






文章目录
- 第一类:
- 第二类:
- 第三类:
- Adversarial Semantic Alignment for Improved Image Captions
- Fast, Diverse and Accurate Image Captioning Guided By Part-of-Speech
- Self-critical n-step Training for Image Captioning
- Pointing Novel Objects in Image Captioning
- Look Back and Predict Forward in Image Captioning
- Exact Adversarial Attack to Image Captioning:via Structured Output Learning with Latent Variables
- Auto-Encoding Scene Graphs for Image Captioning
- Intention Oriented Image Captions with Guiding Objects
- Context and Attribute Grounded Dense Captioning
- Show, Control and Tell: A Framework for Generating Controllable and Grounded Captions
相关博客: cvpr 2018 image caption generation论文导读(含workshop)
2019cvpr image captioning的论文总共16篇左右,其中主要包括三个方向:
第一:就是评价指标;
第二:就是提出新任务,一般都附带一个新的数据库;
第三:就是发现原先captioning当中的的问题,提出一定的解决方案。通过整体阅读,会发现,最后一种当中精度提升都一般,只要选择合适的比较算法,然后讲好自己的故事,就是很优秀的work。下面,我们来简单整体看一下相关论文。
第一类:
Adversarial Semantic Alignment for Improved Image Captions (这篇文章在第三类也会出现,但说问题的角度不同)
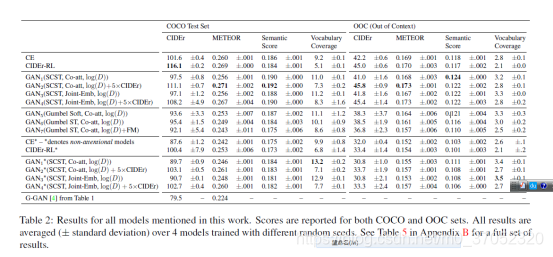
数据库的bias,是这篇文章的重点(具体见第三类第一篇论文,这里重点是评价指标部分)。除了传统的评价指标bleu,CIDEr等。最近有用分类器的做的。作者为了“跨模型评估”提出了叫做semantic score的一个指标,是收到一个叫inception score指标的启发,这个inception score是评价图像生成算法生成图像质量的一个指标。也是利用有监督的标签做一个分类器。具体这里的优势没有讲太多,只是说和人类更符合,因为这篇文章的重点是前面的bias,指标只是顺道提出的。
Semantic score是基于cca(canonical correlation analysis)的。具体操作就是为了暗哨bias,多加了一个im2text的数据库进来,然后直接计算图像和文本的cca.

从下图可以看出,semantic score和meteor还是具有一定一致性的。
Describing like Humans: on Diversity in Image Captioning
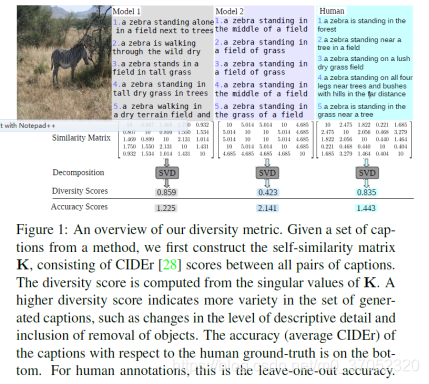
为描述的多样性提出了一个指标,基于SVD做的。
第二类:
Good News, Everyone! Context driven entity-aware captioning for news images
当前的caption任务都是生成一个描述性句子,但是对人类来说,都是带着先验知识来理解描述图片。这里提出了一个新任务,就是给一张新闻图片,给一段新闻,生成一个描述。
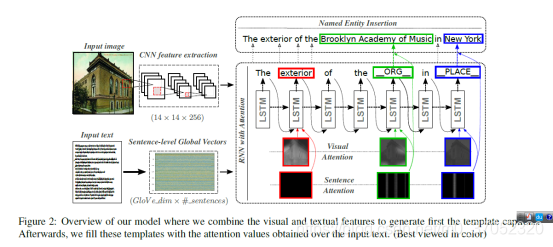
从方法上来看,卷积提取图像特征,Glove提取文本特征,加上attention来用LSTM生成句子。因为有新闻作为先验条件,所以可以生成包含实际地名的句子。
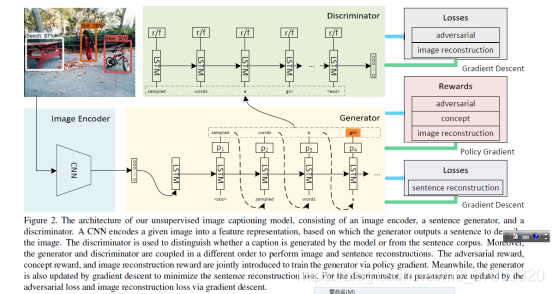
Unsupervised Image Captioning
无监督,重点。作者首先梳理了不同的captioning任务,最后自然的引出了自己的任务,看下面的图。

