







CSV格式
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。通常都是纯文本文件。建议使用WORDPAD或是记事本(NOTE)来开启,再则先另存新档后用EXCEL开启,也是方法之一
csv格式存储: csv文件格式是一种通用的电子表格和数据库导入导出格式。
1:西安邮电:西安:90
1,西安邮电,西安,90
# 读取csv文件
import csv
with open('some.csv', 'rb') as f: # 采用b的方式处理可以省去很多问题
reader = csv.reader(f)
for row in reader:
# do something with row, such as row[0],row[1]
import csv
with open('some.csv', 'wb') as f: # 采用b的方式处理可以省去很多问题
writer = csv.writer(f)
writer.writerows(someiterable)
测试
import csv
with open('doc/example.csv', 'w') as f:
writer = csv.writer(f)
# 将列表的每条数据依次写入csv文件, 并以逗号分隔
writer.writerows([['1', '2', '3'], ['4', '5', '6']])
with open('doc/example.csv', 'r') as f:
reader = csv.reader(f)
for row in reader:
print(row)
生成的文件可用excel打开
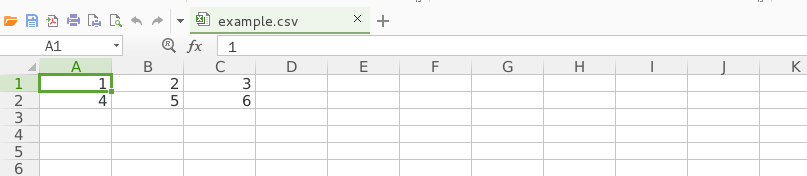
案例-中国大学排名爬取
import requests
from bs4 import BeautifulSoup
import bs4
def get_content(url,):
try:
user_agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36"
response = requests.get(url, headers={'User-Agent': user_agent})
response.raise_for_status() # 如果返回的状态码不是200, 则抛出异常;
response.encoding = response.apparent_encoding # 判断网页的编码格式, 便于respons.text知道如何解码;
except Exception as e:
print("爬取错误")
else:
print(response.url)
print("爬取成功!")
return response.content
def getUnivList(html):
"""解析页面内容, 需要获取: 学校排名, 学校名称, 省份, 总分"""
soup = BeautifulSoup(html, 'lxml')
# 该页面只有一个表格, 也只有一个tbody标签;
# 获取tbosy里面的所有子标签, 返回的是生成器: soup.find('tbody').children
# 获取tbosy里面的所有子标签, 返回的是列表: soup.find('tbody').contents
uList = []
for tr in soup.find('tbody').children:
# 有可能没有内容, 获取的tr标签不存在, 判断是否为标签对象?
if isinstance(tr, bs4.element.Tag):
# print(tr.td)
# 返回tr里面的所有td标签;
tds = tr('td')
# print(tds)
# 将每个学校信息以元组的方式存储到列表变量uList中;
uList.append((tds[0].string, tds[1].string, tds[2].string, tds[3].string))
return uList
def printUnivList(uList):
"""
打印学校信息
:param uList:
:return:
"""
# format的 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3779
3779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









