






Task 01 图论基础与PyG库
本次组队学习的第一个任务分为理论和实践两个部分,第一个部分为图论的一些基础知识,包括图的矩阵表示以及图上的性质等。
图论基础
图的定义
一个图由两大关键组件组成,分别为图中的节点以及节点之间的边,可以记为 G = { V , E } \mathcal{G}=\{\mathcal{V}, \mathcal{E}\} G={V,E},其中 V = { v 1 , … , v N } \mathcal{V}=\left\{v_{1}, \ldots, v_{N}\right\} V={v1,…,vN} 是数量为 N = ∣ V ∣ N=|\mathcal{V}| N=∣V∣ 的结点的集合, E = { e 1 , … , e M } \mathcal{E}=\left\{e_{1}, \ldots, e_{M}\right\} E={e1,…,eM} 是大小为 M M M 的边集合。
- 图 G \mathcal{G} G的大小一般被定义为图的节点数量,即 ∣ V ∣ |\mathcal{V}| ∣V∣;
- 在无向图中,连接两节点的边对于节点来说没有顺序之分,此时节点与此边相关联(incident)
- 图 G = { V , E } \mathcal{G}=\{\mathcal{V}, \mathcal{E}\} G={V,E}可以等价地表示为邻接矩阵的形式,表述节点之间的连接关系;
邻接矩阵
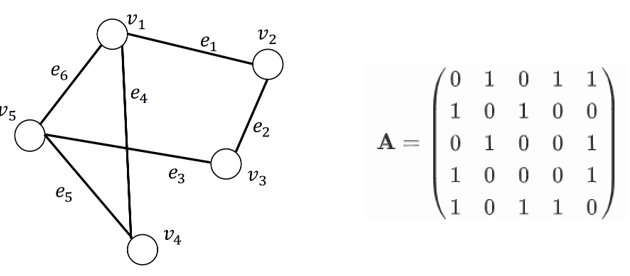
给定一个图 G = { V , E } \mathcal{G}=\{\mathcal{V}, \mathcal{E}\} G={V,E},其对应的邻接矩阵被记为 A ∈ { 0 , 1 } N × N \mathbf{A} \in\{0,1\}^{N \times N} A∈{0,1}N×N,也就是说两节点之间在邻接矩阵中的关系只会存在两种数值(0和1)。 A i , j = 1 \mathbf{A}_{i, j}=1 Ai,j=1表示存在从结点 v i v_i vi到 v j v_j vj的边,反之表示不存在从结点 v i v_i vi到 v j v_j vj的边。
- 无向图中的邻接矩阵一定是对称的;
- 无权图中,各条边的权重被认为是等价地,即各条边的权重都为1;
一个无向无权图及其邻接矩阵例子:
图的基础性质
1 节点的度
图中节点 v i \mathcal{v_i} vi的度表示这个节点和其他节点相关联的次数;具体针对有向有权图,具体分为出度和入度两种度表示。结点 v i v_i vi的出度(out degree)等于从 v i v_i vi出发的边的权重之和,结点 v i v_i vi的入度(in degree)等于从连向 v i v_i vi的边的权重之和。而无权图是有权图的特殊情况,各边的权重为 1 1 1,那么结点 v i v_i vi的出度(out degree)等于从 v i v_i vi出发的边的数量,结点 v i v_i vi的入度(in degree)等于从连向 v i v_i vi的边的数量。
结点 v i v_i vi的度记为 d ( v i ) d(v_i) d(vi),入度记为 d i n ( v i ) d_{in}(v_i) din(vi),出度记为 d o u t ( v i ) d_{out}(v_i) dout(vi)。
2 节点的邻域
在图 G = { V , E } \mathcal{G}=\{\mathcal{V}, \mathcal{E}\} G={V,E}中,节点 v i \mathcal{v_i} vi的邻域** N ( v i ) \mathcal{N(v_i)} N(vi)**是所有和它相邻的一阶( 1 1 1-hop)邻居的节点集合。
- k k k-hop:指的是到结点 v i v_i vi要走 k k k步的节点(节点的2-hop的邻接节点包含了自身)。
3 游走(Walk)
图的游走是节点和边的交替序列,从一个节点开始,以一个节点结束,其中每条边与紧邻的节点相关联。例如: w a l k ( v 1 , v 2 ) = ( v 1 , e 6 , e 5 , e 4 , e 1 , v 2 ) walk(v_1, v_2) = (v_1, e_6,e_5,e_4,e_1,v_2) walk(v1,v2)=(v1,e6,e5,e4,e1,v2),这是一次“行走”,它是一次从节点 v 1 v_1 v1出发,依次经过边 e 6 , e 5 , e 4 , e 1 e_6,e_5,e_4,e_1 e6,e5,e4,e1,最终到达节点 v 2 v_2 v2的“行走”。
