







论文原文: Efficient Estimation of Word Representations in Vector Space
作者: Tomas Mikolov
发表时间: 2013
一、论文背景
统计语言模型
基于马尔科夫假设(下一个词的出现仅依赖于前面的一个词或几个词),通过概率计算来描述语言模型(用语料在数据集出现频率近似概率结果)
缺点:参数空间过大,数据稀疏严重
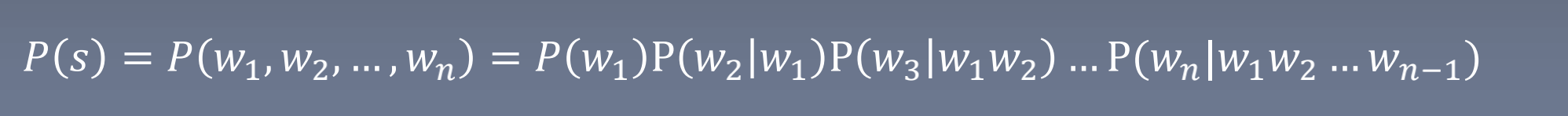
Word representation
- One-hot Representation(稀疏)
watch [0,0,0,0,0,0,0,0,0,1]
table [0,0,0,0,0,0,0,0,1,0]- Distributed Representation(稠密)
watch [0.1,0.2,0.1,0.1,0.7,0.8,0.9,0.1,0.1,0.1]
N-gram
NNLM (Feedforward Neural Net Language Model 前馈神经网络)
- 引用: Bengio A neural probabilistic language model (2003)
- 基本思想:根据前N-1个词预测第N个位置出现单词的概率,优化模型,使输出概率最大;
- 输入层: [1xV] * [VxD] => [1xD] (V:vocabulary 词表大小,D:词向量维度)
- 隐藏层: 全连接层,激活函数a=tanh(d+Ux)
- 输出层: softmax函数,y=b+Wa ( y的维度 [ 1 x V ] )
- Loss:L = − 1 T ∑ i = 1 T l o g p ( w i ∣ w i − n + 1 , . . . , w i − 1 ) \ -\frac{1}{T}\sum_{i=1}^T log{p(w_i|w_{i-n+1},...,w_{i-1})} −T1∑i=1Tlogp(wi∣wi−n+1,...,wi−1)
- 困惑度: PP(s) = P ( w 1 , w 2 , . . . w T ) − 1 T P(w_1,w_2,...w_T)^{-\frac1T} P(w1,w2,...wT)−T1 = 1 P ( w 1 , w 2 , . . . w T ) T \quad \sqrt[T]{\frac1{P(w_1,w_2,...w_T)}} TP(w1,w2,...wT)1 = e L {\bf \color{#f00}{e^L}} eL
优点:
- 仅对一部分输出进行梯度传播;
- 引入先验知识,如词性等;
- 解决一词多义问题;
- 加速softmax层;
RNNLM (Recurrent Neural Net Language Model 循环神经网络)
- 基本思想:每个时间步预测一个词,在预测第N个词时试用了前N-1个词的信息;
- 输入层: [1xV] * [VxD] => [1xD] (V:vocabulary 词表大小,D:词向量维度)
- 隐藏层: 全连接层, s ( t ) = U w ( t ) + W s ( t − 1 ) + d s(t) = Uw(t) +Ws(t-1) + d s(t)=Uw(t)+Ws(t−1)+d
