







CSDN话题挑战赛第2期
参赛话题:学习笔记
文章目录
前言
- 一把锋利的刀在庖丁手里是游刃有余的,而在普通人手中可能会反伤自身。
- C语言就像一把锋利的刀,总是容易伤到那些不能掌握它的人。若你曾经被它伤害过或者认为自己还没完全掌握它的人,就请跟着本文学习如何避开“C语言伤害粗心的人”的方法吧。
简介
学完本文,你将会获得哪些收获?具体如下:
第一部分:研究了当程序被划分为记号时会发生的问题。
第二部分:继续研究了当程序的记号被编译器组合为声明、表达式和语句时会出现的问题。
第三部分:研究了由多个部分组成、分别编译并绑定到一起的 C 程序。
第四部分:处理了概念上的误解:当一个程序具体执行时会发生的事情。
第五部分:研究了我们的程序和它们所使用的常用库之间的关系。
第六部分:我们注意到了我们所写的程序也不并不是我们所运行的程序;预处理器将首先运行。
第七部分:讨论了可移植性问题:一个能在一个实现中运行的程序无法在另一个实现中运行的原因。
第一部分:词法缺陷
- 编译器常被称为词法分析器(lexical analyzer)。词法分析器检查组成程序的字符序列,并将它们划分为记号(token),一个记号是一个又一个或多个字符的序列,它在语言被编译时具有一个(相关地)统一的意义。
- C 程序编译时被两次划分为记号。首先是预处理器读取程序,它必须对程序进行记号划分以发现标识宏的标识符,然后通过对每个宏进行求值来替换宏调用。最后,经过宏替换的程序又被汇集成字符流送给编译器,编译器再第二次将这个流划分为记号。
- 在这一节中,我们将探索对记号意义的普遍误解,以及记号和组成它们的字符之间的关系。稍后我们将谈到预处理器。
1. 1 = 不是 ==
- C 语言则是用 = 表示赋值,而用 == 表示比较。这是因为“赋值”的频率要高于"比较",因此为其分配更短的符号。
- C 将赋值视为一个运算符,可以很容易地写出多重赋值(如 a = b = c),并且可以将赋值嵌入到一个大的表达式中。这种便捷潜在一个风险:可能会将
“比较” 写成了 “赋值”。举例说明:
(1)下面语句想要检查 x 是否等于 y, 却写成了将 y 赋值给 x 并检查结果是否非零:
当你需要先对一个变量进行赋值之后再检查变量是否非零时,应考虑显式给出比较符。改写为:if (x = y) { foo(); }
(2)下面是一个希望跳过空格、制表符和换行符的循环:if (0 != (x = y)) { foo(); }
