







存在原因
Hadoop处理少量大文件时效率较高,但处理大量小文件是效率较低,因此设计了以下两种文件模式容器用于将大量小文件组织起来统一存储。
SequenceFile文件
文件的基本格式。
- 文件的基本格式是一种键值对文件记录。
- 文件的键、值对所代表的类必须支持序列化及反序列化
- Hadoop预定义了一些class,他们已经直接或间接实现了Writable接口(序列化接口)。例如:
Text等同于Java中的StringIntWritable等同于Java中的IntBooleanWritable等同于Java中的Boolean
文件存储结构
在存储结构上,SequenceFile主要由一个Header后跟多条Record组成,如图所示:
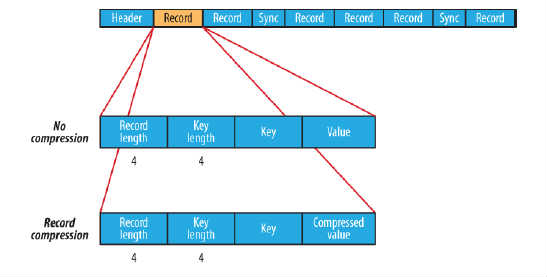
- Header主要包含了Key classname,Value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。
- 每条Record以键值对的方式进行存储,用来表示它的字符数组可依次解析成:记录的长度、Key的长度、Key值和Value值,并且Value值的结构取决于该记录是否被压缩。
- 同步标记位于顺序文件记录与记录之间,用于在读取文件时能够从任意位置开始识别记录边界。
- 该文件有两种压缩方式:record compression和block
- record compression通过图中很明显可以看出,文件压缩是仅压缩值,未压缩键,压缩单条数据。
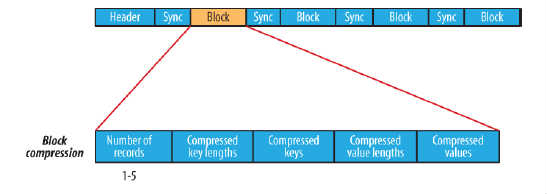
- block compression指块压缩,是将一连串的record组织到一起,统一压缩成一个block,block信息主要存储了:块所包含的记录数、所包含的Key的长度、所包含的Key值的集合、所包含的Value长度,所包含的Value值的集合.如图所示:···
文件写入
createWriter()静态方法创建SequenceFile对象,并返回SequenceFile.Writer实例- 通过
SequenceFile.Writer实例的append()在文件末尾追加键值对。 - 通过调用
close()方法关闭文件,其实现了java.io.Closeable接口。
package chapter5;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import java.io.IOException;
import org.apache.hadoop.io.SequenceFile.Writer;
public class SequenceFileWrite {
private static final String[] data = {
"Hello, this is Hadoop",
"End, this is sequenceFile write demon"
};
public static void main(String[] args) throws IOException {
String output = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path(output);
if (fs.exists(path)) {
fs.delete(path, true);
}
IntWritable key = new IntWritable();
Text value = new Text();
Writer write = null;
try {
// Hadoop权威指南第4版代码,该方法已过时
// writer = SequenceFile.createWriter(fs, conf, path, key.getClass(), value.getClass());
// 新API写法,使用注释掉的语法时报错,原因未知
// Writer.Option fileOption = Writer.file(path);
// Writer.Option keyOption = Writer.keyClass(key.getClass());
// Writer.Option valueOption = Writer.keyClass(value.getClass());
// write = SequenceFile.createWriter(conf, fileOption, keyOption, valueOption);
write = SequenceFile.createWriter(conf,Writer.file(path), Writer.keyClass(IntWritable.class), Writer.valueClass(Text.class));
for (int i = 0; i < 100; i++) {
key.set(100-i);
value.set(data[i%data.length]);
System.out.printf("[%s]\t%s\t%s\n", write.getLength(), key, value);
write.append(key, value);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
IOUtils.closeStream(write);
}
}
}
// STDOUT
[128] 100 Hello, this is Hadoop
[168] 99 End, this is sequenceFile write demon
[224] 98 Hello, this is Hadoop
[264] 97 End, this is sequenceFile write demon
[320] 96 Hello, this is Hadoop
[360] 95 End, this is sequenceFile write demon
[416] 94 Hello, this is Hadoop
[456] 93 End, this is sequenceFile write demon
[512] 92 Hello, this is Hadoop
[552] 91 End, this is sequenceFile write demon
[608] 90 Hello, this is Hadoop
