






卷友们好,我是rumor。
做了三年多的问答,我对这个领域真是又恨又爱。恨吧,互联网里的问答产品就是个锦上添花的东西,而且效果还上不去,一堆case等着我解。爱吧,我们NLP可是人工智能的掌上明珠,而问答又是NLP的尽头,多么fancy的任务啊。

还是选择相信吧。
今天带大家一起学习丹琦女神和Scott大佬在ACL2020上主讲的Tutorial——Open-Domain Question Answering。开放域问答之所以重要,是因为它是搜索引擎的终极形态。而搜索引擎的重要性就不必多说了,需求量大,商业模式成熟,以搜索引擎为入口的应用养活了谷歌、百度和一系列垂搜大厂,占据了当今互联网的大半壁江山。要是掌握了这门技术,前途不可估量。
PPT&视频:https://github.com/danqi/acl2020-openqa-tutorial
丹琦女神这次的Tutorial,主要讲的是利用非结构化数据进行问答这一分支任务,也是当今场景最多的任务,毕竟结构化、半结构化数据有一定的获取成本。
从开放域问答兴起以来,可以分为以下四个阶段:
Pipeline:类似搜索引擎,分为Query理解、候选召回和答案抽取
Two-stage:对Pipeline进行简化,先用Retriever抽取候选,然后用Reader做阅读理解
End-to-end learning:用神经网络替换传统Retriever,尝试把Retriever和Reader一起训练
Retrieval-free models:不检索了,预训练都学会了,直接上模型就完了
下面我们就跟着女神的步伐,来看看这四类方法。
Pipeline
QA的研究从1960年左右就开始了,基本都是rule-based的方法,学者们通过大量人工定义的规则来进行query理解,然后从限定域数据库中寻找答案(那时的学者们可能不会知道,这种方法一直被沿用至今)。
1999年,信息检索领域的顶会TREC推出了QA Tracks,那时他们就开始意识到,搜索引擎的下一个形态就是问答。然而那时由于机器学习、算力的局限,主流方法还是跟搜索引擎类似,数据集也比较简单,都是用单实体作为答案(长了就抽不出来了)。