在与 ‘\t’ 比较时不小心使用 = 代替了 ==。这个“比较”实际上是将 ‘\t’ 赋给 c,然后判断 c 的(新的)值是否为零。因为 ‘\t’ 不为零,这个“比较”将一直为真,因此这个循环会吃尽整个文件。若程序没有读取超过文件尾部的部分,那么这个循环将会一直运行。为了养成好的编写习惯,应改写为:while (c == ' ' || c = '\t' || c == '\n') { c = getc(f); }while (' ' == c || '\t' == c || '\n' == c) { c = getc(f); }
1.2 多字符记号
- 一些 C 记号,如 /、* 和 = 都只有一个字符。而其他一些 C 记号,如 /* 和 ==,以及标识符,具有多个字符。那么我们就来谈谈 C 记号会给我们带来哪些麻烦,以及如何规避它吧。
- 下面的语句看起来像是将 y 的值设置为 x 除以 p 指针所指向的值:
实际上,/* 是开始了一个注释,因此编译器简单地吞噬程序文本,直到 */ 的出现。换句话说,这条语句仅仅把 y 值设置为 x 值,而根本没有看到 p。应重写为:y = x/*py = x / *p; 或者 y = x / (*p) - 这种模棱两可的写法在其他环境中就会引起麻烦。例如,老版本的 C 使用 =+ 表示现在版本中的 +=。这样的编译器会将:
这会让原本打算写成如下语句的程序员感到吃惊:a=-1; 被视为 a =- 1; 或者 a = a - 1;a = -1; - 另外,这种老版本的 C 编译器会将
尽管 /* 看起来像一个注释。a=/*b; 断句为:a =/ *b;所以说,平时编写代码时 ”等式两边“ 要养成留空格的习惯。
1.3 多字符记号一些例外说明
- 组合赋值运算符如 += 实际上是两个记号。因此,
是一个意思。看起来像一个单独的记号而实际上是多个记号的只有这一个特例。a + /* strange */ = 1 和 a += 1 - 特别地,如下写法是不合法的:
它和如下的写法是不同义词的。p - > ap -> a //p -> a 等同 p->a - 另外,有些老式编译器还是将 =+ 视为一个单独的记号并且和 += 是同义词。
1.4 字符串和字符
- 单引号和双引号在 C 中的意义完全不同,在一些混乱的上下文中它们会导致奇怪的结果而不是错误消息。
- 在单引号中的一个字符只是整数的另一种书写方法。这个整数是给定的字符在实现的对照序列中的一个对应的值。因此,在一个 ASCII 实现中,'a’和 0141 或 97 表示完全相同的东西。
- 在双引号中的字符串,只是一个有字符和一个附加的二进制值为零的字符所初始化的一个无名数组的指针的一种简短书写方法。
- 下面的两个程序片断是等价的:
printf("Hello world\n");char hello[] = { 'H', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '\n', 0 }; printf("%s", hello); - 使用一个指针来代替一个整数通常会得到一个警告消息(反之亦然),使用双引号来代替单引号也会
