







大模型的到来,让越来越多的系统工程师,能够接触在之前难以想象的集群规模尺度上解决复杂的、最前沿的工程问题,且能产生巨大的经济成本和时间成本收益。
不过,让人感慨的是随着 GPT 使用 Transformer 结构去规模化大模型后,随着集群规模的扩展,对于 AI 系统的要求越来越高,可是很多人没办法很好地区分 AI 系统与 AI Infra 之间的关系,因此本文除了重点介绍大模型遇到 AI 系统所带来的挑战,看 AI 系统遇到大模型后的改变,还会去分析 AI 系统与 AI Infra 之间的区别。
大模型介绍
大模型发展历程
从参数规模上看,AI 大模型先后经历了预训练模型(Pre Training)、大规模预训练模型、超大规模预训练模型三个阶段,每年网络模型的参数规模以 10 倍级以上进行提升,参数量实现了从亿级到百万亿级的突破。截止到 2024 年为止,千亿级参数规模的大模型成为主流。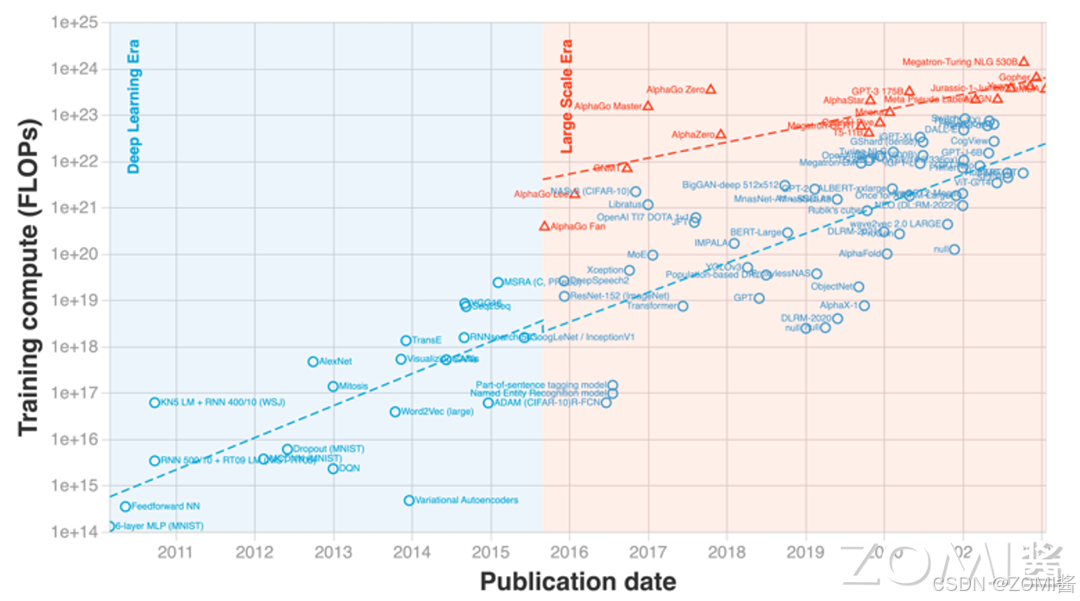
从技术架构上看,如图所示 Transformer 架构是当前大模型领域主流的算法架构基础,由此形成了 GPT 和 BERT 两条主要的技术路线,其中 BERT 最有名的落地课程是谷歌的 AlphaGo。在 GPT3.0 发布后,GPT 逐渐成为大模型的主流路线。综合来看,当前几乎所有参数规模超过千亿的大型语言模型都采取 GPT 模式,如国外有 Grok、Gaulde,国内有百度文心一言,阿里发布的通义千问等。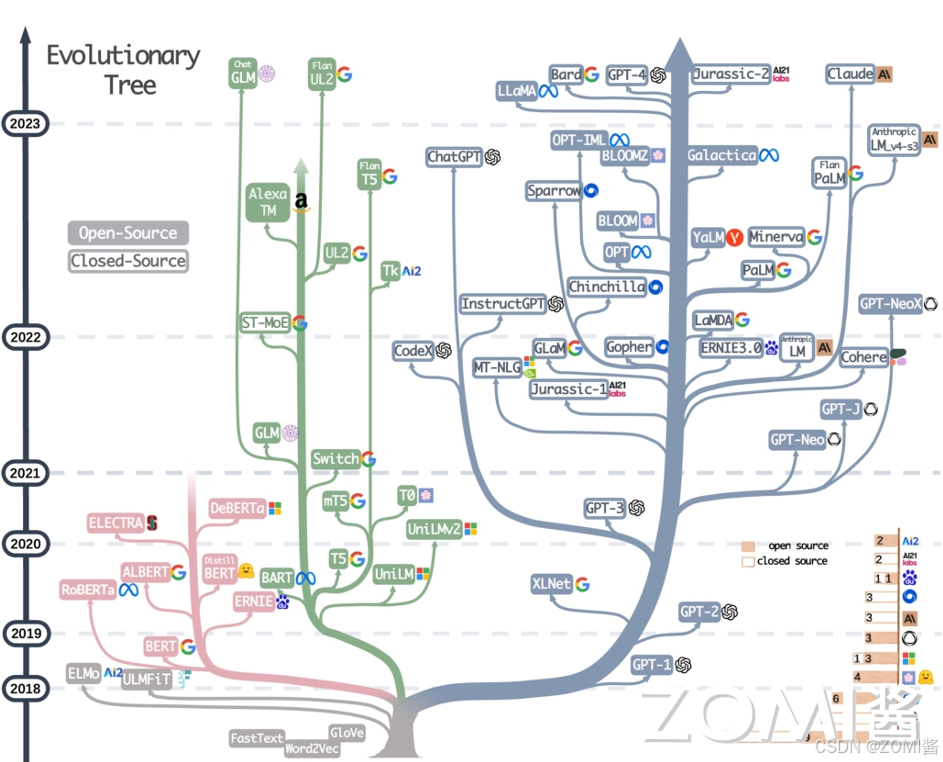
从大模型的支持模态上看,AI 大模型可分为大语言模型(Large Language Model,缩写 LLM),视觉大模型(Large Vision Model,缩写 LVM)、多模态大模型(Large Multimodal Model,缩写 LMM)、图网络大模型(Large Graph Model,缩写 GLM)、科学计算大模型(Large Science Model,缩写 LSM)等。AI 大模型支持的模态呈现丰富化发展、更加多样,从支持文本、图片、图像、语音单一模态下的单一任务,逐渐发展为文生图、文生视频、图解析文字等支持混合多种模态下的多种任务。
