






1.研究背景
随着社会经济愈加发展,现代交通已经非常便利,其中道路交通仍占主导地位"。滞后的道路交通安全基础设施建设、严重不足的交警警力,相对薄弱的道路交通安全管理水平和交通参与者安全意
识之间的矛盾日益突出,加之环境污染和能源短缺,交通安全和交通阻塞造成了惊人的经济损失,成为日益严重的社会问题。
现在,道路交通问题的解决,需求助于智能车技术。智能车集中地运用了计算机、传感、信息,通信及自动控制等技术,是集决策规划、周边环境感知、道路自动识别等功能于一体的综合系统2。智能车自动行驶的首要任务是交通标志自动检测与识别,道路交通标志提供警告、指示信息,规范着驾驶员的行为,为便利、安全的驾驶提供可靠保障3。
2.图片演示

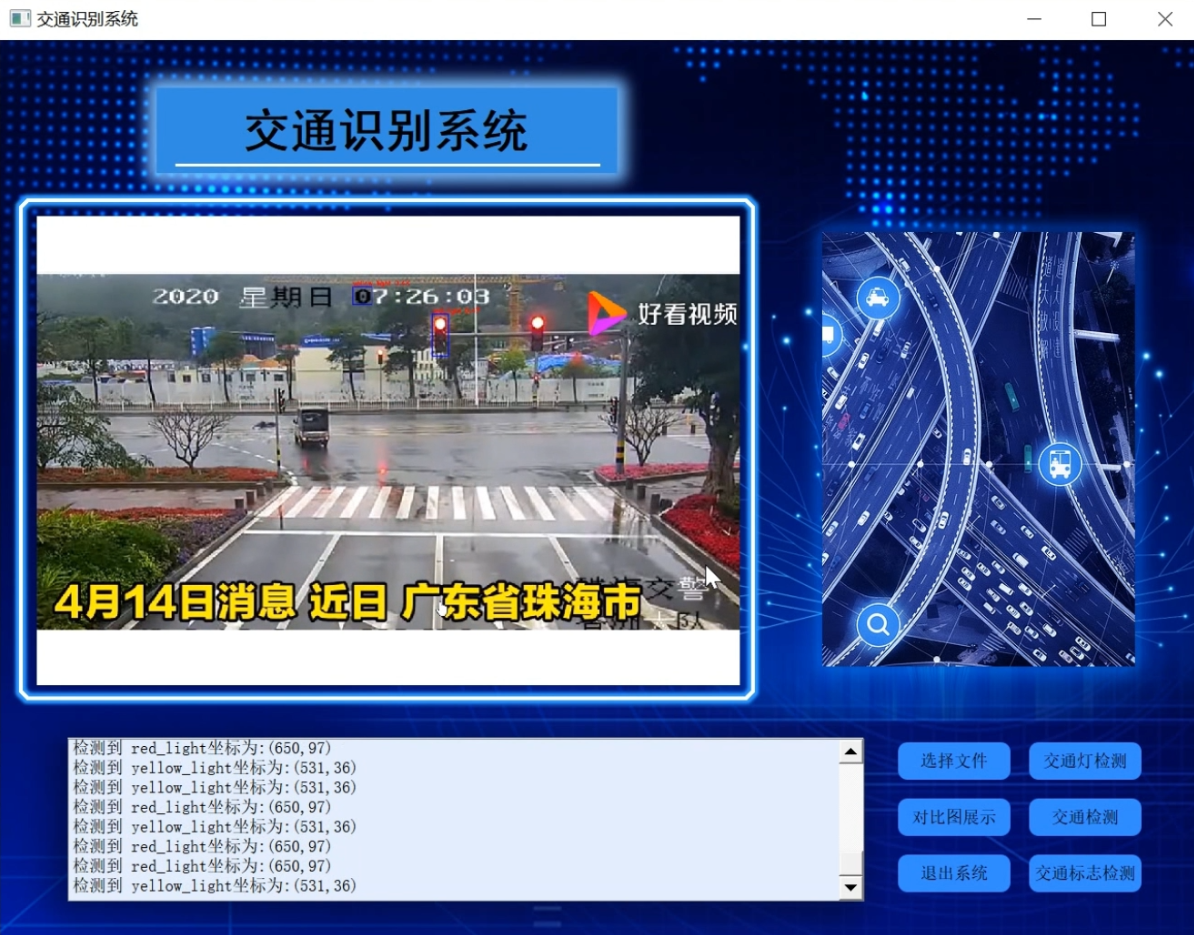

3.视频演示
基于YOLOv7和Deepsort的智慧交通系统(源码&教程)_哔哩哔哩_bilibili
4.Deepsort目标追踪
(1)获取原始视频帧
(2)利用目标检测器对视频帧中的目标进行检测
(3)将检测到的目标的框中的特征提取出来,该特征包括表观特征(方便特征对比避免ID switch)和运动特征(运动特征方
便卡尔曼滤波对其进行预测)
(4)计算前后两帧目标之前的匹配程度(利用匈牙利算法和级联匹配),为每个追踪到的目标分配ID。
Deepsort的前身是sort算法,sort算法的核心是卡尔曼滤波算法和匈牙利算法。
卡尔曼滤波算法作用:该算法的主要作用就是当前的一系列运动变量去预测下一时刻的运动变量,但是第一次的检测结果用来初始化卡尔曼滤波的运动变量。
匈牙利算法的作用:简单来讲就是解决分配问题,就是把一群检测框和卡尔曼预测的框做分配,让卡尔曼预测的框找到和自己最匹配的检测框,达到追踪的效果。