得到一个警告消息(反之亦然)。但对于不检查参数类型的编译器却除外。因此,用
来代替printf('\n');
通常会在运行时得到奇怪的结果。printf("\n");
这是由于一个整数通常足够大,以至于能够放下多个字符,一些 C 编译器允许在一个字符常量中存放多个字符。这意味着用'yes'代替"yes"将不会被发现。前者意味着“在一些定义中表示由字符 y、e、s 联合构成的一个整数”,而后者意味着“分别包含 y、e、s 和一个空字符的四个连续存贮器区域中的第一个的地址”。这两者之间的任何一致性都纯属巧合。
第二部分:句法缺陷
- 要理解 C 语言程序,仅了解构成它的记号是不够的。还要理解这些记号是如何构成声明、表达式、语
句和程序的。尽管这些构成通常都是定义良好的,但这些定义有时候是有悖于直觉的或混乱的。 - 在这一节中,我们将着眼于一些不明显句法构造。
2.1 理解声明
-
如何理解硬件调用地址为0处的子程序:
(*(void(*)())0)(); -
看到这样的表达式一定会令 C 程序员心惊胆战。不过没关系,在此之前我们可以先来理解声明的表达式。
-
每个 C 变量声明都具有两个部分:一个类型和一组具有特定格式的期望用来对该类型求值的表达式。
-
最简单的表达式就是一个变量:
int f, g;说明表达式 f 和 g,在求值时具有类型 int。由于待求值的是表达式,因此可以自由的使用圆括号:
int ((f)); -
同样的逻辑在函数和指针类型也适用。例如:
int func();表示 func 是一个返回值为 int 的函数。类似地:
int *pf;表示 *pf 是一个指向 int 类型的指针。这些形式的组合声明对表达式是一样的。因此,
int *g(), (*h)();表示 *g(), (*h)() 都是 int 类型的表达式。由于 () 比 * 绑定的更紧密,*g() 和 *(g()) 表示同样的东西:g 是一个返回 int 指针的函数,而 h 是一个指向返回 int 函数的指针。
通过以上的例子,我们知道了如何声明一个给定类型的变量以后,就能够很容易地写出一个类型的模型(cast):只要删除变量名和分号,并将所有的东西包围在一对圆括号中即可。例如:int *g();声明 g 是一个返回 int 指针的函数,所以
(int *()) 就是它的模型。 -
有了以上知识的武装,我们现在就可以准备解决
(*(void(*)())0)()了。 我们可以将它分为两个部分进行分析。 -
首先,假设我们有一个指针变量 fp,并且我们希望调用 fp 所指向的函数。可以这样写:
