






作者:Xiao Wang, Shiao Wang, Chuanming Tang, Lin Zhu, Bo Jiang, Yonghong Tian, Jin Tang
代码:https://github.com/Event-AHU/EventVOT_Benchmark
摘要
近年来,使用仿生事件相机进行跟踪引起了越来越多的关注。现有工作要么利用对齐的RGB和事件数据用于精准跟踪,要么直接学习基于事件的跟踪器。前者需要更多的推理成本,后者可能很容易受到噪声事件/稀疏空间分辨率的影响。
因此,本文提出一种新的分层知识蒸馏框架,可以在训练过程中充分利用多模态/多视角信息来促进知识传递,使我们可以在测试过程中仅使用事件信息实现高速和低延迟的视觉跟踪。 || 具体地,(1)通过同时输入RGB帧和事件流,训练一个基于教师Transformer多模态跟踪框架;(2)设计了一种新的分层知识蒸馏策略,其中包括成对相似性、特征表达、基于响应图的知识蒸馏,以指导学生Transformer网络的学习;(3)由于现有的event-based跟踪数据集都是低分辨率(346*260),因此我们提出了第一个大规模高分辨率(1280*720)数据集EventVOT。他包含了1141个视频序列,涵盖行人、车辆、无人机、乒乓球等广泛类别。
1. Introduction
事件相机的背景:可以异步输出事件脉冲(event pluses asynchronously),并通过事件检测(例如,光强度的变化)来捕获运动信息。相比于传统RGB相机,事件相机由于稠密时域分辨率,在捕获快速移动目标时表现更好。他也在高动态变换、低能源消耗和低延迟时表现更好。
| Zhang et al.提出的AFNet和CDFI | 通过多模态对齐和混合模块结合帧和RGB数据 |
| STNet | 结合Transformer和脉冲神经网络用于事件跟踪 |
| Zhu et al. | 尝试挖掘关键事件,并使用图网络挖掘关键事件的不规则时空信息用于跟踪 |
现有方法的缺点:
- 在缓慢移动场景中,事件相机的空间信号非常稀疏,且目标的轮廓不够清晰,可能导致跟踪失败。可以使用RGB-Event数据补偿这个缺陷,但额外的模态会增加模型推理代价;
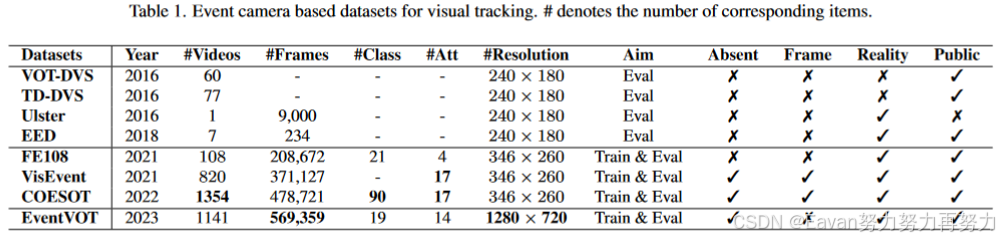
- 现存基于event的跟踪数据集都是由DVS346相机收集得到的,其输出分辨率为346*260。目前还尚未验证为这样低分辨率设计的事件表示和特征提取方法是否仍然对高分辨率事件数据有效;
因此,自然地引出接下来的问题:我们是否可以迁移训练阶段中多模态/多视角数据中的知识,只在测试阶段中使用事件数据来实现鲁棒的跟踪?
