






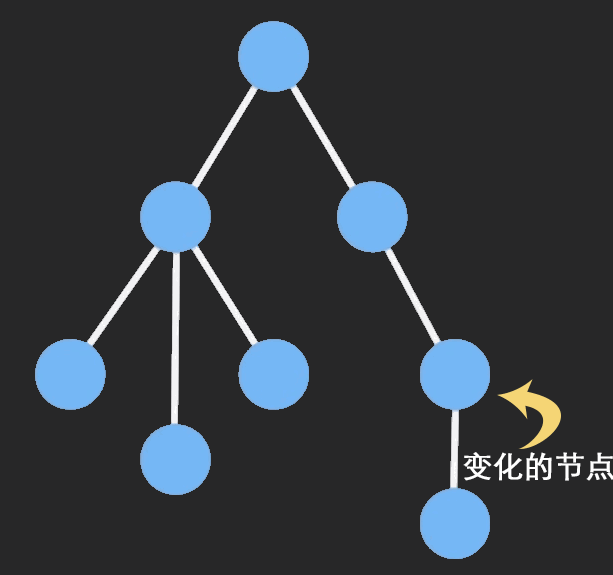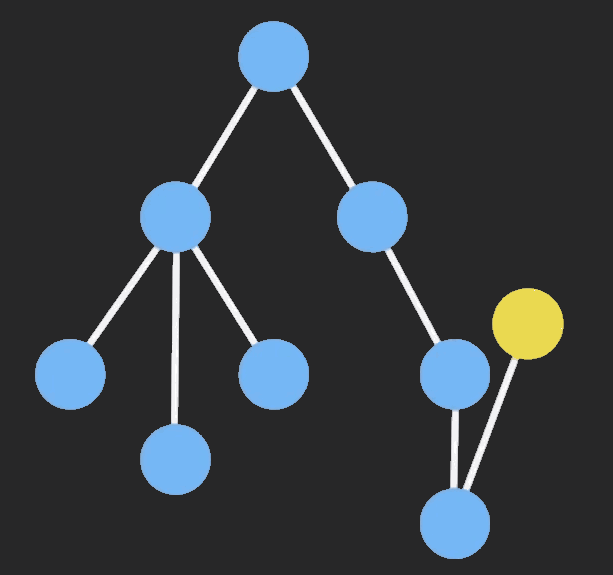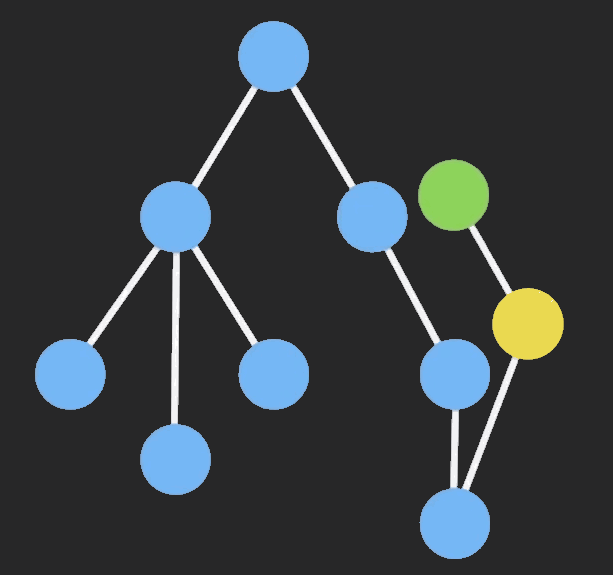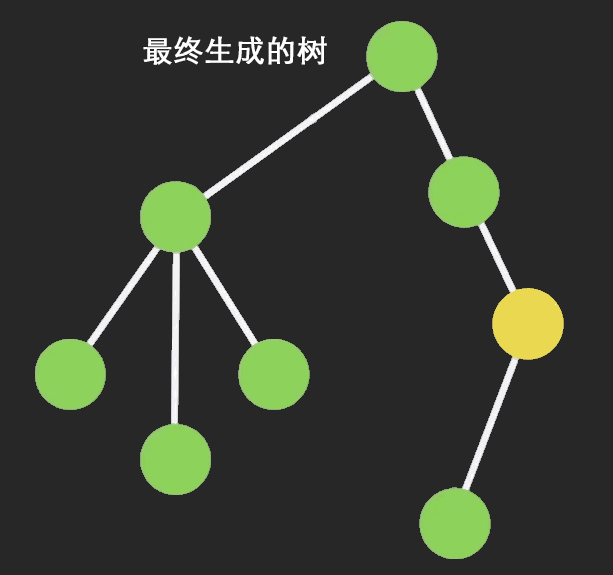
Immutable 是什么?
关于Immutable的定义,官方文档是这样说的:
Immutable data encourages pure functions (data-in, data-out) and lends itself to much simpler application development and enabling techniques from functional programming such as lazy evaluation.
Immutable数据就是一旦创建,就不能更改的数据。每当对Immutable对象进行修改的时候,就会返回一个新的Immutable对象,以此来保证数据的不可变。
不可变数据让纯函数更强大,也让程序开发愈发简单明了,同时使类似于惰性求值的函数式编程成为可能。
为了在javascript上实现这些强大的概念,我们给javascript引擎带来了熟悉的面向对象的API以及Array、Map和Set上一的些镜像方法,让它能简单和高效地与普通javascript对象互相转换。
对于Immutable的好处及介绍,大家可以参考Immutable 详解及 React 中实践,这篇文章介绍的很清楚。
阅前注意
为了更好地介绍Immutable.js多样的API和返回值,本文档将基于静态类型的JS(如Flow、TypeScript)。你_不必使用这些_类型检查工具来使用Immutable.js,然而使用与它们相似的语法能让你更透彻地理解这些API。
一些例子以及阅读指南
方法上所有的参数声明了它能接受和返回何种类型数据。以下例子表示了一个接受两个数值型参数返回值类型为数值型的方法:
sum(first: number, second: number): number
某些情况下,参数需要接受多种类型或者方法能返回多种类型数据,这种参数类型被称作_泛型_。例如,一个方法总是返回与他接受的参数同种类型的数据:
identity<T>(value: T): T
泛型也能被定义在类及其变量上。一个为你保存变量的类应该会是这样:
class Box<T> {
constructor(value: T)
getValue(): T
}
为了修改不可变数据,方法将会返回一个新的同类型集合。this这个类型表明返回值类型将参照类的类型。例如,当你在一个List上push一个数据时,他将会返回一个新的同类型List:
class List<T> {
push(value: T): this
}
在Immutable.js中,一些方法实现了迭代协议,Iterable<string>表示一系列有序的string。在JS中我们一般使用数组([])来表示一个可迭代类型,在Immutable.js中集合都是可迭代的。
例如要在数据结构中获得深入的值,我们可以使用getIn他需要一个Iterable路径:
getIn(path: Iterable<string | number>): any
使用这个方法需要通过一个数组:data.getIn(["key", 2])。
注意:所有实力都是使用JavaScript的ES6规范,在老旧的浏览器上运行可能需要转换为ES3。
例:
// ES2015
const mappedFoo = foo.map(x => x * x);
// ES3
var mappedFoo = foo.map(function (x) { return x * x; });
API
fromJS()
完全地将一个JS对象转或数组转换为不可变的Maps或Lists。
is()
和Object.is类似的相等比较方法,比较两个Collection是否有相同的值。
hash()
hash()方法是Immutable确认两个值是否相等和决定这些值如何存储的重要依据。传入任何数据,它将返回一个31位的整形。
isImmutable()
返回True表示这是一个不可变数据(Collection或Record)。
isCollection()
返回True表示这是一个集合(Collection)或集合的子类。
isKeyed()
返回True表示这是Collection.key或其子类。
isIndexed()
返回True表示这是Collection.isIndexed或其子类。
isAssociative()
返回True表示这是Keyed或者Indexed Collection。
isOrdered()
返回True表示这是一个Collection同时迭代索引设置正确。Collection.indexed、OrderedMap和OrderedSet会返回True。
isValueObject()
返回True表示这是个JS对象并且同时拥有equals()和hashCode()方法。
ValueObject
List
List是有序的密集型集合,类似于JS的数组(Array)。
Map
不可变Map是无序的可持久化的Collection.Keyed(key, value)键值对,存取复杂度为O(log32 N)。
OrderedMap
一种能够保证迭代顺序为元素进入顺序的Map。
Set
一种存取复杂度为O(log32 N)的无重复值的集合。
OrderedSet
一种能够保证迭代顺序为元素添加(add)顺序的Set。
Stack
Stack(栈)是一种支持复杂度为O(1)的高效添加和删除数据的集合,在栈顶添加和删除数据使用unshift(v)和shift()。
Range()
返回由Seq.Indexed指明的从start到end由step指定增量的数值(包含start,不包含end),默认值start为0,step为1,end为无穷大。当start与end相等时,返回一个空范围。
Repeat()
返回右Seq.Indexed指明的重复times次数的value,当times未定义时,返回值为无穷Seq的value。
Record
建立一个继承自Record的新类型。它类似于JS的对象,但需要明确指定可设置的键及其对应的值。
Seq
相当于一系列值,但不能具体表现为某种数据结构。
Collection
Collection是一组可迭代的键值对集合,它也是所有immutable的基类,确保它们能使用集合的方法(如map,filter)。
fromJS()
完全地将一个JS对象转或数组转换为不可变的Maps或Lists。
fromJS(
jsValue: any,
reviver?: (
key: string | number,
sequence: Collection.Keyed<string, any> | Collection.Indexed<any>,
path?: Array<string | number>
) => any
): any
reviver是可选参数,它将在每个集合(collection)上调用,接受Seq(从最深层到顶层)和当前集合的key,父级JS对象将作为this被提供。在最顶层的对象的key为"" 。reviver将会返回一个新的不可变集合,同时允许自定义转换一个深层次的JS对象。path将会提供从开始到当前值的Key系列。
以下是一个由原始JS数据转换为List和OrderedMap:
const { fromJS, isIndexed } = require('immutable')
fromJS({ a: {b: [10, 20, 30]}, c: 40}, function (key, value, path) {
console.log(key, value, path)
return isIndexed(value) ? value.toList() : value.toOrderedMap()
})
> "b", [ 10, 20, 30 ], [ "a", "b" ]
> "a", { b: [10, 20, 30] }, c: 40 }, [ "a" ]
> "", {a: {b: [10, 20, 30]}, c: 40}, []
如果reviver未提供,那么默认地,Array会转换为List,Object会转换为Map。
事实上,reviver和JSON.parse参数一致。
fromJS是保守的转换,它只会将能被Array.isArray认证的数组转换为List,只会转换原始的对象(不包含自定义原型)为Map。
注意,当一个JS对象转换为不可变Map时,尽管不可变Map可接受任意类型键值,JS对象的索引永远为字符串,即使你使用简写。
let obj = { 1: "one" };
Object.keys(obj); // [ "1" ]
obj["1"]; // "one"
obj[1]; // "one"
let map = Map(obj);
map.get("1"); // "one"
map.get(1); // undefined
当使用任意类型去查询JS对象的索引它将会隐式转换为字符串,但不可变Map使用get()去索引时,它的参数将不会被转换。
"Using the reviver parameter"
is()
和Object.is类似的相等比较方法,但其是比较两个Collection是否有相同的值。
is(first: any, second: any): boolean
用于比较两个不可变数据是否相等,包括Map的键值对和Set的成员。
import { Map, is } from 'immutable'
const map1 = Map({ a: 1, b: 1, c: 1 })
const map2 = Map({ a: 1, b: 1, c: 1 })
assert(map1 !== map2)
assert(Object.is(map1, map2) === false)
assert(is(map1, map2) === true)
// 译者注:assert为断言,传入值为false时将报错。Console.assert
is()不仅仅能比较原始的字符串、数值和不可变集合比如Map和Set,也能比较实现了包含equals()和hashCode()两个方法的ValueObject 。
注意:和Object.is不同的是,Immutable.is假定0和-0是相同的,与ES6的Map键值相匹配。
hash()
hash()方法是Immutable确认两个值是否相等和决定这些值如何存储的重要依据。传入任何数据,它将返回一个31位的整形。
hash(value: any): number
设计一个判定两个对象是否相等,关键不是有一个.equals()方法返回true,而是两个对象的.hashCode()方法返回相同的值。hash()应运而生。
注意:尽管hash()专注于平衡速度和防止碰撞,但它不会产生安全的哈希值。
isImmutable()
返回True表示这是一个不可变数据(Collection或Record)。
isImmutable(maybeImmutable: any): boolean
示例
const { isImmutable, Map, List, Stack } = require('immutable');
isImmutable([]); // false
isImmutable({}); // false
isImmutable(Map()); // true
isImmutable(List()); // true
isImmutable(Stack()); // true
isImmutable(Map().asMutable()); // false
isCollection()
返回True表示这是一个集合(Collection)或集合的子类。
isCollection(maybeCollection: any): boolean
示例
const { isCollection, Map, List, Stack } = require('immutable');
isCollection([]); // false
isCollection({}); // false
isCollection(Map()); // true
isCollection(List()); // true
isCollection(Stack()); // true
isKeyed()
返回True表示这是Collection.key或其子类。
isKeyed(maybeKeyed: any): boolean
示例
const { isKeyed, Map, List, Stack } = require('immutable');
isKeyed([]); // false
isKeyed({}); // false
isKeyed(Map()); // true
isKeyed(List()); // false
isKeyed(Stack()); // false
isIndexed()
返回True表示这是Collection.isIndexed或其子类。
isIndexed(maybeIndexed: any): boolean
示例
const { isIndexed, Map, List, Stack, Set } = require('immutable');
isIndexed([]); // false
isIndexed({}); // false
isIndexed(Map()); // false
isIndexed(List()); // true
isIndexed(Stack()); // true
isIndexed(Set()); // false
isAssociative()
返回True表示这是Keyed或者Indexed Collection。
isAssociative(maybeAssociative: any): boolean
示例
const { isAssociative, Map, List, Stack, Set } = require('immutable');
isAssociative([]); // false
isAssociative({}); // false
isAssociative(Map()); // true
isAssociative(List()); // true
isAssociative(Stack()); // true
isAssociative(Set()); // false
isOrdered()
返回True表示这是一个Collection同时迭代索引设置正确。Collection.indexed、OrderedMap和OrderedSet会返回True。
isOrdered(maybeOrdered: any): boolean
示例
const { isOrdered, Map, OrderedMap, List, Set } = require('immutable');
isOrdered([]); // false
isOrdered({}); // false
isOrdered(Map()); // false
isOrdered(OrderedMap()); // true
isOrdered(List()); // true
isOrdered(Set()); // false
isValueObject()
返回True表示这是个JS对象并且同时拥有equals()和hashCode()方法。
isValueObject(maybeValue: any): boolean
任意两个_值对象(value object)_都可以使用Immutable.is()来比较值是否相等或用于Map的键和Set的成员。
ValueObject
class ValueObject
成员函数
equals()
当与传入的集合值相等时返回True,相等比较与Immutable.is()的定义一样。
equals(other: any): boolean
注意:此方法与Immutable.is(this,other)等效,为提供链式写法。
hashCode()
返回当前集合的哈希计算值。
hashCode(): number
在添加一个元素到Set中或者用key索引Map时,hashCode会被用于查明两个集合潜在的相等关系,即使他们没用相同的地址。
const a = List([ 1, 2, 3 ]);
const b = List([ 1, 2, 3 ]);
assert(a !== b); // 不是相同地址
const set = Set([ a ]);
assert(set.has(b) === true);
当两个值的hashCode相等时,并不能完全保证他们是相等的,但当他们的hashCode不同时,他们一定是不等的。
List
List是类似于JS中数组的密集型有序集合。
class List<T> extends Collection.Indexed<T>
List是不可变的(Immutable),修改和读取数据的复杂度为O(log32 N),入栈出栈(push, pop)复杂度为O(1)。
List实现了队列功能,能高效的在队首(unshift, shift)或者队尾(push, pop)进行元素的添加和删除。
与JS的数组不同,在List中一个未设置的索引值和设置为undefined的索引值是相同的。List#forEach会从0到size便利所有元素,无论他是否有明确定义。
构造函数
List()
新建一个包含传入元素的不可变List。
List(): List<any>
List<T>(): List<T>
List<T>(collection: Iterable<T>): List<T>
例
const { List, Set } = require('immutable')
const emptyList = List()
// List []
const plainArray = [ 1, 2, 3, 4 ]
const listFromPlainArray = List(plainArray)
// List [ 1, 2, 3, 4 ]
const plainSet = Set([ 1, 2, 3, 4 ])
const listFromPlainSet = List(plainSet)
// List [ 1, 2, 3, 4 ]
const arrayIterator = plainArray[Symbol.iterator]()
const listFromCollectionArray = List(arrayIterator)
// List [ 1, 2, 3, 4 ]
listFromPlainArray.equals(listFromCollectionArray) // true
listFromPlainSet.equals(listFromCollectionArray) // true
listFromPlainSet.equals(listFromPlainArray) // true
静态方法
List.isList()
判断传入参数是否为List。
List.isList(maybeList: any): boolean
例
List.isList([]); // false
List.isList(List()); // true
List.of()
使用传入值新建一个List。
List.of<T>(...values: Array<T>): List<T>
例
List.of(1, 2, 3, 4)
// List [ 1, 2, 3, 4 ]
注意:所有值不会被改变。
List.of({x:1}, 2, [3], 4)
// List [ { x: 1 }, 2, [ 3 ], 4 ]
成员变量
size
size
持久化修改
set()
返回一个在index位置处值为value的新List。如果index位置已经定义了值,它将会被替换。
set(index: number, value: T): List<T>
当index为负值时,将从List尾部开始索引。v.set(-1, "value")设置了List最后一个索引位置的值。
当index比原List的size大时,返回的新List的size将会足够大以包含index。
const originalList = List([ 0 ]);
// List [ 0 ]
originalList.set(1, 1);
// List [ 0, 1 ]
originalList.set(0, 'overwritten');
// List [ "overwritten" ]
originalList.set(2, 2);
// List [ 0, undefined, 2 ]
List().set(50000, 'value').size;
// 50001
注意:set可以在withMutations中使用。
delete()
返回一个不包含原index值总长度减一的新List。并且大于原index的索引都会减一。
delete(index: number): List<T>
别名
remove()
此方法与list.splice(index, 1)是同义的。
index可以为负值,表示从末尾开始计算索引。v.delete(-1)将会删除List最后一个元素。
注意:delete在IE8上使用是不安全的。
List([ 0, 1, 2, 3, 4 ]).delete(0);
// List [ 1, 2, 3, 4 ]
注意:delete_不可_在withMutations中使用。
insert()
返回一个index处值为value总长度加一的新List。并且大于原index的索引都会加一。
insert(index: number, value: T): List<T>
此方法与list.splice(index, 0, value)同义。
注意:insert_不可_在withMutations中使用。
clear()
返回一个新的长度为0的空List。
clear(): List<T>
例
List([ 1, 2, 3, 4 ]).clear()
// List []
注意:clear可以在withMutations中使用。
push()
返回一个新的List为旧List末尾添加一个元素值为所传入value。
push(...values: Array<T>): List<T>
例
List([ 1, 2, 3, 4 ]).push(5)
// List [ 1, 2, 3, 4, 5 ]
注意:push可以在withMutations中使用。
pop()
返回一个新的List为旧List移除最后一个元素。
pop(): List<T>
注意:这与Array#pop不同,它返回的是新List而不是被移除元素。使用last()方法来获取List最后一个元素。
List([ 1, 2, 3, 4 ]).pop()
// List[ 1, 2, 3 ]
注意:pop可以在withMutations中使用。
unshift()
返回一个新的List为旧List头部插入所提供的values。
unshift(...values: Array<T>): List<T>
例
List([ 2, 3, 4]).unshift(1);
// List [ 1, 2, 3, 4 ]
注意:unshift可以在withMutations中使用。
shift()
返回一个新的List为旧List移除第一个元素,并且其他元素索引减一。
shift(): List<T>
注意:这与Array#shift不同,它返回的是新List而不是被移除元素。使用first()方法来获取List最后一个元素。
List([ 0, 1, 2, 3, 4 ]).shift();
// List [ 1, 2, 3, 4 ]
注意:shift可以在withMutations中使用。
update()
将会返回一个新List,如果指定index位置在原List中存在,那么由所提供函数updater更新此位置值,否则该位置值设为所提供的notSetValue值。 如果只传入了一个参数updater,那么updater接受的参数为List本身。
update(index: number, notSetValue: T, updater: (value: T) => T): this
update(index: number, updater: (value: T) => T): this
update<R>(updater: (value: this) => R): R
重载
Collection#update
见
Map#update
index可以为负值,表示从尾部开始索引。v.update(-1)表示更新最后一个元素。
const list = List([ 'a', 'b', 'c' ])
const result = list.update(2, val => val.toUpperCase())
// List [ "a", "b", "C" ]
此方法可以很方便地链式调用一系列普通的方法。RxJS称这为"let",lodash叫做"thru"。
例,在调用map和filter之后计算List的和:
function sum(collection) {
return collection.reduce((sum, x) => sum + x, 0)
}
List([ 1, 2, 3 ])
.map(x => x + 1)
.filter(x => x % 2 === 0)
.update(sum)
// 6
注意:update(index)可以在withMutations中使用。
merge()
注意:merge可以在withMutations中使用。
merge(...collections: Array<Collection.Indexed<T> | Array<T>>): this
见
Map#merge
mergeWith()
注意:mergeWith可以在withMutations中使用。
mergeWith(
merger: (oldVal: T, newVal: T, key: number) => T,
...collections: Array<Collection.Indexed<T> | Array<T>>
): this
见
Map#mergeWith
