880 | IBM EBCDIC(西里尔俄语) |
| 20905 | IBM905 | IBM EBCDIC(土耳其语) |
| 20924 | IBM00924 | IBM 拉丁语 1 |
| 20932 | EUC-JP | 日语(JIS 0208-1990 和 0212-1990) |
| 20936 | x-cp20936 | 简体中文 (GB2312-80) |
| 20949 | x-cp20949 | 朝鲜语 Wansung |
| 21025 | cp1025 | IBM EBCDIC(西里尔 塞尔维亚 - 保加利亚) |
| 21866 | koi8-u | 西里尔字符 (KOI8-U) |
| 28591 | iso-8859-1 | 西欧字符 (ISO) |
| 28592 | iso-8859-2 | 中欧字符 (ISO) |
| 28593 | iso-8859-3 | 拉丁语 3 (ISO) |
| 28594 | iso-8859-4 | 波罗的海字符 (ISO) |
| 28595 | iso-8859-5 | 西里尔字符 (ISO) |
| 28596 | iso-8859-6 | 阿拉伯字符 (ISO) |
| 28597 | iso-8859-7 | 希腊字符 (ISO) |
| 28598 | iso-8859-8 | 希伯来字符 (ISO-Visual) |
| 28599 | iso-8859-9 | 土耳其字符 (ISO) |
| 28603 | iso-8859-13 | 爱沙尼亚语 (ISO) |
| 28605 | iso-8859-15 | 拉丁语 9 (ISO) |
| 29001 | x-Europa | 欧罗巴 |
| 38598 | iso-8859-8-i | 希伯来字符 (ISO-Logical) |
| 50220 | iso-2022-jp | 日语 (JIS) |
| 50221 | csISO2022JP | 日语(JIS- 允许 1 字节假名) |
| 50222 | iso-2022-jp | 日语(JIS- 允许 1 字节假名 - SO/SI) |
| 50225 | iso-2022-kr | 朝鲜语 (ISO) |
| 50227 | x-cp50227 | 简体中文 (ISO-2022) |
| 51932 | euc-jp | 日语 (EUC) |
| 51936 | EUC-CN | 简体中文 (EUC) |
| 51949 | euc-kr | 朝鲜语 (EUC) |
| 52936 | hz-gb-2312 | 简体中文 (HZ) |
| 54936 | GB18030 | 简体中文 (GB18030) |
| 57002 | x-iscii-de | ISCII 梵文 |
| 57003 | x-iscii-be | ISCII 孟加拉语 |
| 57004 | x-iscii-ta | ISCII 泰米尔语 |
| 57005 | x-iscii-te | ISCII 泰卢固语 |
| 57006 | x-iscii-as | ISCII 阿萨姆语 |
| 57007 | x-iscii-or | ISCII 奥里雅语 |
| 57008 | x-iscii-ka | ISCII 卡纳达语 |
| 57009 | x-iscii-ma | ISCII 马拉雅拉姆字符 |
| 57010 | x-iscii-gu | ISCII 古吉拉特字符 |
| 57011 | x-iscii-pa | ISCII 旁遮普字符 |
| 65000 | utf-7 | Unicode (UTF-7) |
| 65001 | utf-8 | Unicode (UTF-8) |

















 57万+
57万+


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