sort工作流程如下图所示:
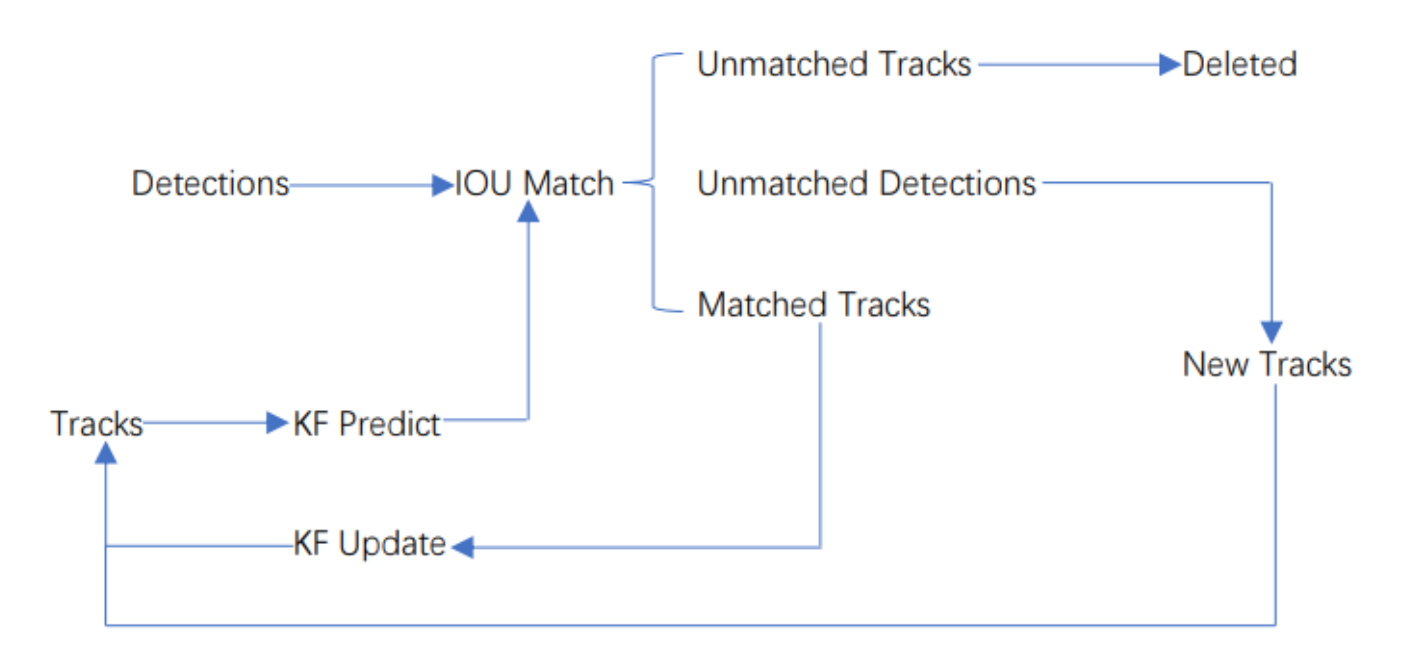
Detections是通过目标检测到的框框。Tracks是轨迹信息。
整个算法的工作流程如下:
(1)将第一帧检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。
(2)将该帧目标检测的框框和上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到视频帧结束。
Deepsort算法流程
由于sort算法还是比较粗糙的追踪算法,当物体发生遮挡的时候,特别容易丢失自己的ID。而该博客提出的方案在sort算法的基础上增加了级联匹配(Matching Cascade)和新轨迹的确认(confirmed)。Tracks分为确认态(confirmed),和不确认态(unconfirmed),新产生的Tracks是不确认态的;不确认态的Tracks必须要和Detections连续匹配一定的次数(默认是3)才可以转化成确认态。确认态的Tracks必须和Detections连续失配一定次数(默认30次),才会被删除。
Deepsort算法的工作流程如下图所示:
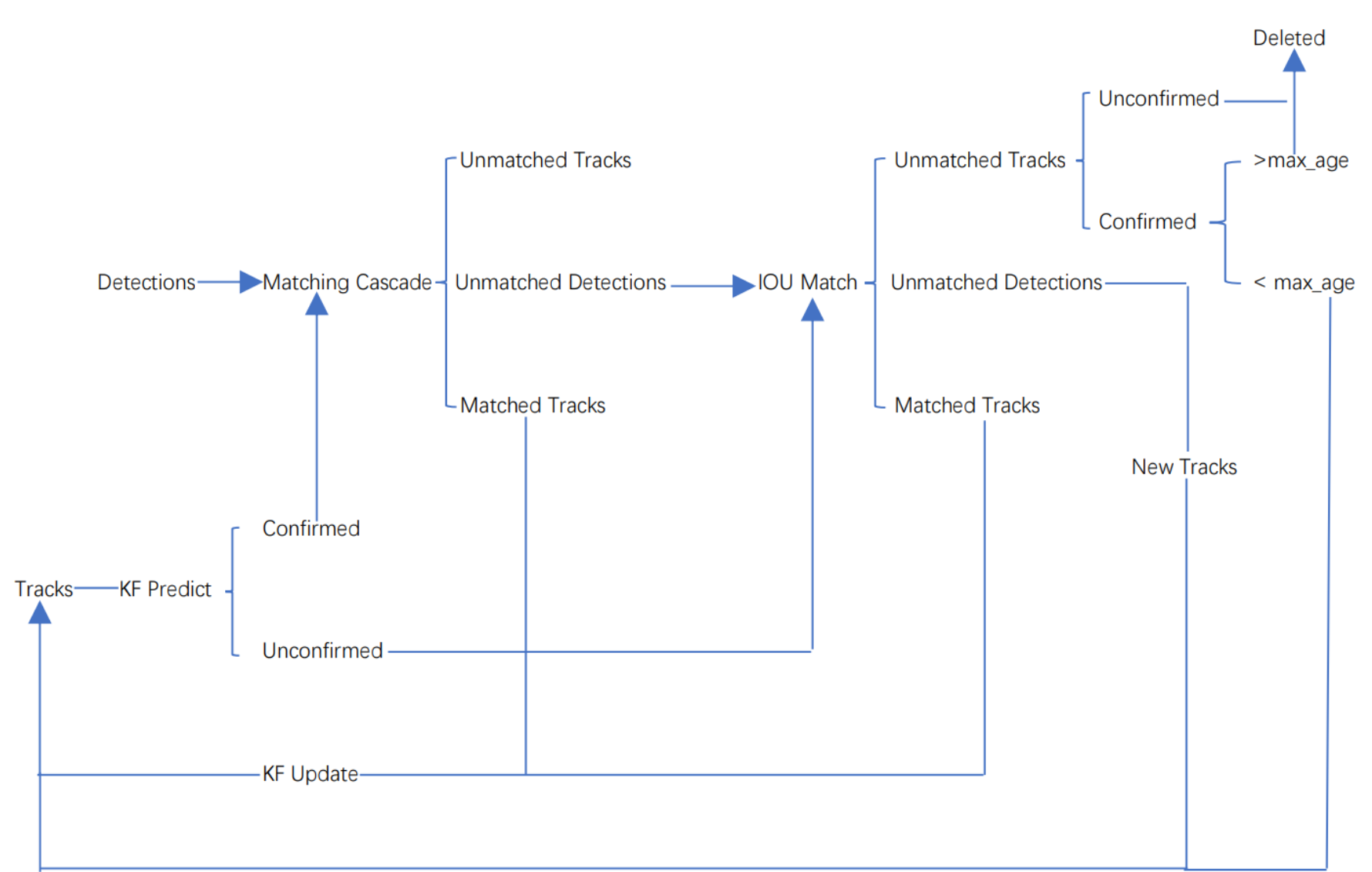
整个算法的工作流程如下:
(1)将第一帧次检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。这时候的Tracks一定是unconfirmed的。
(2)将该帧目标检测的框框和第上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到出现确认态(confirmed)的Tracks或者视频帧结束。
