







引言
近年来,大模型(如GPT系列、Claude等)的多语言能力令人叹为观止。它们不仅能流畅地理解和生成多种语言的文本,还能在不同语言间无缝切换,轻松完成翻译、问答甚至创作任务。这种能力究竟从何而来?大模型内部是否藏着一种神秘的“通用语言”?通过Anthropic对Claude Haiku 3.5模型的研究,我们得以一窥大模型多语言能力的内部机制。本文将带你揭开这一技术奇迹的面纱。


1. 多语言能力的来源:共享核心与语言适配
大模型的多语言能力并非简单地依赖海量数据堆砌,而是源自一种精妙的混合机制:
为此,Anthropic给Claude Haiku 3.5用3种语言问了同一个问题,分别是英文、中文和法语:
- The opposite of “small” is
- “小”的反义词是
- Le contraire de “oetut” est
如下图所示:
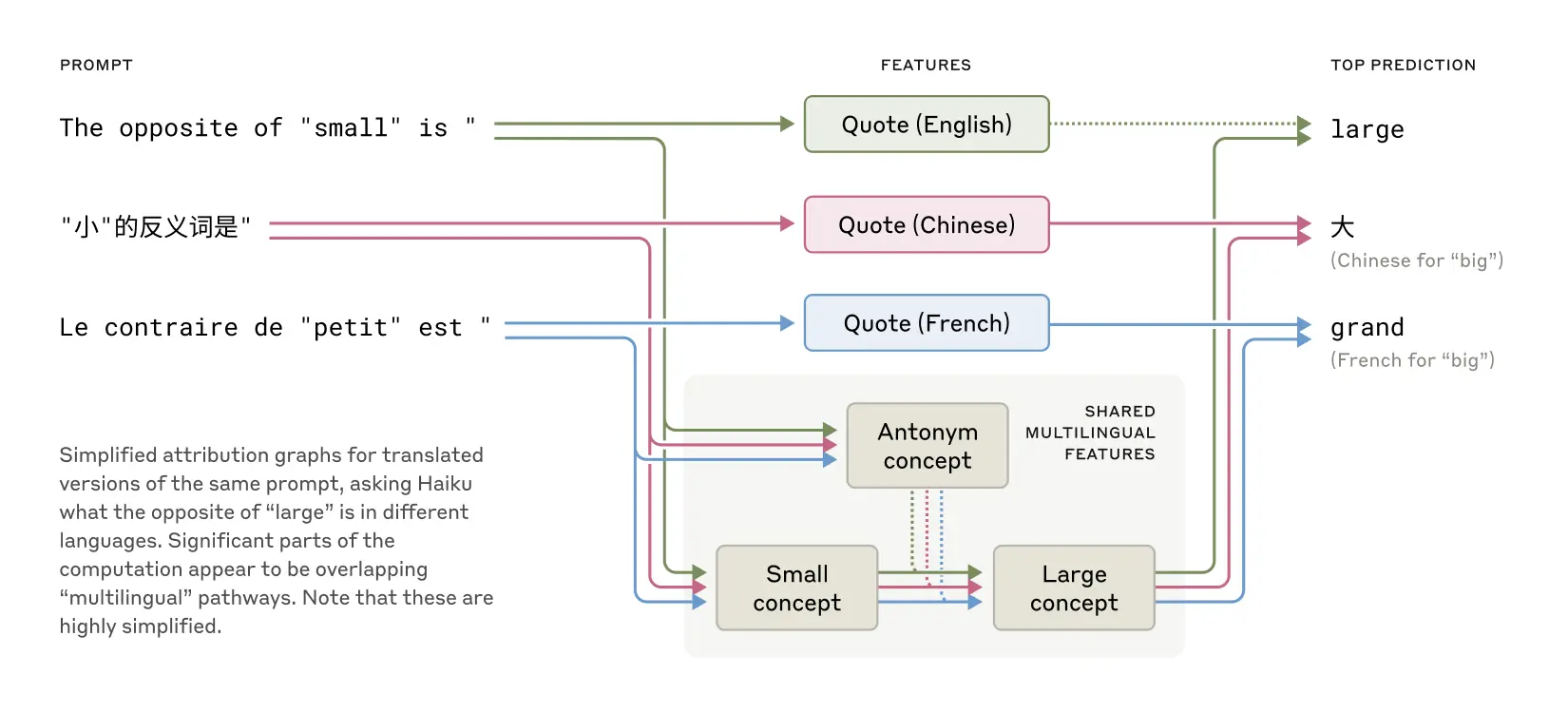
当这三种不同的输入进入Claude Haiku 3.5之后,Anthropic发现,虽然是完全不同的输入,但是它们都激活了一些相同的大模型内部的区域,如小的概念、大的概念、反义词的概念等,但是最终输出的时候激活的是不同的语言区域。同时,当模型的规模增大的时候,那么不同语种之间激活的相同的区域的比例也更高。例如,与一个更小的模型相比,Claude Haiku 3.5激活的共享特征比例是前者的2倍以上。这种“共享+适配”的机制,让大模型在多语言任务中表现出惊人的灵活性。
2. “内部语言”的真相:抽象表征空间
大模型是否拥有一种“内部语言”?答案既是也不是:
- 并非人类语言:研究表明,大模型内部并不存在某种具体的人类语言(如英语或中文)作为“中介”。它不会先把中文翻译成英语再处理。
- 抽象表征空间:取而代之的是一个高度抽象、跨语言共享的概念空间。在这个空间里,“小”与“big”的关系、“首都”与“城市”的联系以独立于语言的形式存在。Anthropic发现,当用不同语言提问“‘小’的反义词是什么”时,模型激活的推理特征高度一致,证明了这一空间的存在。
