









之前介绍了hadoop2.7.4,zookeeper3.4.10,hbase1.2.6集群的搭建,这种集群只有一个master作为NameNode,一旦master挂机,整个集群就会瘫痪。为了避免这种情况的出现,就要用到backup-master,即开启两个NameNode,一旦master出故障,backup-maser就会立即接管master的工作,使集群保持正常工作,就是HA(High Available), 高可用性集群。
一、简述
与之前不同的是,HA集群多出了一个standby的NameNode以及journalnode和ZKFC,简要说明一下:
(1)journalnode负责active NameNode与standby NameNode通信,保持数据同步。
两个namenode部署在不同的两台机器上,一个处于active状态,一个处于standby状态。这两个NameNode都与一组称为JNS的互相独立的进程保持通信(Journal Nodes)。当Active Node上更新了namespace,它将记录修改日志发送给JNS的多数派。Standby noes将会从JNS中读取这些edits,并持续关注它们对日志的变更。Standby Node将日志变更应用在自己的namespace中,当active namenode故障发生时,Standby将会在提升自己为Active之前,确保能够从JNS中读取所有的edits,即在故障发生之前Standy持有的namespace应该与Active保持完全同步。
(2)ZKFC是一个Zookeeper的客户端,它主要用来监测和管理NameNodes的状态,每个NameNode机器上都会运行一个ZKFC程序,它的职责主要有:一是健康监控。ZKFC间歇性的ping NameNode,得到NameNode返回状态,如果NameNode失效或者不健康,那么ZKFS将会标记其为不健康;二是Zookeeper会话管理。当本地NaneNode运行良好时,ZKFC将会持有一个Zookeeper session,如果本地NameNode为Active,它同时也持有一个“排他锁”znode,如果session过期,那么次lock所对应的znode也将被删除;三是选举。当集群中其中一个NameNode宕机,Zookeeper会自动将另一个激活。
二、前期准备
1、分布状况
|
| NameNode | DataNode | Zookeeper | DFSZKFC | JournalNode | HMaster | HRegionServer |
| node01 | 1 |
|
| 1 |
| 1 |
|
| node02 |
| 1 | 1 |
| 1 |
| 1 |
| node03 |
| 1 | 1 |
| 1 |
| 1 |
| node04 |
| 1 | 1 |
| 1 |
| 1 |
| node05 | 1(备份) |
|
| 1 |
| 1(备份) |
|
2、基础配置
(1)配置hosts
vim /etc/profile/hosts,加入
192.168.1.71 node01
192.168.1.72 node02
192.168.1.73 node03
192.168.1.74 node04
192.168.1.75 node05(2)ssh免登录
master与slaves相互免登录,具体参见:http://blog.csdn.net/lzxlfly/article/details/77916842
(3)配置jdk
vim /etc/profile ,加入以下内容
export JAVA_HOME=/usr/local/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH执行source /etc/profile 命令使其生效
(4)ntp时间同步
具体参见:http://blog.csdn.net/lzxlfly/article/details/78018595
(5)关闭防火墙
chkconfig iptables off 重启后生效
service iptables stop 即时生效,重启后失效
三、zookeeper配置
(1)配置zookeeper环境变量
编辑vi /etc/profile ,添加以下内容
export ZOOKEEPER_HOME=/opt/hadoop/zookeeper-3.4.10 #zookeeper安装路径
export PATH=$ZOOKEEPER_HOME/bin:$PATH(2)配置zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/zookeeper/zkdata #zookeeper数据存放路径
dataLogDir=/data/zookeeper/zkdatalog #zookeeper日志存放路径
# the port at which the clients will connect
clientPort=2181 ##zookeeper对外通信端口
server.2=node02:2888:3888
server.3=node03:2888:3888
server.4=node04:2888:3888
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
分别在node02、node03、node04上/data/zookeeper/zkdata,即dataDir对应目录下建立myid文件,
文件内容分别为2、3、4,也即server对应的2、3、4
(3)将配置好的zookeeper分发到其它节点对应路劲下
scp -r /opt/hadoop/zookeeper3.4.10 node02:`pwd`
scp -r /opt/hadoop/zookeeper3.4.10 node03:`pwd`(4)启动zookeeper集群
在node02、node03、node04上分别执行 zkServer.sh start 命令
ZooKeeper JMX enabled by default
Using config: /opt/hadoop/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED四、hadoop配置
1、配置环境变量
编辑vi /etc/profile ,添加以下内容
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.4 #hadoop安装路径
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin编辑vi /opt/hadoop/hadoop-2.7.4/etc/hadoop/hadoop-env.sh 添加以下内容
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk1.8 #jdk路径
export HADOOP_PID_DIR=/opt/bigdata/pids #自定义pid路径
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}编辑vi /opt/hadoop/hadoop-2.7.4/etc/hadoop/mapred-env.sh 添加以下内容
export HADOOP_MAPRED_PID_DIR=/opt/bigdata/pids #自定义pid路径编辑vi /opt/hadoop/hadoop-2.7.4/etc/hadoop/yarn-env.sh 添加以下内容
export YARN_PID_DIR=/opt/bigdata/pids #自定义pid路径
export JAVA_HOME=/opt/java_environment/jdk1.8.0_162
2、配置xml
进入 cd /opt/hadoop/hadoop-2.7.4/etc/hadoop下,进行配置
(1)core-site.xml配置,默认文件core-default.xml在hadoop-common-2.5.1.jar中
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value><!--这个地方改为dfs.nameservices的value-->
<description>NameNode URI</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value><!--默认4096 bytes-->
<description>Size of read/write buffer used inSequenceFiles</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data</value><!--建议重新设置,默认路径重启集群后会失效-->