mergeDeep()
注意:mergeDeep可以在withMutations中使用。
mergeDeep(...collections: Array<Collection.Indexed<T> | Array<T>>): this
见
Map#mergeDeep
mergeDeepWith()
注意:mergeDeepWith可以在withMutations中使用。
mergeDeepWith(
merger: (oldVal: T, newVal: T, key: number) => T,
...collections: Array<Collection.Indexed<T> | Array<T>>
): this
见
Map#mergeDeepWith
setSize()
返回一个新的List,长度为指定size。如果原长度大于size,那么新的list将不包含超size的值。如果原长度小于size,那么超过部分的值为undefind。
setSize(size: number): List<T>
在新构建一个LIst时,当已知最终长度,setSize可能会和withMutations共同使用以提高性能。
深度持久化
setIn()
返回一个新的在ksyPath指定位置了值value的List。如果在keyPath位置没有值存在,这个位置将会被构建一个新的不可变Map。
setIn(keyPath: Iterable<any>, value: any): this
数值索引将被用于描述在List中的路径位置。
const { List } = require('immutable');
const list = List([ 0, 1, 2, List([ 3, 4 ])])
list.setIn([3, 0], 999);
// List [ 0, 1, 2, List [ 999, 4 ] ]
注意:setIn可以在withMutations中使用。
deleteIn()
返回一个删除了由keyPath指定位置值的新List。如果指定位置无值,那么不会发生改变。
deleteIn(keyPath: Iterable<any>): this
别名
removeIn()
例
const { List } = require('immutable');
const list = List([ 0, 1, 2, List([ 3, 4 ])])
list.deleteIn([3, 0]);
// List [ 0, 1, 2, List [ 4 ] ]
注意:removeIn_不可_在withMutations中使用。
updateIn()
注意:updateIn可以在withMutations中使用。
updateIn(
keyPath: Iterable<any>,
notSetValue: any,
updater: (value: any) => any
): this
updateIn(keyPath: Iterable<any>, updater: (value: any) => any): this
见
Map#updateIn
mergIn()
注意:mergIn_不可_在withMutations中使用。
mergeIn(keyPath: Iterable<any>, ...collections: Array<any>): this
见
Map#mergIn
mergeDeepIn()
注意:mergeDeepIn可以在withMutations中使用。
mergeDeepIn(keyPath: Iterable<any>, ...collections: Array<any>): this
见
Map#mergeDeepIn
暂时改变
withMutaitions()
注意:只有部分方法可以被可变的集合调用或者在withMutations中调用!查看文档中各个方法看他是否允许在withMuataions中调用。
withMutations(mutator: (mutable: this) => any): this
见
Map#withMutations
asMutable()
withMutations()的替代API。
asMutable(): this
见
Map#asMutable
注意:只有部分方法可以被可变的集合调用或者在withMutations中调用!查看文档中各个方法看他是否允许在withMuataions中调用。
withMutations(mutator: (mutable: this) => any): this
asImmutable()
asImmutable(): this
见
Map#asImmutable
序列算法
cancat()
将其他的值或者集合与这个List串联起来返回为一个新List。
concat<C>(...valuesOrCollections: Array<Iterable<C> | C>): List<T | C>
覆盖
Collection#concat
map()
返回一个由传入的mapper函数处理过值的新List。
map<M>(mapper: (value: T, key: number, iter: this) => M, context?: any): List<M>
覆盖
Collection#map
例
List([ 1, 2 ]).map(x => 10 * x)
// List [ 10, 20 ]
注意:map()总是返回一个新的实例,即使它产出的每一个值都与原始值相同。
flatMap()
扁平化这个List为一个新List。
flatMap<M>(
mapper: (value: T, key: number, iter: this) => Iterable<M>,
context?: any
): List<M>
覆盖
Collection#flatMap
与list.map(...).flatten(true)相似。
filter()
返回一个只有由传入方法predicate返回为true的值组成的新LIst。
filter<F>(
predicate: (value: T, index: number, iter: this) => boolean,
context?: any
): List<F>
filter(
predicate: (value: T, index: number, iter: this) => any,
context?: any
): this
覆盖
Collection#filter
注意:filter()总是返回一个新的实例,即使它的结果没有过滤掉任何一个值。
zip()
将List与所提供集合拉链咬合(zipped)。
zip(...collections: Array<Collection<any, any>>): List<any>
覆盖
Collection.Index#zip
与zipWIth类似,但这个使用默认的zipper建立数组。
const a = List([ 1, 2, 3 ]);
const b = List([ 4, 5, 6 ]);
const c = a.zip(b); // List [ [ 1, 4 ], [ 2, 5 ], [ 3, 6 ] ]
zipWith()
将List与所提供集合使用自定义zipper方法进行拉链咬合(zipped)。
zipWith<U, Z>(
zipper: (value: T, otherValue: U) => Z,
otherCollection: Collection<any, U>
): List<Z>
zipWith<U, V, Z>(
zipper: (value: T, otherValue: U, thirdValue: V) => Z,
otherCollection: Collection<any, U>,
thirdCollection: Collection<any, V>
): List<Z>
zipWith<Z>(
zipper: (...any: Array<any>) => Z,
...collections: Array<Collection<any, any>>
): List<Z>
覆盖
Collection.Indexed#zipWith
例
const a = List([ 1, 2, 3 ]);
const b = List([ 4, 5, 6 ]);
const c = a.zipWith((a, b) => a + b, b);
// List [ 5, 7, 9 ]
[Symbol.iterator]
[Symbol.iterator](): IterableIterator<T>
继承自
Collection.Indexed#[Symbol.iterator]
filterNot()
返回一个由所提供的predicate方法返回false过滤的新的相同类型的集合。
filterNot(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#filterNot
例
const { Map } = require('immutable')
Map({ a: 1, b: 2, c: 3, d: 4}).filterNot(x => x % 2 === 0)
// Map { "a": 1, "c": 3 }
注意:filterNot总是返回一个新的实例,即使它没有过滤掉任何一个值。
reverse()
返回为一个逆序的新的List。
reverse(): this
继承自
Collection#reverse
sort()
返回一个使用传入的comparator重新排序的新List。
sort(comparator?: (valueA: T, valueB: T) => number): this
继承自
Collection#sort
如果没有提供comparator方法,那么默认的比较将使用<和>。
comparator(valueA, valueB):
- 返回值为
0这个元素将不会被交换。 - 返回值为
-1(或者任意负数)valueA将会移到valueB之前。 - 返回值为
1(或者任意正数)valueA将会移到valueB之后。 - 为空,这将会返回相同的值和顺序。
当被排序的集合没有定义顺序,那么将会返回同等的有序集合。比如map.sort()将返回OrderedMap。
const { Map } = require('immutable')
Map({ "c": 3, "a": 1, "b": 2 }).sort((a, b) => {
if (a < b) { return -1; }
if (a > b) { return 1; }
if (a === b) { return 0; }
});
// OrderedMap { "a": 1, "b": 2, "c": 3 }
注意:sort()总是返回一个新的实例,即使它没有改变排序。
sortBy()
与sort类似,但能接受一个comparatorValueMapper方法,它允许通过更复杂的方式进行排序:
sortBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): this
继承自
Collection#sortBy
例
hitters.sortBy(hitter => hitter.avgHits)
注意:sortBy()总是返回一个新的实例,即使它没有改变排序。
groupBy()
返回一个Collection.Keyeds的Collection.keyed,由传入的grouper方法分组。
groupBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Seq.Keyed<G, Collection<number, T>>
继承自
Collection#groupBy
const { List, Map } = require('immutable')
const listOfMaps = List([
Map({ v: 0 }),
Map({ v: 1 }),
Map({ v: 1 }),
Map({ v: 0 }),
Map({ v: 2 })
])
const groupsOfMaps = listOfMaps.groupBy(x => x.get('v'))
// Map {
// 0: List [ Map{ "v": 0 }, Map { "v": 0 } ],
// 1: List [ Map{ "v": 1 }, Map { "v": 1 } ],
// 2: List [ Map{ "v": 2 } ],
// }
转换为JavaScript类型
toJS()
深层地将这个有序的集合转换转换为原生JS数组。
toJS(): Array<any>
继承自
Collection.Index#toJS
toJSON()
浅转换这个有序的集合为原生JS数组。
toJSON(): Array<any>
继承自
Collection.Index#toJSON
toArray()
浅转换这个有序的集合为原生JS数组并且丢弃key。
toArray(): Array<any>
继承自
Collection#toArray
toObject()
浅转换这个有序的集合为原生JS对象。
toObject(): {[key: string]: V}
继承自
Collection#toObject
读值
get()
返回提供的索引位置关联的值,或者当提供的索引越界时返回所提供的notSetValue。
get<NSV>(index: number, notSetValue: NSV): T | NSV
get(index: number): T | undefined
继承自
Collection.Indexed#get
index可以为负值,表示从集合尾部开始索引。s.get(-1)取得集合最后一个元素。
has()
使用Immutable.is判断key值是否在Collection中。
has(key: number): boolean
继承自
Collection#has
includes()
使用Immutable.is判断value值是否在Collection中。
includes(value: T): boolean
继承自
Collection#includes
first()
取得集合第一个值。
first(): T | undefined
继承自
Collection#first
last()
取得集合第一个值。
last(): T | undefined
继承自
Collection#last
转换为Seq
toSeq()
返回Seq.Indexed。
toSeq(): Seq.Indexed<T>
继承自
Collection.Indexed#toSeq
fromEntrySeq()
如果这个集合是由[key, value]这种原组构成的,那么这将返回这些原组的Seq.Keyed。
fromEntrySeq(): Seq.Keyed<any, any>
继承自
Collection.Index#fromEntrySeq
toKeyedSeq()
从这个集合返回一个Seq.Keyed,其中索引将视作key。
toKeyedSeq(): Seq.Keyed<number, T>
继承自
Collection#toKeyedSeq
如果你想对Collection.Indexed操作返回一组[index, value]对,这将十分有用。
返回的Seq将与Colleciont有相同的索引顺序。
const { Seq } = require('immutable')
const indexedSeq = Seq([ 'A', 'B', 'C' ])
// Seq [ "A", "B", "C" ]
indexedSeq.filter(v => v === 'B')
// Seq [ "B" ]
const keyedSeq = indexedSeq.toKeyedSeq()
// Seq { 0: "A", 1: "B", 2: "C" }
keyedSeq.filter(v => v === 'B')
// Seq { 1: "B" }
toIndexedSeq()
将这个集合的值丢弃键(key)返回为Seq.Indexed。
toIndexedSeq(): Seq.Indexed<T>
继承自
Collection#toIndexedSeq
toSetSeq()
将这个集合的值丢弃键(key)返回为Seq.Set。
toSetSeq(): Seq.Set<T>
继承自
Collection#toSetSeq
组合
interpose()
返回一个在原集合每两个元素之间插入提供的separator的同类型集合。
interpose(separator: T): this
继承自
COllection.Indexed#interpose
interleave()
返回一个原集合与所提供collections交叉的痛类型集合。
interleave(...collections: Array<Collection<any, T>>): this
继承自
Collection.Indexed#interleave
返回的集合依次包含第一个集合元素与第二个集合元素。
const { List } = require('immutable')
List([ 1, 2, 3 ]).interleave(List([ 'A', 'B', 'C' ]))
// List [ 1, "A", 2, "B", 3, "C"" ]
由最短的集合结束交叉。
List([ 1, 2, 3 ]).interleave(
List([ 'A', 'B' ]),
List([ 'X', 'Y', 'Z' ])
)
// List [ 1, "A", "X", 2, "B", "Y"" ]
splice()
返回一个由指定值替换了原集合某个范围的值的新的有序集合。如果没提供替换的值,那么会跳过要删除的范围。
splice(index: number, removeNum: number, ...values: Array<T>): this
继承自
Collection.Indexed#splice
index可以为负值,表示从集合结尾开始索引。s.splice(-2)表示倒数第二个元素开始拼接。
const { List } = require('immutable')
List([ 'a', 'b', 'c', 'd' ]).splice(1, 2, 'q', 'r', 's')
// List [ "a", "q", "r", "s", "d" ]
flatten()
压平嵌套的集合。
flatten(depth?: number): Collection<any, any>
flatten(shallow?: boolean): Collection<any, any>
继承自
Collection#flatten
默认会深度地经常压平集合操作,返回一个同类型的集合。可以指定depth为压平深度或者是否深度压平(为true表示仅进行一层的浅层压平)。如果深度为0(或者shllow:false)将会深层压平。
压平仅会操作其他集合,数组和对象不会进行此操作。
注意:flatten(true)操作是在集合上进行,同时返回一个集合。
查找
indexOf()
返回集合中第一个与所提供的搜索值匹配的索引,无匹配值则返回-1。
indexOf(searchValue: T): number
继承自
Collection.Indexed#indexOf
lastIndexOf()
返回集合中最后一个与所提供的搜索值匹配的索引,无匹配值则返回-1。
lastIndexOf(searchValue: T): number
继承自
Collection.Indexed#lastIndexOf
findIndex()
返回集合中第一个符合与所提供的断言的索引,均不符合则返回-1。
findIndex(
predicate: (value: T, index: number, iter: this) => boolean,
context?: any
): number
继承自
Collection.Indexed#findIndex
findLastIndex()
返回集合中最后一个符合与所提供的断言的索引,均不符合则返回-1。
findLastIndex(
predicate: (value: T, index: number, iter: this) => boolean,
context?: any
): number
继承自
Collection.Indexed#findLastIndex
find()
返回集合中第一个符合与所提供的断言的值。
find(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#find
findLast()
返回集合中最后一个符合与所提供的断言的值。
findLast(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#findLast
注意:predicate将会逆序地在每个值上调用。
findEntry()
返回第一个符合所提供断言的值的[key, value]。
findEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findEntry
findLastEntry()
返回最后一个符合所提供断言的值的[key, value]。
findLastEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findLastEntry
注意:predicate将会逆序地在每个值上调用。
findKey()
返回第一个predicate返回为true的键。
findKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findKey
findLastKey()
返回最后一个predicate返回为true的键。
findLastKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findLastKey
注意:predicate将会逆序地在每个值上调用。
keyOf()
返回与提供的搜索值关联的键,或者undefined。
keyOf(searchValue: T): number | undefined
继承自
Collection#keyOf
lastKeyOf()
返回最后一个与提供的搜索值关联的键或者undefined。
lastKeyOf(searchValue: T): number | undefined
继承自
Collection#lastKeyOf
max()
返回集合中最大的值。如果有多个值比较为相等,那么将返回第一个。
max(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#max
comparator的使用方法与Collection#sort是一样的,如果未提供那么默认的比较为>。
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么max将会独立于输入的顺序。默认的比较器>只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
maxBy()
和max类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
maxBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#maxBy
例
hitters.maxBy(hitter => hitter.avgHits)
min()
返回集合中最小的值,如果有多个值比较为相等,将会返回第一个。
min(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#min
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么min将会独立于输入的顺序。默认的比较器<只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
minBy()
和min类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
minBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#minBy
例
hitters.minBy(hitter => hitter.avgHits)
等值比较
equals()
如果当前集合和另一个集合比较为相等,那么返回true,是否相等由Immutable.is()定义。
equals(other: any): boolean
继承自
Collection#equals
注意:此方法与Immutable.is(this, other)等效,提供此方法是为了方便能够链式地使用。
hashCode()
计算并返回这个集合的哈希值。
hashCode(): number
继承自
Collection#hashCode
集合的hashCode用于确定两个集合的相等性,在添加到Set或者被作为Map的键值时用于检测两个实例是否相等而会被使用到。
const a = List([ 1, 2, 3 ]);
const b = List([ 1, 2, 3 ]);
assert(a !== b); // different instances
const set = Set([ a ]);
assert(set.has(b) === true);
当两个值的hashCode相等时,并不能完全保证他们是相等的,但当他们的hashCode不同时,他们一定是不等的。
读取深层数据
getIn()
返回根据提供的路径或者索引搜索到的嵌套的值。
getIn(searchKeyPath: Iterable<any>, notSetValue?: any): any
继承自
Collection#getIn
hasIn()
根据提供的路径或者索引检测该处是否设置了值。
hasIn(searchKeyPath: Iterable<any>): boolean
继承自
Collection#hasIn
转换为集合
toMap()