(*fp)();如果 fp 是一个指向函数的指针,则 *fp 就是函数本身,而 (*fp)() 是一个 void 值,因此它的声明是这样的:
void (*fp)(); -
接着我们进行第二步分析,假如我们找到一个适当的表达式来替换 fp,并且 C 可以读入并理解这种类型,那么可以写:
(*0)()但这样并不行,因为
* 运算符要求必须有一个指针作为它的操作数,而且这个操作数必须是一个指向函数的指针,以保证 * 的结果可以被调用。因此,我们需要将 0 转换为一个可以描述“指向一个返回 void 函数的指针”的类型。通过 void (*fp)() 的声明,我们就知道了它的模型,只要从变量的声明中去掉名字即可:
void(*)(); -
因此,我们可以这样将 0 转换为一个“指向返回 void 函数的指针”:
(void(*)())0最后,我们用 (void(*)())0 替换 fp 即可:
(*(void(*)())0)();
2.2 运算符并不总是具有你所想象的优先级
-
假设有一个声明了的常量 FLAG 是一个整数,其二进制表示中的某一位被置位(换句话说,它是 2 的某次幂),并且你希望测试一个整型变量 flags 该位是否被置位。通常的写法是:
if(flags & FLAG) ...其意义对于很多 C 程序员都是很明确的:if 语句测试括号中的表达式求值的结果是否为 0。为了更清晰的表达语句的目的可以这样写:
if(flags & FLAG != 0) ...现在这个语句更容易理解了。但它的表达是错的,因为 != 比 & 绑定得更紧密,因此它被分析为:
if(flags & (FLAG != 0)) ...不过有一个例外是可以的。如 FLAG 是 1 或 0 的时候,对于它的 2 次幂是无效的【因为 != 的结果不是 1 就是 0】。
-
假设你有两个整型变量,h 和 l,它们的值在 0 和 15(含 0 和 15)之间,并且你希望将 r 设置为 8 位值,其低位为 l,高位为 h。一种自然的写法是:
r = h << 4 + 1;不幸的是,这是错误的。“加法” 比 "移位"绑定得更紧密,因此这个例子等价于:
r = h << (4 + l);正确的方法有两种:
r = (h << 4) + l;r = h << 4 | l;避免这种问题的一个方法是将所有的东西都用括号括起来,但表达式中的括号过度就会难以理解,因此最好还是记住 C 中的优先级。
-
可是C语言运算符优先级有 15 个级别,太困难了。然而,通过将它们分组可以变得容易:
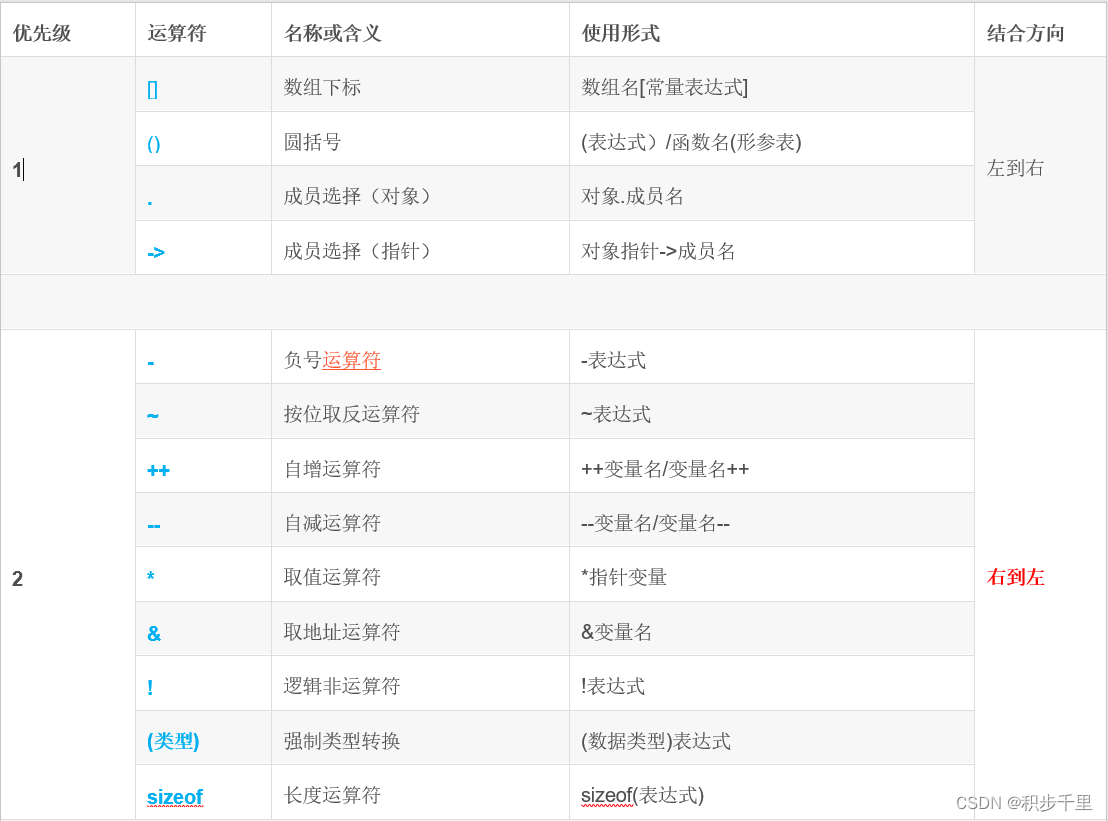
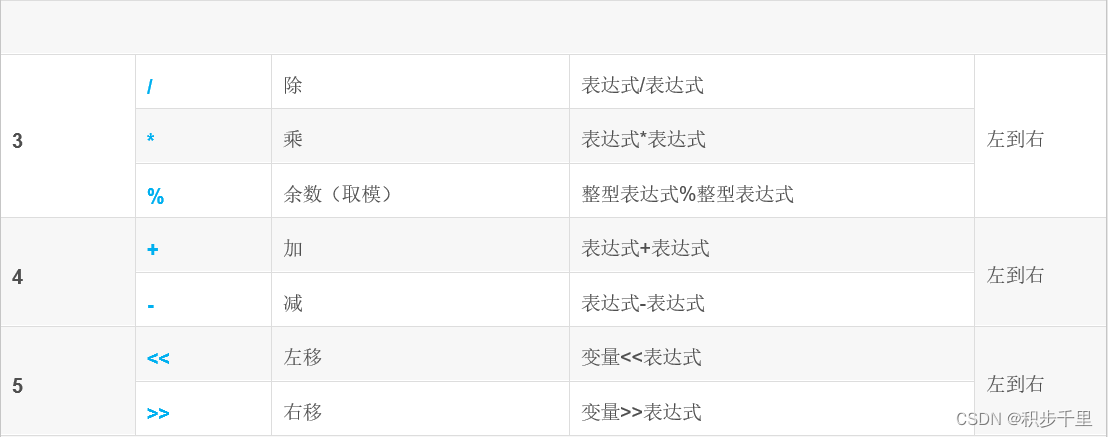