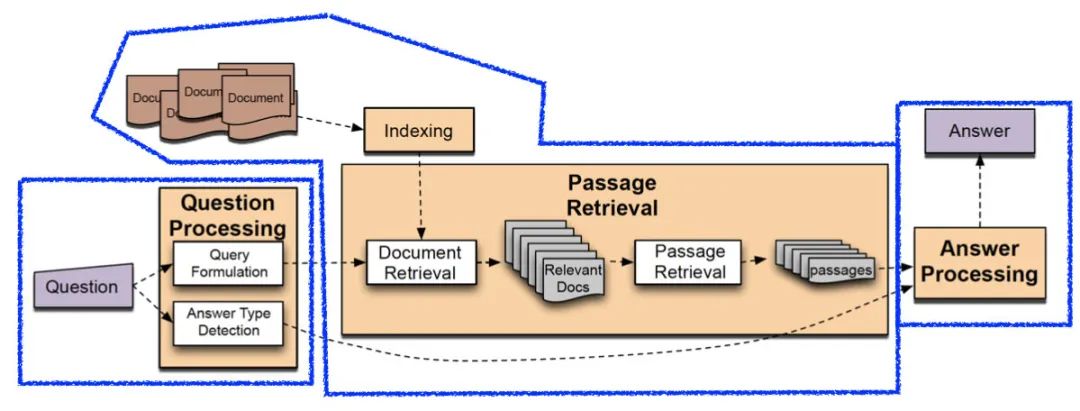
可以看2002年的冠军方案来体会一下Pipeline方法的复杂程度:
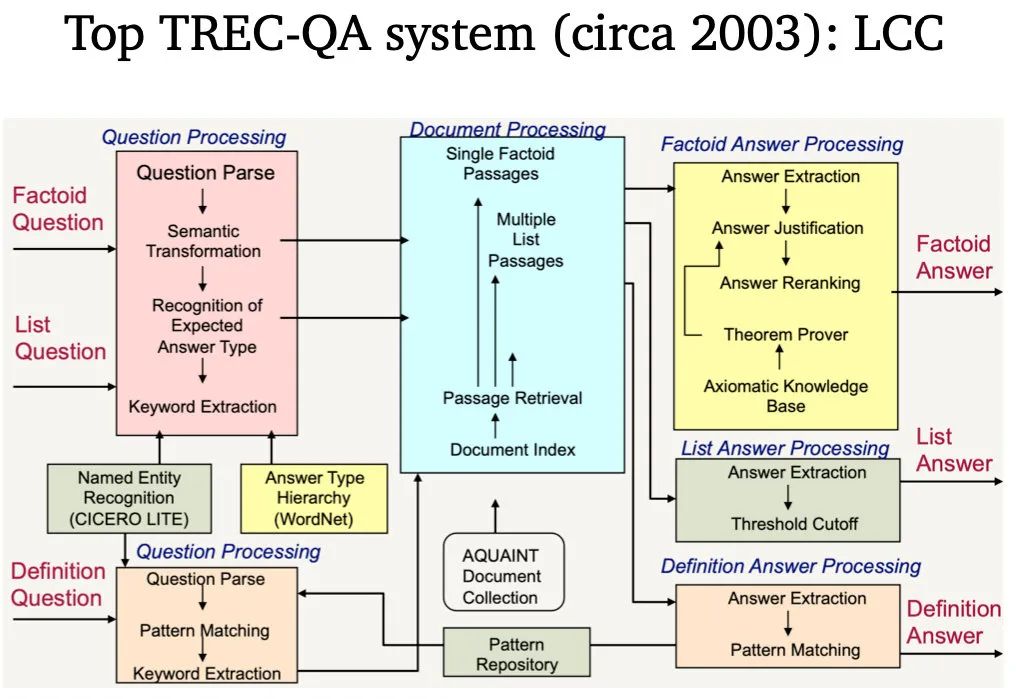
再之后,就是2011年,IBM Watson一举夺得Jeopardy问答竞赛的百万奖金。然而技术上还是没有太大进展,依旧是用Pipeline方法,任务形式也较为简单。
到了2013年,深度学习兴起,任务形式也开始发生变化,从Document层面的Macro-reading走向Passage层面的Micro-reading。出现了更偏向语义的阅读理解任务。以及更多形式的数据集:

Two-Stage
把问答整合成阅读理解任务的形式后,研究者们把Pipeline简化为了Retriever-Reader两步。最基本的解决方案可以参照2017年的DrQA,用TFIDF、BM25等同级方法召回合适的Document,再用神经网络作为Reader去标注合适的回答。
那接下来如何优化呢?除了把Reader替换为更复杂的网络外,还有几个点可以改进:
DrQA是从文档层面进行召回的,因此2019年的BERTserini[1]把文档切成segments,进行更精细的召回,同时用segment和答案片段的加权分数作为最终答案
在预测时,不同段落中抽出的答案不方便做比较,因此2018[2]、19[3]年分别有工作尝试了Multi-passage训练,让一个batch内的段落进行交互,得到一个更好的span预测结果
段落的重要性被忽略掉了,所以2018年的R^3[4]给召回的passage又加了一个强化学习的re-ranker
目前的方法只对答案进行排序,而忽略了聚合,如果不同passage都抽出了同样的答案,可以用不同的方法进行汇总[5]
开放域阅读理解的训练集很多都是远程监督来做的(只要passage包含答案就是正例),这样会忽略passage本身的合理性,也有工作探索这方面的改进[6]