从应用领域上看,大模型可分为 L0、L1、L2 三层。其中 L0 层面是通用基础大模型,涉及到 LLM、LVM、LMM、GLM 等等,通用大模型是具有强大泛化能力,可在不进行微调或少量微调的情况下完成多场景任务,相当于 AI 完成了“通识教育”,ChatGPT、华为盘古都是通用大模型;L1 是构建在 L0 基础上面向行业进行训练的行业大模型(包含政务、金融、制造、矿山、铁路等行业),行业大模型利用行业知识对大模型进行微调,让 AI 完成“专业教育”,以满足在能源、金融、制造、传媒等不同领域的具体需求,如金融领域的 BloombergGPT、航天-百度文心等;而 L2 层则是面是面向一些具体细分行业,通过工作流等从 L1 行业大模型中抽取的符合场景需求,进行针对具体的行业数据机型微调后,使模型处于更加细分领域的场景中应用。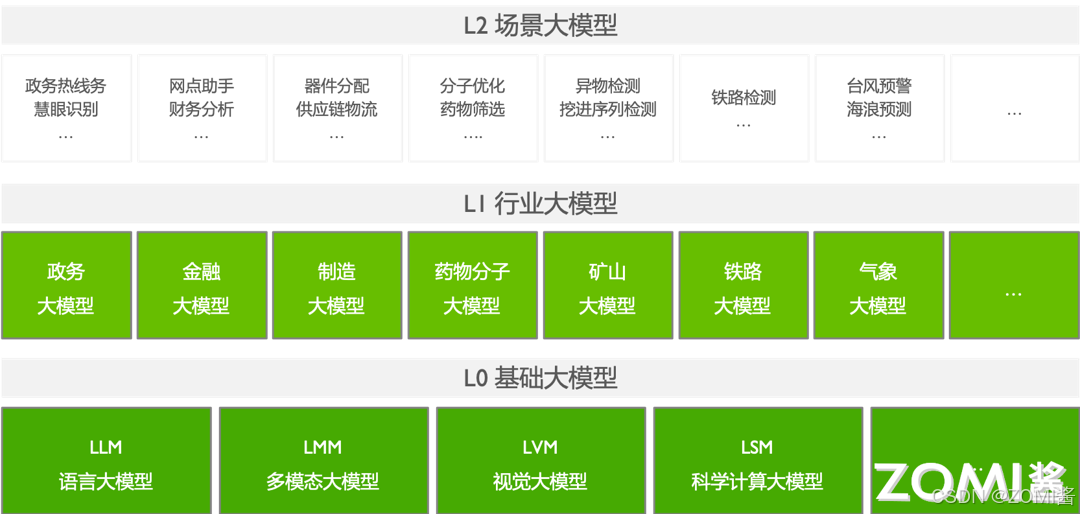
当前,AI 大模型的发展正从以不同模态数据为基础过渡到与知识、可解释性、学习理论等方面相结合,呈现出全面发力、多点开花的新格局。
大模型发展阶段
AI 大模型发展历经三个阶段,分别是萌芽期、探索期和爆发期,其中萌芽期主要是指传统神经网络模型的发展历程和阶段,以小模型为技术主导。
- 萌芽期(1950-2005)
以 CNN 为代表的传统神经网络模型阶段。1956 年,从计算机专家约翰·麦卡锡提出“人工智能”概念开始,AI 发展由最开始基于小规模专家知识逐步发展为基于机器学习。1980 年,卷积神经网络的雏形 CNN 诞生。1998 年,现代卷积神经网络 CNN 的基本结构 LeNet-5 诞生,机器学习方法由早期基于浅层机器学习的模型,变为了基于深度学习的模型。
在萌芽期阶段,小模型的研究为自然语言生成、计算机视觉等领域的深入研究奠定了基础,对后续 AI 框架的迭代及大模型发展具有开创性的意义。此时在自然语言处理 NLP 的模型研究都是在研究基于给定的数据集,在特定的下游任务,如何设计网络模型结构、调整超参、提升训练技巧可以达到更高的任务分数,因此出现了 Word2vec、RNN、LSTM、GRU 等各种 NLP 模型结构。
- 探索期(2006-2019)
以 Transformer 为代表的全新神经网络模型阶段。2013 年,自然语言处理模型 Word2Vec 诞生,首次提出将单词转换为向量的“词向量模型”,以便计算机更好地理解和处理文本数据。2014 年,GAN(对抗式生成网络)诞生,标志着深度学习进入了生成模型研究的新阶段。2017 年,谷歌颠覆性地提出了基于自注意力机制的神经网络结构 Transformer 架构,奠定了大模型预训练算法架构的基础。
2018 年,OpenAI 和谷歌分别发布了 GPT-1 与 BER
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









