







场景:客户业务手工Excel录入的数据中,信息包含电话与手机号码,其中手机号码总是会有人录入的有问题,导成了地址或包含中文字符。
注意:兼容手机号码为数值或加密后的手机号码
解决方案1:处理表中手机号码字段,将包含中文字符的字段内容清空,电话与手机号码只保留一个即可
解决方案2:处理表中手机号码字段,将中文字符过滤掉,只保留手机号码
针对解决方案1:可以利用中文字符编码范围\u4e00-\u9fa5中的'\'字符来判断,分别对电话与手机做判断并更新,宗旨是清空错误的,包留另一个正常的字段
update orders o set o.tel = null
where instr(asciistr(o.tel), '\') > 0
and o.tel is not null
and o.mobile is not null;
update orders o set o.mobile = null
where instr(asciistr(o.mobile), '\') > 0
and o.tel is not null
and o.mobile is not null;
commit;针对解决方案2:则需要使用正则表达式做判断,其中我们虚拟出了数据的各种可能性
最终决定使用regexp_replace(tel, '[^\x00-\xff]', '')正则表达式,利用的就是匹配双字节字符,再加上条件where instr(asciistr(tel), '\') > 0来过滤掉非中文(主要是排除掉加密后的tel)

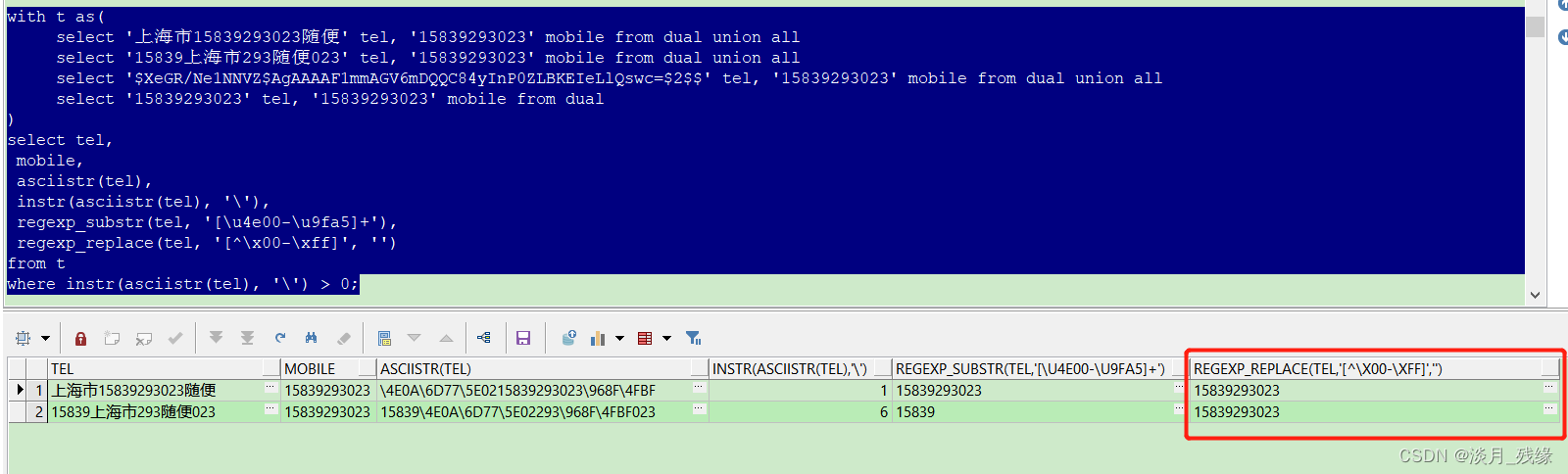
检验的SQL:
with t as(
select '上海市15839293023随便' tel, '15839293023' mobile from dual union all
select '15839上海市293随便023' tel, '15839293023' mobile from dual union all
select '$XeGR/Ne1NNVZ$AgAAAAF1mmAGV6mDQQC84yInP0ZLBKEIeLlQswc=$2$$' tel, '15839293023' mobile from dual union all
select '15839293023' tel, '15839293023' mobile from dual
)
select tel,
mobile,
asciistr(tel),
instr(asciistr(tel), '\'),
regexp_substr(tel, '[\u4e00-\u9fa5]+'),
regexp_replace(tel, '[^\x00-\xff]', '')
from t
where instr(asciistr(tel), '\') > 0;最终解决方案2的更新语句如下:
update orders o set o.tel = regexp_replace(o.tel, '[^\x00-\xff]', '')
where instr(asciistr(o.tel), '\') > 0
and o.tel is not null
and o.mobile is not null;
update orders o set o.mobile = regexp_replace(o.mobile, '[^\x00-\xff]', '')
where instr(asciistr(o.mobile), '\') > 0
and o.tel is not null
and o.mobile is not null;
commit;后计:
实际使用中,我采用的是解决方案1,按需求主要是避免客户手工录入导致的异常字段发生,数据量并不大,但偶尔发生又需要我们来处理,确实比较麻烦。
而针对客户的录入数据发现客户一般会将电话与手机号码录入相同的内容,所以这个字段必然有一个是正常的,因此针对现有情况用了解决方案1。这样在大多数上游下发过来都是加密手机号码的情况下效率更高点。
更好的方案是纠正客户录入错误数据。















 1484
1484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