<description>A base for other temporary directories</description>
</property>
</configuration>(2)hdfs-site.xml配置,默认文件hdfs-default.xml在hadoop-hdfs-2.5.1.jar中
<configuration>
<property>
<name>dfs.namenode.name.dir</name><!--这个属性可以省略,默认路径file:///${hadoop.tmp.dir}/dfs/name-->
<value>file:///data/dfs/name</value>
<description>Path on the local filesystem where the NameNodestores the namespace and transactions logs persistently</description>
</property>
<!--<property>HA模式无需secondaryNameNode,注释掉
<name>dfs.namenode.secondary.http-address</name>
<value>node05:9868</value><!--secondaryNameNode设置在node05上,建议生产环境专门设置在一台机器上-->
<description>The secondary namenode http server address andport,默认port50090</description>
</property>-->
<property>
<name>dfs.replication</name>
<value>2</value><!--备份默认为3,不能超过datanode的数量-->
</property>
<property>
<name>dfs.datanode.data.dir</name><!--这个属性可以省略,默认路径file:///${hadoop.tmp.dir}/dfs/data-->
<value>file:///data/dfs/data</value>
<description>Comma separated list of paths on the local filesystemof a DataNode where it should store its blocks</description>
</property>
<!--下边是HA的有关配置-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value> <!--服务名,名字自定义-->
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn5</value><!--nameservices的机器,名字自己起-->
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value><!--指定master的RPC地址-->
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn5</name>
<value>node05:8020</value><!--指定backup-master的RPC地址-->
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:50070</value><!--指定master的http地址-->
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn5</name>
<value>node05:50070</value><!--指定backup-master的http地址-->
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name><!--配置jounalnode-->
<value>qjournal://node02:8485;node03:8485;node04:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name><!--负责切换的类-->
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider </value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value><!--使用ssh方式切换-->
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value><!--如果使用ssh进行切换时通信时用的密钥存储的位置-->
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value><!--设置为true,master出故障自动切换到backup-maste,启用zkfc-->
</property>
</configuration>
(3)mapred-site.xml配置,默认文件mapred-default.xml在hadoop-mapreduce-client-core-2.5.1.jar中
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value><!--这里设置为yarn框架,默认local-->
<description>The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn.</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
<description>MapReduce JobHistoryServer IPC host:port</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
<description>MapReduce JobHistoryServer Web UI host:port</description>
</property>
</configuration>
(4)yarn-site.xml配置,默认文件yarn-default.xml在hadoop-yarn-common-2.5.1.jar中
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
<description>The hostname of theRM</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduceapplications</description>
</property>
</configuration>
(5)编辑vim slaves,去掉localhost,添加slaves节点
node02
node03
node04(6)将配置好的hadoop分发到其它节点对应目录下
scp -r /opt/hadoop/hadoop2.7.4 node02:`pwd`
scp -r /opt/hadoop/hadoop2.7.4 node03:`pwd`
scp -r /opt/hadoop/hadoop2.7.4 node04:`pwd`
scp -r /opt/hadoop/hadoop2.7.4 node05:`pwd`3、启动hadoop集群
(1)分别在node02、node03、node04上执行zkServer.sh start命令,启动zookeeper集群
(2)分别在node02、node03、node04上执行hadoop-daemon.sh start journalnode 命令,启动journalnode
node02
[root@node02 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-journalnode-node02.outnode03
[root@node03 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-journalnode-node02.outnode04
[root@node04 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-journalnode-node02.out(3)在node01上执行hdfs zkfc -formatZK命令,格式化ZKFC,部分日志如下