Dense Retriever and End-to-end
上文介绍了Pipeline方法的改进思路,然而Retriever还处于远古时代。技术再往前一步,就是对Retriever进行优化。
事实上,在2019年之前,dense retriever的表现都弱于sparse retriever(例如用TFIDF表示的one-hot)。Retriever网络需要从成百上千万的文档中选出合适的,需要大量的语料和算力,终于到BERT出来之后,我们有了预训练模型+Faiss向量化召回框架,才终于让dense retriever的效果上去。
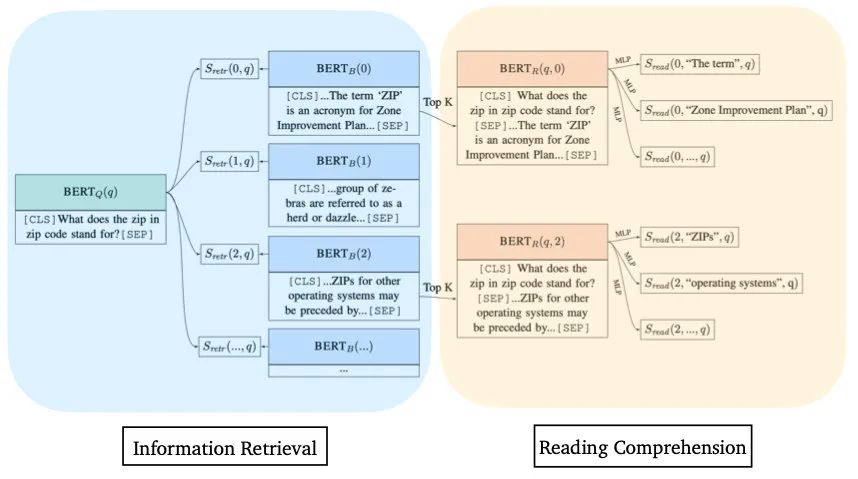
2019年的ORQA[7]提出了Inverse Cloze Task任务,通过预测一句话正确的Context对Retriever进行预训练,之后再对Retriever和Reader进行联合训练,终于在3个数据集上打败了传统的BM25+BERT。
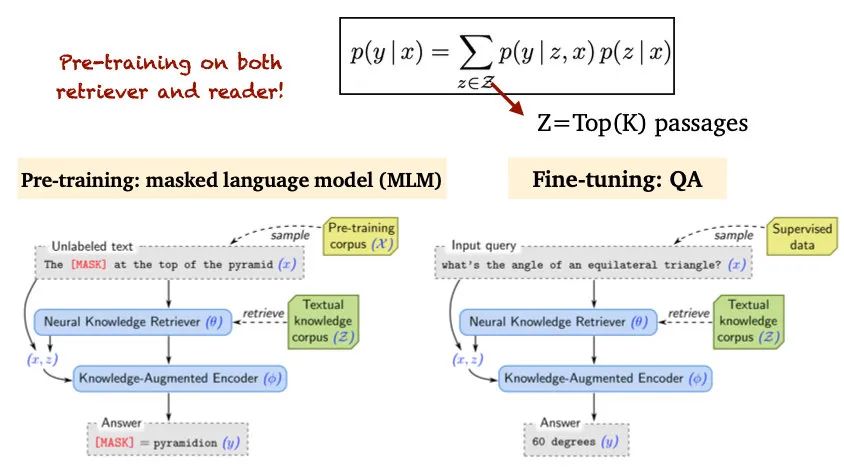
2020年的REALM[8]则更进一步,提出了让Retriever和Reader更好结合的MLM预训练任务。具体的做法是,随机对句子的实体进行mask,作为query,让Retriever从候选中抽取句子,再让Reader根据query和候选预测被mask的实体:
但上述两种方法都需要进行预训练,这个成本是很高的。
接下来,2020年的DPR[9]提出,可以用更少的语料来训一个Retriever。那问题就来了,用什么数据训Retriever才好呢?DPR采用的正例是:
阅读理解数据集的正例
包含answer的BM25高分段落
而负例则采用:
随机段落
不包含答案的高分BM25段落
其他问题的正例段落
同时在训练时采用In-batch negative策略,相比REALM提升了2个多点。同时又证实了Pipeline方法的高效性。
优化了半天Retriever,那Reader层面还有什么优化呢?能不能用生成模型?
