







1. HDFS 简介
HDFS,为Hadoop这个分布式计算框架提供高性能、高可靠、高可扩展的存储服务。HDFS的系统架构是典型的主/从?架构,早期的架构包括一个主节点NameNode和多个从节点DataNode。NameNode是整个文件系统的管理节点,也是HDFS中最复杂的一个实体,它维护着HDFS文件系统中最重要的两个关系:
(1).HDFS文件系统中的文件目录树,以及文件的数据块索引,即每个文件对应的数据块列表。
(2).数据块和数据节点的对应关系,即某一块数据块保存在哪些数据节点的信息。
其中,第一个关系即目录树、元数据和数据块的索引信息会持久化到物理存储中,实现是保存在命名空间的镜像fsimage和编辑日志edits中。而第二个关系是在NameNode启动后,有DataNode主动上报它所存储的数据块,动态建立对应关系。
在上述关系的基础上,NameNode管理着DataNode,通过接收DataNode的注册、心跳、数据块提交等信息的上报,并且在心跳中发送数据块复制、删除、恢复等指令;同时,NameNode还为客户端对文件系统目录树的操作和对文件数据读写、对HDFS系统进行管理提供支持。
DataNode提供真实文件数据的存储服务。它以数据块的方式在本地的Linux文件系统上保存了HDFS文件的内容,并且对外提供文件数据的访问功能。客户端在读写文件时,必须通过NameNode提供的信息,进一步和DataNode进行交互;同时,DataNode还必须接NameNode的管理,执行NameNode的指令,并且上报NameNode感兴趣的事件,以保证文件系统稳定,可靠,高效的运行。架构图如下:
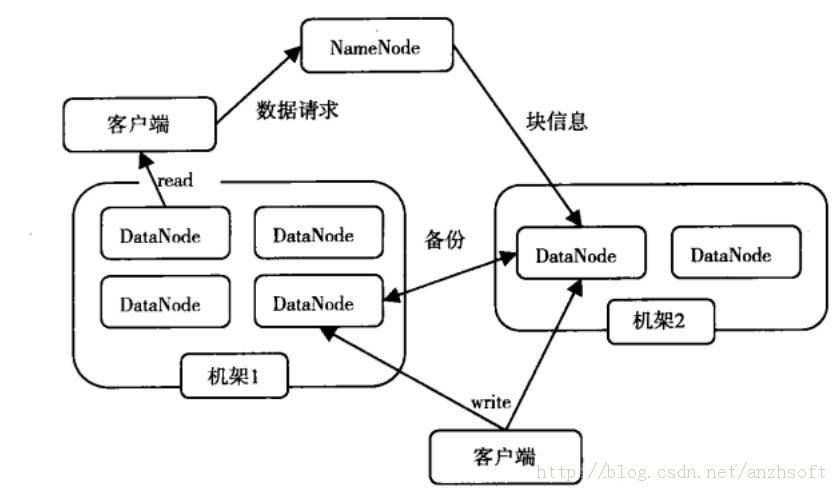
图1 HDFS体系结构
在HDFS集群中NameNode存在单点故障(SPOF)。对于只有一个NameNode的集群,如果NameNode机器出现故障,那么整个集群将无法使用,直到NameNode重新启动。
NameNode主要在以下两个方面影响HDFS集群:
(1).NameNode机器发生意外,比如宕机,集群将无法使用,直到管理员重启NameNode
(2).NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS的HA功能通过配置Active/Standby两个NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
2.HDFS可靠性
为了保障HDFS的高可靠性。HDFS有如下5个特性。
(1)冷备机制
HDFS中Secondary NameNode对NameNode中元数据提供了冷备方案 Secondary NameNode将Na—meNode的fsimage与edit log从Namenode复制到临时目录,将fsitnage同edit log合并,并产生新的Fsimage并把产生的新的Isirnage上传给NameNode ,最后清除NameNode中的edit log
(2)租约机制
NameNode在打开或创建一个文件,准备追加写之前,会与此客户端签订一份租约。客户端会定时轮询续签租约。NameNode始终在轮询检查所有租约,查看是否有到期未续的租约。如果一切正常,该客户端完成写操作,会关闭文件,停止租约,一旦有所意外,比如文件被删除了,客户端宕机了,当超过租约期限时,NameNode就会剥夺此租约,将这个文件的享用权,分配给他人。如此,来避免由于客户端停机带来的资源被长期霸占的问题。
(3)数据的正确性与一致性
在HDFS中,为了保证数据的正确性和同一份数据的一致性,做了大量的工作。首先,每一个数据块,都有一个版本标识,一旦数据块上的数据有所变化,此版本号将向前增加。在NameNode上,保存有此时每个数据块的版本,一旦出现数据服务器上相关数据块版本与其不一致,将会触发相关的恢复流程。这样的机制保证了各个数据服务器器上的数据块,在基本大方向上都是一致的。但是,由于网络的复杂性,简单的版本信息无法保证具体内容的一致性。因此,为了保证数据内容上的一致,必须要依照内容,给出签名。
当客户端向数据服务器追加写人数据包时,每一个数据包的数据,都会切分成512字节大小的段,作为签名验证的基本单位,在HDFS中,把这个数据段称为Chunk,即传输块。在每一个数据包中,都包含若干个传输块以及每一个传输块的签名,一旦发现当前的传输块签名与在客户端中的签名不一致,整个数据包的写人被视为无效。
(4)系统升级回滚
当升级某个集群的Hadoop的时候,正如任何软件的升级一样,可能会引人新的bug或者不兼容的修改导致现有的应用出现过去没有发现的问题。在所有重要的HDFS安装应用中,是不允许出现因丢失任何数据需要从零开始重启HDFS的情况。HDFS允许管理员恢复到Hadoop的早期版本,并且将集群的状态回滚到升级前。
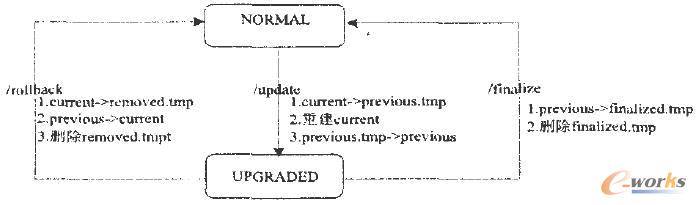
图2 系统升级回滚
如图2所示,升级时,NameNode会将新的版本号,通过DataNode的登录应答返回。DataNode收到以后,会将当前的数据块文件目录改名,从curren,改名为previous.tmp ,建立一个snapshot,然后重建current目录。重建包括重建VERSION文件,重建对应的子目录,然后建立数据块文件和数据块元数据文件到previous.tmp的硬连接。建立硬连接意味着在系统中只保留一份数据块文件和数据块元数据文件,current和previous.tmp中的相应文件,在存储中,只保留一份。当所有的这些工作完成以后,会在current里写人新的VER-SION文件,并将previous.tmp目录改名为previous,完成升级。
回滚相对简单,因为所有的旧版本信息都保存在previou、目录里。回滚首先将current目录改名为re-moved.tmp,然后将previous目录改名为current,最后删除removed.tmp目录。
提交的过程,就是将上面的previous目录改名为finalized.tmp,然后启动一个线程,将该目录删除。
(5)安全模式
在启动的时候,名字节点进入一个特殊的状态叫做安全模式。安全模式是不发生文件块的复制的。NN接受来自DN的心跳和块报告。一个块报告包括的是DN向NN报告数据块的列表。















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