17/09/23 04:01:34 INFO zookeeper.ZooKeeper: Client environment:java.library.path=/opt/hadoop/hadoop-2.7.4/lib/native
17/09/23 04:01:34 INFO zookeeper.ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/09/23 04:01:34 INFO zookeeper.ZooKeeper: Client environment:java.compiler=<NA>
17/09/23 04:01:34 INFO zookeeper.ZooKeeper: Client environment:os.name=Linux
17/09/23 04:01:34 INFO zookeeper.ZooKeeper: Client environment:os.arch=amd64
17/09/23 04:01:34 INFO zookeeper.ZooKeeper: Client environment:os.version=2.6.32-431.el6.x86_64
17/09/23 04:01:34 INFO zookeeper.ZooKeeper: Client environment:user.name=root
17/09/23 04:01:34 INFO zookeeper.ZooKeeper: Client environment:user.home=/root
17/09/23 04:01:34 INFO zookeeper.ZooKeeper: Client environment:user.dir=/data/zookeeper
17/09/23 04:01:34 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=node01:2181,node02:2181,node03:2181 sessionTimeout=5000 watcher=org.apache.hadoop.ha.ActiveStandbyElector$WatcherWithClientRef@1dde4cb2
17/09/23 04:01:35 INFO zookeeper.ClientCnxn: Opening socket connection to server node01/192.168.1.71:2181. Will not attempt to authenticate using SASL (unknown error)
17/09/23 04:01:35 INFO zookeeper.ClientCnxn: Socket connection established to node01/192.168.1.71:2181, initiating session
17/09/23 04:01:35 INFO zookeeper.ClientCnxn: Session establishment complete on server node01/192.168.1.71:2181, sessionid = 0x15eada488810000, negotiated timeout = 5000
17/09/23 04:01:35 INFO ha.ActiveStandbyElector: Session connected.
17/09/23 04:01:35 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
17/09/23 04:01:35 INFO zookeeper.ZooKeeper: Session: 0x15eada488810000 closed
17/09/23 04:01:35 INFO zookeeper.ClientCnxn: EventThread shut down这时候在任意一台装有zookeeper的节点上,执行zkCli.sh命令,连接到zookeeper客户端
Connecting to localhost:2181
2017-09-23 04:08:11,343 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.10-39d3a4f269333c922ed3db283be479f9deacaa0f, built on 03/23/2017 10:13 GMT
2017-09-23 04:08:11,350 [myid:] - INFO [main:Environment@100] - Client environment:host.name=node02
2017-09-23 04:08:11,351 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.8.0_25
2017-09-23 04:08:11,355 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation
2017-09-23 04:08:11,356 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/usr/local/jdk1.7/jre
2017-09-23 04:08:11,357 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/opt/hadoop/zookeeper-3.4.10/bin/../build/classes:/opt/hadoop/zookeeper-3.4.10/bin/../build/lib/*.jar:/opt/hadoop/zookeeper-3.4.10/bin/../lib/slf4j-log4j12-1.6.1.jar:/opt/hadoop/zookeeper-3.4.10/bin/../lib/slf4j-api-1.6.1.jar:/opt/hadoop/zookeeper-3.4.10/bin/../lib/netty-3.10.5.Final.jar:/opt/hadoop/zookeeper-3.4.10/bin/../lib/log4j-1.2.16.jar:/opt/hadoop/zookeeper-3.4.10/bin/../lib/jline-0.9.94.jar:/opt/hadoop/zookeeper-3.4.10/bin/../zookeeper-3.4.10.jar:/opt/hadoop/zookeeper-3.4.10/bin/../src/java/lib/*.jar:/opt/hadoop/zookeeper-3.4.10/bin/../conf:.:/usr/local/jdk1.7/lib/dt.jar:/usr/local/jdk1.7/lib/tools.jar
2017-09-23 04:08:11,358 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
2017-09-23 04:08:11,358 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp
2017-09-23 04:08:11,358 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA>
2017-09-23 04:08:11,359 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux
2017-09-23 04:08:11,359 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64
2017-09-23 04:08:11,359 [myid:] - INFO [main:Environment@100] - Client environment:os.version=2.6.32-431.el6.x86_64
2017-09-23 04:08:11,359 [myid:] - INFO [main:Environment@100] - Client environment:user.name=root
2017-09-23 04:08:11,359 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/root
2017-09-23 04:08:11,359 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/data/zookeeper
2017-09-23 04:08:11,363 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@69d0a921
Welcome to ZooKeeper!