将此集合转换为Map,如果键不可哈希,则抛弃。
toMap(): Map<number, T>
继承自
Collection#toMap
注意:这和Map(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toOrderedMap()
将此集合转换为Map,保留索引的顺序。
toOrderedMap(): OrderedMap<number, T>
继承自
Collection#toOrderedMap
注意:这和OrderedMap(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toSet()
将此集合转换为Set,如果值不可哈希,则抛弃。
toSet(): Set<T>
继承自
Collection#toSet
注意:这和Set(this)等效,为了能够方便的进行链式调用而提供。
toOrderSet()
将此集合转换为Set,保留索引的顺序。
toOrderedSet(): OrderedSet<T>
继承自
Collection#toOrderedSet
注意:这和OrderedSet(this.valueSeq())等效,为了能够方便的进行链式调用而提供。
toList()
将此集合转换为List,丢弃键值。
toList(): List<T>
继承自
Collection#toList
此方法和List(collection)类似,为了能够方便的进行链式调用而提供。然而,当在Map或者其他有键的集合上调用时,collection.toList()会丢弃键值,同时创建一个只有值的list,而List(collection)使用传入的元组创建list。
const { Map, List } = require('immutable')
var myMap = Map({ a: 'Apple', b: 'Banana' })
List(myMap) // List [ [ "a", "Apple" ], [ "b", "Banana" ] ]
myMap.toList() // List [ "Apple", "Banana" ]
toStack()
将此集合转换为Stack,丢弃键值,抛弃不可哈希的值。
toStack(): Stack<T>
注意:这和Stack(this)等效,为了能够方便的进行链式调用而提供。
迭代器
keys()
一个关于Collection键的迭代器。
keys(): IterableIterator<number>
继承自
Collection#keys
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用keySeq来满足需求。
values()
一个关于Collection值的迭代器。
values(): IterableIterator<T>
继承自
Collection#values
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用valueSeq来满足需求。
entries()
一个关于Collection条目的迭代器,是[ key, value ]这样的元组数据。
entries(): IterableIterator<[number, T]>
继承自
Collection#entries
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用entrySeq来满足需求。
集合(Seq)
keySeq()
返回一个新的Seq.Indexed,其包含这个集合的键值。
keySeq(): Seq.Indexed<number>
继承自
Collection#keySeq
valueSeq()
返回一个新的Seq.Indexed,其包含这个集合的所有值。
valueSeq(): Seq.Indexed<T>
继承自
Collection#valueSeq
entrySeq()
返回一个新的Seq.Indexed,其为[key, value]这样的元组。
entrySeq(): Seq.Indexed<[number, T]>
继承自
Collection#entrySeq
副作用
forEach()
sideEffect将会对集合上每个元素执行。
forEach(
sideEffect: (value: T, key: number, iter: this) => any,
context?: any
): number
继承自
Collection#forEach
与Array#forEach不同,任意一个sideEffect返回false都会停止循环。函数将返回所有参与循环的元素(包括最后一个返回false的那个)。
创建子集
slice()
返回一个新的相同类型的相当于原集合指定范围的元素集合,包含开始索引但不包含结束索引位置的值。
slice(begin?: number, end?: number): this
继承自
Collection#slice
如果起始值为负,那么表示从集合结束开始查找。例如slice(-2)返回集合最后两个元素。如果没有提供,那么新的集合将会从最开始那个元素开始。
如果终止值为负,表示从集合结束开始查找。例如silice(0, -1)返回除集合最后一个元素外所有元素。如果没提供,新的集合将会包含到原集合最后一个元素。
如果请求的子集与原集合相等,那么将会返回原集合。
rest()
返回一个不包含原集合第一个元素的新的同类型的集合。
rest(): this
继承自
Collection#rest
butLast()
返回一个不包含原集合最后一个元素的新的同类型的集合。
butLast(): this
继承自
Collection#butLast
skip()
返回一个不包含原集合从头开始amount个数元素的新的同类型集合。
skip(amount: number): this
继承自
Collection#skip
skipLast()
返回一个不包含原集合从结尾开始amount个数元素的新的同类型集合。
skipLast(amount: number): this
继承自
Collection#skipLast
skipWhile()
返回一个原集合从predicate返回false那个元素开始的新的同类型集合。
skipWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipWhile(x => x.match(/g/))
// List [ "cat", "hat", "god" ]
skipUntil()
返回一个原集合从predicate返回true那个元素开始的新的同类型集合。
skipUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipUntil(x => x.match(/hat/))
// List [ "hat", "god"" ]
take()
返回一个包含原集合从头开始的amount个元素的新的同类型集合。
take(amount: number): this
继承自
Collection#take
takeLast()
返回一个包含从原集合结尾开始的amount个元素的新的同类型集合。
takeLast(amount: number): this
继承自
Collection#take
takeWhile()
返回一个包含原集合从头开始的prediacte返回true的那些元素的新的同类型集合。
takeWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeWhile(x => x.match(/o/))
// List [ "dog", "frog" ]
takeUntil()
返回一个包含原集合从头开始的prediacte返回false的那些元素的新的同类型集合。
takeUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeUntil(x => x.match(/at/))
// List [ "dog", "frog" ]
减少值
reduce()
将传入的方法reducer在集合每个元素上调用并传递缩减值,以此来缩减集合的值。
reduce<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduce<R>(reducer: (reduction: T | R, value: T, key: number, iter: this) => R): R
继承自
Collection#reduce
见
Array#reduce
如果initialReduction未提供,那么将会使用集合第一个元素。
reduceRight()
逆向地缩减集合的值(从结尾开始)。
reduceRight<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduceRight<R>(
reducer: (reduction: T | R, value: T, key: number, iter: this) => R
): R
继承自
Collection#reduceRight
注意:与this.reverse().reduce()等效,为了与Array#reduceRight看齐而提供。
every()
当集合中所有元素predicate都判定为true时返回ture。
every(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#every
some()
当集合中任意元素predicate判定为true时返回ture。
some(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#some
join()
将值连接为字符串,并且在每两个值之间插入分割。默认分隔为","。
join(separator?: string): string
继承自
Collection#join
isEmpty()
当集合不包含值时返回true。
isEmpty(): boolean
继承自
Collection#isEmpty
对于惰性Seq,isEmpty会对他经常迭代来确定是否为空。至少会迭代一次。
count()
返回集合的大小。
count(): number
count(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number
继承自
Collection#count
不管此集合是否惰性地确定大小(某些Seq不能),这个方法将总是返回正确的大小。如果必要,他将会评估一个惰性的Seq。
如果predicate提供了,方法返回的数量将是集合中predicate返回true的元素个数。
countBy()
返回Seq.Keyed的数量,由grouper方法将值分组。
countBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Map<G, number>
注意:这不是一个惰性操作。
对比
isSubset()
如果iter包含集合中所有元素则返回true。
isSubset(iter: Iterable<T>): boolean
继承自
Collection#isSubset
isSuperset()
如果集合包含iter中所有元素则返回true。
isSuperset(iter: Iterable<T>): boolean
继承自
Collection#isSuperset
Map
不可变Map是无序的Collection.keyed的(key, value)键值对,具有O(log32 N)读取复杂度和O(log32 N)持久化复杂度。
class Map<K, V> extends Collection.Keyed<K, V>
Map的迭代顺序的不确定的,但是是稳定的。多次迭代同一个Map,迭代顺序将会相同。
Map的键可以为任意类型,使用Immutable.is来确定相等性。这将允许使用任意值(包括NaN)来作为键。
由于Immutable.is是确定对比值语义上的相等性,不可变集合也会被对待为值,所以任何不可变集合都可以作为键来使用。
const { Map, List } = require('immutable');
Map().set(List([ 1 ]), 'listofone').get(List([ 1 ]));
// 'listofone'
JS对象也可以作为值,但是将会使用严格地相等来对比键的相等性。所以两个看起来一样的对象将会是两个不同的键。
构造器
Map()
创建一个新的不可变Map。
Map<K, V>(collection: Iterable<[K, V]>): Map<K, V>
Map<T>(collection: Iterable<Iterable<T>>): Map<T, T>
Map<V>(obj: {[key: string]: V}): Map<string, V>
Map<K, V>(): Map<K, V>
Map(): Map<any, any>
用提供的Collection.Keyed或者JS对象创建相同的键值集合或者期望的[K, V]元组集合。
const { Map } = require('immutable')
Map({ key: "value" })
Map([ [ "key", "value" ] ])
记住,当使用JS对象来创建不可变Map时,尽管不可变数组允许任意类型值作为键,即使使用无引号的缩写方式,JS对象的属性将会对待为字符串。
let obj = { 1: "one" }
Object.keys(obj) // [ "1" ]
obj["1"] // "one"
obj[1] // "one"
let map = Map(obj)
map.get("1") // "one"
map.get(1) // undefined
JS对象的属性键值将首先被装换为字符串,但由于不可变数组的键可以为任意类型,所以get()的参数将不会改变。
静态方法
Map.isMap()
但提供的值为Map时返回true。
Map.isMap(maybeMap: any): boolean
例
const { Map } = require('immutable')
Map.isMap({}) // false
Map.isMap(Map()) // true
成员
size
size
持久化修改
set()
返回一个在原Map基础上包含了新的键值对的新Map。如果key在原函数中已经有相等的存在,那么他将会被替换。
set(key: K, value: V): this
例
const { Map } = require('immutable')
const originalMap = Map()
const newerMap = originalMap.set('key', 'value')
const newestMap = newerMap.set('key', 'newer value')
originalMap
// Map {}
newerMap
// Map { "key": "value" }
newestMap
// Map { "key": "newer value" }
注意:set可以在withMutations中使用。
delete()
返回一个新的不包含key的新Map。
delete(key: K): this
别名
remove()
注意:delete在IE8中不能安全地使用,提供是为了镜像ES6中集合的API。
const { Map } = require('immutable')
const originalMap = Map({
key: 'value',
otherKey: 'other value'
})
// Map { "key": "value", "otherKey": "other value" }
originalMap.delete('otherKey')
// Map { "key": "value" }
注意:delete可以在withMutations中使用。
deleteAll()
返回一个不包含所有提供的key的新Map。
deleteAll(keys: Iterable<K>): this
别名
removeAll()
示例
const { Map } = require('immutable')
const names = Map({ a: "Aaron", b: "Barry", c: "Connor" })
names.deleteAll([ 'a', 'c' ])
// Map { "b": "Barry" }
注意:deleteAll可以在withMutations中使用。
clear()
返回一个不包含任何键或值的新Map。
clear(): this
示例
const { Map } = require('immutable')
Map({ key: 'value' }).clear()
// Map {}
注意:clear可以在withMutations中使用。
update()
将key对应的值传入updater方法,使用此方法返回的值设置返回的新的Map对应位置的值。
update(key: K, notSetValue: V, updater: (value: V) => V): this
update(key: K, updater: (value: V) => V): this
update<R>(updater: (value: this) => R): R
重载
Collection#update
与map.set(key, updater(map.get(key)))效果类似。
const { Map } = require('immutable')
const aMap = Map({ key: 'value' })
const newMap = aMap.update('key', value => value + value)
// Map { "key": "valuevalue" }
这是最常用与在结构化的数据集合上的方法。例如,为了能够在一个层叠的List上进行.push()操作,update和push会同时使用。
const aMap = Map({ nestedList: List([ 1, 2, 3 ]) })
const newMap = aMap.update('nestedList', list => list.push(4))
// Map { "nestedList": List [ 1, 2, 3, 4 ] }
当提供了notSetValue,当Map中键对应位置未设置值时他会被提供给updater方法。
const aMap = Map({ key: 'value' })
const newMap = aMap.update('noKey', 'no value', value => value + value)
// Map { "key": "value", "noKey": "no valueno value" }
如果updater返回了与原数据相同的值,那么Map将不会被改变。即使提供了notSetValue也是一样。
const aMap = Map({ apples: 10 })
const newMap = aMap.update('oranges', 0, val => val)
// Map { "apples": 10 }
assert(newMap === map);
在ES2015或更高的代码环境中,不建议使用notSetValue来支持函数变量默认值。这有助于避免与上述功能有任何潜在的混淆。
这是与默认写法不同的写法将出现的结果的例子:
const aMap = Map({ apples: 10 })
const newMap = aMap.update('oranges', (val = 0) => val)
// Map { "apples": 10, "oranges": 0 }
如果没提供键,则会返回updater的返回值。
const aMap = Map({ key: 'value' })
const result = aMap.update(aMap => aMap.get('key'))
// "value"
这将是一个很有用的方法来将两个普通方法链式调用。RxJS中为"let",lodash中为"thru"。
function sum(collection) {
return collection.reduce((sum, x) => sum + x, 0)
}
Map({ x: 1, y: 2, z: 3 })
.map(x => x + 1)
.filter(x => x % 2 === 0)
.update(sum)
// 6
注意:update(key)可以在withMutations中使用。
merge()
返回一个新的Map由原Map合并了提供的集合(或者JS对象)。换而言之,这个方法将每个集合中的所有元素都设置到了新的Map。
merge(...collections: Array<Collection<K, V> | {[key: string]: V}>): this
如果提供的用来merge的值不是一个集合(isCollection返回false)那么在合并之前它将会被fromJS深度地转换。然后,如果提供的值是一个集合,但包含了非集合的JS对象或数组,这些嵌套值将会被保留。
const { Map } = require('immutable')
const one = Map({ a: 10, b: 20, c: 30 })
const two = Map({ b: 40, a: 50, d: 60 })
one.merge(two) // Map { "a": 50, "b": 40, "c": 30, "d": 60 }
two.merge(one) // Map { "b": 20, "a": 10, "d": 60, "c": 30 }
注意:merge可以在withMutations中使用。
mergeWith()
和mgere()类似,mergeWith()将原集合与提供的集合(或者JS对象)合并返回为新的Map,当它能使用merge来处理冲突。
mergeWith(
merger: (oldVal: V, newVal: V, key: K) => V,
...collections: Array<Collection<K, V> | {[key: string]: V}>
): this
例
const { Map } = require('immutable')
const one = Map({ a: 10, b: 20, c: 30 })
const two = Map({ b: 40, a: 50, d: 60 })
one.mergeWith((oldVal, newVal) => oldVal / newVal, two)
// { "a": 0.2, "b": 0.5, "c": 30, "d": 60 }
two.mergeWith((oldVal, newVal) => oldVal / newVal, one)
// { "b": 2, "a": 5, "d": 60, "c": 30 }
注意:mergeWith可以在withMutations中使用。
mergeDeep()
和merge()类似,但当两个集合冲突时,依然会合并他们,并且能深层地处理嵌套。
const { Map } = require('immutable')
const one = Map({ a: Map({ x: 10, y: 10 }), b: Map({ x: 20, y: 50 }) })
const two = Map({ a: Map({ x: 2 }), b: Map({ y: 5 }), c: Map({ z: 3 }) })
one.mergeDeep(two)
// Map {
// "a": Map { "x": 2, "y": 10 },
// "b": Map { "x": 20, "y": 5 },
// "c": Map { "z": 3 }
// }
注意:mergeDeep可以在withMutations中使用。
mergeDeepWith()
和mergeDeep()类似,但当两个非集合冲突时,使用merger来觉定结果。
mergeDeepWith(
merger: (oldVal: V, newVal: V, key: K) => V,
...collections: Array<Collection<K, V> | {[key: string]: V}>
): this
例
const { Map } = require('immutable')
const one = Map({ a: Map({ x: 10, y: 10 }), b: Map({ x: 20, y: 50 }) })
const two = Map({ a: Map({ x: 2 }), b: Map({ y: 5 }), c: Map({ z: 3 }) })
one.mergeDeepWith((oldVal, newVal) => oldVal / newVal, two)
// Map {
// "a": Map { "x": 5, "y": 10 },
// "b": Map { "x": 20, "y": 10 },
// "c": Map { "z": 3 }
// }
注意:mergeDeepWith可以在withMutations中使用。
深度持久化
setIn()
在原Map的keyPath位置设置值为value并返回为新Map。如果keyPath位置无值,那么新的不可变Map将会创建此位置的值。
setIn(keyPath: Iterable<any>, value: any): this
例
const { Map } = require('immutable')
const originalMap = Map({
subObject: Map({
subKey: 'subvalue',
subSubObject: Map({
subSubKey: 'subSubValue'
})
})
})
const newMap = originalMap.setIn(['subObject', 'subKey'], 'ha ha!')