本文做法:
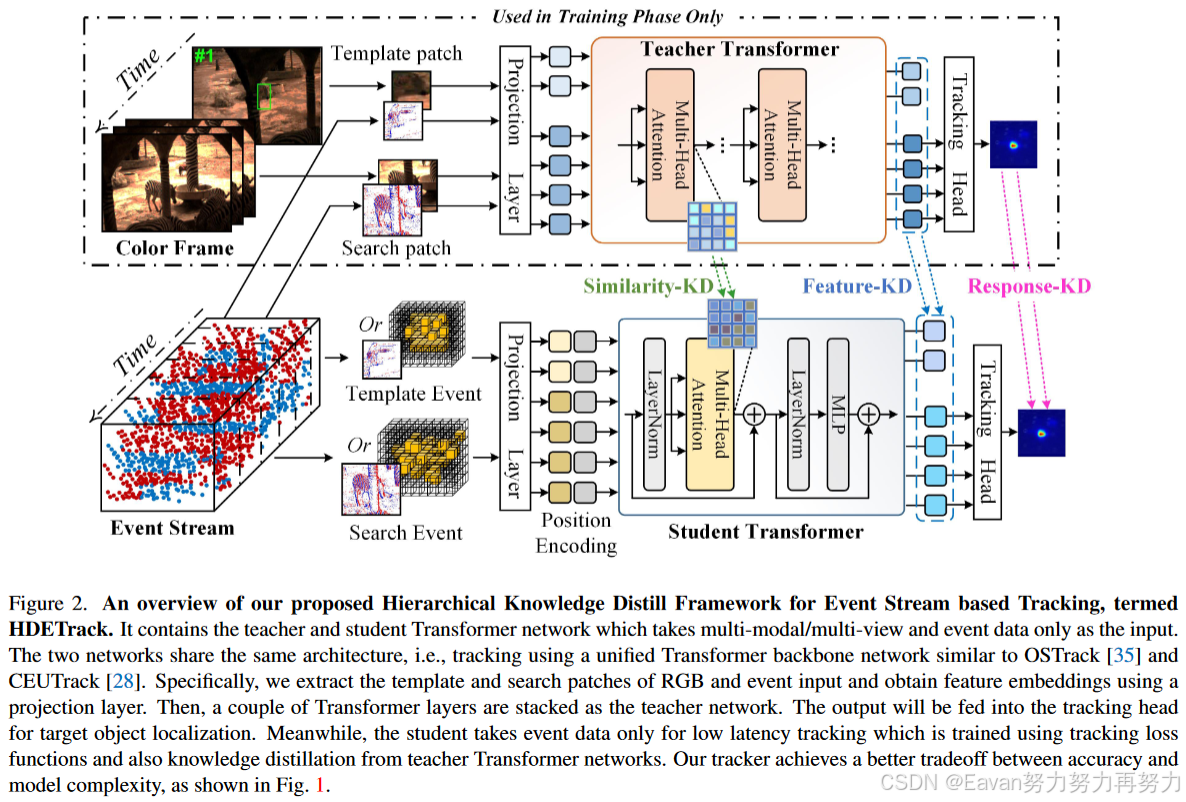
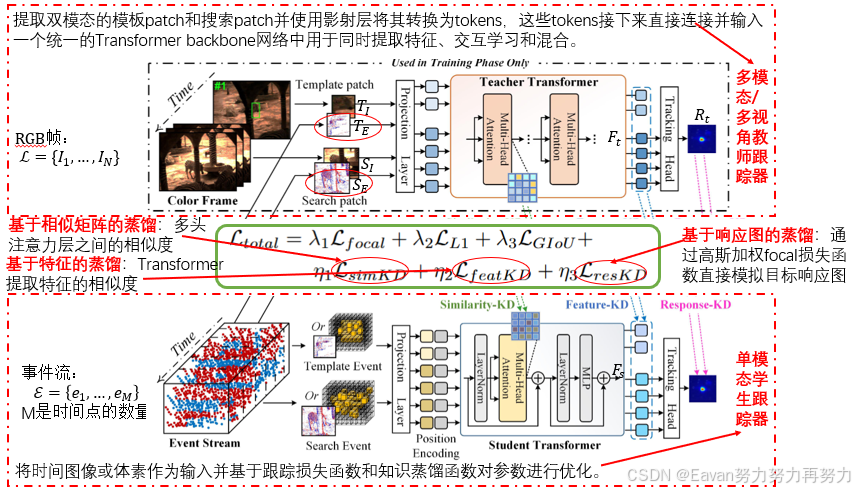
本文通过设计一个跨模态分层知识蒸馏策略(cross-modality hierarchical knowledge distillation scheme),提出一个基于事件的视觉跟踪框架(a novel event-based visual tracking framework)。|| 首先,送入RGB帧和事件流以训练一个教师Transformer网络,他分别从初始帧和后续帧中裁剪双模他的模板patch和搜索区域,并采用 a projection layer将其转换为token表示。|| 然后,几个Transformer块将tokens混合到一个统一backbone中。|| 最后,使用跟踪头预测目标的响应图。|| 一旦获得教师Transformer网络,分层知识蒸馏策略就可以用于学生Transformer网络的学习,其中学生Transformer网络的输入只有事件数据。具体地,相似度矩阵、特征表示和基于知识蒸馏的响应图被同时用于跨模态知识迁移考虑。值得注意的是:由于学生网络中输入事件数据,所以他不仅在测试阶段的跟踪准确,也可以实现低延迟和高效的跟踪。
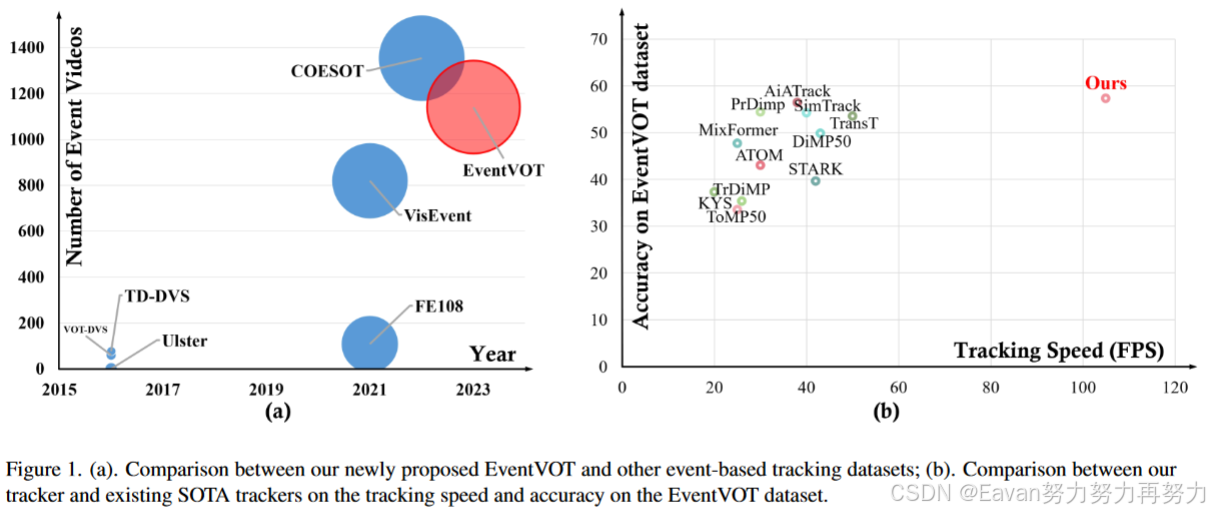
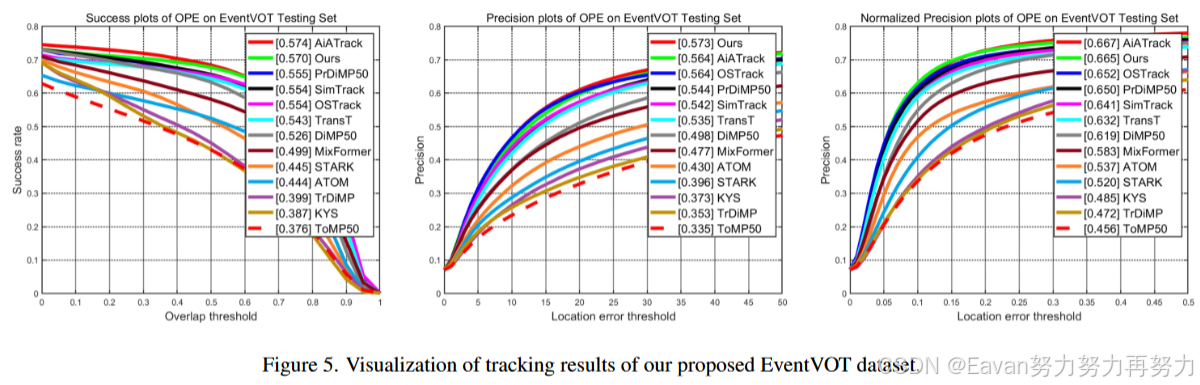
