







汝之观览,吾之幸也!本文章主要统计大数据方面的名词概念,不至于一上来就看到那么多技术名词晕头转向。随时更新
一、Linux
Linux是一个操作系统,是在Unix基础上进行开发的。
Linux的是林纳斯·本纳第克特·托瓦兹(Linus Benedict Torvalds)在大学期间在Unix做了磁盘驱动与文件系统,这些就成为了Linxu的内核。如果在内核上基础上加了软件,就会成为Linux的发行版,比如RedHat、CentOs、Deppin-基于Linux的开源国产操作系统等

虚拟机
虚拟机(Virtual Machine)指通过软件模拟的具有完整硬件系统功能的,运行在一个完全隔离环境中的完整计算机系统。
一般虚拟机就是指操作系统。
Vmware
是一款虚拟机软件,兼容性强,快照功能便捷,方便,允许你在任意开机时刻创建系统快照和恢复。其他的虚拟机软件(VirtualBox)
二、大数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RY3BgOjh-1663046838268)(https://jimmy-blog-images.oss-cn-shanghai.aliyuncs.com/img/bigdata/hadoop%E7%94%9F%E6%80%81%E5%9C%88.png)]
常见的数据单位
| 1Byte(字节)=8bit(比特) | 1K(千)=1024Byte | 1M(兆)=1024K | 1G(千兆)=1024M |
|---|---|---|---|
| 1T(太)=1024G | 1P(拍)=1024T | 1E(艾)=1024P | 1Z(泽)=1024E |
| 1Y(尧)=1024Z | 1B(布)=1024Y | 1N(诺)=1024B | 1D(刀)=1024N |
一般我们了解的只到TB级别,再往上的数据我们怎么处理,这就引申出大数据的概念。
大数据(Big Data),是值无法在一定时间范围内用常规工具进行捕捉、管理和处理的数据集合。是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据主要解决的问题:海量数据的存储和海量数据的计算问题
Hadoop
是Apache基金会开发的分布式系统基础架构。广泛的概念是Hadoop生态圈。
Google的三篇论文:
GFS --> HDFS :分布式框架
Map Reduce -->MR:分布式计算
BigTable -->HBase:分布式数据库

Hive
由Facebook开源用于解决海量结构化日志的数据统计工具。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将HQL转化成MapReduce程序,不做存储与计算。存储还是在HDFS,计算还是用MapReduce。

HBase
HBase是一个分布式的、面向列的开源数据库,适合于非结构化数据存储的数据库。

Impala
用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。 它是一个用C ++和Java编写的开源软件。 与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。
Impala是性能最高的SQL引擎(提供类似RDBMS的体验),它提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。

Spark
是专为大规模数据处理而设计的快速通用的计算引擎
首先,高级 API 剥离了对集群本身的关注,Spark 应用开发者可以专注于应用所要做的计算本身。
其次,Spark 很快,支持交互式计算和复杂算法。
最后,Spark 是一个通用引擎,可用它来完成各种各样的运算,包括 SQL 查询、文本处理、机器学习等,而在 Spark 出现之前,我们一般需要学习各种各样的引擎来分别处理这些需求。
ClickHouse
是俄罗斯的 Yandex 于 2016 年开源的用于在线分析处理查询(OLAP :Online Analytical Processing)MPP架构的列式存储数据库(DBMS:Database Management System),能够使用 SQL 查询实时生成分析数据报告。ClickHouse的全称是Click Stream,Data WareHouse。

Kafka
是一种高吞吐量的分布式发布订阅消息系统

Redis
是一个key-value存储系统,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。

CDH
Cloudera Hadoop发行版(Cloudera’s Distribution Including Apache Hadoop,简称CDH),
Cloudera提供一个可伸缩,稳定的,综合的企业级大数据管理平台,它拥有最多的部署案例,提供强大的部署,管理和监控工具。
Hue
是一款开源的可界面化配置调度、运行代码或管理集群文件系统的工具。

Oozie
是一个基于工作流引擎的开源框架,是由Cloudera公司贡献给Apache的,它能够提供对Hadoop MapReduce和Pig Jobs的任务调度与协调。

三、数据仓库
ETL(Extract-Transform-Load)
数据仓库技术,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
主流ETL工具
Kettle
是目前最为流行的一款开源etl工具之一,被Pentaho公司收购后正式更名为Pentaho Data Integration,但在中国,最为业内大众所熟知的还是“Kettle”。
Talend
是第一家针对数据集成工具市场的ETL开源软件供应商。Talend以它的技术和商业双重模式为ETL服务提供了一个全新的远景。