(5)通过卡尔曼滤波预测其确认态的Tracks和不确认态的Tracks对应的框框。将确认态的Tracks的框框和是Detections进行级联匹配(之前每次只要Tracks匹配上都会保存Detections其的外观特征和运动信息,默认保存前100帧,利用外观特征和运动信息和Detections进行级联匹配,这么做是因为确认态(confirmed)的Tracks和Detections匹配的可能性更大)。
(6)进行级联匹配后有三种可能的结果。第一种,Tracks匹配,这样的Tracks通过卡尔曼滤波更新其对应的Tracks变量。第二第三种是Detections和Tracks失配,这时将之前的不确认状态的Tracks和失配的Tracks一起和Unmatched Detections一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(7)将(6)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(8)反复循环(5)-(7)步骤,直到视频帧结束。
5.YOLOv7算法简介
YOLOv7 在 5 FPS 到 160 FPS 范围内,速度和精度都超过了所有已知的目标检测器
并在 V100 上,30 FPS 的情况下达到实时目标检测器的最高精度 56.8% AP。YOLOv7 是在 MS COCO 数据集上从头开始训练的,不使用任何其他数据集或预训练权重。
相对于其他类型的工具,YOLOv7-E6 目标检测器(56 FPS V100,55.9% AP)比基于 transformer 的检测器 SWINL Cascade-Mask R-CNN(9.2 FPS A100,53.9% AP)速度上高出 509%,精度高出 2%,比基于卷积的检测器 ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) 速度高出 551%,精度高出 0.7%。