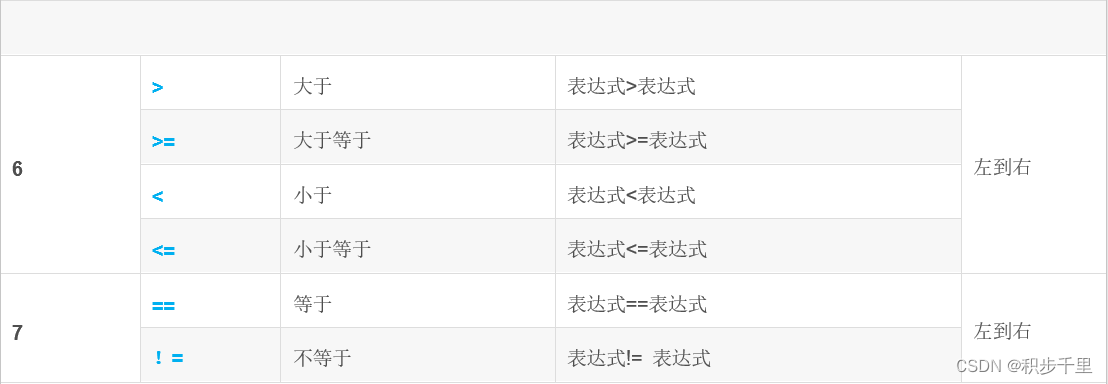
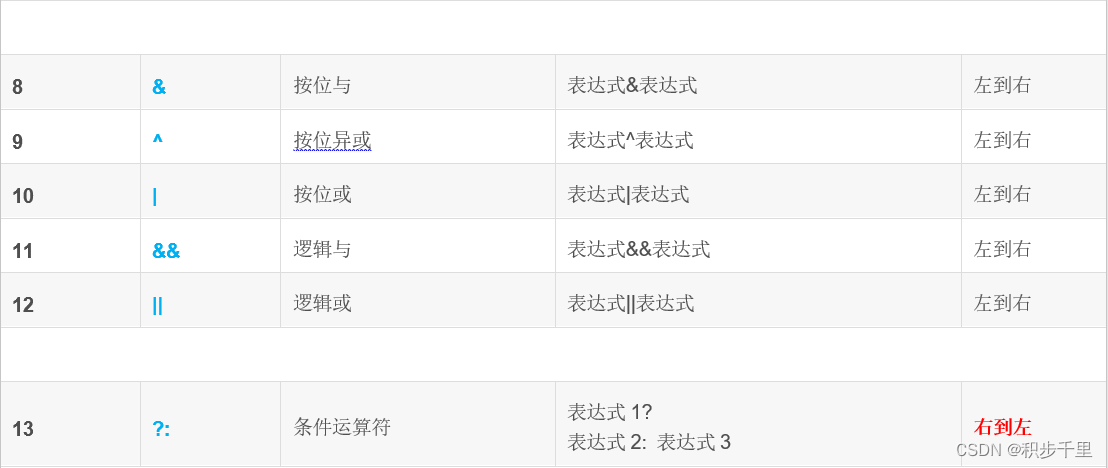
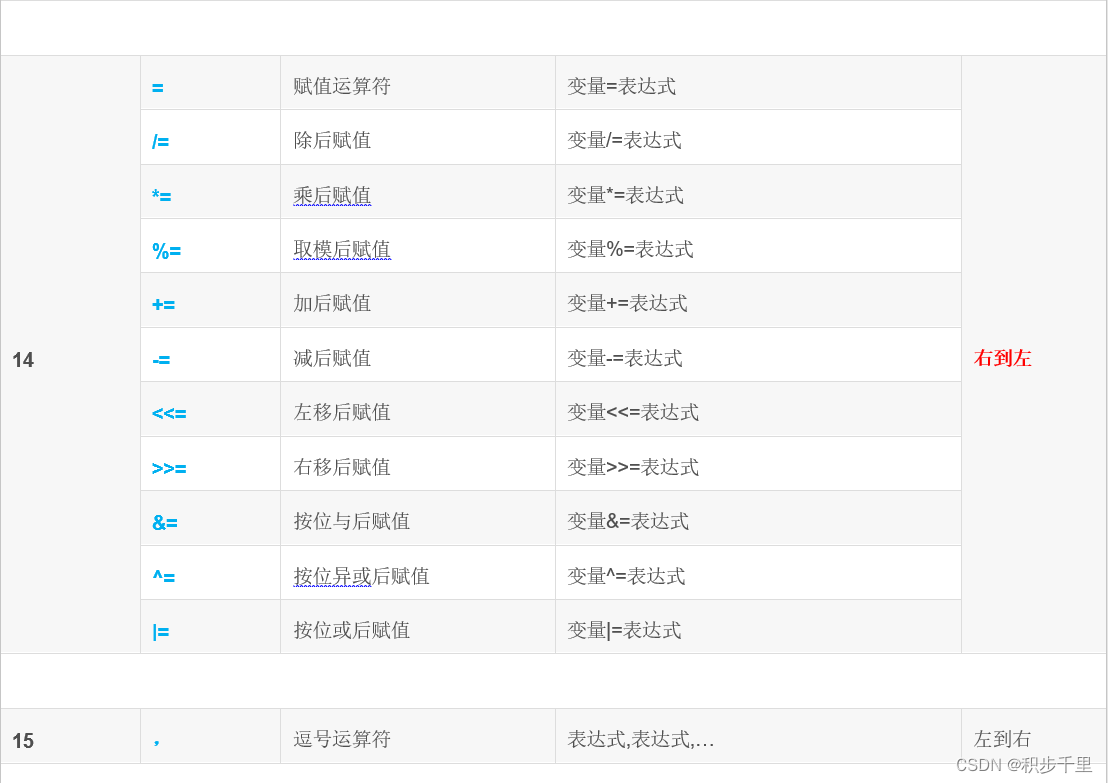
特别说明:
同一优先级的运算符,运算次序由结合方向所决定。
简单的优先级:!>算术运算符>关系运算符>&&>||>赋值运算符
2.3 注意分号的使用
-
C 中的一个多余的分号通常会带来一点点不同:或者是一个空语句,无任何效果;或者编译器可能提出一个诊断消息,可以方便除去掉它。一个重要的区别是在必须跟有一个语句的 if 和 while 语句中。考虑下面的例子:
if (x[i] > big); big = x[i];这不会发生编译错误,但这段程序的意义与下边的就大不相同了:
if (x[i] > big) big = x[i];第一个程序段等价于:
if (x[i] > big) { } big = x[i];也就是直接等价于:
big = x[i]; -
另一个因分号引起巨大不同的地方是,函数定义前面的结构声明的末尾(没加上分号)。请看下面的程序片段:
struct foo { int x; } func() { ..... }在
紧挨着 func 的第一个 } 后面丢失了一个分号。它的效果是声明了一个函数 func,返回值类型是 struct foo,这个结构成了函数声明的一部分。如果这里出现了分号,则 func 将被定义为具有默认的整型返回值。
2.4 switch 语句
- 通常 C 中的 switch 语句中的 case 段可以进入下一个。例如,考虑下面的 C 程序片断:
这个程序片断根据变量 color 的值是 1、2 还是 3 打印 red、yellow 或 blue(默认值)。C 中的 case 标签是真正的标签:控制流程可以无限制地进入到一个 case 标签中。看看另一种形式,假设 C 程序片断如下:switch(color) { case 1: printf ("red"); break; case 2: printf ("yellow"); break; case 3: printf ("blue"); break; }
假设 color = 2。则该程序将打印 yellowblue,因为控制自然地转入到下一个 printf() 的调用。switch(color) { case 1: printf ("red"); case 2: printf ("yellow"); case 3: printf ("blue"); } - 这既是 C 语言 switch 语句的优点又是它的弱点。说它是弱点,是因为很容易忘记一个 break 语句,从而导致程序出现隐晦的异常行为。说它是优点,是因为通过故意去掉 break 语句,可以很容易实现其他方法难以实现的控制结构。尤其是在一个大型的 switch 语句中,我们经常发现对一个 case 的处理可以简化其他一些特殊的处理。
