






网上大神们的文章都很长很详细,看完了自己总结一点点。先来一张图

1. 浏览器会解析三个东西:一般页面里面都含有HTML,CSS,JS脚本
- HTML----> 解析生成DOM Tree,它是一个倒着的树,跟节点是HTML,然后下一级并列这head和body
- CSS ------> 解析CSS会产生一个叫做CSS规则树的东西 CSS Rule Tree
- JS -----> 通过DOM API和CSSOM API 来操作DOM Tree和CSS Rule Tree
2. 解析完成后,浏览器通过dom tree 和css rule tree 来构造rendering tree
- 渲染树并不是DOM树,像header和display:none的东西没必要放在渲染树中
- css rule tree 为了完成匹配并把css rule 附加到渲染树的每个dom element上
- 计算每个element的位置,被称为layout(布局)和reflow过程
3. 最后通过调用操作系统的Native GUI的API来绘制,呈现给用户
一个性能问题: 关于CSS 选择器的写法,CSS匹配DOM tree主要是从右到左解析CSS的selector,和我们的书写方式不太一样,
例如 div p {...} ,匹配的时候会先在html找到所有的p标签,然后再找和这个相关的div标签,所以大神们都说,dom树要小,css尽量用id和class,不要过度层叠下去
通过dom tree和css rule tree 会生成一个叫style context tree
(1) firefox的方式:通过css生成css rule tree,通过比对dom生成style context tree,然后把style context tree 和rendering tree关联上,就完成了
(2)webkit和firefox 不同,webkit有style对象,它直接把这个style对象存在了相应的dom节点上
渲染
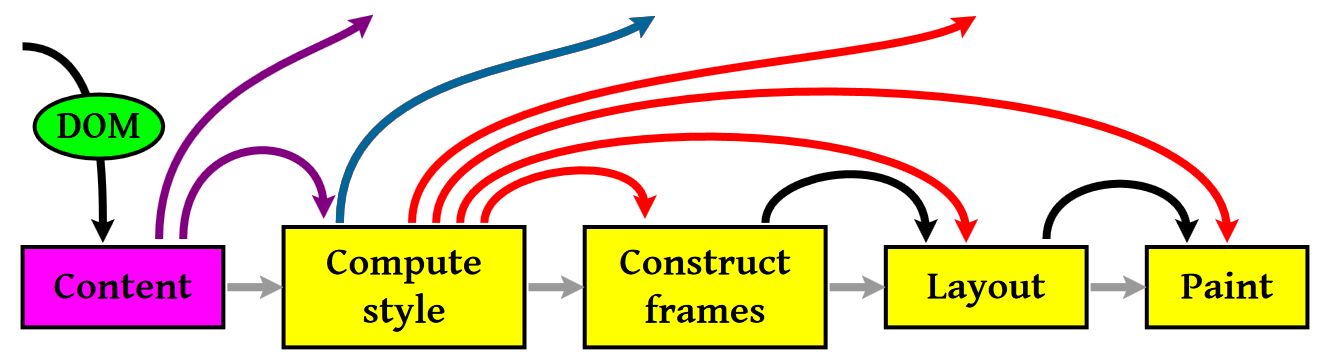
四个步骤:
- 计算css样式
- 构建render tree
- layout - 定位坐标和大小,是否换行,各种position,overflow,z-index。。。
- paint
图中那些指向空中的箭头表示由于js动态改变了dom属性或者css属性导致重新layout,有些改变不会。
以上内容基本都来自这篇文章
http://www.iteye.com/news/27795















 1440
1440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









