







 本文概述了知识图谱如何增强大模型的训练和推理,介绍了ERNIE3.0、K-BERT等方法,讨论了存在的问题如知识噪声,以及动态知识融合和不同处理技术。作者还提到了大模型增强知识图谱构建的几个方面,如实体发掘、类型标注和关系抽取,以及端到端构建方法的发展趋势。
本文概述了知识图谱如何增强大模型的训练和推理,介绍了ERNIE3.0、K-BERT等方法,讨论了存在的问题如知识噪声,以及动态知识融合和不同处理技术。作者还提到了大模型增强知识图谱构建的几个方面,如实体发掘、类型标注和关系抽取,以及端到端构建方法的发展趋势。
写在前面:
本文是笔者的随笔,更多的是针对笔者目前的需求阅读综述文献或者部分论文的相关工作部分进行的简单整合,由于时间关系,也不一定会更新到一些最新的技术,相比于知识图谱与大模型本身这一个大领域,是十分简陋的整合,建议真的想要仔细的了解这个领域的工作者阅读这一项工作:https://arxiv.org/abs/2306.08302。这项工作远比本文要完善,本文更像是笔者结合自己的需求,写的一篇局部的技术速查。
知识图谱增强大模型
预训练阶段
将知识图谱作为大模型训练的input
ERNIE 3.0
这类方法将知识图的三元组表示成为一个tokens的序列,并进行随机[mask]三元组的关系标记或句子里的标记,从而将KGs里面的知识与文本的表示结合起来。
存在的问题:句子里的标记与知识子图里的标记进行了深度的交互,这会引入知识噪声。
K-BERT
通过可见矩阵解决了这个问题,只有知识实体可以访问三元组里的信息,句子中的tokens只能在子注意力模块关注到彼此。
Colake
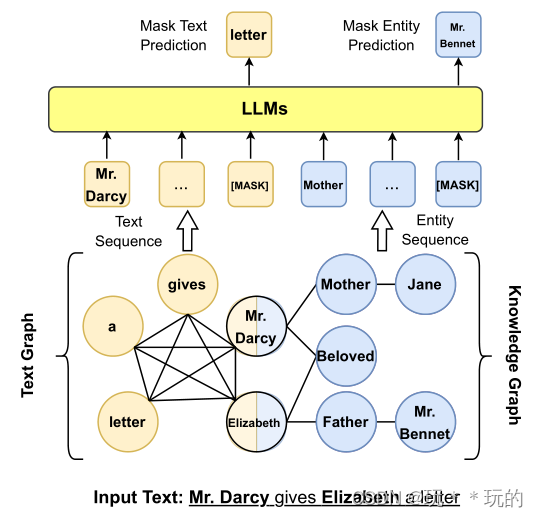
输入句子中的tokens形成了一个完全的词图,与知识实体对齐的标记与起相邻的实体链接。
知识图谱增强大模型的推理过程
定义:在推理阶段使用知识图谱,使大模型不需要重新训练就可以掌握最新的知识。
动态知识融合
直接方法:two-power架构
一个分离的模块处理文本的输入,一个模块处理相关的知识图输入
但是本方法中,两个模块是分离的,也就以为这缺乏了知识和文本之间的互动。
一些其他的处理方法
MHRRN:将大模型根据输入的最终输出作为指导知识的推理过程的依据(只是一个单向的交互过程)。
QA-GNN:提出使用基于GNN的模型通过消息传递对输入上下文和KG信息进行联合推理。
实现思路:通过池化操作将输入的文本信息表示成为一个特殊的节点,并且将这个节点与KG中的其他实体连接起来。
存在问题:文本的输入只集中到一个单一的密集向量当中,限制了信息融合的性能。
JointLK:通过LLM->KG和KG->LLM的双向注意机制,在文本和知识图中实现细粒度的交互。
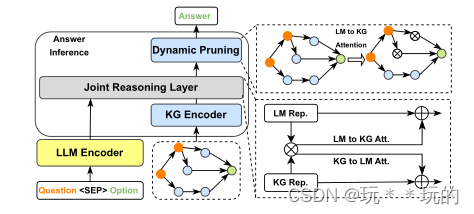
GreaseLM:在大模型的每一层的输入文本令牌和KG实体之间设计了深度和丰富的交互。
大模型增强知识图谱
本部分具体可以划分为以下五个大类,受时间限制,目前只完成感兴趣的部分的阅读,剩下的等有时间再进一步了解。
- 增强知识图谱的嵌入
- 大模型增强知识图谱的合并与补全
- 大模型增强知识图谱的构建
- 大模型增强知识图谱向文本方向的生成
- 大模型增强知识图谱的问答能力
大模型增强知识图谱的构建
传统知识图谱的构建设计到了三个阶段。
- 发现实体
- 共同索引解析
- 实体关系的提取
其可以用下图的关系来描述。

近期,部分工作产生了一些新的角度,包括端到端的知识图谱构建,即一步到位的构建知识图谱,同时还有从大模型中蒸馏出知识图谱等相关的操作。
实体的发掘