- 可以路过重复节点
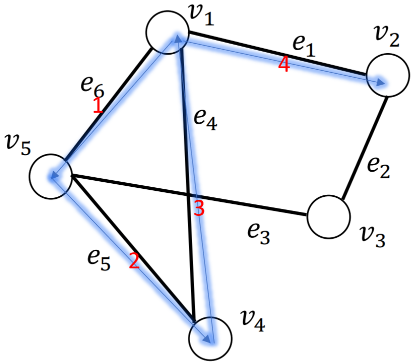
4 路径(Path)
注意和Walk的区别:“路径”是结点不可重复的“游走”。
5 子图(subgraph)
G = { V , E } \mathcal{G}=\{\mathcal{V}, \mathcal{E}\} G={V,E}的子图 G ′ = { V ′ , E ′ } \mathcal{G}^{\prime}=\{\mathcal{V}^{\prime}, \mathcal{E}^{\prime}\} G′={V′,E′}由节点集合和边集合的子集合组成。
6 连通分量
7 连通图
当一个图只包含一个连通分量,即其自身,那么该图是一个连通图。
8 最短路径
v
s
,
v
t
∈
V
v_{s}, v_{t} \in \mathcal{V}
vs,vt∈V 是图
G
=
{
V
,
E
}
\mathcal{G}=\{\mathcal{V}, \mathcal{E}\}
G={V,E}上的一对结点,结点对
v
s
,
v
t
∈
V
v_{s}, v_{t} \in \mathcal{V}
vs,vt∈V之间所有路径的集合记为
P
s
t
\mathcal{P}_{\mathrm{st}}
Pst。结点对
v
s
,
v
t
v_{s}, v_{t}
vs,vt之间的最短路径
p
s
t
s
p
p_{\mathrm{s} t}^{\mathrm{sp}}
pstsp为
P
s
t
\mathcal{P}_{\mathrm{st}}
Pst中长度最短的一条路径,其形式化定义为
p
s
t
s
p
=
arg
min
p
∈
P
s
t
∣
p
∣
p_{\mathrm{s} t}^{\mathrm{sp}}=\arg \min _{p \in \mathcal{P}_{\mathrm{st}}}|p|
pstsp=argp∈Pstmin∣p∣
其中,
p
p
p表示
P
s
t
\mathcal{P}_{\mathrm{st}}
Pst中的一条路径,
∣
p
∣
|p|
∣p∣是路径
p
p
p的长度。
9 直径(diameter)
给定一个连通图
G
=
{
V
,
E
}
\mathcal{G}=\{\mathcal{V}, \mathcal{E}\}
G={V,E},其直径为其所有结点对之间的最短路径的最小值,形式化定义为
diameter
(
G
)
=
max
v
s
,
v
t
∈
V
min
p
∈
P
s
t
∣
p
∣
\operatorname{diameter}(\mathcal{G})=\max _{v_{s}, v_{t} \in \mathcal{V}} \min _{p \in \mathcal{P}_{s t}}|p|
diameter(G)=vs,vt∈Vmaxp∈Pstmin∣p∣
- 任意给定的节点对之间可能存在多条最短路。
10 拉普拉斯矩阵
给定一个图 G = { V , E } \mathcal{G}=\{\mathcal{V}, \mathcal{E}\} G={V,E},其邻接矩阵为 A A A,其拉普拉斯矩阵定义为 L = D − A \mathbf{L=D-A} L=D−A,其中 D = d i a g ( d ( v 1 ) , ⋯ , d ( v N ) ) \mathbf{D=diag(d(v_1), \cdots, d(v_N))} D=diag(d(v1),⋯,d(vN))。
- 对称化的拉普拉斯矩阵
L = D − 1 2 ( D − A ) D − 1 2 = I − D − 1 2 A D − 1 2 \mathbf{L=D^{-\frac{1}{2}}(D-A)D^{-\frac{1}{2}}=I-D^{-\frac{1}{2}}AD^{-\frac{1}{2}}} L=D−21(D−A)D−21=I−D−21AD−21
图的种类
- 同质图(Homogeneous Graph):只有一种类型的节点和一种类型的边的图。