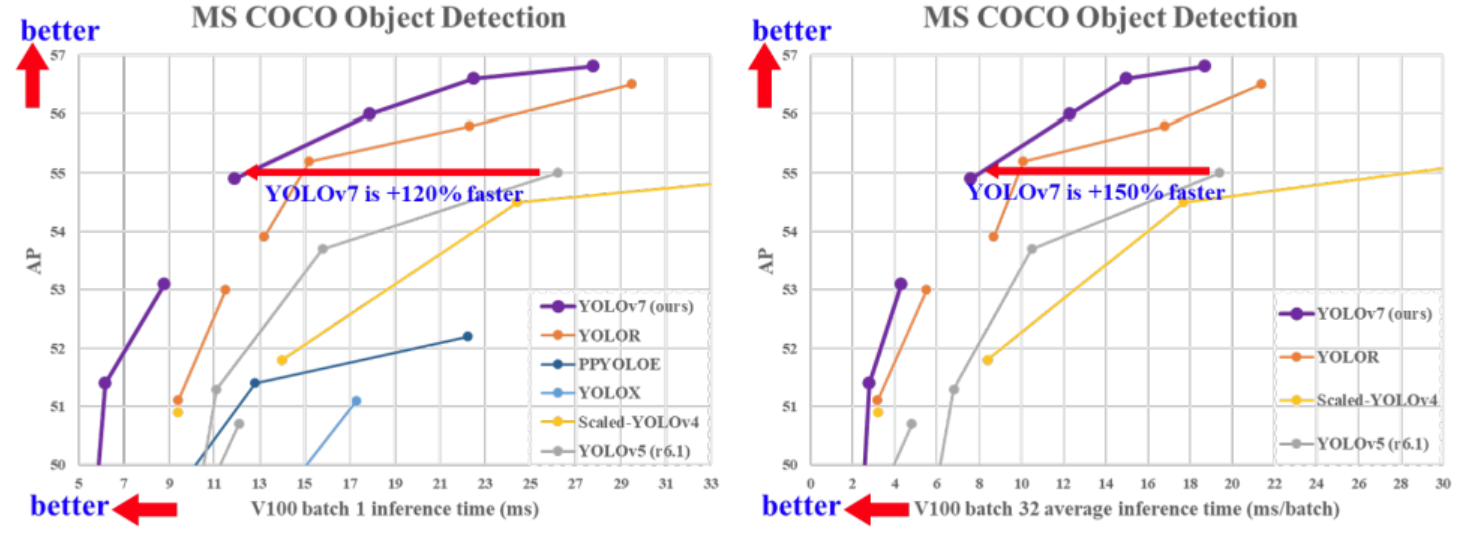
此外, YOLOv7 的在速度和精度上的表现也优于 YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、DETR 等多种目标检测器。
6.YOLOv7 技术方法
近年来,实时目标检测器仍在针对不同的边缘设备进行开发。例如,MCUNet 和 NanoDet 的开发专注于生产低功耗单芯片并提高边缘 CPU 的推理速度;YOLOX、YOLOR 等方法专注于提高各种 GPU 的推理速度;实时目标检测器的发展集中在高效架构的设计上;在 CPU 上使用的实时目标检测器的设计主要基于 MobileNet、ShuffleNet 或 GhostNet;为 GPU 开发的实时目标检测器则大多使用 ResNet、DarkNet 或 DLA,并使用 CSPNet 策略来优化架构。
YOLOv7 的发展方向与当前主流的实时目标检测器不同,研究团队希望它能够同时支持移动 GPU 和从边缘到云端的 GPU 设备。除了架构优化之外,该研究提出的方法还专注于训练过程的优化,将重点放在了一些优化模块和优化方法上。这可能会增加训练成本以提高目标检测的准确性,但不会增加推理成本。研究者将提出的模块和优化方法称为可训练的「bag-of-freebies」。
对于模型重参数化,该研究使用梯度传播路径的概念分析了适用于不同网络层的模型重参数化策略,并提出了有计划的重参数化模型。此外,研究者发现使用动态标签分配技术时,具有多个输出层的模型在训练时会产生新的问题:「如何为不同分支的输出分配动态目标?」针对这个问题,研究者提出了一种新的标签分配方法,称为从粗粒度到细粒度(coarse-to-fine)的引导式标签分配。