定义:从非结构化的数据中识别和提取实体的过程
一般的方法有以下几类
命名实体识别方法(NER)
目前最新的工作通常就是使用大模型的上下文理解能力来准确识别实体和分类。可以将其划分为以下三个模块:
- flat NER:从输入文本中识别不重叠的命名实体,通常被理解为一个序列标记问题。
- nested NER:可以解决多个实体的复杂场景。
- discontinuous NER:解决的是文本中不连续的命名实体的识别问题,使用了大模型。
有一种通用方法,使用了带有指针机制的序列到序列的大模型来生成实体序列,据文章的表述,似乎可以作为上面提到的三类问题的通用解法:https://aclanthology.org/2021.acl-long.451/。
Entity Typing(ET)
ET为上下文中提到的给定实体提供细粒度和超粒度的类型信息。
代表性的工作有:LDET、BOX4Types、MLMET、DFET、LITE等。
Entity Link(EL)
将文本中出现的实体提及与其在知识图谱中对应的实体链接起来。
目前的工作有:GENRE、ELQ、ReFinED等,计划有时间可以进一步阅读了解ReFinED(https://aclanthology.org/2022.naacl-industry.24/https://aclanthology.org/2022.naacl-industry.24/)。
Coreference Resolution(同一实体解析)
基于单个文本的
目前本部分的工作似乎主要都是基于BERT的。
可以参考的重点工作有:SpanBERT、CorefBERT
P.S. 利用双线性函数来计算提及和先行分数,似乎可以减少对跨度级表示的依赖,这个主要是解决基于大模型的解决方案遇到的巨大内存占用的问题。(https://aclanthology.org/2021.acl-short.3/、https://aclanthology.org/2021.findings-acl.343/)
跨文档的解决方案
目前的工作主要有:CDML、Longformer、CrossCR、CR-RL。
关系的抽取
关系的抽取可以从规模的角度对其进行简单的划分,主要可以划分为句子级别的关系的抽取和对于文档级别的关系抽取。
句子级别的工作:BERT-MTB、Curriculum-RE、RECENT。
文档级别的工作:本部分的工作主要是基于大模型的了(曾经主要基于BiLSTM),具体有HIN、GLRE、SIRE、LSR、GAIN、DocuNet、DREAM、ATLOP。
端到端的构建方法
参考工作:
Grapher: 利用大模型生成知识图谱的实体,然后是一个简单的关系构建头,从而能够从文本描述高效地构建知识图谱
Multi-stage knowledge graph construction using pretrained language models(NeurIPS)
PiVE:迭代框架,用小模型纠正大模型的知识图谱生成中的错误。
Pive: Prompting with iterative verification improving graph-based generative capability of llms。
从大模型中蒸馏出知识图谱
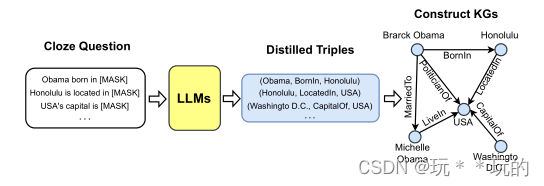
背景:大模型已经被证明可以隐式的编码海量的知识,所以相当多的工作旨在从大模型中提取知识来构建知识图谱。
与本人目前工作关系不大,待有时间再补充。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