// Map {
// "subObject": Map {
// "subKey": "ha ha!",
// "subSubObject": Map { "subSubKey": "subSubValue" }
// }
// }
const newerMap = originalMap.setIn(
['subObject', 'subSubObject', 'subSubKey'],
'ha ha ha!'
)
// Map {
// "subObject": Map {
// "subKey": "ha ha!",
// "subSubObject": Map { "subSubKey": "ha ha ha!" }
// }
// }
如果指定位置存在值,但没有.set()方法(如Map和List),此时将会抛出异常。
注意:setIn可以在withMutations中使用。
deleteIn()
返回一个移除了原MapkeyPath位置的新Map。如果keyPath处无值,那么将不会发生改变。
deleteIn(keyPath: Iterable<any>): this
别名
removeIn()
注意:removeIn可以在withMutations中使用。
updateIn()
在指定索引位置调用updater,并返回为新Map。
updateIn(
keyPath: Iterable<any>,
notSetValue: any,
updater: (value: any) => any
): this
updateIn(keyPath: Iterable<any>, updater: (value: any) => any): this
这是经常会在层叠的数据集合上使用的方法。如,为了在层叠的List上进行push()操作,updateIn和push会同时使用:
const { Map, List } = require('immutable')
const map = Map({ inMap: Map({ inList: List([ 1, 2, 3 ]) }) })
const newMap = map.updateIn(['inMap', 'inList'], list => list.push(4))
// Map { "inMap": Map { "inList": List [ 1, 2, 3, 4 ] } }
如果keyPath位置没有值,那么不可变Map将会在此位置创建这个键。如果keyPath指定位置为定义值,那么updater方法将会使用notSetValue来调用,如果notSetValue未提供,那么将会传入undefined。
const map = Map({ a: Map({ b: Map({ c: 10 }) }) })
const newMap = map.updateIn(['a', 'b', 'c'], val => val * 2)
// Map { "a": Map { "b": Map { "c": 20 } } }
如果updater方法返回了和原值一样的值,那么将不会发生改变,即使提供了notSetValue。
const map = Map({ a: Map({ b: Map({ c: 10 }) }) })
const newMap = map.updateIn(['a', 'b', 'x'], 100, val => val)
// Map { "a": Map { "b": Map { "c": 10 } } }
assert(newMap === map)
当处在ES2015或者更高环境下,不推荐使用notSetValue来实现函数变量默认值。这有助于避免任何可能导致与上述特性不符的困惑。
这里提供一个设置了函数变量默认值的例子,以展示这种写法将产生的不同表现:
const map = Map({ a: Map({ b: Map({ c: 10 }) }) })
const newMap = map.updateIn(['a', 'b', 'x'], (val = 100) => val)
// Map { "a": Map { "b": Map { "c": 10, "x": 100 } } }
如果指定位置存在值,但没有.set()方法(如Map和List),此时将会抛出异常。
mergeIn()
一个updateIn和merge的结合体,会一个新的Map在指定路径那个点上执行合并操作。换而言之,这两条语句效果相同:
map.updateIn(['a', 'b', 'c'], abc => abc.merge(y))
map.mergeIn(['a', 'b', 'c'], y)
mergeIn(keyPath: Iterable<any>, ...collections: Array<any>): this
注意:mergeIn可以在withMutations中使用。
mergeDeepIn()
一个updateIn和mergeDeep的结合体,会一个新的Map在指定路径那个点上执行合并操作。换而言之,这两条语句效果相同:
map.updateIn(['a', 'b', 'c'], abc => abc.mergeDeep(y))
map.mergeDeepIn(['a', 'b', 'c'], y)
mergeDeepIn(keyPath: Iterable<any>, ...collections: Array<any>): this
注意:mergeDeepIn可以在withMutations中使用。
暂时改变
withMutations()
每次你调用以上方法,它都会新建一个不可变Map。如果一个纯函数调用了多个上述方法来产生需要的值,那么产生的这些中间不可变Map将会对性能和内存造成负担。
withMutations(mutator: (mutable: this) => any): this
如果你需要进行一系列变化来产生新的不可变Map,用withMutations()对此Map创造一个临时的可变拷贝的方式来进程变化操作,可以极大地提升性能。事实上这是像merge这样复杂地操作实现地方式。
以下例子将会创造2个而不是4个新Map:
const { Map } = require('immutable')
const map1 = Map()
const map2 = map1.withMutations(map => {
map.set('a', 1).set('b', 2).set('c', 3)
})
assert(map1.size === 0)
assert(map2.size === 3)
注意:不是所有方法都可以在可变的集合或者是在withMutations中使用!查看每个方法的文档可以确认他是否能够安全地使用withMutations。
asMutable()
另外一种避免产生中间值的不可变Map的方式是创建一个这个集合的可变拷贝。可变拷贝总是返回this,因此不要用他们来进行比较。你的函数不要将这个可变集合返回出去,请只在函数内使用它来构建新的集合。如果可能的话使用withMutations,因为他提供了更易用地API。
asMutable(): this
注意:如果一个集合已经是可变的,asMutable将会返回他本身。
注意:不是所有方法都可以在可变的集合或者是在withMutations中使用!查看每个方法的文档可以确认他是否能够安全地使用withMutations。
asImmutable()
与asMutable谓之阳所对应的阴。因为他作用于可变集合,此操作是可变地并返回自身。一旦执行,这个可变的拷贝将会变成不可变的,这样即可将他安全的从方法中返回出去。
asImmutable(): this
系列算法
concat()
将传入的集合与当前集合合并返回为新的Map。
concat<KC, VC>(...collections: Array<Iterable<[KC, VC]>>): Map<K | KC, V | VC>
concat<C>(...collections: Array<{[key: string]: C}>): Map<K | string, V | C>
继承
Collection#concat
map()
使用mapper遍历所有值,将其返回的值返回为新的Map。
map<M>(mapper: (value: V, key: K, iter: this) => M, context?: any): Map<K, M>
继承自
Collection#map
例
Map({ a: 1, b: 2 }).map(x => 10 * x)
// Map { a: 10, b: 20 }
注意:map()始终返回一个新的实例,即使它产生的结果与原Map一致。
mapEntries()
mapEntries<KM, VM>(
mapper: (entry: [K, V], index: number, iter: this) => [KM, VM],
context?: any
): Map<KM, VM>
继承自
Collection.Keyed#mapEntries
见
Collection.Keyed.mapEntries
flatMap()
返回一个新的扁平化的Map。
flatMap<KM, VM>(
mapper: (value: V, key: K, iter: this) => Iterable<[KM, VM]>,
context?: any
): Map<KM, VM>
继承自
Collection#flatMap
与data.map(...).flatten(true)效果一致。
filter()
返回只有由方法predicate返回为true的那些条目组成的新的Map。
filter<F>(
predicate: (value: V, key: K, iter: this) => boolean,
context?: any
): Map<K, F>
filter(predicate: (value: V, key: K, iter: this) => any, context?: any): this
重载
Collection#filter
注意:filter()总是返回一个新的实例,即使没有过滤任何值。
filterNot()
返回一个同类型的集合,只包含predicate方法返回为false的那些值。
filterNot(
predicate: (value: V, key: K, iter: this) => boolean,
context?: any
): this
继承自
Collection#filterNot
例
const { Map } = require('immutable')
Map({ a: 1, b: 2, c: 3, d: 4}).filterNot(x => x % 2 === 0)
// Map { "a": 1, "c": 3 }
注意:filterNot()总是返回一个新的实例,即使没有过滤任何值。
reverse()
返回一个同类型逆序的集合。
reverse(): this
继承自
Collection#reverse
sort()
返回一个新的同类型包含相同条目由comparator排序的新的集合。
sort(comparator?: (valueA: V, valueB: V) => number): this
继承自
Collection#sort
如果comparator未提供,默认比较器为<和>。
comparator(valueA, valueB):
- 返回值为
0这个元素将不会被交换。 - 返回值为
-1(或者任意负数)valueA将会移到valueB之前。 - 返回值为
1(或者任意正数)valueA将会移到valueB之后。 - 为空,这将会返回相同的值和顺序。
当被排序的集合没有定义顺序,那么将会返回同等的有序集合。比如map.sort()将返回OrderedMap。
const { Map } = require('immutable')
Map({ "c": 3, "a": 1, "b": 2 }).sort((a, b) => {
if (a < b) { return -1; }
if (a > b) { return 1; }
if (a === b) { return 0; }
});
// OrderedMap { "a": 1, "b": 2, "c": 3 }
注意:sort()总是返回一个新的实例,即使它没有改变排序。
sortBy()
与sort类似,但能接受一个comparatorValueMapper方法,它允许通过更复杂的方式进行排序:
sortBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): this
继承自
Collection#sortBy
例
hitters.sortBy(hitter => hitter.avgHits)
注意:sortBy()总是返回一个新的实例,即使它没有改变排序。
groupBy()
返回一个Collection.Keyeds的Collection.keyed,由传入的grouper方法分组。
groupBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Seq.Keyed<G, Collection<number, T>>
继承自
Collection#groupBy
const { List, Map } = require('immutable')
const listOfMaps = List([
Map({ v: 0 }),
Map({ v: 1 }),
Map({ v: 1 }),
Map({ v: 0 }),
Map({ v: 2 })
])
const groupsOfMaps = listOfMaps.groupBy(x => x.get('v'))
// Map {
// 0: List [ Map{ "v": 0 }, Map { "v": 0 } ],
// 1: List [ Map{ "v": 1 }, Map { "v": 1 } ],
// 2: List [ Map{ "v": 2 } ],
// }
转换为JavaScript类型
toJS()
深层地将这个有序的集合转换转换为原生JS数组。
toJS(): Array<any>
继承自
Collection.Index#toJS
toJSON()
浅转换这个有序的集合为原生JS数组。
toJSON(): Array<any>
继承自
Collection.Index#toJSON
toArray()
浅转换这个有序的集合为原生JS数组并且丢弃key。
toArray(): Array<any>
继承自
Collection#toArray
toObject()
浅转换这个有序的集合为原生JS对象。
toObject(): {[key: string]: V}
继承自
Collection#toObject
键会被转换为String。
转换为Seq
toSeq()
返回Seq.Indexed。
toSeq(): Seq.Indexed<T>
继承自
Collection.Indexed#toSeq
fromEntrySeq()
如果这个集合是由[key, value]这种原组构成的,那么这将返回这些原组的Seq.Keyed。
fromEntrySeq(): Seq.Keyed<any, any>
继承自
Collection.Index#fromEntrySeq
toKeyedSeq()
从这个集合返回一个Seq.Keyed,其中索引将视作key。
toKeyedSeq(): Seq.Keyed<number, T>
继承自
Collection#toKeyedSeq
如果你想对Collection.Indexed操作返回一组[index, value]对,这将十分有用。
返回的Seq将与Colleciont有相同的索引顺序。
const { Seq } = require('immutable')
const indexedSeq = Seq([ 'A', 'B', 'C' ])
// Seq [ "A", "B", "C" ]
indexedSeq.filter(v => v === 'B')
// Seq [ "B" ]
const keyedSeq = indexedSeq.toKeyedSeq()
// Seq { 0: "A", 1: "B", 2: "C" }
keyedSeq.filter(v => v === 'B')
// Seq { 1: "B" }
toIndexedSeq()
将这个集合的值丢弃键(key)返回为Seq.Indexed。
toIndexedSeq(): Seq.Indexed<T>
继承自
Collection#toIndexedSeq
toSetSeq()
将这个集合的值丢弃键(key)返回为Seq.Set。
toSetSeq(): Seq.Set<T>
继承自
Collection#toSetSeq
系列函数
flip()
返回一个新的同类型Collection.Keyed,它将原Map的键和值进行交换。
flip(): this
继承自
Collection.Keyed#flip
例
const { Map } = require('immutable')
Map({ a: 'z', b: 'y' }).flip()
// Map { "z": "a", "y": "b" }
[Symbol.iterator]()
[Symbol.iterator](): IterableIterator<[K, V]>
继承自
Collection.Keyed#[Symbol.iterator]
等值比较
equals()
如果当前集合和另一个集合比较为相等,那么返回true,是否相等由Immutable.is()定义。
equals(other: any): boolean
继承自
Collection#equals
注意:此方法与Immutable.is(this, other)等效,提供此方法是为了方便能够链式地使用。
hashCode()
计算并返回这个集合的哈希值。
hashCode(): number
继承自
Collection#hashCode
集合的hashCode用于确定两个集合的相等性,在添加到Set或者被作为Map的键值时用于检测两个实例是否相等而会被使用到。
const a = List([ 1, 2, 3 ]);
const b = List([ 1, 2, 3 ]);
assert(a !== b); // different instances
const set = Set([ a ]);
assert(set.has(b) === true);
当两个值的hashCode相等时,并不能完全保证他们是相等的,但当他们的hashCode不同时,他们一定是不等的。
读值
get()
返回提供的索引位置关联的值,或者当提供的索引越界时返回所提供的notSetValue。
get<NSV>(index: number, notSetValue: NSV): T | NSV
get(index: number): T | undefined
继承自
Collection.Indexed#get
index可以为负值,表示从集合尾部开始索引。s.get(-1)取得集合最后一个元素。
has()
使用Immutable.is判断key值是否在Collection中。
has(key: number): boolean
继承自
Collection#has
includes()
使用Immutable.is判断value值是否在Collection中。
includes(value: T): boolean
继承自
Collection#includes
first()
取得集合第一个值。
first(): T | undefined
继承自
Collection#first
last()
取得集合第一个值。
last(): T | undefined
继承自
Collection#last
读取深层数据
getIn()
返回根据提供的路径或者索引搜索到的嵌套的值。
getIn(searchKeyPath: Iterable<any>, notSetValue?: any): any
继承自
Collection#getIn
hasIn()
根据提供的路径或者索引检测该处是否设置了值。
hasIn(searchKeyPath: Iterable<any>): boolean
继承自
Collection#hasIn
转换为集合
toMap()
将此集合转换为Map,如果键不可哈希,则抛弃。
toMap(): Map<number, T>
继承自
Collection#toMap
注意:这和Map(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toOrderedMap()
将此集合转换为Map,保留索引的顺序。
toOrderedMap(): OrderedMap<number, T>
继承自
Collection#toOrderedMap
注意:这和OrderedMap(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toSet()
将此集合转换为Set,如果值不可哈希,则抛弃。
toSet(): Set<T>
继承自
Collection#toSet
注意:这和Set(this)等效,为了能够方便的进行链式调用而提供。
toOrderSet()
将此集合转换为Set,保留索引的顺序。
toOrderedSet(): OrderedSet<T>
继承自
Collection#toOrderedSet
注意:这和OrderedSet(this.valueSeq())等效,为了能够方便的进行链式调用而提供。
toList()
将此集合转换为List,丢弃键值。
toList(): List<T>
继承自
Collection#toList
此方法和List(collection)类似,为了能够方便的进行链式调用而提供。然而,当在Map或者其他有键的集合上调用时,collection.toList()会丢弃键值,同时创建一个只有值的list,而List(collection)使用传入的元组创建list。
const { Map, List } = require('immutable')
var myMap = Map({ a: 'Apple', b: 'Banana' })
List(myMap) // List [ [ "a", "Apple" ], [ "b", "Banana" ] ]
myMap.toList() // List [ "Apple", "Banana" ]
toStack()
将此集合转换为Stack,丢弃键值,抛弃不可哈希的值。
toStack(): Stack<T>
注意:这和Stack(this)等效,为了能够方便的进行链式调用而提供。
迭代器
keys()
一个关于Collection键的迭代器。
keys(): IterableIterator<number>
继承自
Collection#keys
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用keySeq来满足需求。
values()
一个关于Collection值的迭代器。
values(): IterableIterator<T>
继承自
Collection#values
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用valueSeq来满足需求。
entries()
一个关于Collection条目的迭代器,是[ key, value ]这样的元组数据。
entries(): IterableIterator<[number, T]>
继承自
Collection#entries
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用entrySeq来满足需求。
集合(Seq)
keySeq()
返回一个新的Seq.Indexed,其包含这个集合的键值。
keySeq(): Seq.Indexed<number>
继承自
Collection#keySeq
valueSeq()
返回一个新的Seq.Indexed,其包含这个集合的所有值。
valueSeq(): Seq.Indexed<T>
继承自
Collection#valueSeq
entrySeq()
返回一个新的Seq.Indexed,其为[key, value]这样的元组。
entrySeq(): Seq.Indexed<[number, T]>
继承自
Collection#entrySeq
副作用
forEach()
sideEffect将会对集合上每个元素执行。
forEach(
sideEffect: (value: T, key: number, iter: this) => any,
context?: any
): number
继承自
Collection#forEach
与Array#forEach不同,任意一个sideEffect返回false都会停止循环。函数将返回所有参与循环的元素(包括最后一个返回false的那个)。
创建子集
slice()
返回一个新的相同类型的相当于原集合指定范围的元素集合,包含开始索引但不包含结束索引位置的值。
slice(begin?: number, end?: number): this
继承自
Collection#slice
如果起始值为负,那么表示从集合结束开始查找。例如slice(-2)返回集合最后两个元素。如果没有提供,那么新的集合将会从最开始那个元素开始。
如果终止值为负,表示从集合结束开始查找。例如silice(0, -1)返回除集合最后一个元素外所有元素。如果没提供,新的集合将会包含到原集合最后一个元素。
如果请求的子集与原集合相等,那么将会返回原集合。
rest()
返回一个不包含原集合第一个元素的新的同类型的集合。
rest(): this
继承自
Collection#rest
butLast()
返回一个不包含原集合最后一个元素的新的同类型的集合。
butLast(): this
继承自
Collection#butLast
skip()
返回一个不包含原集合从头开始amount个数元素的新的同类型集合。
skip(amount: number): this
继承自
Collection#skip
skipLast()
返回一个不包含原集合从结尾开始amount个数元素的新的同类型集合。
skipLast(amount: number): this
继承自
Collection#skipLast
skipWhile()
返回一个原集合从predicate返回false那个元素开始的新的同类型集合。
skipWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipWhile(x => x.match(/g/))
// List [ "cat", "hat", "god" ]
skipUntil()
返回一个原集合从predicate返回true那个元素开始的新的同类型集合。
skipUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipUntil(x => x.match(/hat/))
// List [ "hat", "god"" ]
take()
返回一个包含原集合从头开始的amount个元素的新的同类型集合。
take(amount: number): this
继承自
Collection#take
takeLast()
返回一个包含从原集合结尾开始的amount个元素的新的同类型集合。
takeLast(amount: number): this
继承自
Collection#take
takeWhile()
返回一个包含原集合从头开始的prediacte返回true的那些元素的新的同类型集合。
takeWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeWhile(x => x.match(/o/))
// List [ "dog", "frog" ]
takeUntil()
返回一个包含原集合从头开始的prediacte返回false的那些元素的新的同类型集合。
takeUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeUntil(x => x.match(/at/))
