







计算图的调度与执行
在前面的内容介绍过,深度学习的训练过程主要分为以下三个部分:1)前向计算、2)计算损失、3)更新权重参数。在训练神经网络时,前向传播和反向传播相互依赖。对于前向传播,沿着依赖的方向遍历计算图并计算其路径上的所有变量。然后将这些用于反向传播,其中计算顺序与计算图的相反。
基于计算图的 AI 框架中,训练的过程阶段中,会统一表示为由基础算子构成的计算图,算子属于计算图中的一个节点,由具体的后端硬件进行高效执行。
目前 AI 框架的前端负责给开发者提供对应的 API,通过统一表示把开发者编写的 Python 代码表示为前向计算图,AI 框架会根据前向计算图图,自动补全反向计算图,生成出完整的计算图。神经网络模型的整体训练流程,则对应了计算图的数据流动的执行过程。算子的调度根据计算图描述的数据依赖关系,确定算子的执行顺序,由运行时系统调度计算图中的节点到设备上执行。
实际上,计算图的执行方式,可以分为两种模式:1)逐算子下发执行的交互式方式,如 PyTroch 框架;2)以及整个计算图或者部分子图一次性下发到硬件进行执行,如 TensorFlow 和 MindSpore。无论采用哪种模式,其大致架构如下所示。
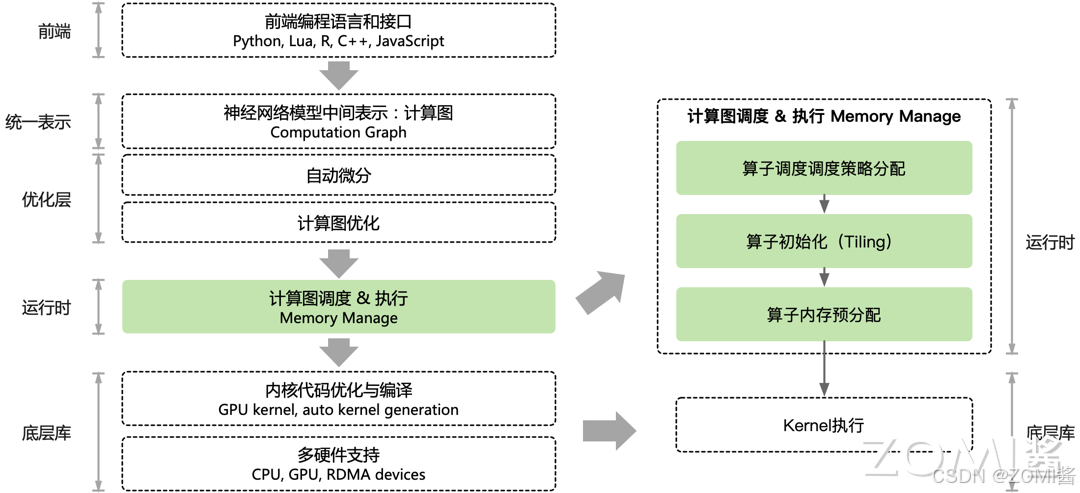
图调度
计算图的调度主要是指静态图。在静态图中,需要先定义好整个计算流,再次运行的时就不需要重新构建计算图,因此其性能更加高效。之所以性能会更高效,是因为会对计算图中的算子的执行序列进行调度优化。
什么是算子
AI 框架中对张量计算的种类有很多,比如加法、乘法、矩阵相乘、矩阵转置等,这些计算被称为算子(Operator),它们是 AI 框架的核心组件。为了更加方便的描述计算图中的算子,现在来对算子这一概念进行定义:
-
狭义的算子(Kernel):对张量 Tensor 执行的基本操作集合,包括四则运算,数学函数,甚至是对张量元数据的修改,如维度压缩(Squeeze),维度修改(reshape)等。
-
广义的算子(Function):AI 框架中对算子模块的具体实现,涉及到调度模块,Kernel 模块,求导模块以及代码自动生成模块。
我们在后续的内容中会将狭义的算子,统一称之为核(Kernel),在 AI 框架中,使用 C++ 实现层里的算子指的就是这里的 Kernel,而这里的 Kernel 实现并不支持自动梯度计算(Autograd)模块,也不感知微分的概念。
广义的算子我们将其称之为函数或方法(Function),这也是平时经常接触到的 AI 框架中 PyTorch API,包括 Python API 和 C++ API,其配合 PyTorch Autograd 模块后就可以支持自动梯度求导计算。
算子间调度
无论是大模型还是传统的神经网络模型,实际上最后执行都会落在单台设备环境上执行对应的算子。对单设备执行环境,制约计算图中节点调度执行的关键因素是节点之间的数据流依赖和具体的算子。
假设继续以简单的复合函数为例子:
f ( x 1 , x 2 ) = l n ( x 1 ) + x 1 ∗ x 2 − s i n ( x 2 ) f(x_1,x_2)=ln(x_1)+x_1*x_2−sin(x_2)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