提出一个新的高分辨率事件跟踪数据集,EventVOT,验证本文和相关方法的性能。不同于现存的数据集(FE240hz, VisEvent, COESOT)分别率有限346*260,本文数据集通过Prophese camera EVK4-HD采集,其输出分辨率为1280*720,包含1141个视频序列。
本文贡献:
- 提出一个新的分层跨模态知识蒸馏策略用于事件跟踪。这是第一个将知识迁移从多模态/多视角到单模态跟踪的工作,称为HDETrack。
- 提出第一个高分辨率数据集用于事件跟踪,称为EventVOT。提供了现存跟踪器的实验评估结果。
- 在4个大规模数据集(FE240HZ, VisEvent, COESOT, EventVOT)上的实验结果充分验证了本文提出跟踪器的有效性。
2. Related Work
RGB Camera based Tracking.(略)
Event Camera based Tracking.相关文献如下:
| ESVM | 基于事件的支持向量机用于高速移动目标跟踪 |
| AFNet | 集成基于事件的跨模态对齐(ECA)和交叉相关混合(CF)模块,有效对齐并混合RGB和事件流 |
| ATSLTD | 一种具有线性时间衰减的自适应时间表面事件-帧转换算法,用于异步视网膜事件跟踪 |
| EKLT | 将帧和事件流混合为具有高时域分辨率的视觉特征 |
| Zhang等人 | 采用自注意力和交叉注意力策略增强RGB和事件特征用于鲁棒跟踪 |