- 异质图(Heterogeneous Graph):存在多种类型的节点和多种类型的边的图。
- 二部图(Bipartite Graph):节点分为两类,只有不同类的节点之间存在边。
图上的机器学习任务
- 节点级别
- 节点聚类:检测节点是否形成一个社区;
- 社交圈检测
- 节点预测:预测节点的类别或某类属性的取值
- 对是否是潜在客户分类、对游戏玩家的消费能力做预测
- 节点聚类:检测节点是否形成一个社区;
- 边级别
- 边预测:预测两个节点间是否存在链接
- Knowledge graph completion、好友推荐、商品推荐
- 边预测:预测两个节点间是否存在链接
- 图级别
- 对不同的图进行分类或预测图的属性
- 分子属性预测
- 图生成
- 药物发现
- 对不同的图进行分类或预测图的属性
图结构的特点
- 任意的大小和复杂的拓扑结构;
- 没有固定的结点排序或参考点;
- 通常是动态的,并具有多模态的特征;
- 图的信息并非只蕴含在节点信息和边的信息中,图的信息还包括了图的拓扑结构。
所以面向图结构数据的神经网络方法需要满足一下几点要求:
- 适用于不同度的节点;
- 节点表征的计算与邻接节点的排序无关;
- 不但能够根据节点信息、邻接节点的信息和边的信息计算节点表征,还能根据图拓扑结构计算节点表征。
PyG环境配置
本次task最麻烦的地方就在环境配置这一块了,由于最近开始服务器大家都在用docker配环境了,所以顺带也把docker的一些操作放在这里了,以备后面复习。
以别人的镜像作为基础去扩展为自己的docker环境:
nvidia-docker ps -a|grep pytorch
# nvidia-docker images 查看本地镜像
# nvidia-docker ps -a 查看开启的镜像
查询结果如下:
以本次task配置要求,选取CUDA版本为10.1的torch 1.6.0镜像(pytorch/pytorch:1.6.0-cuda10.1-cudnn7-devel)为基础镜像;
激活镜像(执行命令./run_in_docker.sh脚本):
#!/bin/bash
gpu_id=$1
echo $gpu_id # 指定 GPU
# 启动镜像
NV_GPU=$gpu_id nvidia-docker run --rm --shm-size=4g -it -v /:/mnt pytorch/pytorch:1.6.0-cuda10.1-cudnn7-devel bash
接下来按照顺序安装一下package:
pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.6.0+cu101.html
pip install torch-sparse -f https://pytorch-geometric.com/whl/torch-1.6.0+cu101.html
pip install torch-cluster -f https://pytorch-geometric.com/whl/torch-1.6.0+cu101.html
pip install torch-spline-conv -f https://pytorch-geometric.com/whl/torch-1.6.0+cu101.html
pip install torch-geometric
时间有点长,等待一会会就全部安装成功了;
最后我们需要将安装了上述packages的镜像保存为新镜像(否则下次再次启动该镜像时,会发现上述package都没有了,不要问我是怎么知道的😭)
那应该怎么及时将安装了我们需要package的镜像环境保存我们的新镜像呢?打开一个新的窗口,输入以下命令;!!!现在的窗口不能关闭,要保持基础docker 镜像处于一个激活的状态!!!
sudo docker commit -m "updata packages" -a "chenhs" 5b2e2cf1f5fe pytorch/pytorch:transformersV1
# -m 指定提交的说明信息
# -a 可以指定更新的用户信息
# 之后是用来创建镜像的容器的ID;最后指定目标镜像的仓库名。
sudo docker images # 再次查看已有镜像,发现我们commit的镜像在列!