2017-09-23 04:08:11,408 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1032] - Opening socket connection to server localhost/0:0:0:0:0:0:0:1:2181. Will not attempt to authenticate using SASL (unknown error)
JLine support is enabled
[zk: localhost:2181(CONNECTING) 0] 2017-09-23 04:08:11,556 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@876] - Socket connection established to localhost/0:0:0:0:0:0:0:1:2181, initiating session
2017-09-23 04:08:11,570 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1299] - Session establishment complete on server localhost/0:0:0:0:0:0:0:1:2181, sessionid = 0x25eada489620002, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null按回车进入到zookeeper客户端命令界面,执行ls /,列出所有文件
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper, hadoop-ha]可以看到有zookeeper和hadoop-ha两个文件夹,执行ls /hadoop-ha
[zk: localhost:2181(CONNECTED) 1] ls /hadoop-ha
[mycluster]可以看到nameservices名字mycluster已经被植入到zookeeper中,quit可以退出
[zk: localhost:2181(CONNECTED) 4] quit
Quitting...
2017-09-23 04:11:05,450 [myid:] - INFO [main:ZooKeeper@684] - Session: 0x35eada4b87c0000 closed
2017-09-23 04:11:05,454 [myid:] - INFO [main-EventThread:ClientCnxn$EventThread@519] - EventThread shut down for session: 0x35eada4b87c0000(4)在node01上执行hdfs namenode -format命令,格式化namenode,部分日志如下
17/09/23 04:17:52 INFO util.GSet: Computing capacity for map NameNodeRetryCache
17/09/23 04:17:52 INFO util.GSet: VM type = 64-bit
17/09/23 04:17:52 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
17/09/23 04:17:52 INFO util.GSet: capacity = 2^15 = 32768 entries
Re-format filesystem in QJM to [192.168.1.72:8485, 192.168.1.73:8485, 192.168.1.74:8485] ? (Y or N) Y
17/09/23 04:18:22 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1931614468-192.168.1.71-1506154702817
17/09/23 04:18:22 INFO common.Storage: Storage directory /data/dfs/name has been successfully formatted.
17/09/23 04:18:23 INFO namenode.FSImageFormatProtobuf: Saving image file /data/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
17/09/23 04:18:23 INFO namenode.FSImageFormatProtobuf: Image file /data/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds.
17/09/23 04:18:23 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
17/09/23 04:18:23 INFO util.ExitUtil: Exiting with status 0
17/09/23 04:18:23 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node01/192.168.1.71
************************************************************/格式化完成后并在node01上执行hadoop-daemon.sh start namenode命令,启动namenode
[root@node01 ~]# hadoop-daemon.sh start namenode
starting namenode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-namenode-node01.out(5)在node05上执行hdfs namenode -bootstrapStandby命令,把node01上的信息,同步到备份的node05上。node05作为备份的namenode要和活跃的namenode的信息保持一致,不能再执行格式化操作。
17/09/23 04:28:31 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
17/09/23 04:28:31 INFO namenode.NameNode: createNameNode [-bootstrapStandby]
=====================================================
About to bootstrap Standby ID nn5 from:
Nameservice ID: mycluster
Other Namenode ID: nn1
Other NN's HTTP address: http://node01:50070
Other NN's IPC address: node01/192.168.1.71:8020
Namespace ID: 392086364
Block pool ID: BP-1931614468-192.168.1.71-1506154702817
Cluster ID: CID-01a7bb63-83af-4130-9ffa-f5f6c2ffd9b9
Layout version: -63
isUpgradeFinalized: true
=====================================================
17/09/23 04:28:32 INFO common.Storage: Storage directory /data/dfs/name has been successfully formatted.
17/09/23 04:28:33 INFO namenode.TransferFsImage: Opening connection to http://node01:50070/imagetransfer?getimage=1&txid=0&storageInfo=-63:392086364:0:CID-01a7bb63-83af-4130-9ffa-f5f6c2ffd9b9
17/09/23 04:28:33 INFO namenode.TransferFsImage: Image Transfer timeout configured to 60000 milliseconds
17/09/23 04:28:33 INFO namenode.TransferFsImage: Transfer took 0.01s at 0.00 KB/s
17/09/23 04:28:33 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 321 bytes.
