







最近特别火的DeepSeek,是一个大语言模型,那一个模型是如何构建起来的呢?DeepSeek基于Transformer架构,接下来我们也从零开始构建一个基于Transformer架构的小型语言模型,并说明构建的详细步骤及内部组件说明。我们以构建一个字符级语言模型(Char-Level LM)为例,目标是通过训练模型预测序列中的下一个字符。
全文采用的python语言。
想了解个人windows电脑上安装DeepSeek大模型,看我的文章:个人windows电脑上安装DeepSeek大模型(完整详细可用教程)_deepseek-r1-distill-qwen-1.5b-gguf-CSDN博客
本文的前置基础,Windows安装Hugging Face Transformers库,看我的文章:Windows安装Hugging Face Transformers库并实现案例训练的详细教程-CSDN博客
请务必先看完前文:从零开始构建一个小型字符级语言模型的详细教程(基于Transformer架构)之一-CSDN博客
一、整体流程概览
听说了太多的大模型,那么大模型是如何一步一步建立起来的呢?我们接下来就从一个小的模型开始,逐步分解,让大家知道其中的逻辑、构成等关键内容。从基础开始,逐步实现,包括数据准备、模型架构、训练和评估。
首先,确定模型的目标。
然后,是模型架构。
接下来,是训练过程。
所以综合,本文将从以下步骤实现一个小模型:
1.数据准备 → 2.模型架构设计 → 3.训练 → 4.评估与生成
二、详细步骤与组件说明
2. 模型架构设计
目标:实现一个简化版Transformer解码器。
模型架构设计阶段的流程如下:
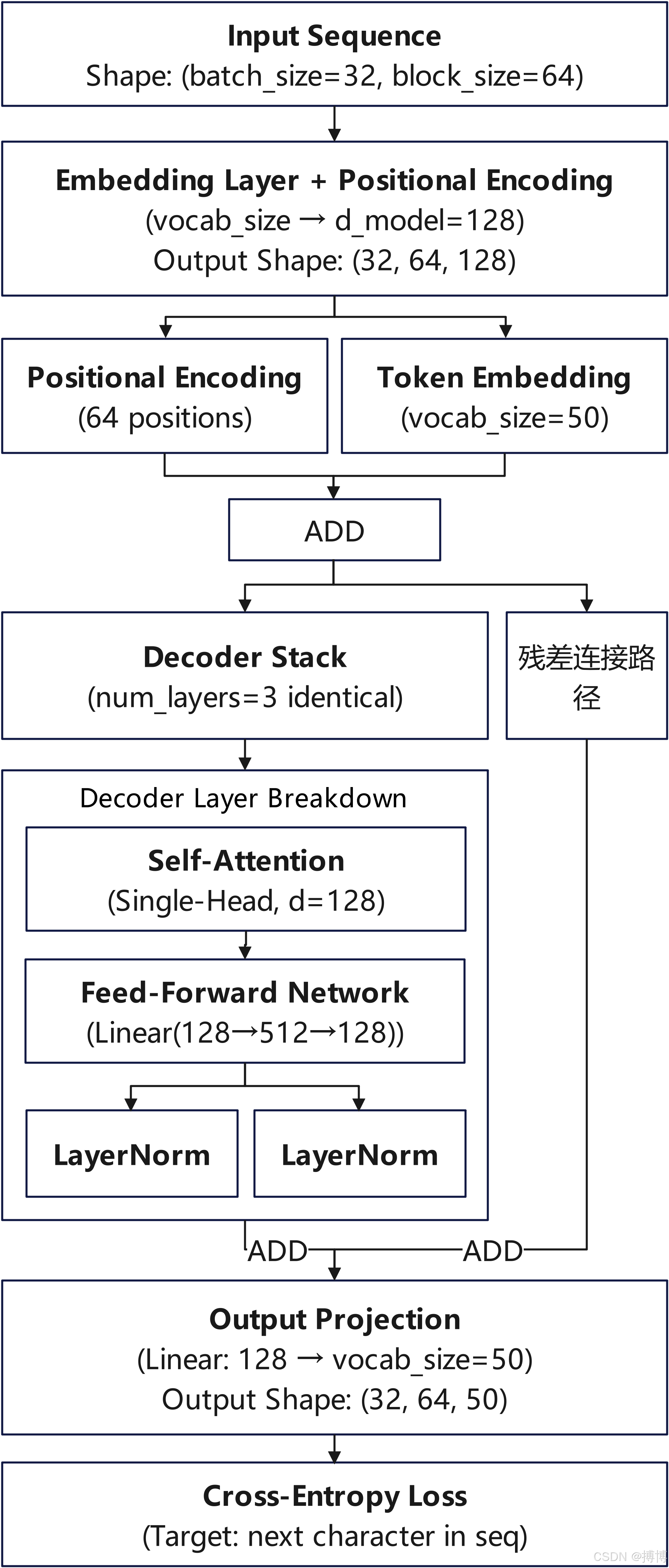
图6 模型架构设计阶段的流程
2.1 输入层 (Input Layer)
(1)输入层参数说明
上文我们为了绘制演示图,使用了很简单的示例,接下来部分设置的参数有一些不一样,注意区分。
1)批尺寸 (batch_size=32)
作用:控制单次参数更新时使用的样本数量。
平衡考量:较小值(如16),内存占用低但梯度更新噪声大;当前值32
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











