







重点在自注意力机制的image captioning方法上。
现有的Self-Attention方法作者认为存在两个问题:
一个是:Internal Covariate Shift

我的理解就是输入分布不一样
解决办法就是Normalization。
原来的Transformer当中也是有Normalization的,但是作者认为原来的做法不够好:

翻译过来,就是要把norm放到自注意力模块里面
另一个问题是:几何关系信息的缺失
在自然语言里面,可以直接使用代表位置的数字来做,但是二维就比较复杂了。

(小声说一句:作者这样说,不知道没有做实验?后面有答复:相关工作里有一个用坐标信息做的,参考文献【15】)
作者是在原始的权重上,增加了一个代表几何的偏置

看完前面的两点,具体怎么做呢?
首先问题是啥?
怎么加?
不,是往哪里加。
首先是norm加在编码器
而position是在解码器加。
先回顾自注意力:

作者把instance norm加在了q上:

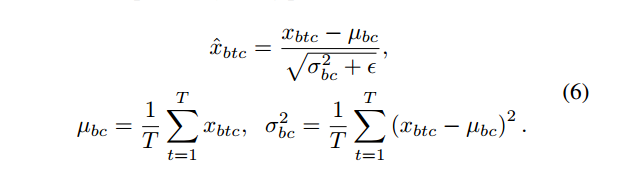
作者坦言:其他地方也试着加过了,效果不好。。。

几何信息的使用主要还是靠坐标:

这个关系定义可以自己定义,这里定义了三种:



实验部分的机器翻译是使用一个公开的工具包做的。
这方面比较感兴趣,我就直接上链接
https://github.com/pytorch/fairseq




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











