







在${HIVE_HOME}/bin目录下有个.hiverc文件,它是隐藏文件,我们可以用Linux的ls -a命令查看。我们在启动Hive的时候会去加载这个文件中的内容,所以我们可以在这个文件中配置一些常用的参数,如下:
#在命令行中显示当前数据库名
set hive.cli.print.current.db=true;
#查询出来的结果显示列的名称
set hive.cli.print.header=true;
#启用桶表
set hive.enforce.bucketing=true;
#压缩hive的中间结果
set hive.exec.compress.intermediate=true;
#对map端输出的内容使用BZip2编码/解码器
set mapred.map.output.compression.codec=org.apache.hadoop.io.compress.BZip2Codec;
#压缩hive的输出
set hive.exec.compress.output=true;
#对hive中的MR输出内容使用BZip2编码/解码器
set mapred.output.compression.codec=org.apache.hadoop.io.compress.BZip2Codec;
#让hive尽量尝试local模式查询而不是mapred方式
set hive.exec.mode.local.auto=true;命令的运行方式:
1.在Linux命令行下使用hive -e "SQL语句"的方式运行:
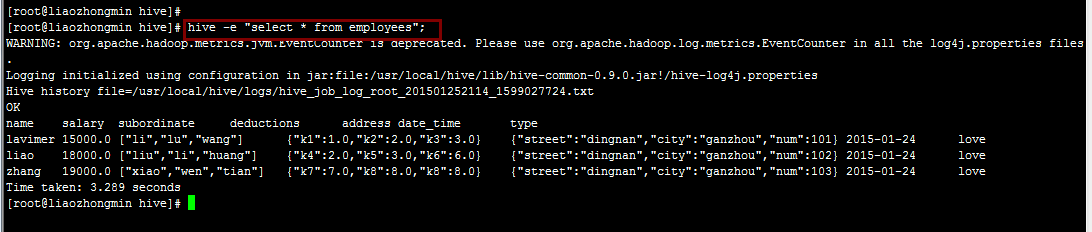
注:从图中可以看出这种方式并不需要进入Hive直接在Linux命令行运行,这可以避免切换状态带来的不便。
2.把查询结果导出到文件中,也是在Linux命令中使用hive -e "XXX" > a.txt
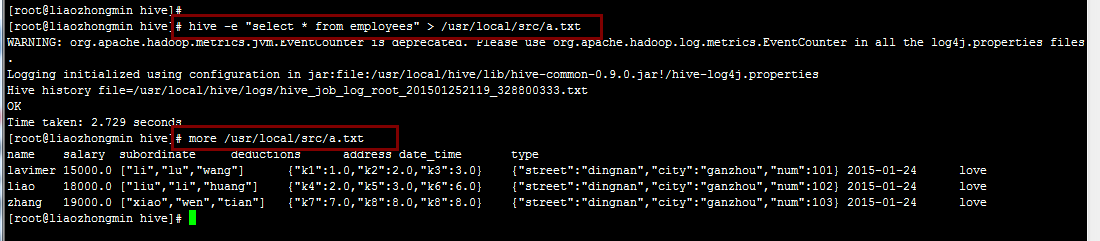
3.是执行语句安静的执行,使用hive -S -e "XXX"。

附:从上面我们可以看到和HQL语句执行相关的日志都不会输出了。
4.在Linux命令行中使用hive -f "文件" 执行写在某个文件中的HQL语句。
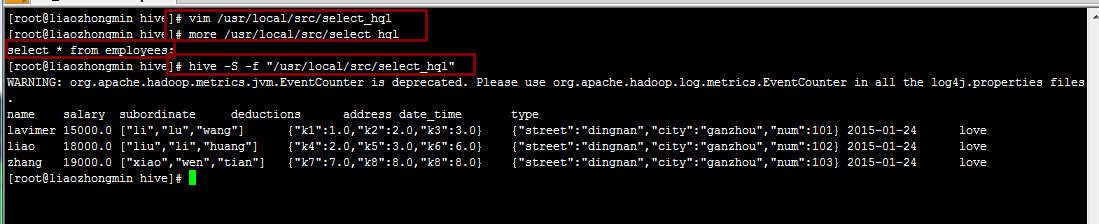
5.执行写在shell脚本中的查询语句
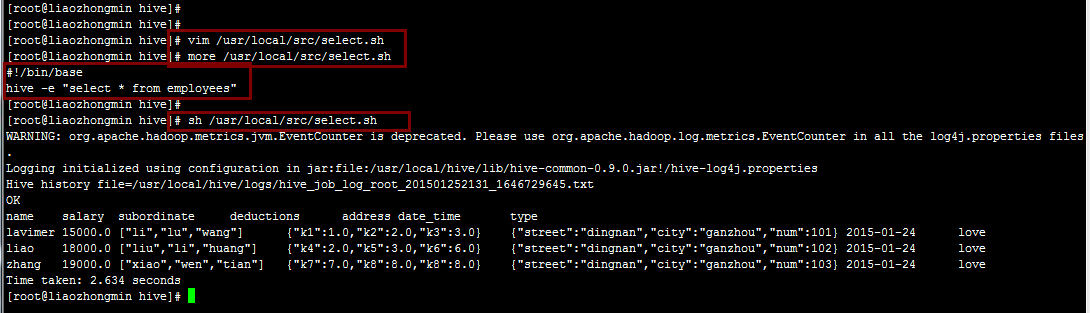
6.在Hive终端使用source 文件名 的形式执行写在文件中的语句

注:这个命令是在Hive终端执行的,且文件不需要使用双引号!
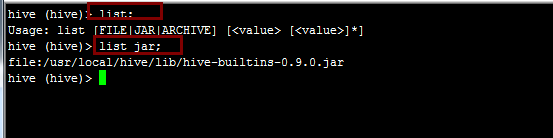
7.显示分布式缓存中的jar包,在hive终端使用list jar命令

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