该研究的主要贡献包括:
(1) 设计了几种可训练的 bag-of-freebies 方法,使得实时目标检测可以在不增加推理成本的情况下大大提高检测精度;
(2) 对于目标检测方法的演进,研究者发现了两个新问题:一是重参数化的模块如何替换原始模块,二是动态标签分配策略如何处理分配给不同输出层的问题,并提出了解决这两个问题的方法;
(3) 提出了实时目标检测器的「扩充(extend)」和「复合扩展(compound scale)」方法,以有效地利用参数和计算;
(4) 该研究提出的方法可以有效减少 SOTA 实时目标检测器约 40% 的参数和 50% 的计算量,并具有更快的推理速度和更高的检测精度。
在大多数关于设计高效架构的文献中,人们主要考虑的因素包括参数的数量、计算量和计算密度。下图 2(b)中 CSPVoVNet 的设计是 VoVNet 的变体。CSPVoVNet 的架构分析了梯度路径,以使不同层的权重能够学习更多不同的特征,使推理更快、更准确。图 2 © 中的 ELAN 则考虑了「如何设计一个高效网络」的问题。
YOLOv7 研究团队提出了基于 ELAN 的扩展 E-ELAN,其主要架构如图所示。
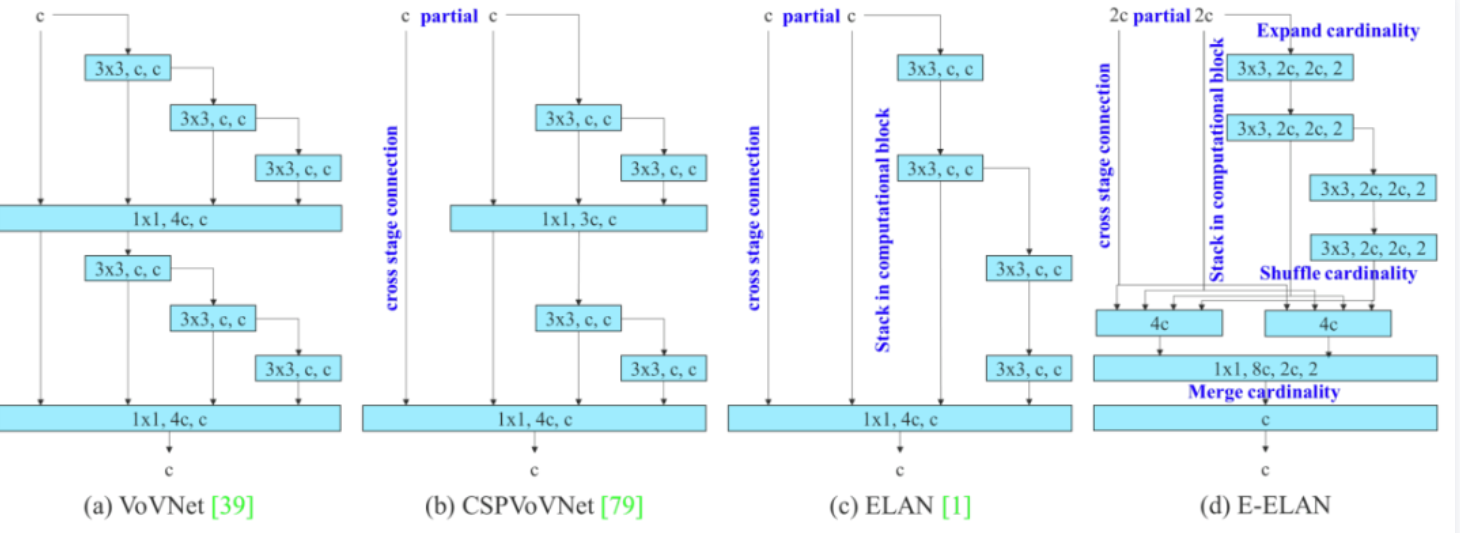
新的 E-ELAN 完全没有改变原有架构的梯度传输路径,其中使用组卷积来增加添加特征的基数(cardinality),并以 shuffle 和 merge cardinality 的方式组合不同组的特征。这种操作方式可以增强不同特征图学得的特征,改进参数的使用和计算效率。