| STNet | 用Transformer捕获全局空间特征,用脉冲神经网络捕获时域线索 |
| Wang等人 | 用跨模态Transformer混合RGB和事件数据 |
| Zhu等人 | 使用密度不敏感下采样策略采样关键事件,并使用图网络将其嵌入到高维特征空间中 |
| Tang等人 | 使用一个统一的backbone网络同时实现多模态特征提取、相关和混合操作 |
| Zhu等人 | 引入Prompt微调,驱动预训练的RGB backbong用于多模态跟踪 |
| AFNet | 使用多模态对齐和混合模块以不同测量速率 组合 来自两种模态的有意义信息 |
| Zhu等人 | 对特定模态随机掩码,并提出一个正交高秩损失函数来加强不同模态之间的交互 |
Knowledge Distillation.(略)
3. Methodology
3.1 Overview
先用RGB帧和事件流训练一个大规模教师Transformer。具体地,提取双模态的模板patch和搜索patch并使用影射层将其转换为tokens,这些tokens接下来直接连接并输入一个统一的Transformer backbone网络中用于同时提取特征、交互学习和混合。
其次,对于事件学生跟踪网络,将时间图像或体素作为输入并基于跟踪损失函数和知识蒸馏函数对参数进行优化。
更细节的是,基于KD的相似度矩阵、基于KD的特征、基于KD的响应图都被考虑用于更高的跟踪性能。
3.2 Input Representaion