// List [ "dog", "frog" ]
组合
flatten()
压平嵌套的集合。
flatten(depth?: number): Collection<any, any>
flatten(shallow?: boolean): Collection<any, any>
继承自
Collection#flatten
默认会深度地经常压平集合操作,返回一个同类型的集合。可以指定depth为压平深度或者是否深度压平(为true表示仅进行一层的浅层压平)。如果深度为0(或者shllow:false)将会深层压平。
压平仅会操作其他集合,数组和对象不会进行此操作。
注意:flatten(true)操作是在集合上进行,同时返回一个集合。
减少值
reduce()
将传入的方法reducer在集合每个元素上调用并传递缩减值,以此来缩减集合的值。
reduce<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduce<R>(reducer: (reduction: T | R, value: T, key: number, iter: this) => R): R
继承自
Collection#reduce
见
Array#reduce
如果initialReduction未提供,那么将会使用集合第一个元素。
reduceRight()
逆向地缩减集合的值(从结尾开始)。
reduceRight<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduceRight<R>(
reducer: (reduction: T | R, value: T, key: number, iter: this) => R
): R
继承自
Collection#reduceRight
注意:与this.reverse().reduce()等效,为了与Array#reduceRight看齐而提供。
every()
当集合中所有元素predicate都判定为true时返回ture。
every(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#every
some()
当集合中任意元素predicate判定为true时返回ture。
some(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#some
join()
将值连接为字符串,并且在每两个值之间插入分割。默认分隔为","。
join(separator?: string): string
继承自
Collection#join
isEmpty()
当集合不包含值时返回true。
isEmpty(): boolean
继承自
Collection#isEmpty
对于惰性Seq,isEmpty会对他经常迭代来确定是否为空。至少会迭代一次。
count()
返回集合的大小。
count(): number
count(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number
继承自
Collection#count
不管此集合是否惰性地确定大小(某些Seq不能),这个方法将总是返回正确的大小。如果必要,他将会评估一个惰性的Seq。
如果predicate提供了,方法返回的数量将是集合中predicate返回true的元素个数。
countBy()
返回Seq.Keyed的数量,由grouper方法将值分组。
countBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Map<G, number>
注意:这不是一个惰性操作。
查找
find()
返回集合中第一个符合与所提供的断言的值。
find(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#find
findLast()
返回集合中最后一个符合与所提供的断言的值。
findLast(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#findLast
注意:predicate将会逆序地在每个值上调用。
findEntry()
返回第一个符合所提供断言的值的[key, value]。
findEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findEntry
findLastEntry()
返回最后一个符合所提供断言的值的[key, value]。
findLastEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findLastEntry
注意:predicate将会逆序地在每个值上调用。
findKey()
返回第一个predicate返回为true的键。
findKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findKey
findLastKey()
返回最后一个predicate返回为true的键。
findLastKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findLastKey
注意:predicate将会逆序地在每个值上调用。
keyOf()
返回与提供的搜索值关联的键,或者undefined。
keyOf(searchValue: T): number | undefined
继承自
Collection#keyOf
lastKeyOf()
返回最后一个与提供的搜索值关联的键或者undefined。
lastKeyOf(searchValue: T): number | undefined
继承自
Collection#lastKeyOf
max()
返回集合中最大的值。如果有多个值比较为相等,那么将返回第一个。
max(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#max
comparator的使用方法与Collection#sort是一样的,如果未提供那么默认的比较为>。
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么max将会独立于输入的顺序。默认的比较器>只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
maxBy()
和max类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
maxBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#maxBy
例
hitters.maxBy(hitter => hitter.avgHits)
min()
返回集合中最小的值,如果有多个值比较为相等,将会返回第一个。
min(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#min
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么min将会独立于输入的顺序。默认的比较器<只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
minBy()
和min类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
minBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#minBy
例
hitters.minBy(hitter => hitter.avgHits)
对比
isSubset()
如果iter包含集合中所有元素则返回true。
isSubset(iter: Iterable<T>): boolean
继承自
Collection#isSubset
isSuperset()
如果集合包含iter中所有元素则返回true。
isSuperset(iter: Iterable<T>): boolean
继承自
Collection#isSuperset
OrderedMap
一种能保证Map内元素的顺序与他们被set()的先后顺序一致的Map类型。
class OrderedMap<K, V> extends Map<K, V>
OrderedMap的迭代表现与ES6Map和JS对象一致。
注意OrderedMap将会比无序Map话费跟多的内存。OrderedMap#set复杂度大概为O(log32 N),但不稳定。
构造器
OrderedMap()
构造一个新的不可变OrderedMap()。
OrderedMap<K, V>(collection: Iterable<[K, V]>): OrderedMap<K, V>
OrderedMap<T>(collection: Iterable<Iterable<T>>): OrderedMap<T, T>
OrderedMap<V>(obj: {[key: string]: V}): OrderedMap<string, V>
OrderedMap<K, V>(): OrderedMap<K, V>
OrderedMap(): OrderedMap<any, any>
用提供的Collection.Keyed或者JS对象创建相同的键值集合或者期望的[K, V]元组集合。
键值对的迭代顺序将会按照提供给构造函数的顺序保存在OrderedMap中。
let newOrderedMap = OrderedMap({key: "value"})
let newOrderedMap = OrderedMap([["key", "value"]])
静态方法
OrderedMap.isOrderedMap()
如果提供的值为OrderedMap,那么会返回true。
OrderedMap.isOrderedMap(maybeOrderedMap: any): boolean
成员
size
size
系列算法
concat()
将传入的集合与当前集合合并返回为新的Map。
concat<KC, VC>(...collections: Array<Iterable<[KC, VC]>>): Map<K | KC, V | VC>
concat<C>(...collections: Array<{[key: string]: C}>): Map<K | string, V | C>
继承
Collection#concat
map()
使用mapper遍历所有值,将其返回的值返回为新的Map。
map<M>(mapper: (value: V, key: K, iter: this) => M, context?: any): Map<K, M>
继承自
Collection#map
例
Map({ a: 1, b: 2 }).map(x => 10 * x)
// Map { a: 10, b: 20 }
注意:map()始终返回一个新的实例,即使它产生的结果与原Map一致。
mapEntries()
mapEntries<KM, VM>(
mapper: (entry: [K, V], index: number, iter: this) => [KM, VM],
context?: any
): Map<KM, VM>
继承自
Collection.Keyed#mapEntries
见
Collection.Keyed.mapEntries
flatMap()
返回一个新的扁平化的Map。
flatMap<KM, VM>(
mapper: (value: V, key: K, iter: this) => Iterable<[KM, VM]>,
context?: any
): Map<KM, VM>
继承自
Collection#flatMap
与data.map(...).flatten(true)效果一致。
filter()
返回只有由方法predicate返回为true的那些条目组成的新的Map。
filter<F>(
predicate: (value: V, key: K, iter: this) => boolean,
context?: any
): Map<K, F>
filter(predicate: (value: V, key: K, iter: this) => any, context?: any): this
重载
Collection#filter
注意:filter()总是返回一个新的实例,即使没有过滤任何值。
filterNot()
返回一个同类型的集合,只包含predicate方法返回为false的那些值。
filterNot(
predicate: (value: V, key: K, iter: this) => boolean,
context?: any
): this
继承自
Collection#filterNot
例
const { Map } = require('immutable')
Map({ a: 1, b: 2, c: 3, d: 4}).filterNot(x => x % 2 === 0)
// Map { "a": 1, "c": 3 }
注意:filterNot()总是返回一个新的实例,即使没有过滤任何值。
reverse()
返回一个同类型逆序的集合。
reverse(): this
继承自
Collection#reverse
sort()
返回一个新的同类型包含相同条目由comparator排序的新的集合。
sort(comparator?: (valueA: V, valueB: V) => number): this
继承自
Collection#sort
如果comparator未提供,默认比较器为<和>。
comparator(valueA, valueB):
- 返回值为
0这个元素将不会被交换。 - 返回值为
-1(或者任意负数)valueA将会移到valueB之前。 - 返回值为
1(或者任意正数)valueA将会移到valueB之后。 - 为空,这将会返回相同的值和顺序。
当被排序的集合没有定义顺序,那么将会返回同等的有序集合。比如map.sort()将返回OrderedMap。
const { Map } = require('immutable')
Map({ "c": 3, "a": 1, "b": 2 }).sort((a, b) => {
if (a < b) { return -1; }
if (a > b) { return 1; }
if (a === b) { return 0; }
});
// OrderedMap { "a": 1, "b": 2, "c": 3 }
注意:sort()总是返回一个新的实例,即使它没有改变排序。
sortBy()
与sort类似,但能接受一个comparatorValueMapper方法,它允许通过更复杂的方式进行排序:
sortBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): this
继承自
Collection#sortBy
例
hitters.sortBy(hitter => hitter.avgHits)
注意:sortBy()总是返回一个新的实例,即使它没有改变排序。
groupBy()
返回一个Collection.Keyeds的Collection.keyed,由传入的grouper方法分组。
groupBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Seq.Keyed<G, Collection<number, T>>
继承自
Collection#groupBy
const { List, Map } = require('immutable')
const listOfMaps = List([
Map({ v: 0 }),
Map({ v: 1 }),
Map({ v: 1 }),
Map({ v: 0 }),
Map({ v: 2 })
])
const groupsOfMaps = listOfMaps.groupBy(x => x.get('v'))
// Map {
// 0: List [ Map{ "v": 0 }, Map { "v": 0 } ],
// 1: List [ Map{ "v": 1 }, Map { "v": 1 } ],
// 2: List [ Map{ "v": 2 } ],
// }
持久化修改
set()
返回一个在原Map基础上包含了新的键值对的新Map。如果key在原函数中已经有相等的存在,那么他将会被替换。
set(key: K, value: V): this
例
const { Map } = require('immutable')
const originalMap = Map()
const newerMap = originalMap.set('key', 'value')
const newestMap = newerMap.set('key', 'newer value')
originalMap
// Map {}
newerMap
// Map { "key": "value" }
newestMap
// Map { "key": "newer value" }
注意:set可以在withMutations中使用。
delete()
返回一个新的不包含key的新Map。
delete(key: K): this
别名
remove()
注意:delete在IE8中不能安全地使用,提供是为了镜像ES6中集合的API。
const { Map } = require('immutable')
const originalMap = Map({
key: 'value',
otherKey: 'other value'
})
// Map { "key": "value", "otherKey": "other value" }
originalMap.delete('otherKey')
// Map { "key": "value" }
注意:delete可以在withMutations中使用。
deleteAll()
返回一个不包含所有提供的key的新Map。
deleteAll(keys: Iterable<K>): this
别名
removeAll()
示例
const { Map } = require('immutable')
const names = Map({ a: "Aaron", b: "Barry", c: "Connor" })
names.deleteAll([ 'a', 'c' ])
// Map { "b": "Barry" }
注意:deleteAll可以在withMutations中使用。
clear()
返回一个不包含任何键或值的新Map。
clear(): this
示例
const { Map } = require('immutable')
Map({ key: 'value' }).clear()
// Map {}
注意:clear可以在withMutations中使用。
update()
将key对应的值传入updater方法,使用此方法返回的值设置返回的新的Map对应位置的值。
update(key: K, notSetValue: V, updater: (value: V) => V): this
update(key: K, updater: (value: V) => V): this
update<R>(updater: (value: this) => R): R
重载
Collection#update
与map.set(key, updater(map.get(key)))效果类似。
const { Map } = require('immutable')
const aMap = Map({ key: 'value' })
const newMap = aMap.update('key', value => value + value)
// Map { "key": "valuevalue" }
这是最常用与在结构化的数据集合上的方法。例如,为了能够在一个层叠的List上进行.push()操作,update和push会同时使用。
const aMap = Map({ nestedList: List([ 1, 2, 3 ]) })
const newMap = aMap.update('nestedList', list => list.push(4))
// Map { "nestedList": List [ 1, 2, 3, 4 ] }
当提供了notSetValue,当Map中键对应位置未设置值时他会被提供给updater方法。
const aMap = Map({ key: 'value' })
const newMap = aMap.update('noKey', 'no value', value => value + value)
// Map { "key": "value", "noKey": "no valueno value" }
如果updater返回了与原数据相同的值,那么Map将不会被改变。即使提供了notSetValue也是一样。
const aMap = Map({ apples: 10 })
const newMap = aMap.update('oranges', 0, val => val)
// Map { "apples": 10 }
assert(newMap === map);
在ES2015或更高的代码环境中,不建议使用notSetValue来支持函数变量默认值。这有助于避免与上述功能有任何潜在的混淆。
这是与默认写法不同的写法将出现的结果的例子:
const aMap = Map({ apples: 10 })
const newMap = aMap.update('oranges', (val = 0) => val)
// Map { "apples": 10, "oranges": 0 }
如果没提供键,则会返回updater的返回值。
const aMap = Map({ key: 'value' })
const result = aMap.update(aMap => aMap.get('key'))
// "value"
这将是一个很有用的用法来将两个普通方法链式调用。RxJS中为"let",lodash中为"thru"。
function sum(collection) {
return collection.reduce((sum, x) => sum + x, 0)
}
Map({ x: 1, y: 2, z: 3 })
.map(x => x + 1)
.filter(x => x % 2 === 0)
.update(sum)
// 6
注意:update(key)可以在withMutations中使用。
merge()
返回一个新的Map由原Map合并了提供的集合(或者JS对象)。换而言之,这个方法将每个集合中的所有元素都设置到了新的Map。
merge(...collections: Array<Collection<K, V> | {[key: string]: V}>): this
如果提供的用来merge的值不是一个集合(isCollection返回false)那么在合并之前它将会被fromJS深度地转换。然后,如果提供的值是一个集合,但包含了非集合的JS对象或数组,这些嵌套值将会被保留。
const { Map } = require('immutable')
const one = Map({ a: 10, b: 20, c: 30 })
const two = Map({ b: 40, a: 50, d: 60 })
one.merge(two) // Map { "a": 50, "b": 40, "c": 30, "d": 60 }
two.merge(one) // Map { "b": 20, "a": 10, "d": 60, "c": 30 }
注意:merge可以在withMutations中使用。
mergeWith()
和mgere()类似,mergeWith()将原集合与提供的集合(或者JS对象)合并返回为新的Map,当它能使用merge来处理冲突。
mergeWith(
merger: (oldVal: V, newVal: V, key: K) => V,
...collections: Array<Collection<K, V> | {[key: string]: V}>
): this
例
const { Map } = require('immutable')
const one = Map({ a: 10, b: 20, c: 30 })
const two = Map({ b: 40, a: 50, d: 60 })
one.mergeWith((oldVal, newVal) => oldVal / newVal, two)
// { "a": 0.2, "b": 0.5, "c": 30, "d": 60 }
two.mergeWith((oldVal, newVal) => oldVal / newVal, one)
// { "b": 2, "a": 5, "d": 60, "c": 30 }
注意:mergeWith可以在withMutations中使用。
mergeDeep()
和merge()类似,但当两个集合冲突时,依然会合并他们,并且能深层地处理嵌套。
const { Map } = require('immutable')
const one = Map({ a: Map({ x: 10, y: 10 }), b: Map({ x: 20, y: 50 }) })
const two = Map({ a: Map({ x: 2 }), b: Map({ y: 5 }), c: Map({ z: 3 }) })
one.mergeDeep(two)
// Map {
// "a": Map { "x": 2, "y": 10 },
// "b": Map { "x": 20, "y": 5 },
// "c": Map { "z": 3 }
// }
注意:mergeDeep可以在withMutations中使用。
mergeDeepWith()
和mergeDeep()类似,但当两个非集合冲突时,使用merger来觉定结果。
mergeDeepWith(
merger: (oldVal: V, newVal: V, key: K) => V,
...collections: Array<Collection<K, V> | {[key: string]: V}>
): this
例
const { Map } = require('immutable')
const one = Map({ a: Map({ x: 10, y: 10 }), b: Map({ x: 20, y: 50 }) })
const two = Map({ a: Map({ x: 2 }), b: Map({ y: 5 }), c: Map({ z: 3 }) })
one.mergeDeepWith((oldVal, newVal) => oldVal / newVal, two)
// Map {
// "a": Map { "x": 5, "y": 10 },
// "b": Map { "x": 20, "y": 10 },
// "c": Map { "z": 3 }
// }
注意:mergeDeepWith可以在withMutations中使用。
深度持久化
setIn()
在原Map的keyPath位置设置值为value并返回为新Map。如果keyPath位置无值,那么新的不可变Map将会创建此位置的值。
setIn(keyPath: Iterable<any>, value: any): this
例
const { Map } = require('immutable')
const originalMap = Map({
subObject: Map({
subKey: 'subvalue',
subSubObject: Map({
subSubKey: 'subSubValue'
})
})
})
const newMap = originalMap.setIn(['subObject', 'subKey'], 'ha ha!')