无论梯度路径长度和大规模 ELAN 中计算块的堆叠数量如何,它都达到了稳定状态。如果无限堆叠更多的计算块,可能会破坏这种稳定状态,参数利用率会降低。新提出的 E-ELAN 使用 expand、shuffle、merge cardinality 在不破坏原有梯度路径的情况下让网络的学习能力不断增强。
在架构方面,E-ELAN 只改变了计算块的架构,而过渡层(transition layer)的架构完全没有改变。YOLOv7 的策略是使用组卷积来扩展计算块的通道和基数。研究者将对计算层的所有计算块应用相同的组参数和通道乘数。然后,每个计算块计算出的特征图会根据设置的组参数 g 被打乱成 g 个组,再将它们连接在一起。此时,每组特征图的通道数将与原始架构中的通道数相同。最后,该方法添加 g 组特征图来执行 merge cardinality。除了保持原有的 ELAN 设计架构,E-ELAN 还可以引导不同组的计算块学习更多样化的特征。
因此,对基于串联的模型,我们不能单独分析不同的扩展因子,而必须一起考虑。该研究提出图 (c),即在对基于级联的模型进行扩展时,只需要对计算块中的深度进行扩展,其余传输层进行相应的宽度扩展。这种复合扩展方法可以保持模型在初始设计时的特性和最佳结构。
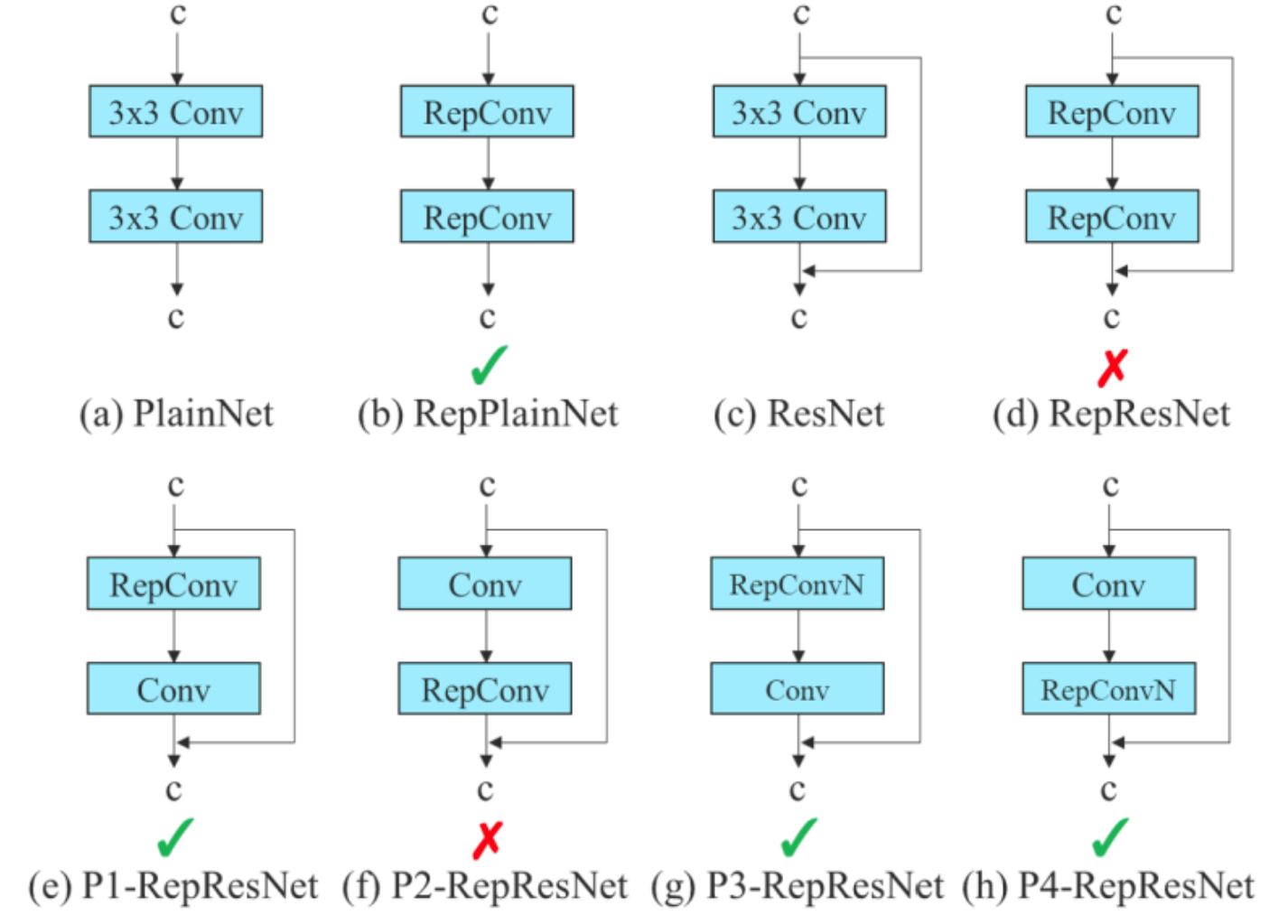
此外,该研究使用梯度流传播路径来分析如何重参数化卷积,以与不同的网络相结合。下图展示了该研究设计的用于 PlainNet 和 ResNet 的「计划重参数化卷积」。
7.数据预处理
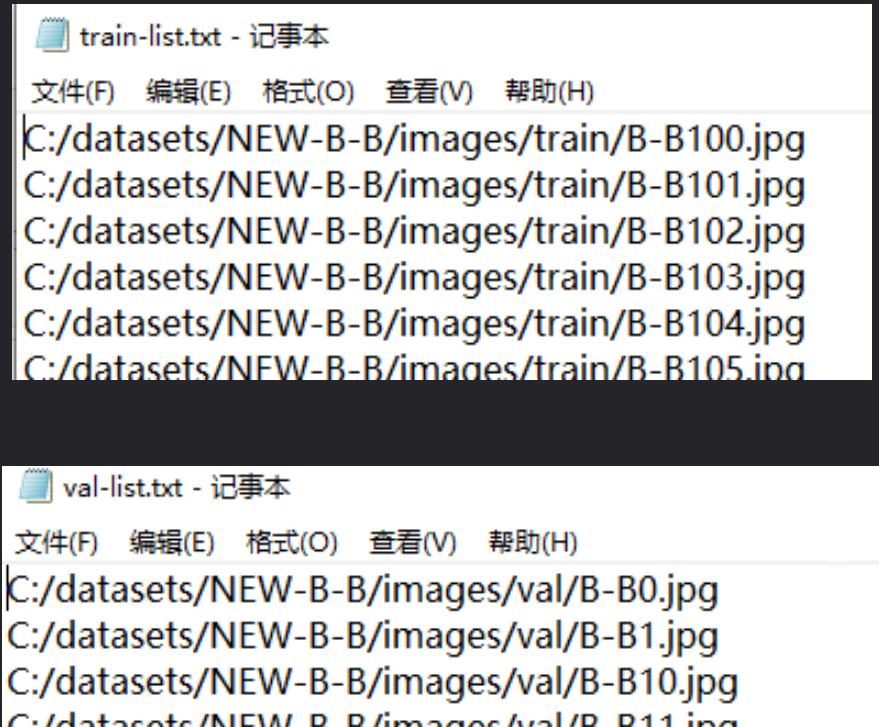
自己创建一个myself.yaml文件用来配置路径,路径格式与之前的V5、V6不同,只需要配置txt路径就可以