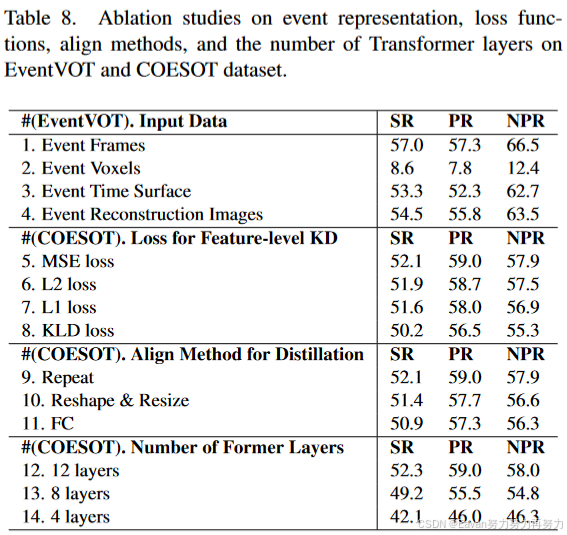
事件体素:将事件流ℰE堆叠/拆分为事件图像/体素,便于与现存RGB模态融合。具体地,事件图像通过与RGB模态的曝光事件对齐来获得的。事件体素是将通过将事件流与空间维度(W和H)和时间维度(𝑇_𝑖)一起拆分来获得的。每个体素网格的比例表示为(a,b,c),因此,可得到W/a×H/b×T/c个体素网格。类似地,得到事件数据的模态和搜索区域T_E和S_E。
3.3 Network Architecture及3.4 Hierarchical Knowledge Distillation
4. EventVOT Dataset
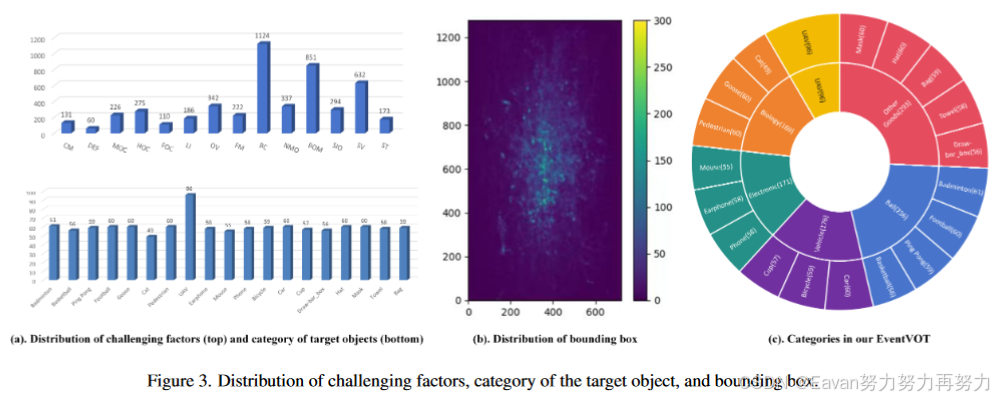
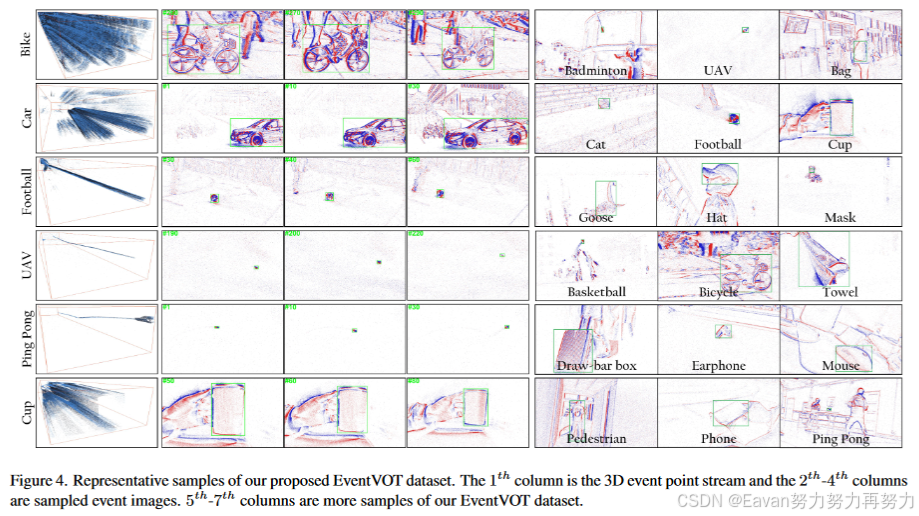
5. Experiment
对比数据集:
- EventVOT:本文提出的
- FE240hz:使用灰度DVS346事件相机收集,包含71个训练视频和25个测试视频。在超过143K张图片和相应事件上提供了超过1132K个注释。
- VisEvent:使用彩色DVS346事件相机收集,第一个大规模帧-事件跟踪数据集。一共820个视频,包括室内的和室外的。训练集500个视频,测试集320个视频。https://github.com/wangxiao5791509/VisEvent_SOT_Benchmark.