PyG 代码初尝
Data对象—图的表示
data对象的创建
在torch-geometric,第一步就是对图结构数据的表示,也就是data对象的创建;
我们先看看Data类的构造函数:
class Data(object):
def __init__(self, x=None, edge_index=None, edge_attr=None, y=None, **kwargs):
r"""
x (Tensor, optional): 节点属性矩阵,大小为`[num_nodes, node_features]`
edge_index (LongTensor, optional): 边索引矩阵,大小为`[2, num_edges]`,其中第0行为尾节点(起始节点)索引,第1行(结束节点)为头节点索引,边是由尾节点指向头节点;
edge_attr (Tensor, optional): 边特征矩阵,大小为`[num_edges,edge_features]`
y (Tensor, optional): 节点级或图级或边的标签,任意大小
"""
self.x = x
self.edge_index = edge_index
self.edge_attr = edge_attr
self.y = y
for key, item in kwargs.items():
if key == 'num_nodes':
self.__num_nodes__ = item
else:
self[key] = item
edge_index的每一列定义为图中的一条边,其中第一行为边起始节点的索引,第二行为边结束节点的索引。这种表示方法被称为COO格式(coordinate format),通常用于表示稀疏矩阵。
通常,Graph至少会包含x, edge_index, edge_attr, y, num_nodes5个属性,当图包含其他属性时,我们可以通**过指定额外的参数使Data对象包含其他的属性。(好像发现了作业的关键)**类似下面这样的:
graph = Data(x=x, edge_index=edge_index, edge_attr=edge_attr, y=y, num_nodes=num_nodes, other_attr=other_attr)
我们也可以通过dict对象来创建data对象(Creates a data object from a python dictionary.)
graph_dict = {
'x': x,
'edge_index': edge_index,
'edge_attr': edge_attr,
'y': y,
'num_nodes': num_nodes,
'other_attr': other_attr
}
#graph_dict中属性值的类型与大小的要求与`Data`类的构造函数的要求相同
graph_data = Data.from_dict(graph_dict) # from_dict是一个类方法
我们也可以将data对象转化为dict或namedtuple
def to_dict(self):
return {key: item for key, item in self}
# ---------------------------------------------------------------------------
def to_namedtuple(self):
keys = self.keys
DataTuple = collections.namedtuple('DataTuple', keys)
return DataTuple(*[self[key] for key in keys])
查看data对象
# 获取data对象属性 (由上可知,graph_data是一个字典)
x = graph_data['x']
# 设置data对象属性
graph_data['x'] = x
# 获取data对象包含的属性的关键字
graph_data.keys()
# 对边排序并移除重复的边
graph_data.coalesce()
data对象的性质
我们通过一个实际的图例子看下data对象的其他属性:
from torch_geometric.datasets import KarateClub
dataset = KarateClub()
data = dataset[0] # Get the first graph object.