(a)一个图对应一个句子。(b)重点就是新目标。图像中有训练集没有出现过的东西,生成的时候要想办法包含。©第三个是cross-domain captioning,这个的论文没怎么看过,个人理解在成对的数据上训练完,非成对的要利用类似检索的策略来做?(d)就是利用一个pivot,简单就是目标是生成英文描述,我们利用汉语来作为pivot。先生成汉语描述,然后直接翻译生英语。(e)半监督,部分是成对的。(f)最后就是完全不相关。
虽然任务很惊艳,但是实现的方法很简单,就是先做目标检测。
无监督的大概指标:
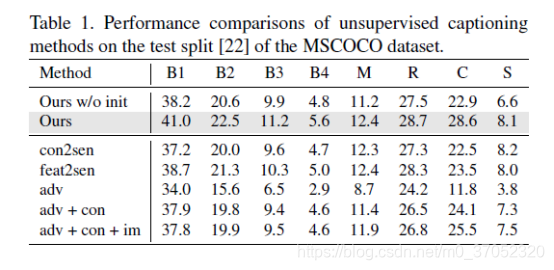
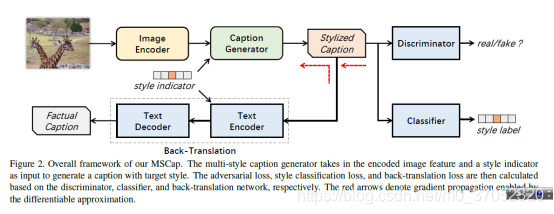
MSCap: Multi-Style Image Captioning with Unpaired Stylized Text
新任务,多个style的。去年有一篇是故事性的。这个工作就是给数据库,方法很简单。
任务如下:

方法如下:
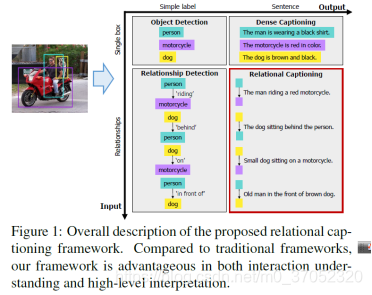
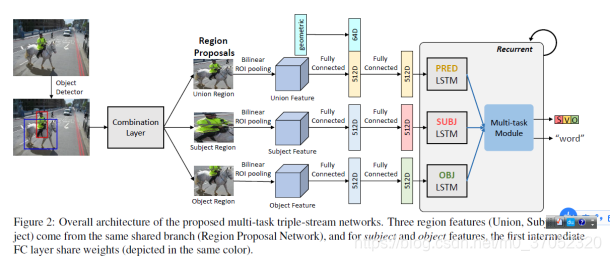
Dense Relational Captioning: Triple-Stream Networks for Relationship-Based Captioning
又是一个新任务,基于关系。简单来说,就是先检测一个关系,在生成句子。一个图可以说明问题:
方法如下:
Engaging Image Captioning via Personality
新任务,带一点个性,具体还是用例子来体会一下:
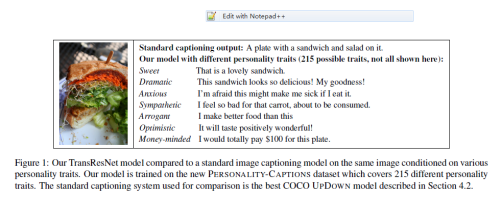
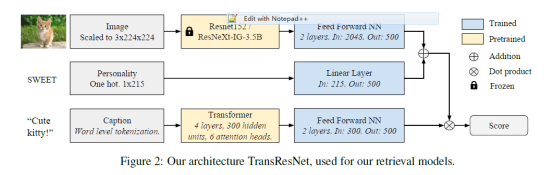
在新数据库上,作者使用了经典的show tell , show attend and tell还有updown来进行生成,但是效果并不好,所以作者提出了一个检索的模型。
第三类:
Adversarial Semantic Alignment for Improved Image Captions
数据库的bias,是这篇文章的重点。因为数据库本身的原因,模型回overfit一些共同出现的目标,比如数据库中全是猫和狗在一起,模型以为他们永远在一起,给一张猫和老虎的照片,模型生成的描述当中,无法识别出并包含老虎,可能还会强行带着狗。这就特别尴尬了。所以作者提出用对抗的思想,有一个带有context识别的生成器和联合注意力机制的判别器来完成这个任务。