2020年的RAG[10]就用DPR Retriever+BART模型来了一版生成式开放域QA:
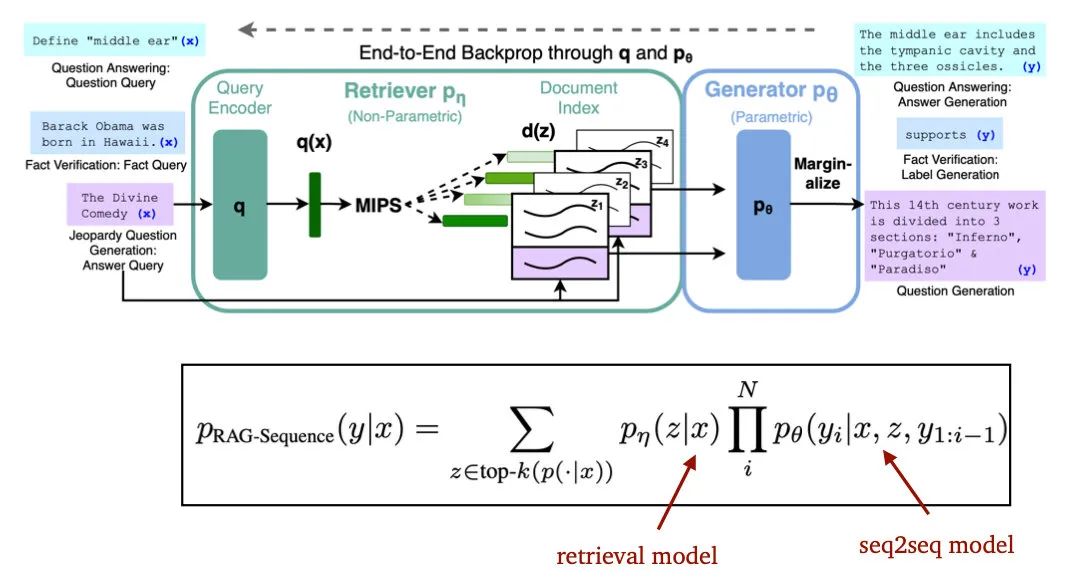
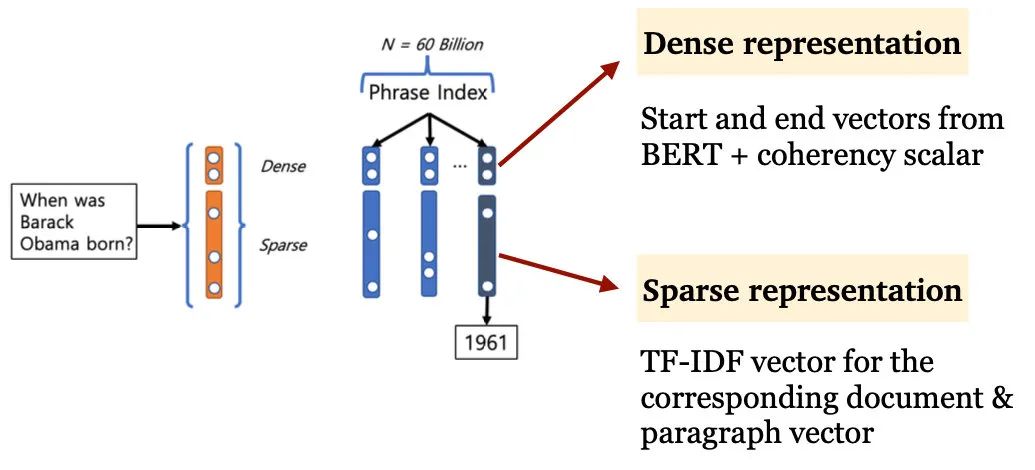
不过讲了半天,上面方法本质还是Two-stage的,2019年的DenSPI[11]就想,能不能phrase level进行召回,那要是都召回phrase了,reader是不是就可以省了?