17/09/23 04:28:33 INFO util.ExitUtil: Exiting with status 0
17/09/23 04:28:33 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node05/192.168.1.75
************************************************************/
(6)在node01上执行start-all.sh,启动hadoop集群。
[root@node01 ~]# start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [node01 node05]
node05: starting namenode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-namenode-node05.out
node01: namenode running as process 4473. Stop it first.
node04: starting datanode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-datanode-node04.out
node02: starting datanode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-datanode-node02.out
node03: starting datanode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-datanode-node03.out
Starting journal nodes [node02 node03 node04]
node04: journalnode running as process 2183. Stop it first.
node02: journalnode running as process 2402. Stop it first.
node03: journalnode running as process 2321. Stop it first.
Starting ZK Failover Controllers on NN hosts [node01 node05]
node05: starting zkfc, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-zkfc-node05.out
node01: starting zkfc, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-zkfc-node01.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop/hadoop-2.7.4/logs/yarn-root-resourcemanager-node01.out
node04: starting nodemanager, logging to /opt/hadoop/hadoop-2.7.4/logs/yarn-root-nodemanager-node04.out
node02: starting nodemanager, logging to /opt/hadoop/hadoop-2.7.4/logs/yarn-root-nodemanager-node02.out
node03: starting nodemanager, logging to /opt/hadoop/hadoop-2.7.4/logs/yarn-root-nodemanager-node03.out(7)在浏览器查看hadoop集群状态
在浏览器输入http://node01:50070,可以看到node01处于active状态
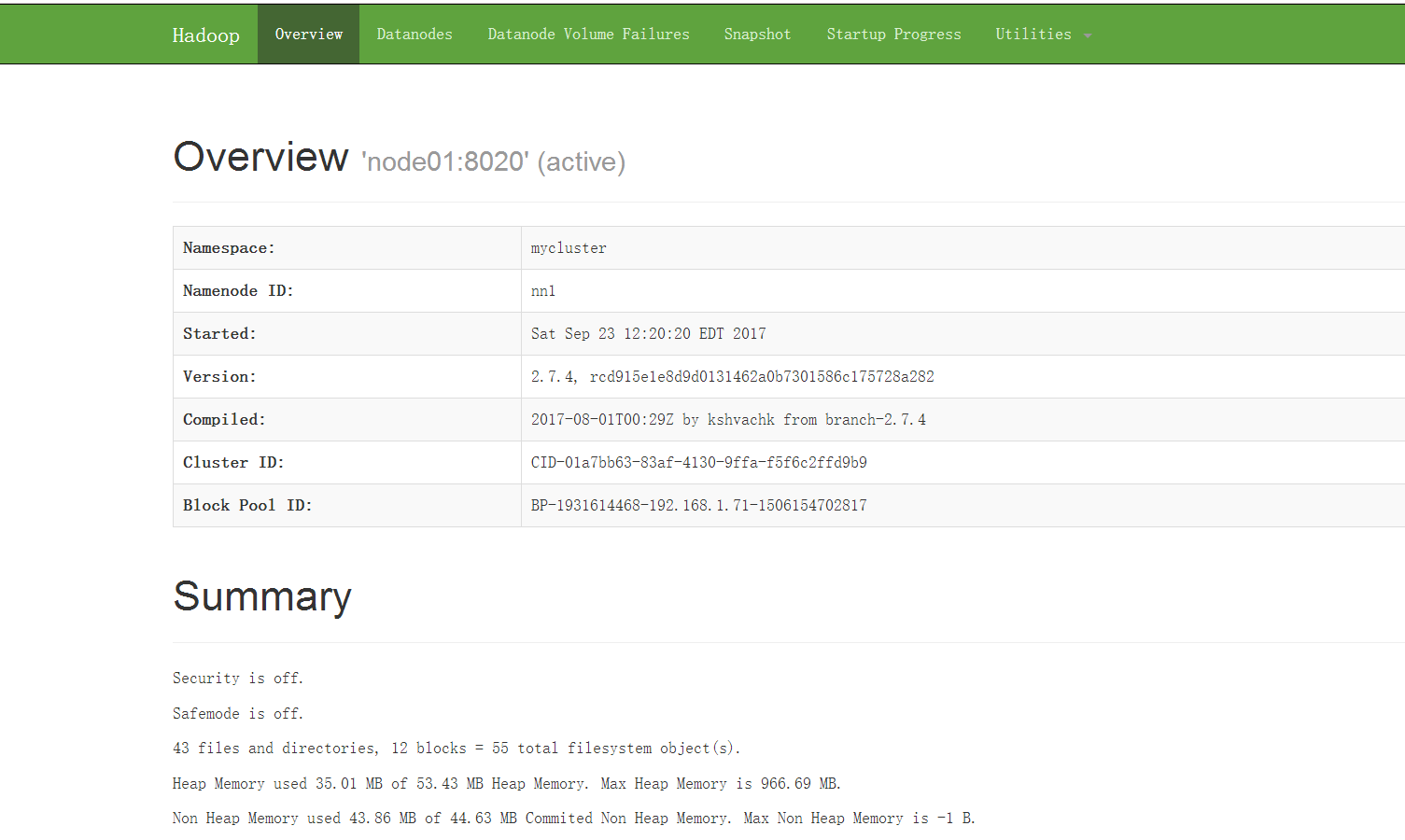
在浏览器输入http://node05:50070,可以看到node05处于standby状态
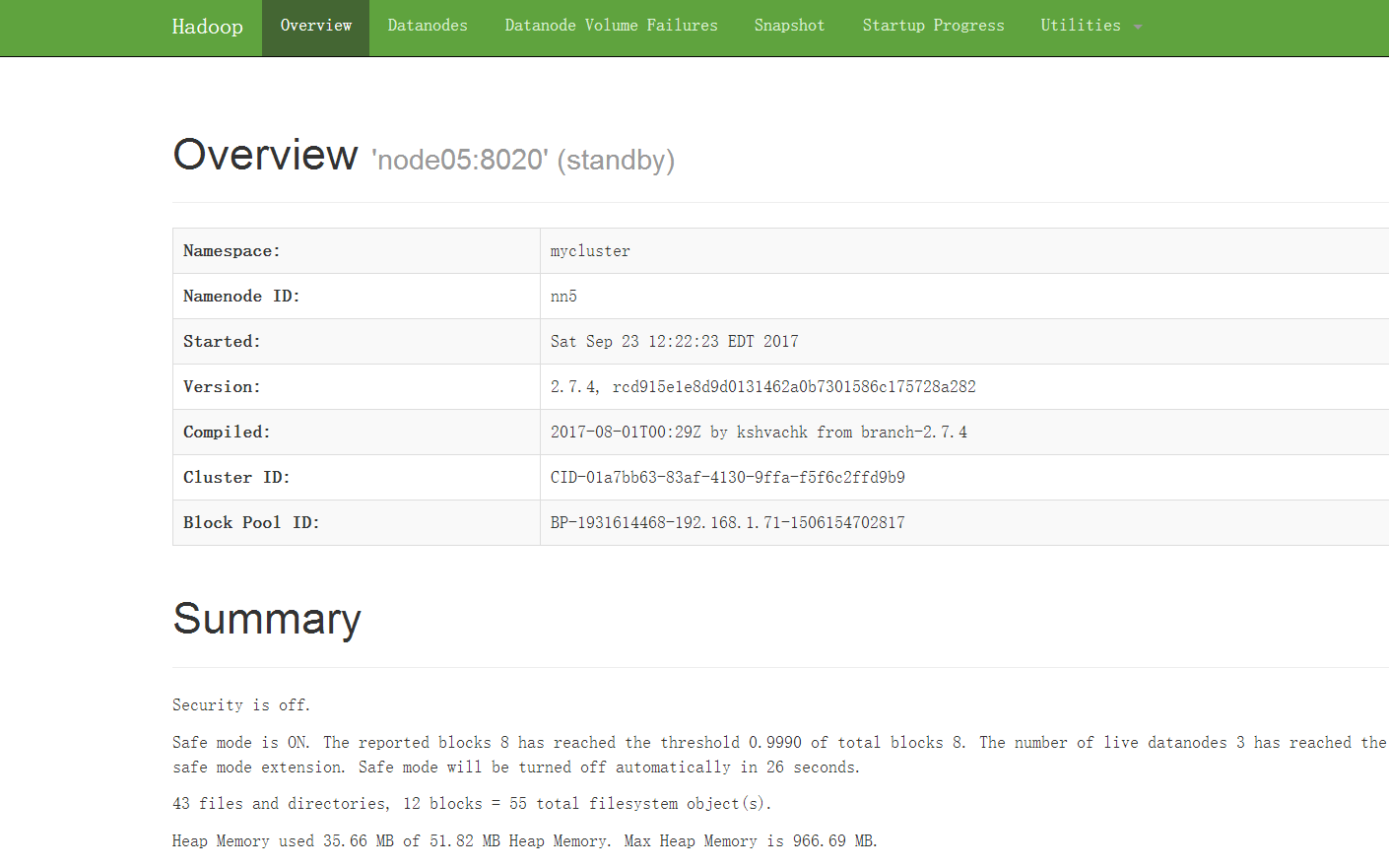
这时候,让node01出故障,kill掉node01的namenode
[root@node01 conf]# jps
4946 DFSZKFailoverController
11442 NameNode
11651 Jps
6195 HMaster
5030 ResourceManager
4299 QuorumPeerMain
[root@node01 conf]# kill -9 11442
在浏览器访问http://node01:50070已经无法访问,访问http://node05:50070,看到node05变为active状态
这时候重新启动node01

[root@node01 conf]# hadoop-daemon.sh start namenode
starting namenode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-namenode-node01.out
在浏览器访问http://node01:50070,可以看到node01变为standby状态,而不是原来的active状态。
从而实现了出故障时两NameNode的自动切换

五、hbase配置
1、配置hbase环境变量
编辑vim /etc/profile ,添加以下内容
export HBASE_HOME=/opt/hadoop/hbase-1.2.6 #hbase安装路径
export PATH=$HBASE_HOME/bin:$PATH编辑 vim /opt/hadoop/hbase-1.2.6/conf/hbase-env.sh,配置jdk路径
export JAVA_HOME=/usr/local/jdk1.8 #jdk路径
export HBASE_PID_DIR=/opt/bigdata/pids #pid 自定义路径
export HBASE_MANAGES_ZK=false #设置为false,不用hbase内置的zookeeper
如果jdk1.8,还要注释以下两行
# Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"若不注释的话,启动hbase会报以下警告,Java HotSpot(TM) 64-Bit Server VM warning。
tarting master, logging to /opt/hadoop/hbase-1.2.6/logs/hbase-root-master-node01.out
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
node02: starting regionserver, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-regionserver-node02.out
node03: starting regionserver, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-regionserver-node03.out