// Map {
// "subObject": Map {
// "subKey": "ha ha!",
// "subSubObject": Map { "subSubKey": "subSubValue" }
// }
// }
const newerMap = originalMap.setIn(
['subObject', 'subSubObject', 'subSubKey'],
'ha ha ha!'
)
// Map {
// "subObject": Map {
// "subKey": "ha ha!",
// "subSubObject": Map { "subSubKey": "ha ha ha!" }
// }
// }
如果指定位置存在值,但没有.set()方法(如Map和List),此时将会抛出异常。
注意:setIn可以在withMutations中使用。
deleteIn()
返回一个移除了原MapkeyPath位置的新Map。如果keyPath处无值,那么将不会发生改变。
deleteIn(keyPath: Iterable<any>): this
别名
removeIn()
注意:removeIn可以在withMutations中使用。
updateIn()
在指定索引位置调用updater,并返回为新Map。
updateIn(
keyPath: Iterable<any>,
notSetValue: any,
updater: (value: any) => any
): this
updateIn(keyPath: Iterable<any>, updater: (value: any) => any): this
这是经常会在层叠的数据集合上使用的方法。如,为了在层叠的List上进行push()操作,updateIn和push会同时使用:
const { Map, List } = require('immutable')
const map = Map({ inMap: Map({ inList: List([ 1, 2, 3 ]) }) })
const newMap = map.updateIn(['inMap', 'inList'], list => list.push(4))
// Map { "inMap": Map { "inList": List [ 1, 2, 3, 4 ] } }
如果keyPath位置没有值,那么不可变Map将会在此位置创建这个键。如果keyPath指定位置为定义值,那么updater方法将会使用notSetValue来调用,如果notSetValue未提供,那么将会传入undefined。
const map = Map({ a: Map({ b: Map({ c: 10 }) }) })
const newMap = map.updateIn(['a', 'b', 'c'], val => val * 2)
// Map { "a": Map { "b": Map { "c": 20 } } }
如果updater方法返回了和原值一样的值,那么将不会发生改变,即使提供了notSetValue。
const map = Map({ a: Map({ b: Map({ c: 10 }) }) })
const newMap = map.updateIn(['a', 'b', 'x'], 100, val => val)
// Map { "a": Map { "b": Map { "c": 10 } } }
assert(newMap === map)
当处在ES2015或者更高环境下,不推荐使用notSetValue来实现函数变量默认值。这有助于避免任何可能导致与上述特性不符的困惑。
这里提供一个设置了函数变量默认值的例子,以展示这种写法将产生的不同表现:
const map = Map({ a: Map({ b: Map({ c: 10 }) }) })
const newMap = map.updateIn(['a', 'b', 'x'], (val = 100) => val)
// Map { "a": Map { "b": Map { "c": 10, "x": 100 } } }
如果指定位置存在值,但没有.set()方法(如Map和List),此时将会抛出异常。
mergeIn()
一个updateIn和merge的结合体,会一个新的Map在指定路径那个点上执行合并操作。换而言之,这两条语句效果相同:
map.updateIn(['a', 'b', 'c'], abc => abc.merge(y))
map.mergeIn(['a', 'b', 'c'], y)
mergeIn(keyPath: Iterable<any>, ...collections: Array<any>): this
注意:mergeIn可以在withMutations中使用。
mergeDeepIn()
一个updateIn和mergeDeep的结合体,会一个新的Map在指定路径那个点上执行合并操作。换而言之,这两条语句效果相同:
map.updateIn(['a', 'b', 'c'], abc => abc.mergeDeep(y))
map.mergeDeepIn(['a', 'b', 'c'], y)
mergeDeepIn(keyPath: Iterable<any>, ...collections: Array<any>): this
注意:mergeDeepIn可以在withMutations中使用。
暂时改变
withMutations()
每次你调用以上方法,它都会新建一个不可变Map。如果一个纯函数调用了多个上述方法来产生需要的值,那么产生的这些中间不可变Map将会对性能和内存造成负担。
withMutations(mutator: (mutable: this) => any): this
继承自
Map#withMutations
如果你需要进行一系列变化来产生新的不可变Map,用withMutations()对此Map创造一个临时的可变拷贝的方式来进程变化操作,可以极大地提升性能。事实上这是像merge这样复杂地操作实现地方式。
以下例子将会创造2个而不是4个新Map:
const { Map } = require('immutable')
const map1 = Map()
const map2 = map1.withMutations(map => {
map.set('a', 1).set('b', 2).set('c', 3)
})
assert(map1.size === 0)
assert(map2.size === 3)
注意:不是所有方法都可以在可变的集合或者是在withMutations中使用!查看每个方法的文档可以确认他是否能够安全地使用withMutations。
asMutable()
另外一种避免产生中间值的不可变Map的方式是创建一个这个集合的可变拷贝。可变拷贝总是返回this,因此不要用他们来进行比较。你的函数不要将这个可变集合返回出去,请只在函数内使用它来构建新的集合。如果可能的话使用withMutations,因为他提供了更易用地API。
asMutable(): this
继承自
Map#asMutable
注意:如果一个集合已经是可变的,asMutable将会返回他本身。
注意:不是所有方法都可以在可变的集合或者是在withMutations中使用!查看每个方法的文档可以确认他是否能够安全地使用withMutations。
asImmutable()
与asMutable谓之阳所对应的阴。因为他作用于可变集合,此操作是可变地并返回自身。一旦执行,这个可变的拷贝将会变成不可变的,这样即可将他安全的从方法中返回出去。
asImmutable(): this
继承自
Map#asImmutable
转换为JavaScript类型
toJS()
深层地将这个有序的集合转换转换为原生JS数组。
toJS(): Array<any>
继承自
Collection.Index#toJS
toJSON()
浅转换这个有序的集合为原生JS数组。
toJSON(): Array<any>
继承自
Collection.Index#toJSON
toArray()
浅转换这个有序的集合为原生JS数组并且丢弃key。
toArray(): Array<any>
继承自
Collection#toArray
toObject()
浅转换这个有序的集合为原生JS对象。
toObject(): {[key: string]: V}
继承自
Collection#toObject
键会被转换为String。
转换为Seq
toSeq()
返回Seq.Indexed。
toSeq(): Seq.Indexed<T>
继承自
Collection.Indexed#toSeq
fromEntrySeq()
如果这个集合是由[key, value]这种原组构成的,那么这将返回这些原组的Seq.Keyed。
fromEntrySeq(): Seq.Keyed<any, any>
继承自
Collection.Index#fromEntrySeq
toKeyedSeq()
从这个集合返回一个Seq.Keyed,其中索引将视作key。
toKeyedSeq(): Seq.Keyed<number, T>
继承自
Collection#toKeyedSeq
如果你想对Collection.Indexed操作返回一组[index, value]对,这将十分有用。
返回的Seq将与Colleciont有相同的索引顺序。
const { Seq } = require('immutable')
const indexedSeq = Seq([ 'A', 'B', 'C' ])
// Seq [ "A", "B", "C" ]
indexedSeq.filter(v => v === 'B')
// Seq [ "B" ]
const keyedSeq = indexedSeq.toKeyedSeq()
// Seq { 0: "A", 1: "B", 2: "C" }
keyedSeq.filter(v => v === 'B')
// Seq { 1: "B" }
toIndexedSeq()
将这个集合的值丢弃键(key)返回为Seq.Indexed。
toIndexedSeq(): Seq.Indexed<T>
继承自
Collection#toIndexedSeq
toSetSeq()
将这个集合的值丢弃键(key)返回为Seq.Set。
toSetSeq(): Seq.Set<T>
继承自
Collection#toSetSeq
系列函数
flip()
返回一个新的同类型Collection.Keyed,它将原Map的键和值进行交换。
flip(): this
继承自
Collection.Keyed#flip
例
const { Map } = require('immutable')
Map({ a: 'z', b: 'y' }).flip()
// Map { "z": "a", "y": "b" }
[Symbol.iterator]()
[Symbol.iterator](): IterableIterator<[K, V]>
继承自
Collection.Keyed#[Symbol.iterator]
等值比较
equals()
如果当前集合和另一个集合比较为相等,那么返回true,是否相等由Immutable.is()定义。
equals(other: any): boolean
继承自
Collection#equals
注意:此方法与Immutable.is(this, other)等效,提供此方法是为了方便能够链式地使用。
hashCode()
计算并返回这个集合的哈希值。
hashCode(): number
继承自
Collection#hashCode
集合的hashCode用于确定两个集合的相等性,在添加到Set或者被作为Map的键值时用于检测两个实例是否相等而会被使用到。
const a = List([ 1, 2, 3 ]);
const b = List([ 1, 2, 3 ]);
assert(a !== b); // different instances
const set = Set([ a ]);
assert(set.has(b) === true);
当两个值的hashCode相等时,并不能完全保证他们是相等的,但当他们的hashCode不同时,他们一定是不等的。
读值
get()
返回提供的索引位置关联的值,或者当提供的索引越界时返回所提供的notSetValue。
get<NSV>(index: number, notSetValue: NSV): T | NSV
get(index: number): T | undefined
继承自
Collection.Indexed#get
index可以为负值,表示从集合尾部开始索引。s.get(-1)取得集合最后一个元素。
has()
使用Immutable.is判断key值是否在Collection中。
has(key: number): boolean
继承自
Collection#has
includes()
使用Immutable.is判断value值是否在Collection中。
includes(value: T): boolean
继承自
Collection#includes
first()
取得集合第一个值。
first(): T | undefined
继承自
Collection#first
last()
取得集合第一个值。
last(): T | undefined
继承自
Collection#last
读取深层数据
getIn()
返回根据提供的路径或者索引搜索到的嵌套的值。
getIn(searchKeyPath: Iterable<any>, notSetValue?: any): any
继承自
Collection#getIn
hasIn()
根据提供的路径或者索引检测该处是否设置了值。
hasIn(searchKeyPath: Iterable<any>): boolean
继承自
Collection#hasIn
转换为集合
toMap()
将此集合转换为Map,如果键不可哈希,则抛弃。
toMap(): Map<number, T>
继承自
Collection#toMap
注意:这和Map(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toOrderedMap()
将此集合转换为Map,保留索引的顺序。
toOrderedMap(): OrderedMap<number, T>
继承自
Collection#toOrderedMap
注意:这和OrderedMap(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toSet()
将此集合转换为Set,如果值不可哈希,则抛弃。
toSet(): Set<T>
继承自
Collection#toSet
注意:这和Set(this)等效,为了能够方便的进行链式调用而提供。
toOrderSet()
将此集合转换为Set,保留索引的顺序。
toOrderedSet(): OrderedSet<T>
继承自
Collection#toOrderedSet
注意:这和OrderedSet(this.valueSeq())等效,为了能够方便的进行链式调用而提供。
toList()
将此集合转换为List,丢弃键值。
toList(): List<T>
继承自
Collection#toList
此方法和List(collection)类似,为了能够方便的进行链式调用而提供。然而,当在Map或者其他有键的集合上调用时,collection.toList()会丢弃键值,同时创建一个只有值的list,而List(collection)使用传入的元组创建list。
const { Map, List } = require('immutable')
var myMap = Map({ a: 'Apple', b: 'Banana' })
List(myMap) // List [ [ "a", "Apple" ], [ "b", "Banana" ] ]
myMap.toList() // List [ "Apple", "Banana" ]
toStack()
将此集合转换为Stack,丢弃键值,抛弃不可哈希的值。
toStack(): Stack<T>
注意:这和Stack(this)等效,为了能够方便的进行链式调用而提供。
迭代器
keys()
一个关于Collection键的迭代器。
keys(): IterableIterator<number>
继承自
Collection#keys
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用keySeq来满足需求。
values()
一个关于Collection值的迭代器。
values(): IterableIterator<T>
继承自
Collection#values
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用valueSeq来满足需求。
entries()
一个关于Collection条目的迭代器,是[ key, value ]这样的元组数据。
entries(): IterableIterator<[number, T]>
继承自
Collection#entries
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用entrySeq来满足需求。
集合(Seq)
keySeq()
返回一个新的Seq.Indexed,其包含这个集合的键值。
keySeq(): Seq.Indexed<number>
继承自
Collection#keySeq
valueSeq()
返回一个新的Seq.Indexed,其包含这个集合的所有值。
valueSeq(): Seq.Indexed<T>
继承自
Collection#valueSeq
entrySeq()
返回一个新的Seq.Indexed,其为[key, value]这样的元组。
entrySeq(): Seq.Indexed<[number, T]>
继承自
Collection#entrySeq
副作用
forEach()
sideEffect将会对集合上每个元素执行。
forEach(
sideEffect: (value: T, key: number, iter: this) => any,
context?: any
): number
继承自
Collection#forEach
与Array#forEach不同,任意一个sideEffect返回false都会停止循环。函数将返回所有参与循环的元素(包括最后一个返回false的那个)。
创建子集
slice()
返回一个新的相同类型的相当于原集合指定范围的元素集合,包含开始索引但不包含结束索引位置的值。
slice(begin?: number, end?: number): this
继承自
Collection#slice
如果起始值为负,那么表示从集合结束开始查找。例如slice(-2)返回集合最后两个元素。如果没有提供,那么新的集合将会从最开始那个元素开始。
如果终止值为负,表示从集合结束开始查找。例如silice(0, -1)返回除集合最后一个元素外所有元素。如果没提供,新的集合将会包含到原集合最后一个元素。
如果请求的子集与原集合相等,那么将会返回原集合。
rest()
返回一个不包含原集合第一个元素的新的同类型的集合。
rest(): this
继承自
Collection#rest
butLast()
返回一个不包含原集合最后一个元素的新的同类型的集合。
butLast(): this
继承自
Collection#butLast
skip()
返回一个不包含原集合从头开始amount个数元素的新的同类型集合。
skip(amount: number): this
继承自
Collection#skip
skipLast()
返回一个不包含原集合从结尾开始amount个数元素的新的同类型集合。
skipLast(amount: number): this
继承自
Collection#skipLast
skipWhile()
返回一个原集合从predicate返回false那个元素开始的新的同类型集合。
skipWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipWhile(x => x.match(/g/))
// List [ "cat", "hat", "god" ]
skipUntil()
返回一个原集合从predicate返回true那个元素开始的新的同类型集合。
skipUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipUntil(x => x.match(/hat/))
// List [ "hat", "god"" ]
take()
返回一个包含原集合从头开始的amount个元素的新的同类型集合。
take(amount: number): this
继承自
Collection#take
takeLast()
返回一个包含从原集合结尾开始的amount个元素的新的同类型集合。
takeLast(amount: number): this
继承自
Collection#take
takeWhile()
返回一个包含原集合从头开始的prediacte返回true的那些元素的新的同类型集合。
takeWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeWhile(x => x.match(/o/))
// List [ "dog", "frog" ]
takeUntil()
返回一个包含原集合从头开始的prediacte返回false的那些元素的新的同类型集合。
takeUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeUntil(x => x.match(/at/))
// List [ "dog", "frog" ]
组合
flatten()
压平嵌套的集合。
flatten(depth?: number): Collection<any, any>
flatten(shallow?: boolean): Collection<any, any>
继承自
Collection#flatten
默认会深度地经常压平集合操作,返回一个同类型的集合。可以指定depth为压平深度或者是否深度压平(为true表示仅进行一层的浅层压平)。如果深度为0(或者shllow:false)将会深层压平。
压平仅会操作其他集合,数组和对象不会进行此操作。
注意:flatten(true)操作是在集合上进行,同时返回一个集合。
减少值
reduce()
将传入的方法reducer在集合每个元素上调用并传递缩减值,以此来缩减集合的值。
reduce<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduce<R>(reducer: (reduction: T | R, value: T, key: number, iter: this) => R): R
继承自
Collection#reduce
见
Array#reduce
如果initialReduction未提供,那么将会使用集合第一个元素。
reduceRight()
逆向地缩减集合的值(从结尾开始)。
reduceRight<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduceRight<R>(
reducer: (reduction: T | R, value: T, key: number, iter: this) => R
): R
继承自
Collection#reduceRight
注意:与this.reverse().reduce()等效,为了与Array#reduceRight看齐而提供。
every()
当集合中所有元素predicate都判定为true时返回ture。
every(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#every
some()
当集合中任意元素predicate判定为true时返回ture。
some(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#some
join()
将值连接为字符串,并且在每两个值之间插入分割。默认分隔为","。
join(separator?: string): string
继承自
Collection#join
isEmpty()
当集合不包含值时返回true。
isEmpty(): boolean
继承自
Collection#isEmpty
对于惰性Seq,isEmpty会对他经常迭代来确定是否为空。至少会迭代一次。
count()
返回集合的大小。
count(): number
count(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number
继承自
Collection#count
不管此集合是否惰性地确定大小(某些Seq不能),这个方法将总是返回正确的大小。如果必要,他将会评估一个惰性的Seq。
如果predicate提供了,方法返回的数量将是集合中predicate返回true的元素个数。