说干就干,于是DenSPI把phrase都切出来了,一方面用BERT的start和end表示作为dense表示,一方面用TF-IDF做sparse表示,两个表示拼接起来,居然效果还不错,在SQuAD上能超越一些Two-stage的方法。
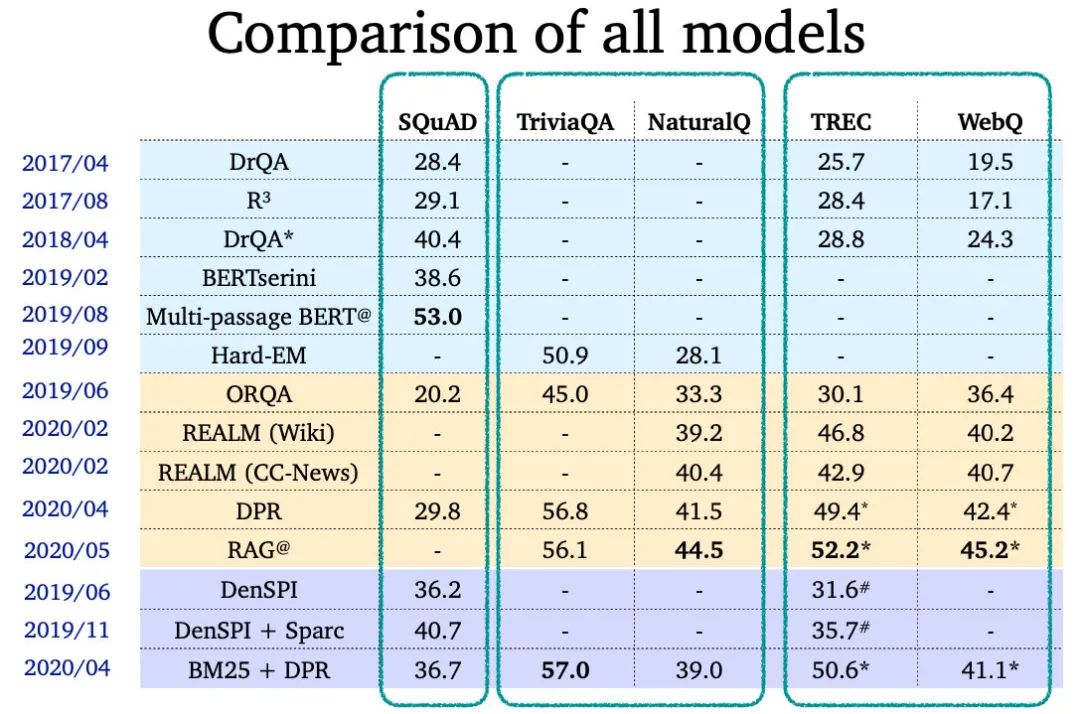
最后,让我们来看看女神总结的各模型表现:
Retriever-free
开放域问答的尽头,难道是预训练大模型?
然而女神的报告是2020年做的,只介绍了GPT-2和T5,从效果上看,预训练大模型是可以得到不错的效果的,然而这个效果跟模型尺寸强相关,11B的T5刚刚能赶上3个BERT-base的DPR效果。
数据集与评估

评估方式主要有:F1、Exact match、Top-N accuracy等
总结
问答是搜索引擎的尽头吗?我不知道,但我相信未来几十年之后,随着互联网的信息越来越多,人机交互的形式一定会发生变化。而其中最重要的技术,除了NLP可能就是脑机接口了。
希望我35岁危机之前问答技术能有一波大突破,please。

参考资料
[1]
End-to-End Open-Domain Question Answering with BERTserini: https://arxiv.org/abs/1902.01718
[2]Simple and Effective Multi-Paragraph Reading Comprehension: https://arxiv.org/abs/1710.10723v1
[3]Multi-passage BERT: A Globally Normalized BERT Model for Open-domain Question Answering: https://aclanthology.org/D19-1599/
[4]Reinforced Ranker-Reader for Open-Domain Question Answering: https://arxiv.org/abs/1709.00023
[5]Evidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering: https://arxiv.org/abs/1711.05116
[6]A Discrete Hard EM Approach for Weakly Supervised Question Answering: https://arxiv.org/abs/1909.04849
[7]Latent Retrieval for Weakly Supervised Open Domain Question Answering: https://arxiv.org/abs/1906.00300
[8]REALM: Retrieval-Augmented Language Model Pre-Training: https://kentonl.com/pub/gltpc.2020.pdf
[9]Dense Passage Retrieval for Open-Domain Question Answering: https://aclanthology.org/2020.emnlp-main.550.pdf
[10]Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks: https://arxiv.org/abs/2005.11401
[11]Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index: https://aclanthology.org/P19-1436.pdf
欢迎对NLP感兴趣的朋友加入我们的「NLP卷王养成」群,一起学习讨论~
扫码添加微信备注「NLP」即可⬇️


大家好我是rumor
一个热爱技术,有一点点幽默的妹子
欢迎关注我
带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「为NLP的进步干杯」















 2026
2026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