node04: starting regionserver, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-regionserver-node04.out
node02: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
node02: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
node03: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
node03: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
node04: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
node04: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
node05: starting master, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-master-node05.out
node05: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
node05: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.02、配置regionservers、backup-masters
vim regionservers,去掉localhost,添加slaves节点
node02
node03
node04backup-masters不存在,需要手动创建并添加备份节点
node05 #可以有多个备份节点,一般一个备份就够了3、配置hbase-xml
(1)配置hbase-site.xml,默认文件hbase-site.xml在hbase-common-1.2.6.jar中
<configuration>
<property>
<name>hbase.rootdir</name> <!-- hbase存放数据目录 ,默认值${hbase.tmp.dir}/hbase-->
<value>hdfs://mycluster/data/hbase_db</value><!--这个地方要改变,mycluster为hdfs-site.xml中dfs.nameservices的值-->
</property>
<property>
<name>hbase.cluster.distributed</name> <!-- 是否分布式部署 -->
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name> <!-- list of zookooper -->
<value>node01,node02,node03</value>
</property>
</configuration>
(2)把hadoop的hdfs-site.xml复制一份到hbase的conf目录下
因为hbase的数据最终要写入hdfs中,要把hbase的路径链接到hsfs中
cp /opt/hadoop/hadoop2.7.4/etc/haddop/hdfs-site.xml /opt/hadoop/hbase-1.2.6/conf(3)将配置好的hbase分发到其它节点
scp -r /opt/hadoop/hbase1.2.6 node02:`pwd`
scp -r /opt/hadoop/hbase1.2.6 node03:`pwd`