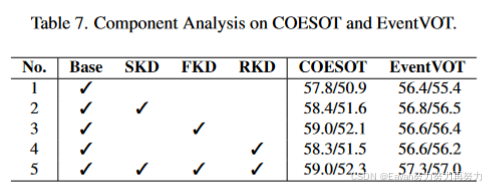
- COESOT:包含90个类别和1354个视频序列(478721个RGB帧)。训练集827个视频,测试集527个视频。https://github.com/Event-AHU/COESOT
评价指标:
Precision Rate (PR), Normalized Precision Rate (NPR), and Success Rate (SR), FPS (Frames Per Second)。
实验细节:
两阶段训练:(1)50个epoch对多模态教师Transformer训练,学习率0.0001, 权重衰减0.0001,batch size为32。(2)采用分层知识蒸馏策略对单模态学生Transformer网络训练,学习率0.0001, 权重衰减0.0001,batch size为32。优化器:AdamW, 硬件:CPU Intel(R) Xeon(R) Gold 5318Y CPU @2.10GHz and GPU RTX3090.
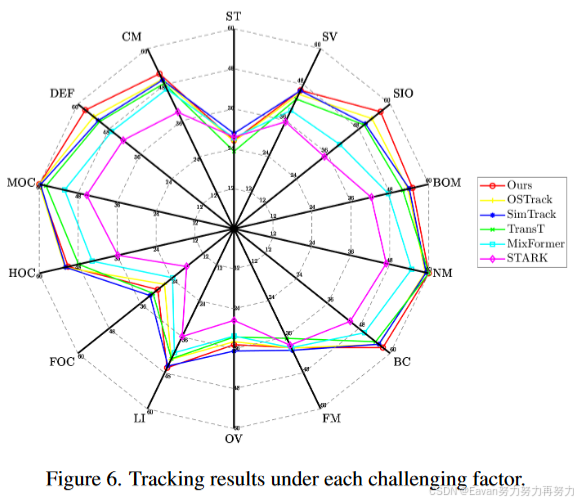
实验结果:
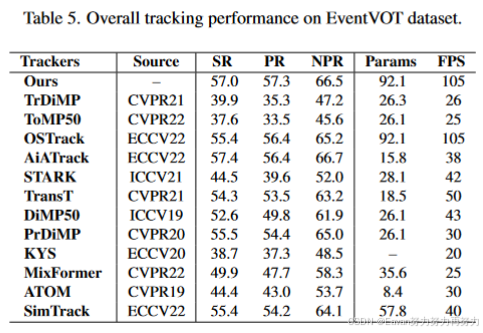
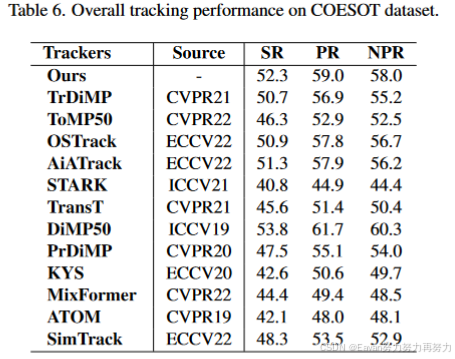
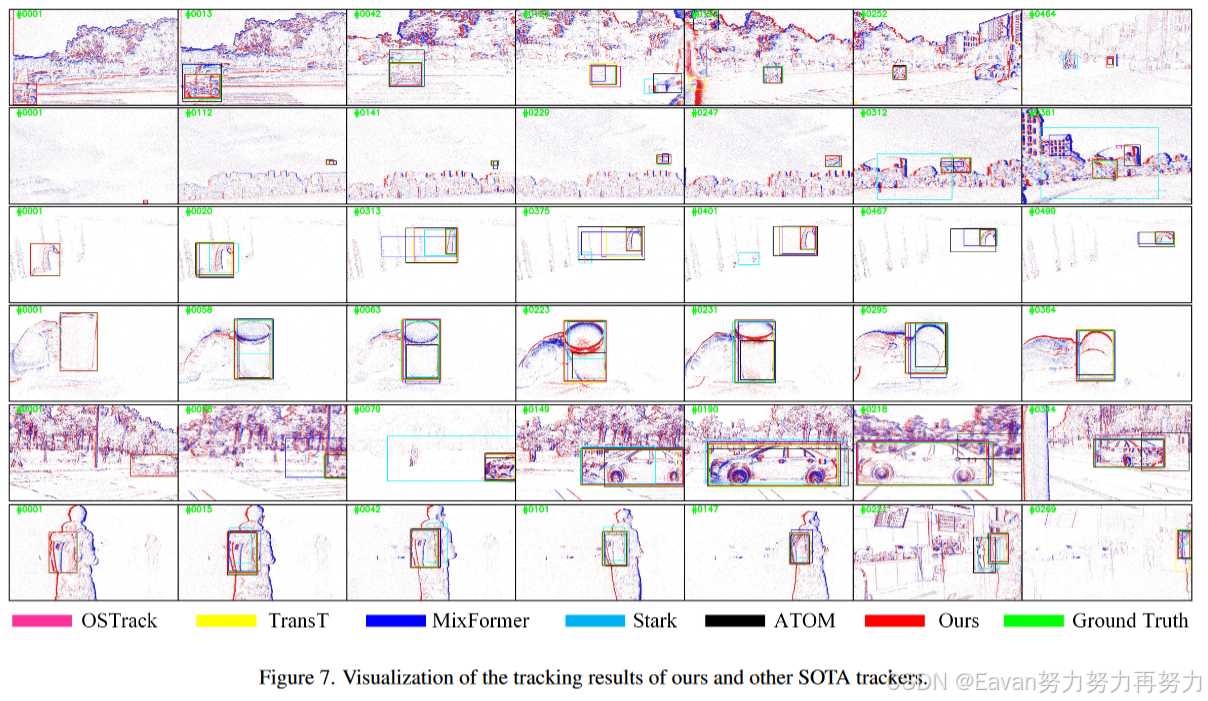
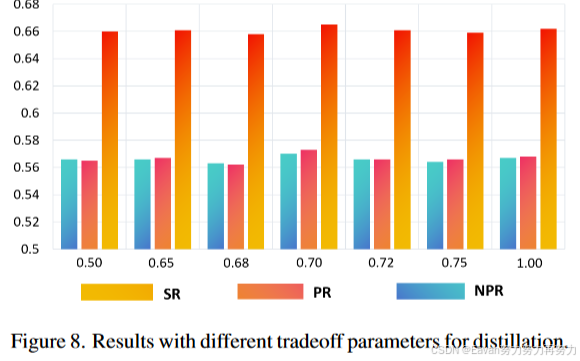
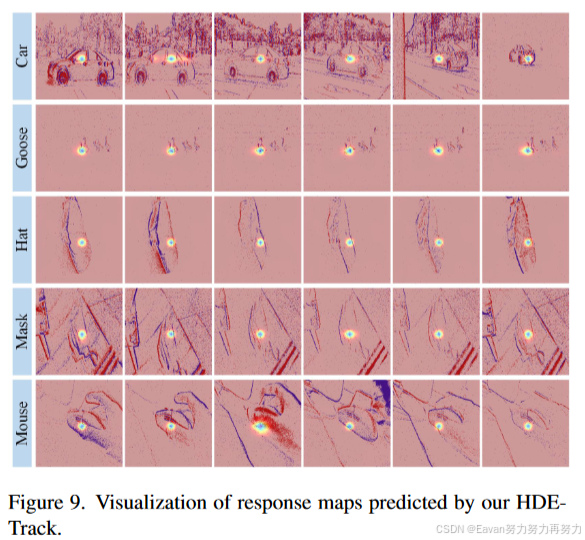

















 3406
3406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









