







以下源码在
org.apache.spark.sql.DataFrameReader/DataFrameWriter中
format指定内置数据源
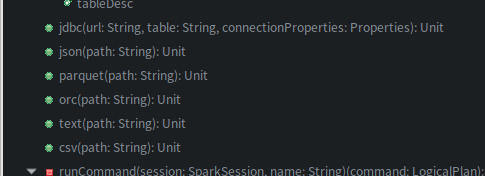
无论是load还是save都可以手动指定用来操作的数据源类型,format方法,通过eclipse查看相关源码,spark内置支持的数据源包括parquet(默认)、json、csv、text(文本文件)、 jdbc、orc,如图
def format(source: String): DataFrameWriter[T] = {
this.source = source
this}
private var source: String = df.sparkSession.sessionState.conf.defaultDataSourceName
def defaultDataSourceName: String = getConf(DEFAULT_DATA_SOURCE_NAME)
// This is used to set the default data source,默认处理parquet格式数据
val DEFAULT_DATA_SOURCE_NAME = buildConf("spark.sql.sources.default")
.doc("The default data source to use in input/output.")
.stringConf
.createWithDefault("parquet")
列举csv方法使用
源码如下,可见其实本质就是format指定数据源再调用save方法保存
def csv(paths: String*): DataFrame = format("csv").load(paths : _*) //可以指定多个文件或目录
def csv(path: String): Unit = {
format("csv").save(path)
}
可以看下我这篇文章:Spark1.x和2.x如何读取和写入csv文件
可选的option方法
还有就是这几个内置数据源读取或保存的方法都有写可选功能方法option,比如csv方法可选功能有(截取部分自认为有用的):
You can set the following CSV-specific opti
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3911
3911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