- 例如,考虑编译器通过跳过空白字符来查找一个记号。这里,我们将空格、制表符和新行符视为是相同的,除了新行符还要引起行计数器的增长外:
switch(color) { case '\n': linecount++; /* no break */ case '\t': case ' ': ..... }
2.5 函数调用
- 和其他程序设计语言不同,C 要求一个函数调用必须有一个参数列表,但可以没有参数。因此,假设 func 是一个函数,
就是对该函数进行调用的语句,而func();
什么也不做,它会func;作为函数地址被求值,但不会调用它。
2.6 悬挂 else 问题
-
在讨论任何语法缺陷时我们都不会忘记提到这个问题。尽管这一问题不是 C 语言所独有的,但它仍然伤害着那些有着多年经验的 C 程序员。
-
请看下面的程序片断:
if (0 == x) if (0 == y) error(); else { z = x + y; func(&z); }写这段程序的程序员的目的明显是想将情况分为两种:x = 0 和 x != 0。在第一种情况中,程序段什么都不做,除非 y = 0 时调用 error()。第二种情况中,程序设置 z = x + y 并以 z 的地址作为参数调用 func()。
然而, 这段程序的实际效果却大为不同。其原因是一个 else 总是与其最近的 if 相关联。如果我们希望这段程序能够按照实际的情况运行,应该这样写:if (0 == x) { if (0 == y) { error(); } else { z = x + y; func(&z); } }换句话说,当 x != 0 发生时什么也不做。
如果希望达到第一个例子的效果,应该写:
if (0 == x) { if (0 == y) { error(); } } else { z = z + y; func(&z); }
第三部分: 链接
3.1 你必须自己检查外部类型
- 假设你有一个 C 程序,被划分为两个文件:A 和 B。其中 A 文件包含如下外部声明:
而 B 文件包含如下外部声明:int n;long n; - 这不是一个有效的 C 程序,因为一些外部名称在两个文件中被声明为不同的类型。然而,很多实现检测不到这个错误,因为编译器在编译其中一个文件时并不知道另一个文件的内容。因此,检查类型的工作只能由链接器(或一些工具程序如 lint)来完成;如果操作系统的链接器不能识别数据类型,C 编译器也没法过多地强制它。
