







目录
1、PPO (Proximal Policy Optimization)的介绍
1、PPO (Proximal Policy Optimization)的介绍
ppo是一种强化学习算法,用于训练智能体(agent)在复杂环境中学习最优策略。简单来说,PPO有以下几个关键特点:
- 它是一种策略梯度方法,直接优化智能体的决策策略。
- 相比其他算法,PPO更稳定、更容易实现,且性能良好,因此在实践中很受欢迎。
- PPO通过限制每次策略更新的幅度来提高训练的稳定性。它引入了一个"裁剪"机制,防止过大的策略变化。
- 它使用了"演员-评论家"(Actor-Critic)架构:
- "演员"(Actor)网络用于生成动作
- "评论家"(Critic)网络用于估计动作的价值
- PPO交替进行数据收集和多轮小批量的策略优化。
- 它能有效处理连续和离散的动作空间。
在语言模型领域,PPO被用于 RLHF (基于人类反馈的强化学习)过程,以微调模型使其输出更符合人类偏好。在这种情况下:
- "演员"是要微调的语言模型
- "评论家"评估模型输出的质量
- 奖励信号来自预先训练的奖励模型,代表人类偏好
这种方法帮助语言模型生成更高质量、更符合人类期望的输出。
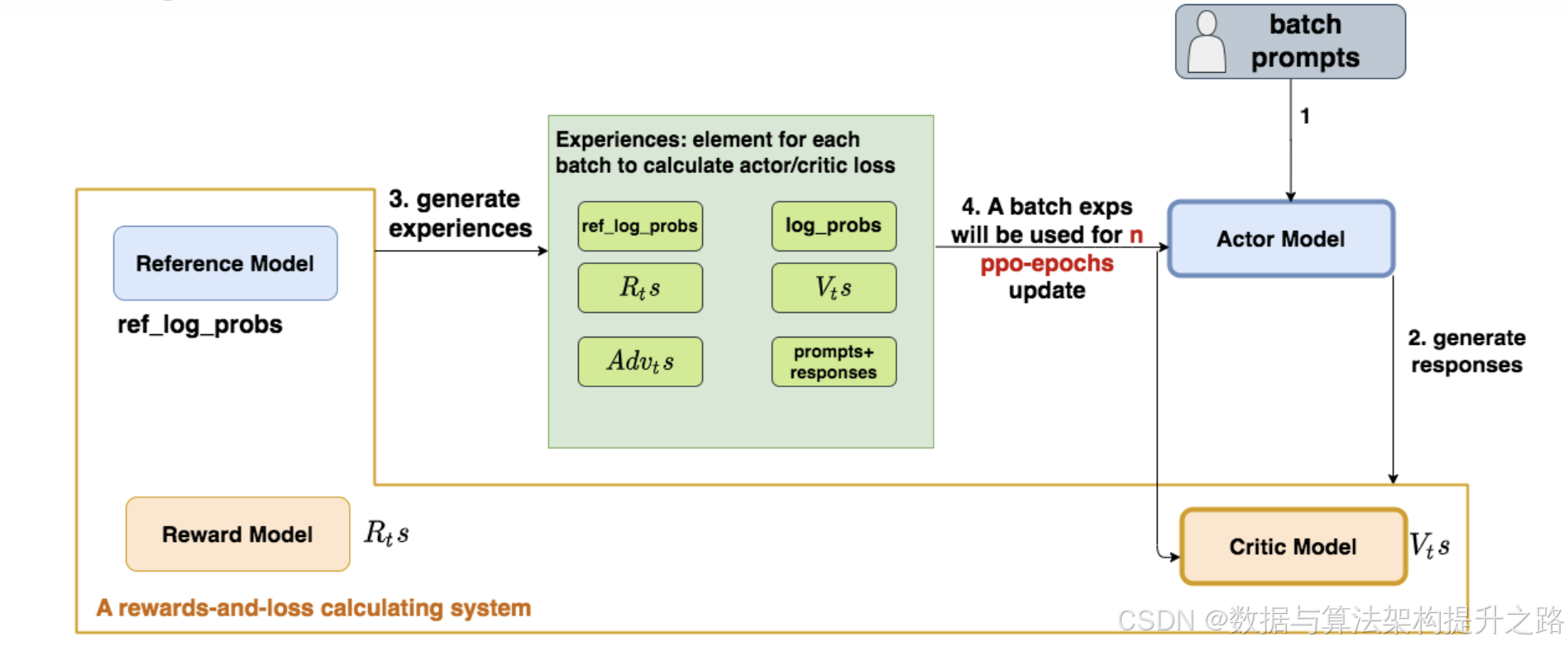
2、用打游戏比喻解释PPO
场景设定: 假设你在训练一个AI玩《超级马里奥》,目标是让它尽可能多吃金币、快速通关。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