- 输出层: softmax函数, y ( t ) = b + V s ( t ) y(t)=b+Vs(t) y(t)=b+Vs(t) ( y的维度 [ 1 x V ] )
- Loss:L = − 1 T ∑ i = 1 T l o g p ( w i ∣ w i − n + 1 , . . . , w i − 1 ) \ -\frac{1}{T}\sum_{i=1}^T log{p(w_i|w_{i-n+1},...,w_{i-1})} −T1∑i=1Tlogp(wi∣wi−n+1,...,wi−1)
- 困惑度: PP(s) = P ( w 1 , w 2 , . . . w T ) − 1 T P(w_1,w_2,...w_T)^{-\frac1T} P(w1,w2,...wT)−T1 = 1 P ( w 1 , w 2 , . . . w T ) T \quad \sqrt[T]{\frac1{P(w_1,w_2,...w_T)}} TP(w1,w2,...wT)1 = e L {\bf \color{#f00}{e^L}} eL
二、模型结构
语言模型的基本思想
句子中下一个词的出现和前面的 词是有关系的,所以可以使用前面的词预测下一个词。
Word2Vec的基本思想
句子中相近的词之间是有联系 的,比如今天后面经常出现上午,下午和晚上。所以 Word2vec的基本思想就是用词来预测词,skip-gram 使用中心词预测周围词,cbow使用周围词预测中心 词。
2.1 abstract
- 提出了两种新颖的模型结构(skip-gram、cbow)用来计算词向量
- 采用一种词相似度的任务来评估对比词向量质量
- 大量降低模型计算量可以提升词向量质量
- 在语义和句法任务上,效果表现很好
2.2 SKIP-GRAM
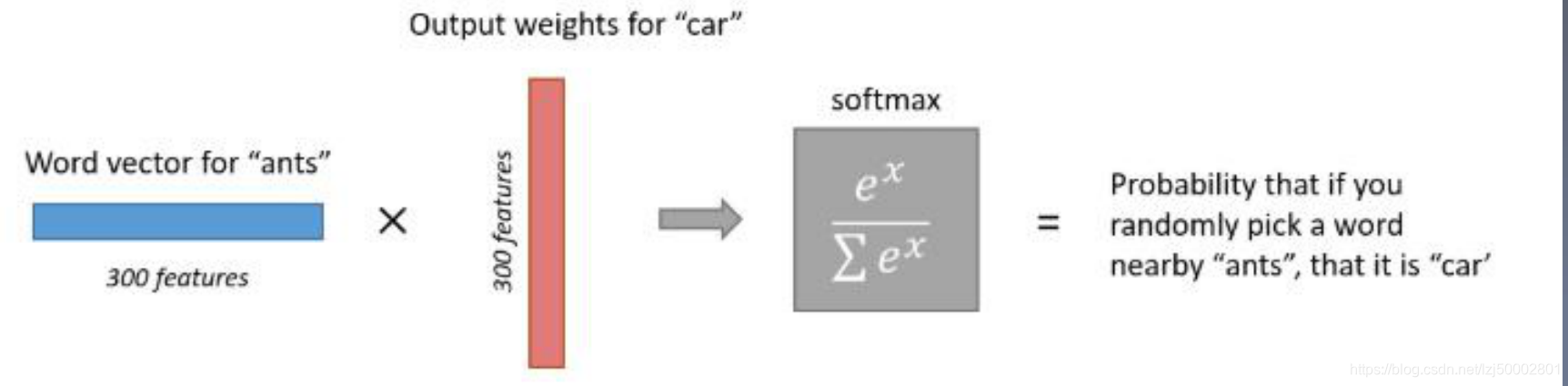
求解公式: p ( o ∣ c ) = e x p ( u o T v c ) ∑ w = 1 V e x p ( u w T v c ) p(o|c) = \frac {exp(u_o^Tv_c)}{\sum_{w=1}^Vexp(u_w^Tv_c)} p(o∣c)=∑w=1Vexp(uwTvc)exp(uoTvc)
注: v c v_c vc是中心词向量 , u o T v C u_o^Tv_C uoTvC是窗口内上下文词向量
损失函数: J ( θ ) = 1 T ∑ t = 1 T ∑ − m ≤ j ≤ m , j ≠ 0 log p ( w t + j ∣ w t ) J(\theta) = \frac1T\sum_{t=1}^T\sum_{-m\leq j\leq m,j\neq0} \log p(w_{t+j}|w_t) J(θ)=T1∑t=1T∑−m≤j≤m,j=0logp(wt+j∣wt)
2.2 CBOW
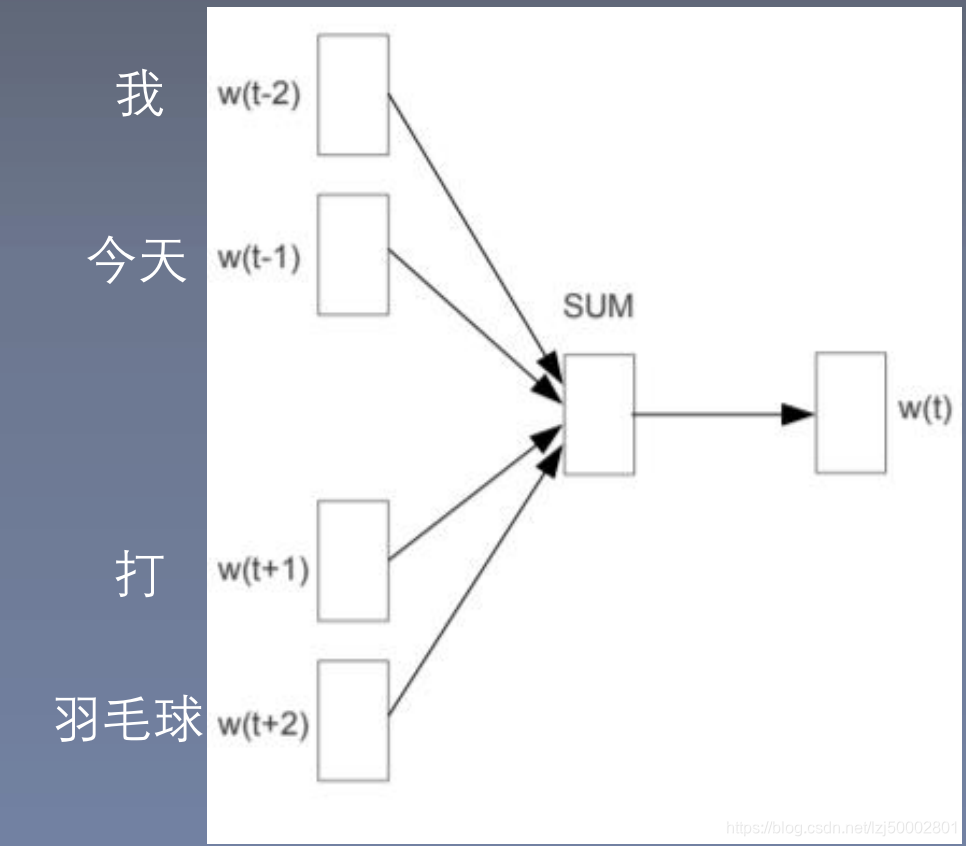
基本原理: p i = p ( w i ∣ w i − 2 , w i − 1 , w i + 1 , w i + 2 ) p_i = p(w_i|w_{i-2},w_{i-1},w_{i+1},w_{i+2}) pi=p(wi∣wi−2,wi−1,wi+1,wi+2)