countBy()
返回Seq.Keyed的数量,由grouper方法将值分组。
countBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Map<G, number>
注意:这不是一个惰性操作。
查找
find()
返回集合中第一个符合与所提供的断言的值。
find(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#find
findLast()
返回集合中最后一个符合与所提供的断言的值。
findLast(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#findLast
注意:predicate将会逆序地在每个值上调用。
findEntry()
返回第一个符合所提供断言的值的[key, value]。
findEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findEntry
findLastEntry()
返回最后一个符合所提供断言的值的[key, value]。
findLastEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findLastEntry
注意:predicate将会逆序地在每个值上调用。
findKey()
返回第一个predicate返回为true的键。
findKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findKey
findLastKey()
返回最后一个predicate返回为true的键。
findLastKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findLastKey
注意:predicate将会逆序地在每个值上调用。
keyOf()
返回与提供的搜索值关联的键,或者undefined。
keyOf(searchValue: T): number | undefined
继承自
Collection#keyOf
lastKeyOf()
返回最后一个与提供的搜索值关联的键或者undefined。
lastKeyOf(searchValue: T): number | undefined
继承自
Collection#lastKeyOf
max()
返回集合中最大的值。如果有多个值比较为相等,那么将返回第一个。
max(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#max
comparator的使用方法与Collection#sort是一样的,如果未提供那么默认的比较为>。
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么max将会独立于输入的顺序。默认的比较器>只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
maxBy()
和max类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
maxBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#maxBy
例
hitters.maxBy(hitter => hitter.avgHits)
min()
返回集合中最小的值,如果有多个值比较为相等,将会返回第一个。
min(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#min
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么min将会独立于输入的顺序。默认的比较器<只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
minBy()
和min类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
minBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#minBy
例
hitters.minBy(hitter => hitter.avgHits)
对比
isSubset()
如果iter包含集合中所有元素则返回true。
isSubset(iter: Iterable<T>): boolean
继承自
Collection#isSubset
isSuperset()
如果集合包含iter中所有元素则返回true。
isSuperset(iter: Iterable<T>): boolean
继承自
Collection#isSuperset
Set
一种存取复杂度为O(log32 N)的无重复值的集合。
class Set<T> extends Collection.Set<T>
遍历一个Set它的值将会以(value, value)这种形式便利。便利Set的顺序是不确定但稳定地。同一个Set进行多次遍历,他们遍历的顺序将会是一样的。
Set的值和Map的键一样,可以是任意类型的,包括其他不可变集合,自定义类型及NaN。使用Immutable.is来确定相等性,以保证Set中值的唯一性。
构造器
Set()
构建一个包含提供的集合的值得新的不可变Set。
Set(): Set<any>
Set<T>(): Set<T>
Set<T>(collection: Iterable<T>): Set<T>
静态方法
Set.isSet()
如果提供的值为Set返回true。
Set.isSet(maybeSet: any): boolean
Set.of()
返回新的包含提供值的Set。
Set.of<T>(...values: Array<T>): Set<T>
Set.fromKeys()
Set.fromKeys()使用集合或者JS对象的键创建一个新的不可变Set。
Set.fromKeys<T>(iter: Collection<T, any>): Set<T>
Set.fromKeys(obj: {[key: string]: any}): Set<string>
Set.intersect()
Set.intersect()使用与另一个Set共有值创建新的不可变Set。
Set.intersect<T>(sets: Iterable<Iterable<T>>): Set<T>
例
const { Set } = require('immutable')
const intersected = Set.intersect([
Set([ 'a', 'b', 'c' ])
Set([ 'c', 'a', 't' ])
])
// Set [ "a", "c"" ]
Set.union()
Set.union()将两个Set结合返回一个新的不可变Set。
Set.union<T>(sets: Iterable<Iterable<T>>): Set<T>
例
* const { Set } = require('immutable')
const unioned = Set.union([
Set([ 'a', 'b', 'c' ])
Set([ 'c', 'a', 't' ])
])
// Set [ "a", "b", "c", "t"" ]
成员
size
size
修改持久化
add()
返回一个新的在原Set基础上包含提供值的Set。
add(value: T): this
注意:add可以在withMutations中使用。
delete()
在原Set基础上删除提供值返回为新的Set。
delete(value: T): this
别名
remove()
注意:remove可以在withMutations中使用。
注意:delete不可安全地在IE8环境下使用,如果需要支持旧的浏览器请使用remove。
clear()
返回一个新的不包含值的Set。
claer(value: T): this
注意:claer可以在withMutations中使用。
uniton()
在原Set基础上添加collections中不在原Set中存在的值,返回为新的Set。
union(...collections: Array<Collection<any, T> | Array<T>>): this
别名
merge()
注意:uniton可以在withMutations中使用。
intersect()
在原Set基础上剔除collections中未出现的值,返回为新Set。
intersect(...collections: Array<Collection<any, T> | Array<T>>): this
注意:intersect可以在withMutations中使用。
subtract()
在原Set基础上剔除与collections共同包含的值,返回为新Set。
subtract(...collections: Array<Collection<any, T> | Array<T>>): this
注意:subtract可以在withMutations中使用。
update()
这将是一个很有用的方法来将两个普通方法进行链式调用。RxJS中为"let",lodash中为"thru"。
update<R>(updater: (value: this) => R): R
继承自
Collection#update
例如,在进行map和filter操作后计算总和操作:
const { Seq } = require('immutable')
function sum(collection) {
return collection.reduce((sum, x) => sum + x, 0)
}
Map({ x: 1, y: 2, z: 3 })
.map(x => x + 1)
.filter(x => x % 2 === 0)
.update(sum)
// 6
临时改变
withMutations()
注意:只有部分方法可以被可变的集合调用或者在withMutations中调用!查看文档中各个方法看他是否允许在withMuataions中调用。
withMutations(mutator: (mutable: this) => any): this
见
Map#withMutations
asMutable()
注意:只有部分方法可以被可变的集合调用或者在withMutations中调用!查看文档中各个方法看他是否允许在withMuataions中调用。
asMutable(): this
见
Map#asMutable
asImmutable()
asImmutable(): this
见
Map#asImmutable
序列算法
map()
返回一个由传入的mapper函数处理过值的新Set。
map<M>(mapper: (value: T, key: number, iter: this) => M, context?: any): Set<M>
覆盖
Collection#map
例
Set([ 1, 2 ]).map(x => 10 * x)
// Set [ 10, 20 ]
注意:map()总是返回一个新的实例,即使它产出的每一个值都与原始值相同。
flatMap()
扁平化这个Set为一个新Set。
flatMap<M>(
mapper: (value: T, key: number, iter: this) => Iterable<M>,
context?: any
): Set<M>
覆盖
Collection#flatMap
与set.map(...).flatten(true)相似。
filter()
返回一个只有由传入方法predicate返回为true的值组成的新Set。
filter<F>(
predicate: (value: T, index: number, iter: this) => boolean,
context?: any
): Set<F>
filter(
predicate: (value: T, index: number, iter: this) => any,
context?: any
): this
覆盖
Collection#filter
注意:filter()总是返回一个新的实例,即使它的结果没有过滤掉任何一个值。
[Symbol.iterator]
[Symbol.iterator](): IterableIterator<T>
继承自
Collection.Set#[Symbol.iterator]
filterNot()
返回一个由所提供的predicate方法返回false过滤的新的相同类型的集合。
filterNot(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#filterNot
例
const { Map } = require('immutable')
Map({ a: 1, b: 2, c: 3, d: 4}).filterNot(x => x % 2 === 0)
// Map { "a": 1, "c": 3 }
注意:filterNot总是返回一个新的实例,即使它没有过滤掉任何一个值。
reverse()
返回为一个逆序的新的同类型集合。
reverse(): this
继承自
Collection#reverse
sort()
返回一个使用传入的comparator重新排序的新同类型集合。
sort(comparator?: (valueA: T, valueB: T) => number): this
继承自
Collection#sort
如果没有提供comparator方法,那么默认的比较将使用<和>。
comparator(valueA, valueB):
- 返回值为
0这个元素将不会被交换。 - 返回值为
-1(或者任意负数)valueA将会移到valueB之前。 - 返回值为
1(或者任意正数)valueA将会移到valueB之后。 - 为空,这将会返回相同的值和顺序。
当被排序的集合没有定义顺序,那么将会返回同等的有序集合。比如map.sort()将返回OrderedMap。
const { Map } = require('immutable')
Map({ "c": 3, "a": 1, "b": 2 }).sort((a, b) => {
if (a < b) { return -1; }
if (a > b) { return 1; }
if (a === b) { return 0; }
});
// OrderedMap { "a": 1, "b": 2, "c": 3 }
注意:sort()总是返回一个新的实例,即使它没有改变排序。
sortBy()
与sort类似,但能接受一个comparatorValueMapper方法,它允许通过更复杂的方式进行排序:
sortBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): this
继承自
Collection#sortBy
例
hitters.sortBy(hitter => hitter.avgHits)
注意:sortBy()总是返回一个新的实例,即使它没有改变排序。
groupBy()
返回一个Collection.Keyeds的Collection.keyed,由传入的grouper方法分组。
groupBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Seq.Keyed<G, Collection<number, T>>
继承自
Collection#groupBy
const { List, Map } = require('immutable')
const listOfMaps = List([
Map({ v: 0 }),
Map({ v: 1 }),
Map({ v: 1 }),
Map({ v: 0 }),
Map({ v: 2 })
])
const groupsOfMaps = listOfMaps.groupBy(x => x.get('v'))
// Map {
// 0: List [ Map{ "v": 0 }, Map { "v": 0 } ],
// 1: List [ Map{ "v": 1 }, Map { "v": 1 } ],
// 2: List [ Map{ "v": 2 } ],
// }
转换为JavaScript类型
toJS()
深层地将这个有序的集合转换转换为原生JS数组。
toJS(): Array<any>
继承自
Collection.Index#toJS
toJSON()
浅转换这个有序的集合为原生JS数组。
toJSON(): Array<any>
继承自
Collection.Index#toJSON
toArray()
浅转换这个有序的集合为原生JS数组并且丢弃key。
toArray(): Array<any>
继承自
Collection#toArray
toObject()
浅转换这个有序的集合为原生JS对象。
toObject(): {[key: string]: V}
继承自
Collection#toObject
转换为Seq
toSeq()
返回Seq.Indexed。
toSeq(): Seq.Indexed<T>
继承自
Collection.Indexed#toSeq
fromEntrySeq()
如果这个集合是由[key, value]这种原组构成的,那么这将返回这些原组的Seq.Keyed。
fromEntrySeq(): Seq.Keyed<any, any>
继承自
Collection.Index#fromEntrySeq
toKeyedSeq()
从这个集合返回一个Seq.Keyed,其中索引将视作key。
toKeyedSeq(): Seq.Keyed<number, T>
继承自
Collection#toKeyedSeq
如果你想对Collection.Indexed操作返回一组[index, value]对,这将十分有用。
返回的Seq将与Colleciont有相同的索引顺序。
const { Seq } = require('immutable')
const indexedSeq = Seq([ 'A', 'B', 'C' ])
// Seq [ "A", "B", "C" ]
indexedSeq.filter(v => v === 'B')
// Seq [ "B" ]
const keyedSeq = indexedSeq.toKeyedSeq()
// Seq { 0: "A", 1: "B", 2: "C" }
keyedSeq.filter(v => v === 'B')
// Seq { 1: "B" }
toIndexedSeq()
将这个集合的值丢弃键(key)返回为Seq.Indexed。
toIndexedSeq(): Seq.Indexed<T>
继承自
Collection#toIndexedSeq
toSetSeq()
将这个集合的值丢弃键(key)返回为Seq.Set。
toSetSeq(): Seq.Set<T>
继承自
Collection#toSetSeq
等值比较
equals()
如果当前集合和另一个集合比较为相等,那么返回true,是否相等由Immutable.is()定义。
equals(other: any): boolean
继承自
Collection#equals
注意:此方法与Immutable.is(this, other)等效,提供此方法是为了方便能够链式地使用。
hashCode()
计算并返回这个集合的哈希值。
hashCode(): number
继承自
Collection#hashCode
集合的hashCode用于确定两个集合的相等性,在添加到Set或者被作为Map的键值时用于检测两个实例是否相等而会被使用到。
const a = List([ 1, 2, 3 ]);
const b = List([ 1, 2, 3 ]);
assert(a !== b); // different instances
const set = Set([ a ]);
assert(set.has(b) === true);
当两个值的hashCode相等时,并不能完全保证他们是相等的,但当他们的hashCode不同时,他们一定是不等的。
读值
get()
返回提供的索引位置关联的值,或者当提供的索引越界时返回所提供的notSetValue。
get<NSV>(index: number, notSetValue: NSV): T | NSV
get(index: number): T | undefined
继承自
Collection.Indexed#get
index可以为负值,表示从集合尾部开始索引。s.get(-1)取得集合最后一个元素。
has()
使用Immutable.is判断key值是否在Collection中。
has(key: number): boolean
继承自
Collection#has
includes()
使用Immutable.is判断value值是否在Collection中。
includes(value: T): boolean
继承自
Collection#includes
first()
取得集合第一个值。
first(): T | undefined
继承自
Collection#first
last()
取得集合第一个值。
last(): T | undefined
继承自
Collection#last
读取深层数据
getIn()
返回根据提供的路径或者索引搜索到的嵌套的值。
getIn(searchKeyPath: Iterable<any>, notSetValue?: any): any
继承自
Collection#getIn
hasIn()
根据提供的路径或者索引检测该处是否设置了值。
hasIn(searchKeyPath: Iterable<any>): boolean
继承自
Collection#hasIn
转换为集合
toMap()
将此集合转换为Map,如果键不可哈希,则抛弃。
toMap(): Map<number, T>
继承自
Collection#toMap
注意:这和Map(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toOrderedMap()
将此集合转换为Map,保留索引的顺序。
toOrderedMap(): OrderedMap<number, T>
继承自
Collection#toOrderedMap
注意:这和OrderedMap(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toSet()
将此集合转换为Set,如果值不可哈希,则抛弃。
toSet(): Set<T>
继承自
Collection#toSet
注意:这和Set(this)等效,为了能够方便的进行链式调用而提供。
toOrderSet()
将此集合转换为Set,保留索引的顺序。
toOrderedSet(): OrderedSet<T>
继承自
Collection#toOrderedSet
注意:这和OrderedSet(this.valueSeq())等效,为了能够方便的进行链式调用而提供。
toList()
将此集合转换为List,丢弃键值。
toList(): List<T>
继承自
Collection#toList
此方法和List(collection)类似,为了能够方便的进行链式调用而提供。然而,当在Map或者其他有键的集合上调用时,collection.toList()会丢弃键值,同时创建一个只有值的list,而List(collection)使用传入的元组创建list。
const { Map, List } = require('immutable')
var myMap = Map({ a: 'Apple', b: 'Banana' })
List(myMap) // List [ [ "a", "Apple" ], [ "b", "Banana" ] ]
myMap.toList() // List [ "Apple", "Banana" ]
toStack()
将此集合转换为Stack,丢弃键值,抛弃不可哈希的值。
toStack(): Stack<T>
注意:这和Stack(this)等效,为了能够方便的进行链式调用而提供。
迭代器
keys()
一个关于Collection键的迭代器。
keys(): IterableIterator<number>
继承自
Collection#keys
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用keySeq来满足需求。
values()
一个关于Collection值的迭代器。
values(): IterableIterator<T>
继承自
Collection#values
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用valueSeq来满足需求。
entries()
一个关于Collection条目的迭代器,是[ key, value ]这样的元组数据。
entries(): IterableIterator<[number, T]>
继承自
Collection#entries
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用entrySeq来满足需求。