这就像一个“通用的心智语言”,让模型能在不同语言间自由穿梭。
3. 知识迁移的奥秘:从英语到中文的“无形桥梁”
大模型为何能将在一种语言中学到的知识用另一种语言表达?答案就在于上述的抽象表征空间:
- 跨语言迁移:以“奥斯汀是得克萨斯州的首府”为例,模型在英语数据中学会这一事实后,会将其编码为抽象概念(如“奥斯汀-首府-得克萨斯州”)。当用户用中文提问“得克萨斯州的首府是哪里?”时,模型直接在抽象空间检索答案,再通过中文输出回路生成“奥斯汀”。
- 无需翻译:整个过程无需显式的语言转换,知识仿佛天然跨越了语言界限。
这种能力解释了为何即使中文训练数据有限,模型仍能回答中文问题——它借用了英语数据的“智慧”。
4. 英语的“特权”:隐藏的偏见?
尽管大模型展现了真正的多语言能力,Anthropic的研究却发现了一个有趣现象:英语似乎在模型内部占据“默认”地位。
- 倾向英语输出:如果不明确指定输出语言,模型更可能生成英语答案(如“big”而非“大”)。
- 原因探寻:这可能与训练数据中英语占比更高有关。英语相关特征在模型的几何表征中更“基础”,其他语言则需额外适配。
这一发现提醒我们,大模型的多语言能力虽强大,但仍可能携带语言偏见,值得开发者警惕。
结尾
Anthropic的研究为我们揭开了大模型多语言能力的神秘面纱:一个跨语言共享的抽象核心,搭配语言特定的适配机制,共同构建了知识迁移的桥梁。这一发现不仅让我们更理解AI的“心智”,也为优化其跨语言性能、减少偏见提供了方向。未来,随着技术进步,我们或许能打造出更加公平、高效的多语言大模型。
附录:Anthropic是如何研究大模型内部机制的
理解大模型内部机制的一大挑战在于其“黑箱”特性和神经元的“多义性”(polysemanticity)——即单个神经元不可解释,同时也可能参与多种不同的功能。为了克服这一点,Anthropic研究人员采用类似生物学中解剖和显微观察的方法:
- 替代模型与“特征”:研究者首先训练了一个“替代模型”。这个模型使用一种叫做“跨层转码器”(Cross-Layer Transcoder, CLT)的技术,将原始模型中难以理解的密集神经元激活,替换为大量稀疏激活的、更易于解释的单元,称为“特征”(features)。这些特征往往代表着具体的、可解释的概念,小到特定词语,大到抽象逻辑或情感。这就像是用功能明确的“细胞”来重构大脑组织。
- 归因图(Attribution Graphs):基于这些“特征”,研究者构建了归因图。这种图能够可视化特定输入到特定输出过程中,信息是如何在不同特征之间流动和处理的。它揭示了模型完成任务所依赖的关键计算步骤和中间状态,类似于绘制大脑中的“神经线路图”。
- 干预实验(Intervention Experiments):为了验证归因图揭示的机制是否真实可靠,研究者会进行干预实验。他们主动抑制或激活模型内部特定的“特征”或特征组合,观察其对模型后续计算和最终输出的影响,以此来检验假设的因果关系。
这里核心理解第一个替代模型就可以了,下图展示了替代模型的大致原理:
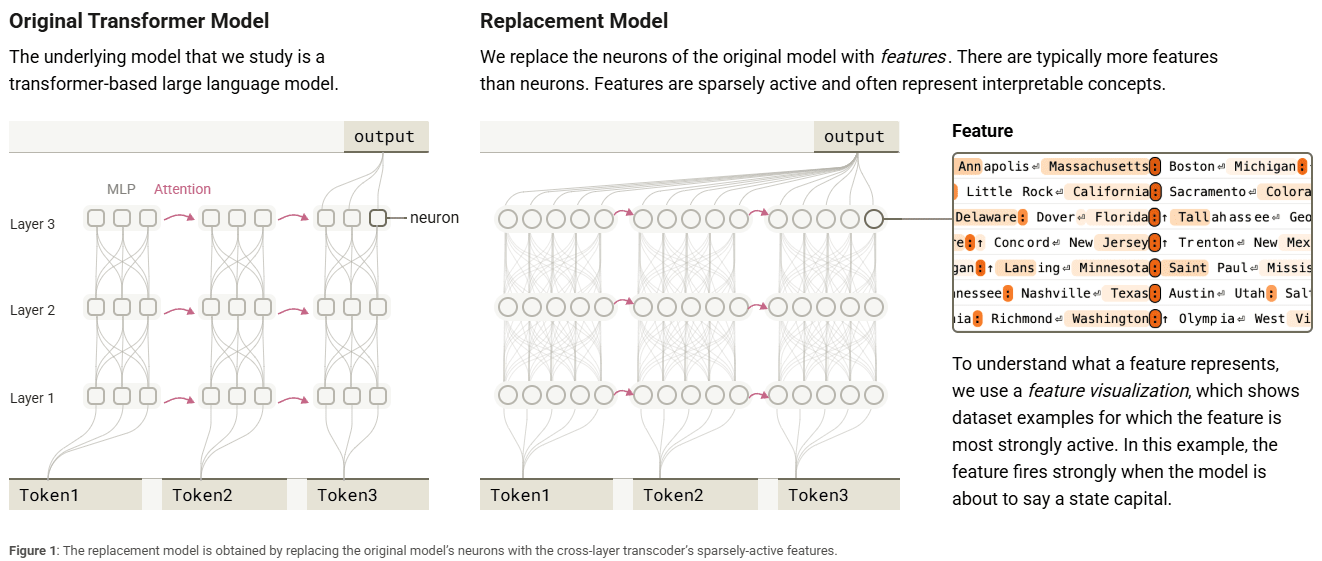
当前 Transformer 大模型内部的 MLP 部分计算复杂且难以通过单个神经元来解读其语义。为了解决这个问题,研究者训练了一个替代模型,使用CLT技术读取 Transformer 中间层信息,分解为“特征”,因为CLT是尽力模拟这些中间层行为,达到替换掉原始的中间层不影响结果的目的。因此,替代模型和原始的模型内部运行很接近,所以Anthropic可以通过观察这个可解释的CLT来观察大模型的情况。
通过这套方法,Anthropic得以在一定程度上“解剖”大模型,观察其在处理多语言任务时的内部“生理活动”。Anthropic使用这套机制研究了很多大模型的能力,在这里我们主要来说明大模型的多语言机制。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