求解公式: p ( c ∣ o ) = e x p { u o T v c } ∑ j = 1 V e x p { u w T v c } p(c|o) = \frac {exp\{u_o^Tv_c\}}{\sum_{j=1}^Vexp\{u_w^Tv_c\}} p(c∣o)=∑j=1Vexp{uwTvc}exp{uoTvc}注:
e1,e2,e3,e4 上下文词
u o u_o uo = sum(e1,e2,e3,e4)
u o u_o uo是窗口内上下文词向量的和 , v c v j v_c v_j vcvj是中心词向量
损失函数:
J ( θ ) = 1 T ∑ T ∑ log p ( c ∣ o ) ) = 1 T ∑ e x p { u o T v c } ∑ j = 1 V e x p { u w T v c } J(\theta) = \frac1T\sum_{T}\sum \log p(c|o))=\frac 1T \sum \frac {exp\{u_o^Tv_c\}}{\sum_{j=1}^Vexp\{u_w^Tv_c\}} J(θ)=T1∑T∑logp(c∣o))=T1∑∑j=1Vexp{uwTvc}exp{uoTvc}
2.3 复杂度
- Hierarchical Softmax (层次softmax)
基本思路:构建哈夫曼树,复杂度 V => log 2 V \log_2V log2V - Negative Sampling
基本思路:增大正样本概率,减小负样本概率
损失函数: J n e g − s a m p l e ( θ ) = log σ ( u o T v c ) + ∑ k = 1 K E k ∼ P ( w ) [ log σ ( − u k T v c ) ] J_{neg-sample}(\theta) = \log \sigma(u_o^Tv_c) + \sum_{k=1}^K E_{k \sim P(w)}[\log \sigma(-u_k^Tv_c)] Jneg−sample(θ)=logσ(uoTvc)+∑k=1KEk∼P(w)[logσ(−ukTvc)]
注: v c v_c vc是中心词向量, u o u_o uo窗口内上下文词向量, u k u_k uk负采样上下文词向量
第一部分是P(o|c),第二部分是1-P(j|c)
负采样: P ( w ) = U ( w ) 3 4 z P(w) = \frac {U(w)^\frac34}z P(w)=zU(w)43 - Subsampling of Frequent Words(重采样)
重采样方法: P ( w ) = 1 − t f ( w i ) P(w) = 1- \sqrt \frac {t}{f(w_i)} P(w)=1−f(wi)t
注: f ( w i ) f(w_i) f(wi)是词在数据集中出现的概率,论文中 t = 1 0 − 5 t=10^{-5} t=10−5, 训练集中词 w i w_i wi会以 P ( w i ) P(w_i) P(wi)的概率被删除。
三、数据集和测试方法
//TODO
四、讨论和回顾
//TODO
五、语言模型评价指标
1. 困惑度

2. 衡量词的相似度方法
sim 𝑤𝑜𝑟𝑑1, 𝑤𝑜𝑟𝑑2 = cos(𝑤𝑜𝑟𝑑𝑣𝑒𝑐1, 𝑣𝑜𝑟𝑑𝑣𝑒𝑐2)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