因为任务是bias,所以一般的测试集也验证不出来呀,所以作者提出一个新的测试集,在这个测试集里,上面举的例子经常出现(数据库中全是猫和狗在一起,模型以为他们永远在一起,给一张猫和老虎的照片,模型生成的描述当中,无法识别出并包含老虎,可能还会强行带着狗),这样就能看出,到底有没有识别出真正的目标,而不是被强行带bias。
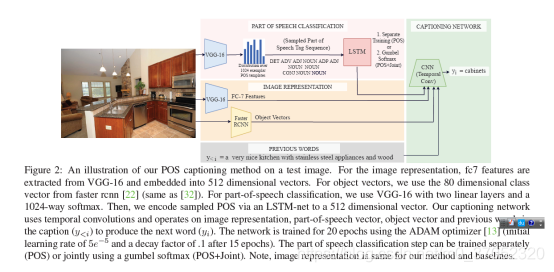
Fast, Diverse and Accurate Image Captioning Guided By Part-of-Speech
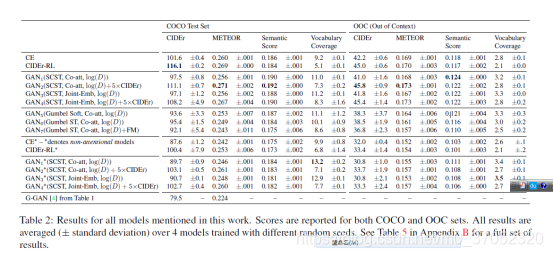
多样性,从名字我们可以看出这个工作的重点。如何做呢?之前用GAN或者VAE做,虽然多样性增加了,但是准确率降低了。本文作者提出可以使用part-of-speech作为桥梁来生成多样性的标注,并且用n-grams的不同来度量多样性,来说明本文方法的优越性。
因为重点是多样性,所以传统的度量指标用的都是相对的,而且绝对精度并不高
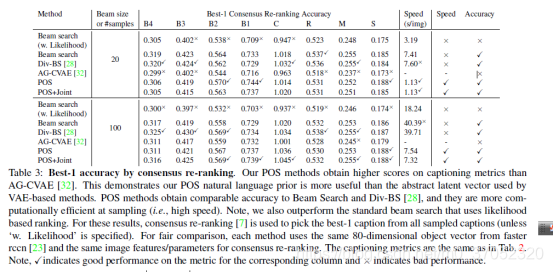
Self-critical n-step Training for Image Captioning
这篇是说怎么训练的。说之前用交叉熵损失函数不合适。这里用了增强学习,增强学习我也不是很了解,文中各种强化学习的公式。所以这个论文。。。。
贴个图感受一下结果吧
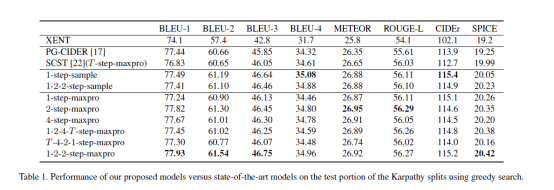
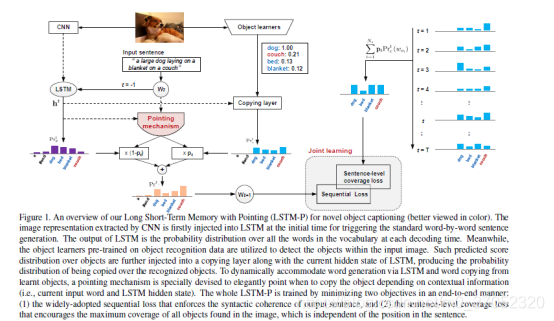
Pointing Novel Objects in Image Captioning
Domain knowledge,应该是这里的重点,我的理解其实就是学一些目标识别,先看下面的例子。