[648] 89 End, this is sequenceFile write demon
[704] 88 Hello, this is Hadoop
[744] 87 End, this is sequenceFile write demon
[800] 86 Hello, this is Hadoop
---
[4680] 6 Hello, this is Hadoop
[4720] 5 End, this is sequenceFile write demon
[4776] 4 Hello, this is Hadoop
[4816] 3 End, this is sequenceFile write demon
[4872] 2 Hello, this is Hadoop
[4912] 1 End, this is sequenceFile write demon
文件读入
package chapter5;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.IOException;
public class SequenceFileReader {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
SequenceFile.Reader reader = null;
Path path = new Path(uri);
try {
// 旧版API写法
// reader = new SequenceFile.Reader(fs, path, conf);
// 新版API写法
reader = new SequenceFile.Reader(conf, SequenceFile.Reader.file(path));
Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
// 标记出同步点位置
String syncSecc = reader.syncSeen() ? "*" : "-";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSecc, key, value);
position = reader.getPosition();
}
} finally {
IOUtils.closeStream(reader);
}
}
}
// STDOUT
[ochadoop@server7 artifacts]$ hadoop chapter5.SequenceFileReader /zpy/bigdata/chapter5/number.seq
18/11/02 11:09:32 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
18/11/02 11:09:32 INFO compress.CodecPool: Got brand-new decompressor [.deflate]
[128-] 100 Hello, this is Hadoop
[168-] 99 End, this is sequenceFile write demon
[224-] 98 Hello, this is Hadoop
[264-] 97 End, this is sequenceFile write demon
[320-] 96 Hello, this is Hadoop
[360-] 95 End, this is sequenceFile write demon
[416-] 94 Hello, this is Hadoop
---
[4028-] 19 End, this is sequenceFile write demon
[4084*] 18 Hello, this is Hadoop
[4144-] 17 End, this is sequenceFile write demon
[4200-] 16 Hello, this is Hadoop
[4240-] 15 End, this is sequenceFile write demon
[4296-] 14 Hello, this is Hadoop
[4336-] 13 End, this is sequenceFile write demon
[4392-] 12 Hello, this is Hadoop
[4432-] 11 End, this is sequenceFile write demon
[4488-] 10 Hello, this is Hadoop
[4528-] 9 End, this is sequenceFile write demon
[4584-] 8 Hello, this is Hadoop
[4624-] 7 End, this is sequenceFile write demon
[4680-] 6 Hello, this is Hadoop
[4720-] 5 End, this is sequenceFile write demon
[4776-] 4 Hello, this is Hadoop
[4816-] 3 End, this is sequenceFile write demon
[4872-] 2 Hello, this is Hadoop
[4912-] 1 End, this is sequenceFile write demon
命令行查看文件
格式:hadoop fs -text (File PATH)
eg: hadoop fs -text /zpy/bigdata/chapter5/number.seq
同步点操作
Reader对象
- 调用
Reader的seek(long position),将指针指向文件中指定位置。该方法给定的位置不是同步点时,调用next()方法会报错。 - 调用
Reader的sync(long position),将指针指向文件中指定位置。该方法会将位置指向文件当前位置的下一个同步点,若无下一个同步点,则指向文件尾。
Writer对象
调用Writer的sync(),将在文件当前位置插入一个同步点,请区别于hsync,后者用于文件底层IO
更详细链接
https://blog.csdn.net/qianshangding0708/article/details/47666735















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