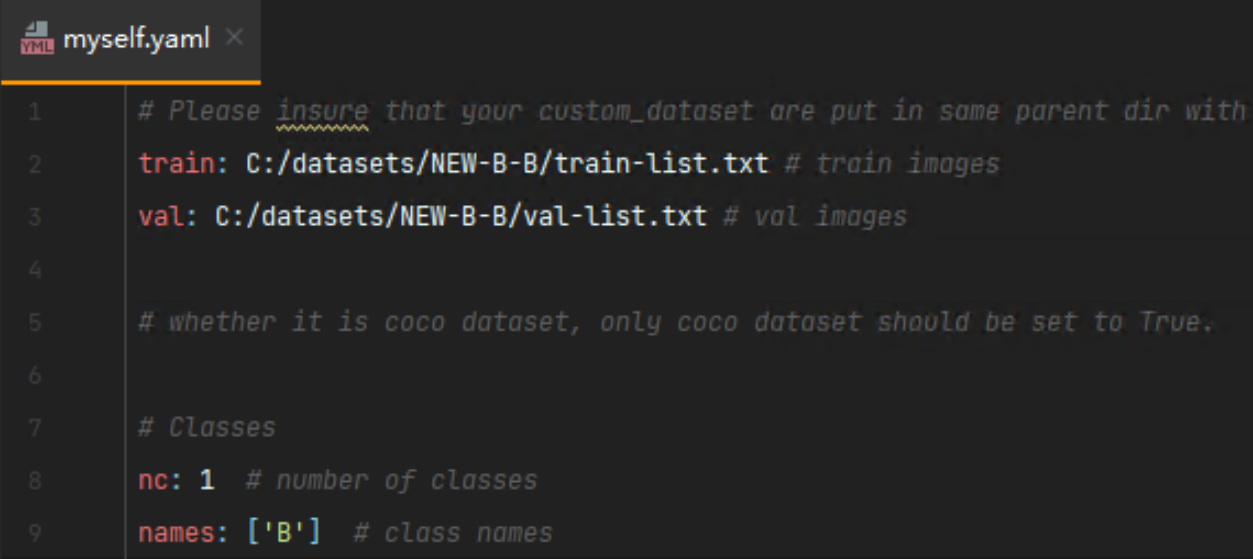
train-list.txt和val-list.txt文件里存放的都是图片的绝对路径(也可以放入相对路径)
如何获取图像的绝对路径,脚本写在下面了(也可以获取相对路径)
# From Mr. Dinosaur
import os
def listdir(path, list_name): # 传入存储的list
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
listdir(file_path, list_name)
else:
list_name.append(file_path)
list_name = []
path = 'D:/PythonProject/data/' # 文件夹路径
listdir(path, list_name)
print(list_name)
with open('./list.txt', 'w') as f: # 要存入的txt
write = ''
for i in list_name:
write = write + str(i) + '\n'
f.write(write)
8.训练过程
运行train.py
train文件还是和V5一样,为了方便,我将需要用到的文件放在了根目录下
路径修改完之后右击运行即可
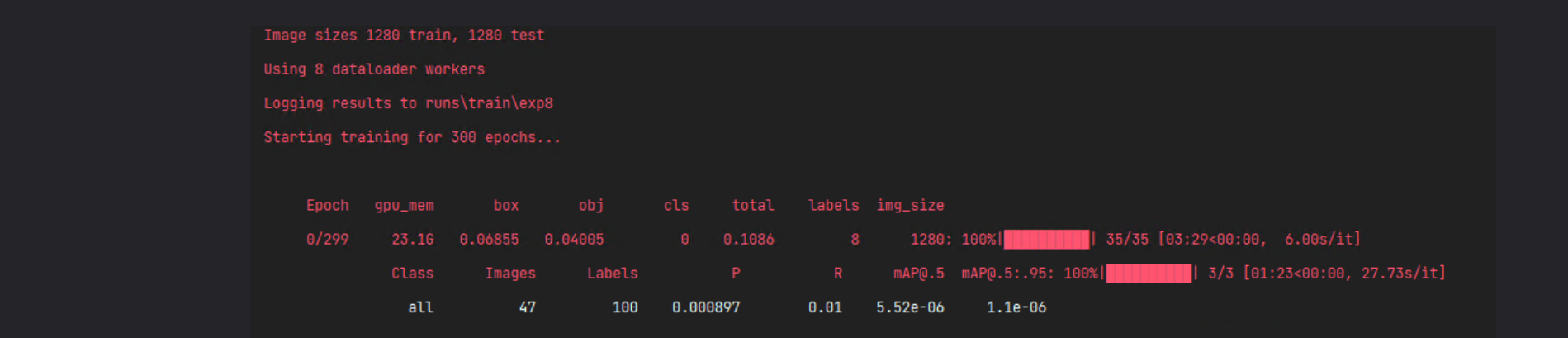
1.等待漫长的训练过程,实测GPU 3090ti训练长达40小时以上
2.在训练方面,YOLOv7相比YOLOv5更吃配置尤其是显存(上图可以看出需要23.1G显存,爆显存建议降低batchsize),建议电脑显存8G以下的谨慎尝试,可能训练的过程低配置的电脑会出现蓝屏等现象皆为显卡过载