比较本文提出方法(LSTM-P)和普通方法的差异,也就是有没有准确识别出racket和bus。方法如下图,就是提出了一个并行的识别目标的模块,最后在生成单词的时候同时考虑原本的lstm输出和识别目标模块的输出。
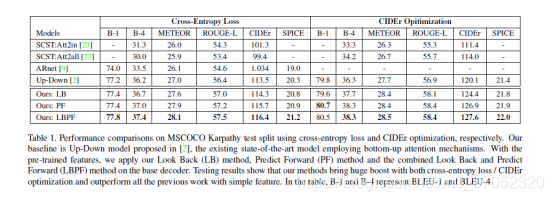
Look Back and Predict Forward in Image Captioning
前后都看看。在预测当前单词的时候,利用前面的视觉特征注意力输出和当前隐藏状态输出做一个注意力,然后往后看就是一下子预测两个单词(这两个单词的LSTM权重共享)。

结果如下图:
Exact Adversarial Attack to Image Captioning:via Structured Output Learning with Latent Variables
这个做对抗攻击的。但是没明白攻击的是哪里。给个例子

左边一列不用说了,是原本的,中间一列,给出半个句子模板,模型往里面填写单词,肯定是错的呀,人类也不可能把一个已经错了的句子填对吧?也可能是我没理解作者的意图。。。
Auto-Encoding Scene Graphs for Image Captioning
利用图卷积引入先验知识克服数据库的bias。分两步,第一步先从S-G-D-S训练一个D。第二步I-G-D-S生成句子。
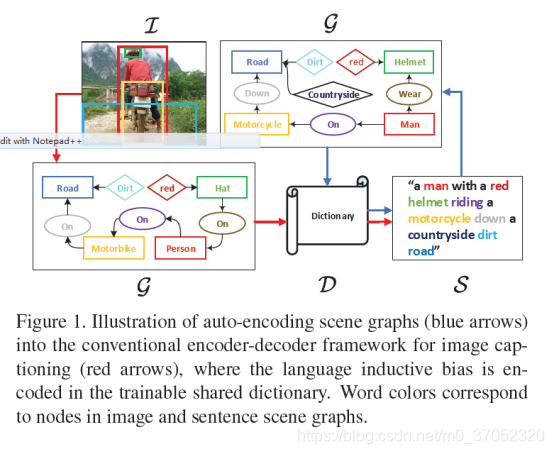
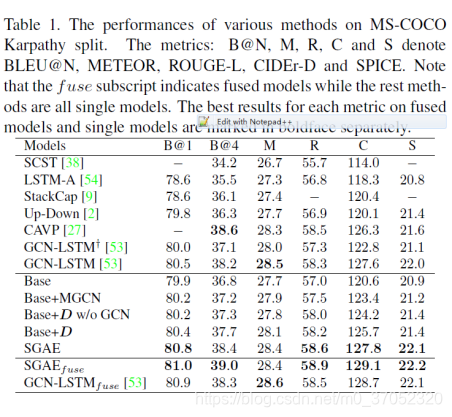
结果相当不错:
Intention Oriented Image Captions with Guiding Objects
清华的这个论文有意思了,不走寻常路:
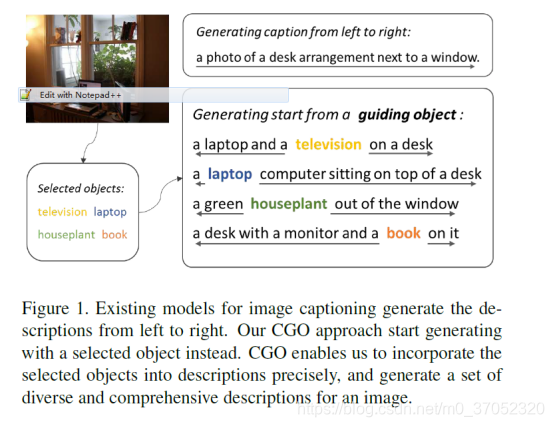
先检测一个名词,然后左右生成,有了这个思路,方法也就不难想了:

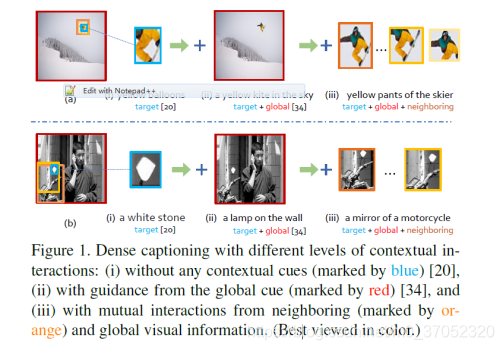
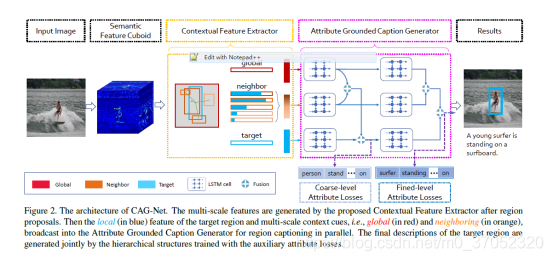
Context and Attribute Grounded Dense Captioning
做Dense captioning(已经不是一般意义的image captioning了,扫一眼就行)的时候,需要考虑最终bounding box的上下文信息,如下图
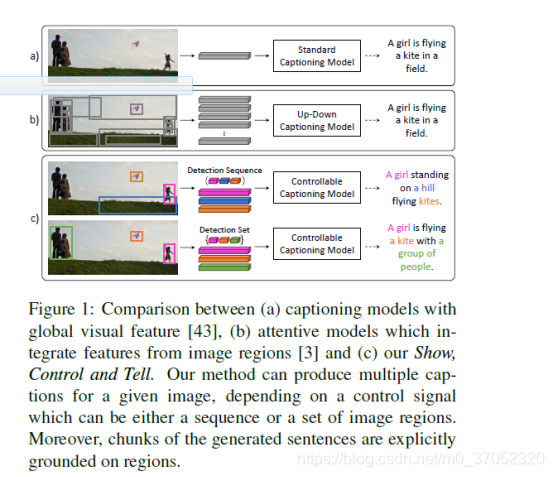
Show, Control and Tell: A Framework for Generating Controllable and Grounded Captions
有名的题目,show tell系列,这里增加了控制因素,这里的控制信号是image region的一个set或者sequence,因为这个控制信号其实相当于提供了各位的信息,所以效果提升的很大。
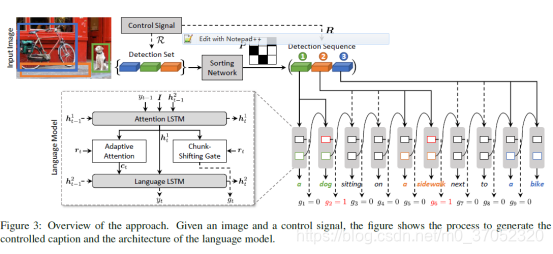
方法框图如下:
很厉害的结果提升:



















 8549
8549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