- 那么,这个程序运行时实际会发生什么?这有很多可能性:
1. 实现足够聪明,能够检测到类型冲突。则我们会得到一个诊断消息,说明 n 在两个文件中具有不同的类型。
2. 你所使用的实现将 int 和 long 视为相同的类型。典型的情况是机器可以自然地进行 32 位运算。在这种情况下你的程序或许能够工作,好象你两次都将变量声明为 long(或 int)。但这种程序的工作纯属偶然。
3. n 的两个实例需要不同的存储,它们以某种方式共享存储区,即对其中一个的赋值对另一个也有效。这可能发生,例如,编译器可以将 int 安排在 long 的低位。不论这是基于系统的还是基于机器的,这种程序的运行同样是偶然。
4. n 的两个实例以另一种方式共享存储区,即对其中一个赋值的效果是对另一个赋以不同的值。在这种情况下,程序可能失败。 - 然而,像这种情况的发生在编程中却出奇地频繁。例如,程序中的一个 A 文件包含下面的声明:
而另一个 B 文件包含这样的声明:char filename[] = "etc/passwd";
(1)尽管在某些环境中数组和指针的行为非常相似,但它们是不同的。在第一个声明中,filename 是一个字符数组的名字。尽管使用数组的名字可以产生数组第一个元素的指针,但这个指针只有在需要的时候才产生并且不会持续。在第二个声明中,filename 是一个指针的名字。这个指针可以指向程序员让它指向的任何地方。如果程序员没有给它赋一个值,它将具有一个默认的 0 值(null)[char *filename;*注:实际上,在 C 中一个为初始化的指针通常具有一个随机的值,这是很危险的!]。
(2)这两个声明以不同的方式使用存储区,他们不可能共存。避免这种类型冲突的一个方法是使用像 lint 这样的工具(如果可以的话)。为了在一个程序的不同编译单元之间检查类型冲突,一些程序需要一次看到其所有部分。典型的编译器无法完成,但 lint 可以。
(3)避免该问题的另一种方法是将外部声明放到包含文件中。这时,一个外部对象的类型仅出现一次 —— [一些 C 编译器要求每个外部对象仅有一个定义,但可以有多个声明。使用这样的编译器时,我们可以很容易地将一个声明放到一个包含文件中,并将其定义放到其它地方。这意味着每个外部对象的类型将出现两次,但这比出现多于两次要好。]
章节续集声明
- 由于《C 语言陷阱和缺陷》 章节内容较多,该篇幅将分为 "两分部” 来完成编辑;
- 第4部分 ~ 第7部分,将在下节分解,敬请期待。。。















 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