scp -r /opt/hadoop/hbase1.2.6 node04:`pwd`
scp -r /opt/hadoop/hbase1.2.6 node05:`pwd4、启动hbase
(1)在node01上执行start-hbase.sh命令
[root@node01 ~]# start-hbase.sh
starting master, logging to /opt/hadoop/hbase-1.2.6/logs/hbase-root-master-node01.out
node03: starting regionserver, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-regionserver-node03.out
node02: starting regionserver, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-regionserver-node02.out
node04: starting regionserver, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-regionserver-node04.out
node05: starting master, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-master-node05.out(2)在浏览器查看hbase集群状态
在浏览器输入http://node01:16010,可以看到node01为master,node05为backup master
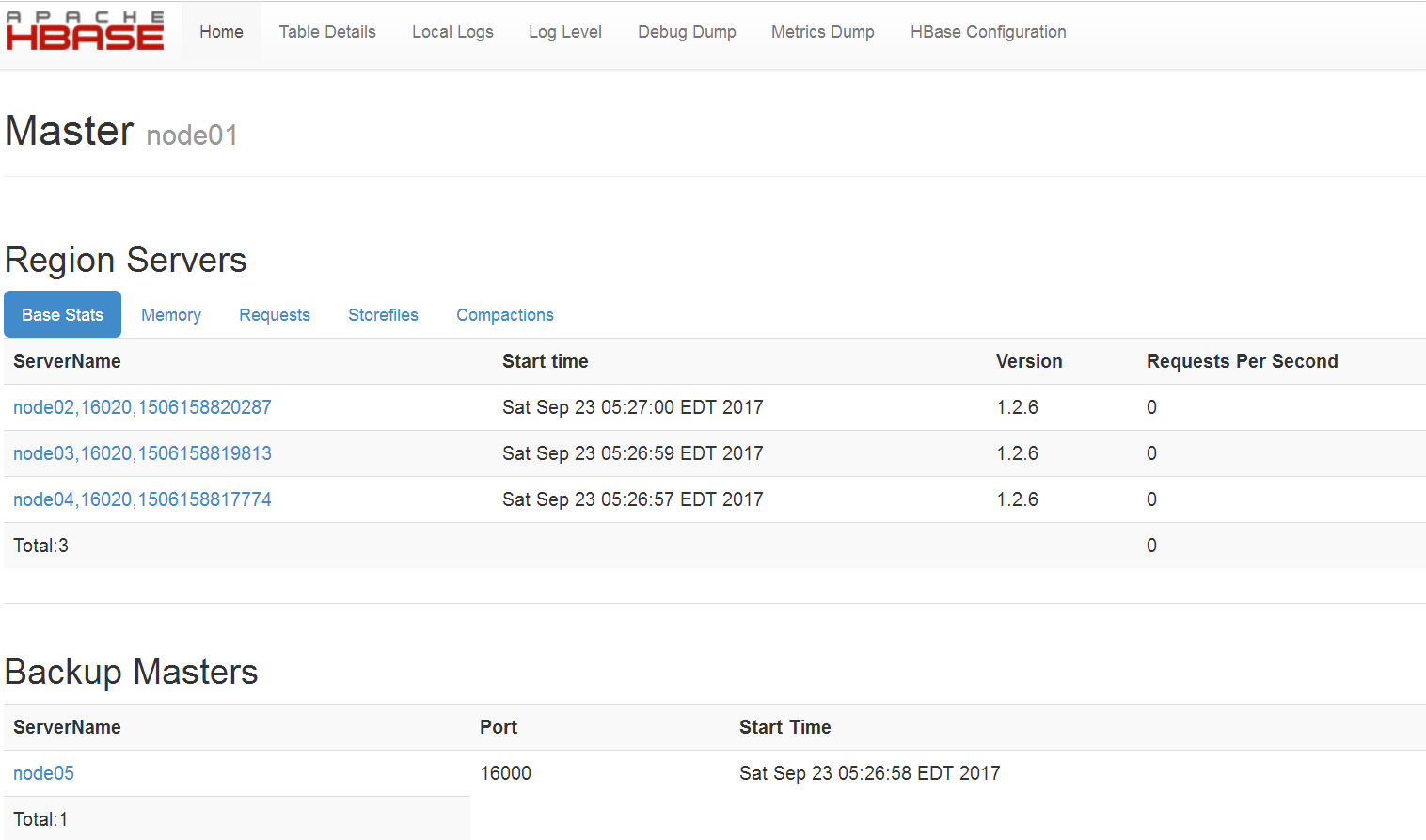
在浏览器输入http://node05:16010,可以看到node05为backup master,node01为current active master

可以kill掉node01,node05就会有backup master变为active master,重新启动node01,node01就会成为backup master
这里不再详细展示,操作同hadoop集群是一样的。
5、执行jps查看进程
node01
[root@node01 ~]# jps
6304 Jps
4946 DFSZKFailoverController
6195 HMaster
5030 ResourceManager
4473 NameNode
4299 QuorumPeerMain
node02
[root@node02 ~]# jps
2402 JournalNode
2611 NodeManager
3800 Jps
2491 DataNode
2892 HRegionServer
2223 QuorumPeerMainnode03
[root@node03 ~]# jps
2321 JournalNode
2213 QuorumPeerMain
2390 DataNode
2776 HRegionServer
3610 Jps
2510 NodeManagernode04
[root@node04 ~]# jps
3588 Jps
2262 DataNode
2647 HRegionServer
2183 JournalNode
2382 NodeManagernode05
[root@node05 ~]# jps
5680 Jps
4211 NameNode
4684 HMaster
4303 DFSZKFailoverController















 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