print(data)
print('==============================================================')
# 获取图的一些信息
print(f'节点数量: {data.num_nodes}')
print(f'边数量: {data.num_edges}')
print(f'单个节点特征维度: {data.num_node_features}')
print(f'单个节点特征维度: {data.num_features}')
print(f'边特征维度: {data.num_edge_features}')
print(f'平均节点度:边数量/节点数量: {data.num_edges / data.num_nodes:.2f}')
print(f'边是都有序且不重复.: {data.is_coalesced()}')
print(f'用作训练集的节点数量: {data.train_mask.sum()}')
print(f'训练集在数据集中的比率:{int(data.train_mask.sum()) / data.num_nodes:.2f}')
print(f'是否包含孤立的点: {data.contains_isolated_nodes()}')
print(f'是否包含自环边: {data.contains_self_loops()}')
print(f'是否为无向图: {data.is_undirected()}')
Data(edge_index=[2, 156], train_mask=[34], x=[34, 34], y=[34])
==============================================================
节点数量: 34
边数量: 156
单个节点特征维度: 34
单个节点特征维度: 34
边特征维度: 0
平均节点度:边数量/节点数量: 4.59
边是都有序且不重复.: True
用作训练集的节点数量: 4
训练集在数据集中的比率: 0.12
是否包含孤立的点: False
是否包含自环边: False
是否为无向图: True
Dataset对象—图数据集的表示
PyG内置了大量常用的基准数据集,我们以PyG内置的Planetoid数据集为例,来学习PyG中图数据集的表示及使用。
下载数据集
下载数据集这里需要更改一下在源码中更改下载源,不然会陷入漫长的等待中;
具体而言:将planetoid.py中48行url = 'https://github.com/kimiyoung/planetoid/raw/master/data 改为url=‘https://gitee.com/jiajiewu/planetoid/raw/master/data’
from torch_geometric.datasets import Planetoid
# 将原始文件处理为包含Data对象的Dataset对象
dataset = Planetoid(root='./dataset/Cora', name='Cora')
Downloading https://gitee.com/jiajiewu/planetoid/raw/master/data/ind.cora.x
Downloading https://gitee.com/jiajiewu/planetoid/raw/master/data/ind.cora.tx
Downloading https://gitee.com/jiajiewu/planetoid/raw/master/data/ind.cora.allx
Downloading https://gitee.com/jiajiewu/planetoid/raw/master/data/ind.cora.y
Downloading https://gitee.com/jiajiewu/planetoid/raw/master/data/ind.cora.ty
Downloading https://gitee.com/jiajiewu/planetoid/raw/master/data/ind.cora.ally
Downloading https://gitee.com/jiajiewu/planetoid/raw/master/data/ind.cora.graph
Downloading https://gitee.com/jiajiewu/planetoid/raw/master/data/ind.cora.test.index
Processing...
Done!
分析数据集
print("数据集大小:",len(dataset)) # 1
print("数据集所包含的分类任务:",dataset.num_classes) # 7
print("数据集节点特征维度:",dataset.num_node_features) # 1433
由上分析可知,数据集中仅包含一张Graph(样本数量为1),该Graph上可以执行的分类任务有7项,同时Graph中的节点特征维度为1433;
进一步,我们再分析这个样本
data = dataset[0]
print("看看样本",data)
print("可以用作训练的节点数目", data.train_mask.sum())
print("可以用作验证的节点数目", data.val_mask.sum())
print("可以用作测试的节点数目", data.test_mask.sum())
输出:
看看样本 Data(edge_index=[2, 10556], test_mask=[2708], train_mask=[2708], val_mask=[2708], x=[2708, 1433], y=[2708])
可以用作训练的节点数目 tensor(140)
可以用作验证的节点数目 tensor(500)
可以用作测试的节点数目 tensor(1000)
作业:
请通过继承
Data类实现一个类,专门用于表示“机构-作者-论文”的网络。该网络包含“机构“、”作者“和”论文”三类节点,以及“作者-机构“和“作者-论文“两类边。对要实现的类的要求:1)用不同的属性存储不同节点的属性;2)用不同的属性存储不同的边(边没有属性);3)逐一实现获取不同节点数量的方法。
我的作业
import torch
from torch_geometric.data import Data
class authors_network(Data):
def __init__(self, institution=None, author=None, paper=None, from_edge_index=None,
from_edge_attr=None, write_edge_index=None, write_edge_attr=None, y=None, **kwargs):
# “机构“、”作者“和”论文”三类节点
self.institution = institution
self.author = author
self.paper= paper
# 作者-机构和作者-论文两类边
self.from_edge_index = from_edge_index
self.from_edge_attr = from_edge_attr
self.write_edge_index = write_edge_index
self.write_edge_attr = write_edge_attr
self.y = y
def institution_number(self):
return(self.institution.shape[0])
def author_number(self):
return(self.author.shape[0])
def paper_number(self):
return(self.paper.shape[0])















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