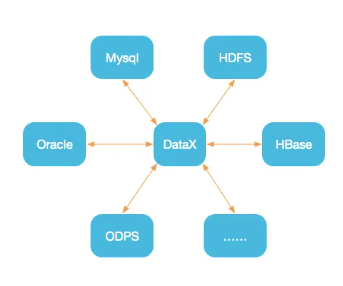
DataX
是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。
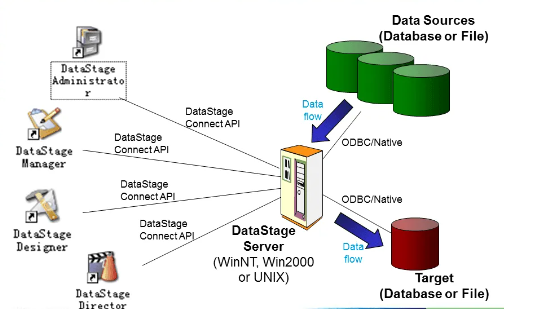
DataStage
是IBM旗下的一款十分强大的ETL工具。
支持对数据结构从简单到高度复杂的大量数据进行收集、变换以及分发操作,且管理到达的数据以及定期或按调度接收的数据。
分层
ODS(Operational Data Store,操作数据层)
把操作系统数据几乎无处理的存放在数据仓库系统中。
- 实现功能:该层为数据接入源层,业务源系统数据接入到此层,此层数据不做任何加工,禁止重复进入
- 数据来源范围:业务源系统
- 数据存储时长:根据业务需求状况
CDM(Common Data Model,通用数据模型层/数据中间层)
主要完成公共数据加工与整合,建立一致性的维度,构建可复用面向分析和统计的明细事实表以及汇总事实表。
DIM(Dimension,公共维度层)
是CDM层中的公共维度层,基于维度建模理论,建设企业一致性公共维度数据。
- 实现功能:该层为公共维表层,该层独立于dwd、dws、ads,为dwd、dws、ads提供维度字段说明。
- 数据来源范围:ods、人工录入
- 数据存储时长:根据业务需求状况
DWD(Data Warehouse Detail Model,明细宽表层)
是CDM层中的明细宽表层,用于存放完整详细历史数据。
- 实现功能:该层为融合数据层,主要对分来源基础数据进行数据整合。该层数据可以对应用开放。用于解决数据融合的问题。
- 数据来源范围:此层数据来源于分来源基础数据表
- 数据存储时长:根据业务需求保留
DWS(Data Warehouse Subject,数据汇总层)
是CDM层中存放详细历史数据的公共汇总数据层,面向分析主题建模。
- 实现功能:该层为宽表数据层,主要根据多个基础数据层表,整合应用需要的指标宽表。为全局抽象的业务实体及汇总型事实表
- 数据来源范围:dwd
- 数据存储时长:根据业务需求状况
ADS(Application Data Service,应用数据层)
提供直接面向业务或应用的数据,主要对个性化指标数据进行架构处理,如无公用性或复杂性(如指数型、比值型、排名型等指标数据)的指标数据加工。
- 实现功能:该层为应用数据层,根据业务需求组织数据,该层支持百花齐放、尽可能都依赖dws,特殊情况可依赖dwd的数据,该层定期需要定期review,将公共指标沉淀到dws中
- 数据来源范围:dws、dwd
- 数据存储时长:根据业务需求状况
EVL(Evaluation,数据评价层)
- 实现功能:该层为数据评价层,该层独立与ods、dwd、dws,对其他层进行数据的检测和评价
- 数据来源:其他各层
- 存储时长:根据业务需求情况
分域
- 业务域有用户数据和业务数据,比如用户的消费习惯、终端信息、ARPU的分组、业务内容,业务受众人群等
- 操作域有网络数据,比如信令、告警、故障、网络资源等
- 运动域有位置信息,比如对象的流动轨迹、地图信息等
数据实体
实体是指现实世界中客观存在的并可以相互区分的对象或事物。就数据库而言,实体往往指某类事物的集合。可以是具体的人事物,也可以是抽象的概念、联系。
账期
年、月、日、周、时、分、秒、实时、历史
编码规则
表名的编码规则:
ods_[业务单位]_<源系统简写>_<源系统表名>
dwd_<数据域>_<数据内容描述> _[数据周期]
dws_<数据域>_<数据粒度>_<表内容描述>_[数据周期]
ads_<应用名称>_<数据内容描述>_[数据周期]
dim_<数据内容描述>
evl_<主题域>_<数据内容描述>
数据目录
是层、域的关系合集展示
四、其他
C/S、B/S
C/S : Client/Server , 客户端/服务器。传统的桌面级的应用程序,基于客户端的应用。
B/S : Browser/Server , 浏览器/服务器。web应用程序,基于浏览器的应用
区别:
[1] 语言:
C/S: c,c++,
B/S:java,php,.Net,js,nodeJs
[2] 更新:
C/S: 下载新版本的客户端,升级不大方便。
B/S:热更新,永远都是最新的。
[3] 数据通信:
C/S: 基于自定义的应用层协议
B/S:基于http协议,基于http的服务器拿来就能用,nginx,apache,微软的IIS这些
[4] 跨平台:
C/S:开发时可能需要考虑跨平台问题(不同操作系统下)
B/S:开发时跨平台方便,毕竟每个平台都有浏览器
[5] 数据处理:
C/S: 支持离线,数据可以本地保存或处理.
B/S: 支持云端,数据保存在云端,随时随地联网就能访问















 5221
5221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