3.在预测方面,使用本文提供的训练好的权重进行预测可以跳过上一步训练的步骤,CPU也能取得很好的预测结果且不会损伤电脑
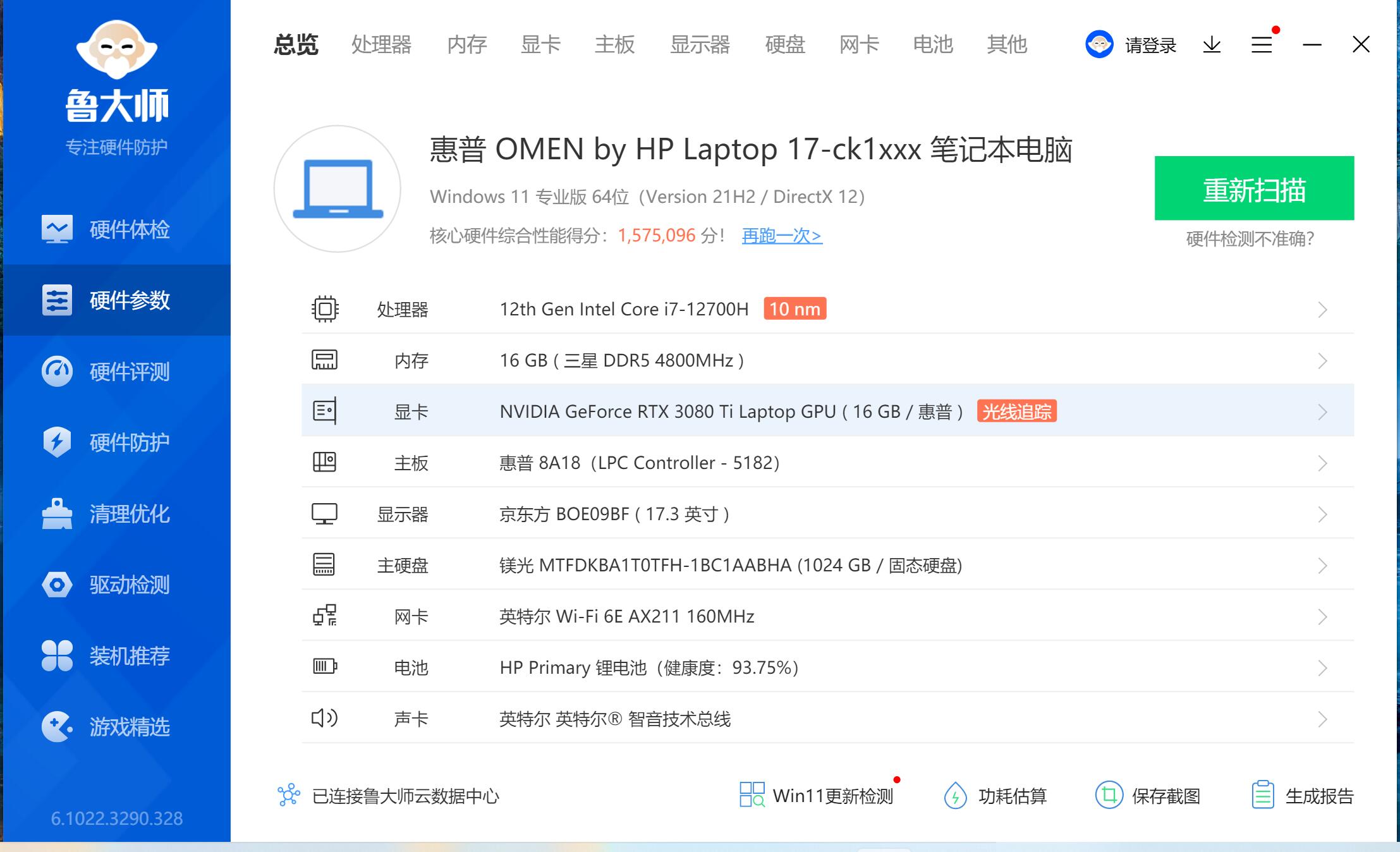
附上推荐设备配置
9.测试验证
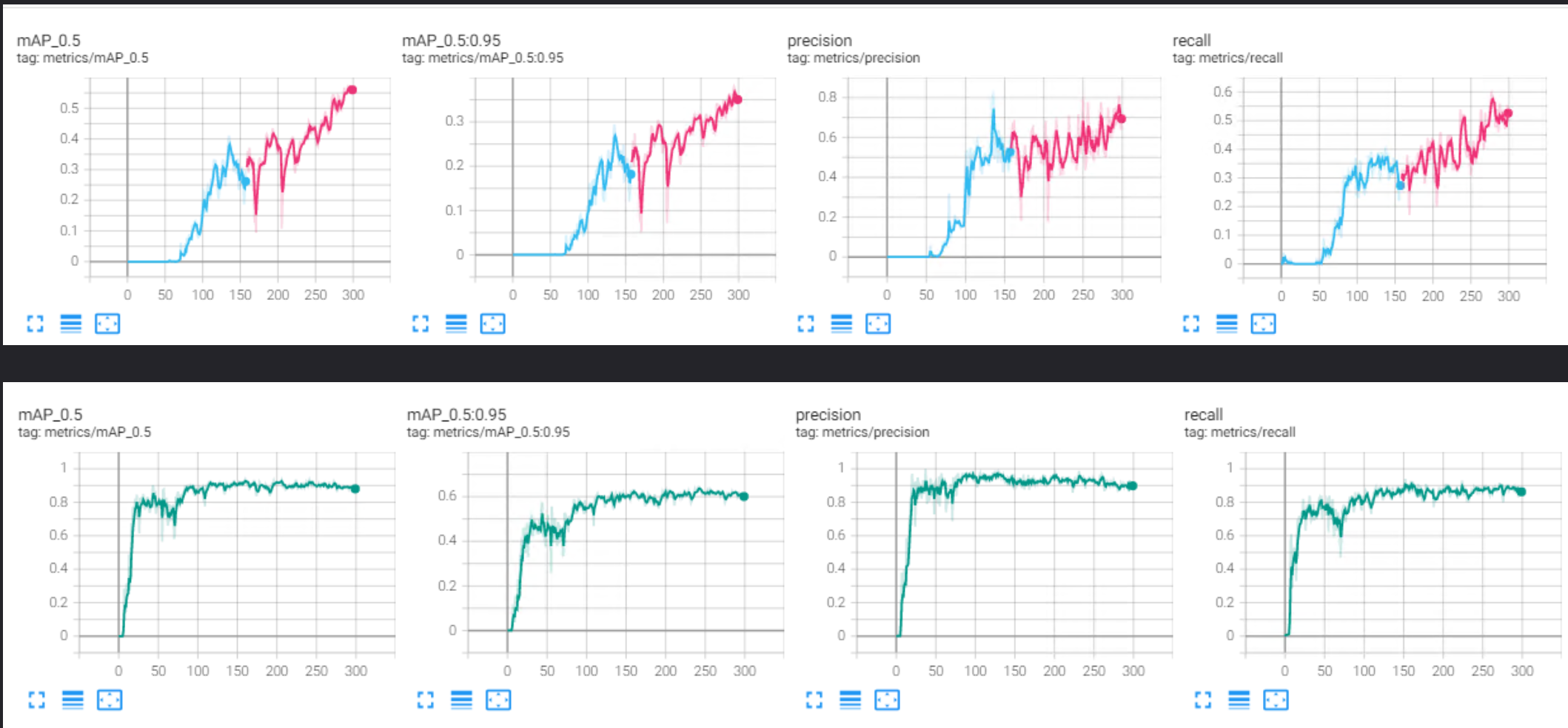
下面放上对比图:(上面V7,下面V5)
10.系统整合
下图源码&环境部署视频教程&自定义UI界面

参考博客《基于YOLOv7和Deepsort的智慧交通系统(源码&教程)》
11.参考文献
[1]郭亮,叶爱民,林涛,等.基于树莓派和Java语言的温湿度远程实时测量系统的设计[D].2017
[2]李晓旭,周焕银.基于STM32智能小车视觉控制导航的设计[D].2017
[3]雷慧杰.基于STM32的直流电机PID调速系统设计[D].2016
[4]郭勇,何军.STM32单片机多串口通信仿真测试技术研究[D].2015
[5]陈晖,张军国,李默涵,等.基于STC89C52和nRF24L01的智能小车设计[D].2012
[6]朱双东,陆晓峰.道路交通标志识别的研究现状及展望[D].2006
[7]王芳.交通禁止标志的检测和识别[D].2014
[8]张俊才.嵌入式信息家电平台中的红外通信研究与实现[D].2007
[9]Haibo He,Garcia, E.A…Learning from Imbalanced Data[J].IEEE Transactions on Knowledge & Data Engineering.2009,21(9).


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