集合(Seq)
keySeq()
返回一个新的Seq.Indexed,其包含这个集合的键值。
keySeq(): Seq.Indexed<number>
继承自
Collection#keySeq
valueSeq()
返回一个新的Seq.Indexed,其包含这个集合的所有值。
valueSeq(): Seq.Indexed<T>
继承自
Collection#valueSeq
entrySeq()
返回一个新的Seq.Indexed,其为[key, value]这样的元组。
entrySeq(): Seq.Indexed<[number, T]>
继承自
Collection#entrySeq
副作用
forEach()
sideEffect将会对集合上每个元素执行。
forEach(
sideEffect: (value: T, key: number, iter: this) => any,
context?: any
): number
继承自
Collection#forEach
与Array#forEach不同,任意一个sideEffect返回false都会停止循环。函数将返回所有参与循环的元素(包括最后一个返回false的那个)。
创建子集
slice()
返回一个新的相同类型的相当于原集合指定范围的元素集合,包含开始索引但不包含结束索引位置的值。
slice(begin?: number, end?: number): this
继承自
Collection#slice
如果起始值为负,那么表示从集合结束开始查找。例如slice(-2)返回集合最后两个元素。如果没有提供,那么新的集合将会从最开始那个元素开始。
如果终止值为负,表示从集合结束开始查找。例如silice(0, -1)返回除集合最后一个元素外所有元素。如果没提供,新的集合将会包含到原集合最后一个元素。
如果请求的子集与原集合相等,那么将会返回原集合。
rest()
返回一个不包含原集合第一个元素的新的同类型的集合。
rest(): this
继承自
Collection#rest
butLast()
返回一个不包含原集合最后一个元素的新的同类型的集合。
butLast(): this
继承自
Collection#butLast
skip()
返回一个不包含原集合从头开始amount个数元素的新的同类型集合。
skip(amount: number): this
继承自
Collection#skip
skipLast()
返回一个不包含原集合从结尾开始amount个数元素的新的同类型集合。
skipLast(amount: number): this
继承自
Collection#skipLast
skipWhile()
返回一个原集合从predicate返回false那个元素开始的新的同类型集合。
skipWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipWhile(x => x.match(/g/))
// List [ "cat", "hat", "god" ]
skipUntil()
返回一个原集合从predicate返回true那个元素开始的新的同类型集合。
skipUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipUntil(x => x.match(/hat/))
// List [ "hat", "god"" ]
take()
返回一个包含原集合从头开始的amount个元素的新的同类型集合。
take(amount: number): this
继承自
Collection#take
takeLast()
返回一个包含从原集合结尾开始的amount个元素的新的同类型集合。
takeLast(amount: number): this
继承自
Collection#take
takeWhile()
返回一个包含原集合从头开始的prediacte返回true的那些元素的新的同类型集合。
takeWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeWhile(x => x.match(/o/))
// List [ "dog", "frog" ]
takeUntil()
返回一个包含原集合从头开始的prediacte返回false的那些元素的新的同类型集合。
takeUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeUntil(x => x.match(/at/))
// List [ "dog", "frog" ]
组合
cancat()
将其他的值或者集合与这个Set串联起来返回为一个新Set。
concat<C>(...valuesOrCollections: Array<Iterable<C> | C>): Set<T | C>
覆盖
Collection#concat
flatten()
压平嵌套的集合。
flatten(depth?: number): Collection<any, any>
flatten(shallow?: boolean): Collection<any, any>
继承自
Collection#flatten
默认会深度地经常压平集合操作,返回一个同类型的集合。可以指定depth为压平深度或者是否深度压平(为true表示仅进行一层的浅层压平)。如果深度为0(或者shllow:false)将会深层压平。
压平仅会操作其他集合,数组和对象不会进行此操作。
注意:flatten(true)操作是在集合上进行,同时返回一个集合。
减少值
reduce()
将传入的方法reducer在集合每个元素上调用并传递缩减值,以此来缩减集合的值。
reduce<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduce<R>(reducer: (reduction: T | R, value: T, key: number, iter: this) => R): R
继承自
Collection#reduce
见
Array#reduce
如果initialReduction未提供,那么将会使用集合第一个元素。
reduceRight()
逆向地缩减集合的值(从结尾开始)。
reduceRight<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduceRight<R>(
reducer: (reduction: T | R, value: T, key: number, iter: this) => R
): R
继承自
Collection#reduceRight
注意:与this.reverse().reduce()等效,为了与Array#reduceRight看齐而提供。
every()
当集合中所有元素predicate都判定为true时返回ture。
every(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#every
some()
当集合中任意元素predicate判定为true时返回ture。
some(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#some
join()
将值连接为字符串,并且在每两个值之间插入分割。默认分隔为","。
join(separator?: string): string
继承自
Collection#join
isEmpty()
当集合不包含值时返回true。
isEmpty(): boolean
继承自
Collection#isEmpty
对于惰性Seq,isEmpty会对他经常迭代来确定是否为空。至少会迭代一次。
count()
返回集合的大小。
count(): number
count(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number
继承自
Collection#count
不管此集合是否惰性地确定大小(某些Seq不能),这个方法将总是返回正确的大小。如果必要,他将会评估一个惰性的Seq。
如果predicate提供了,方法返回的数量将是集合中predicate返回true的元素个数。
countBy()
返回Seq.Keyed的数量,由grouper方法将值分组。
countBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Map<G, number>
注意:这不是一个惰性操作。
查找
find()
返回集合中第一个符合与所提供的断言的值。
find(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#find
findLast()
返回集合中最后一个符合与所提供的断言的值。
findLast(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#findLast
注意:predicate将会逆序地在每个值上调用。
findEntry()
返回第一个符合所提供断言的值的[key, value]。
findEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findEntry
findLastEntry()
返回最后一个符合所提供断言的值的[key, value]。
findLastEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findLastEntry
注意:predicate将会逆序地在每个值上调用。
findKey()
返回第一个predicate返回为true的键。
findKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findKey
findLastKey()
返回最后一个predicate返回为true的键。
findLastKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findLastKey
注意:predicate将会逆序地在每个值上调用。
keyOf()
返回与提供的搜索值关联的键,或者undefined。
keyOf(searchValue: T): number | undefined
继承自
Collection#keyOf
lastKeyOf()
返回最后一个与提供的搜索值关联的键或者undefined。
lastKeyOf(searchValue: T): number | undefined
继承自
Collection#lastKeyOf
max()
返回集合中最大的值。如果有多个值比较为相等,那么将返回第一个。
max(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#max
comparator的使用方法与Collection#sort是一样的,如果未提供那么默认的比较为>。
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么max将会独立于输入的顺序。默认的比较器>只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
maxBy()
和max类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
maxBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#maxBy
例
hitters.maxBy(hitter => hitter.avgHits)
min()
返回集合中最小的值,如果有多个值比较为相等,将会返回第一个。
min(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#min
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么min将会独立于输入的顺序。默认的比较器<只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
minBy()
和min类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
minBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#minBy
例
hitters.minBy(hitter => hitter.avgHits)
对比
isSubset()
如果iter包含集合中所有元素则返回true。
isSubset(iter: Iterable<T>): boolean
继承自
Collection#isSubset
isSuperset()
如果集合包含iter中所有元素则返回true。
isSuperset(iter: Iterable<T>): boolean
继承自
Collection#isSuperset
OrderedSet
一种能够保证迭代顺序为元素添加(add)顺序的Set。
构造器
OrderedSet()
构建一个新的不可变OrderedSet包含所提供类集合结构的值。
OrderedSet(): OrderedSet<any>
OrderedSet<T>(): OrderedSet<T>
OrderedSet<T>(collection: Iterable<T>): OrderedSet<T>
静态方法
OrderedSet.isOrderedSet()
如果提供的值为OrderedSet则返回true。
OrderedSet.isOrderedSet(maybeOrderedSet: any): boolean
OrderedSet.of()
构建一个新的不可变OrderedSet包含所提供values。
OrderedSet.of<T>(...values: Array<T>): OrderedSet<T>
OrderedSet.fromKeys()
OrderedSet.fromKeys()使用集合或者JS对象的键创建一个新的不可变OrderedSet。
成员
size
size
序列算法
cancat()
将其他的值或者集合与这个OrderedSet串联起来返回为一个新OrderedSet。
concat<C>(...valuesOrCollections: Array<Iterable<C> | C>): OrderedSet<T | C>
覆盖
Collection#concat
map()
返回一个由传入的mapper函数处理过值的新OrderedSet。
map<M>(mapper: (value: T, key: number, iter: this) => M, context?: any): OrderedSet<M>
覆盖
Collection#map
例
OrderedSet([ 1, 2 ]).map(x => 10 * x)
// OrderedSet [ 10, 20 ]
注意:map()总是返回一个新的实例,即使它产出的每一个值都与原始值相同。
flatMap()
扁平化这个OrderedSet为一个新OrderedSet。
flatMap<M>(
mapper: (value: T, key: number, iter: this) => Iterable<M>,
context?: any
): OrderedSet<M>
覆盖
Collection#flatMap
与set.map(...).flatten(true)相似。
filter()
返回一个只有由传入方法predicate返回为true的值组成的新OrderedSet。
filter<F>(
predicate: (value: T, index: number, iter: this) => boolean,
context?: any
): OrderedSet<F>
filter(
predicate: (value: T, index: number, iter: this) => any,
context?: any
): this
覆盖
Collection#filter
注意:filter()总是返回一个新的实例,即使它的结果没有过滤掉任何一个值。
zip()
将OrderedSet与所提供集合拉链咬合(zipped)。
zip(...collections: Array<Collection<any, any>>): OrderedSet<any>
覆盖
Collection.Index#zip
与zipWIth类似,但这个使用默认的zipper建立数组。
const a = OrderedSet([ 1, 2, 3 ]);
const b = OrderedSet([ 4, 5, 6 ]);
const c = a.zip(b); // OrderedSet [ [ 1, 4 ], [ 2, 5 ], [ 3, 6 ] ]
zipWith()
将OrderedSet与所提供集合使用自定义zipper方法进行拉链咬合(zipped)。
zipWith<U, Z>(
zipper: (value: T, otherValue: U) => Z,
otherCollection: Collection<any, U>
): OrderedSet<Z>
zipWith<U, V, Z>(
zipper: (value: T, otherValue: U, thirdValue: V) => Z,
otherCollection: Collection<any, U>,
thirdCollection: Collection<any, V>
): OrderedSet<Z>
zipWith<Z>(
zipper: (...any: Array<any>) => Z,
...collections: Array<Collection<any, any>>
): OrderedSet<Z>
见
IndexedIterator.zipWith
[Symbol.iterator]
[Symbol.iterator](): IterableIterator<T>
继承自
Collection.Indexed#[Symbol.iterator]
filterNot()
返回一个由所提供的predicate方法返回false过滤的新的相同类型的集合。
filterNot(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#filterNot
例
const { Map } = require('immutable')
Map({ a: 1, b: 2, c: 3, d: 4}).filterNot(x => x % 2 === 0)
// Map { "a": 1, "c": 3 }
注意:filterNot总是返回一个新的实例,即使它没有过滤掉任何一个值。
reverse()
返回为一个逆序的新的同类型集合。
reverse(): this
继承自
Collection#reverse
sort()
返回一个使用传入的comparator重新排序的新同类型集合。
sort(comparator?: (valueA: T, valueB: T) => number): this
继承自
Collection#sort
如果没有提供comparator方法,那么默认的比较将使用<和>。
comparator(valueA, valueB):
- 返回值为
0这个元素将不会被交换。 - 返回值为
-1(或者任意负数)valueA将会移到valueB之前。 - 返回值为
1(或者任意正数)valueA将会移到valueB之后。 - 为空,这将会返回相同的值和顺序。
当被排序的集合没有定义顺序,那么将会返回同等的有序集合。比如map.sort()将返回OrderedMap。
const { Map } = require('immutable')
Map({ "c": 3, "a": 1, "b": 2 }).sort((a, b) => {
if (a < b) { return -1; }
if (a > b) { return 1; }
if (a === b) { return 0; }
});
// OrderedMap { "a": 1, "b": 2, "c": 3 }
注意:sort()总是返回一个新的实例,即使它没有改变排序。
sortBy()
与sort类似,但能接受一个comparatorValueMapper方法,它允许通过更复杂的方式进行排序:
sortBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): this
继承自
Collection#sortBy
例
hitters.sortBy(hitter => hitter.avgHits)
注意:sortBy()总是返回一个新的实例,即使它没有改变排序。
groupBy()
返回一个Collection.Keyeds的Collection.keyed,由传入的grouper方法分组。
groupBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Seq.Keyed<G, Collection<number, T>>
继承自
Collection#groupBy
const { List, Map } = require('immutable')
const listOfMaps = List([
Map({ v: 0 }),
Map({ v: 1 }),
Map({ v: 1 }),
Map({ v: 0 }),
Map({ v: 2 })
])
const groupsOfMaps = listOfMaps.groupBy(x => x.get('v'))
// Map {
// 0: List [ Map{ "v": 0 }, Map { "v": 0 } ],
// 1: List [ Map{ "v": 1 }, Map { "v": 1 } ],
// 2: List [ Map{ "v": 2 } ],
// }
修改持久化
add()
返回一个新的在原Set基础上包含提供值的Set。
add(value: T): this
注意:add可以在withMutations中使用。
delete()
在原Set基础上删除提供值返回为新的Set。
delete(value: T): this
别名
remove()
注意:remove可以在withMutations中使用。
注意:delete不可安全地在IE8环境下使用,如果需要支持旧的浏览器请使用remove。
clear()
返回一个新的不包含值的Set。
claer(value: T): this
注意:claer可以在withMutations中使用。
uniton()
在原Set基础上添加collections中不在原Set中存在的值,返回为新的Set。
union(...collections: Array<Collection<any, T> | Array<T>>): this
别名
merge()
注意:uniton可以在withMutations中使用。
intersect()
在原Set基础上剔除collections中未出现的值,返回为新Set。
intersect(...collections: Array<Collection<any, T> | Array<T>>): this
注意:intersect可以在withMutations中使用。
subtract()
在原Set基础上剔除与collections共同包含的值,返回为新Set。
subtract(...collections: Array<Collection<any, T> | Array<T>>): this
注意:subtract可以在withMutations中使用。
update()
这将是一个很有用的方法来将两个普通方法进行链式调用。RxJS中为"let",lodash中为"thru"。
update<R>(updater: (value: this) => R): R
继承自
Collection#update
例如,在进行map和filter操作后计算总和操作:
const { Seq } = require('immutable')
function sum(collection) {
return collection.reduce((sum, x) => sum + x, 0)
}
Map({ x: 1, y: 2, z: 3 })
.map(x => x + 1)
.filter(x => x % 2 === 0)
.update(sum)
// 6
修改持久化
add()
返回一个新的在原Set基础上包含提供值的Set。
add(value: T): this
注意:add可以在withMutations中使用。
delete()
在原Set基础上删除提供值返回为新的Set。
delete(value: T): this
别名
remove()
注意:remove可以在withMutations中使用。
注意:delete不可安全地在IE8环境下使用,如果需要支持旧的浏览器请使用remove。
clear()
返回一个新的不包含值的Set。
claer(value: T): this
注意:claer可以在withMutations中使用。
uniton()
在原Set基础上添加collections中不在原Set中存在的值,返回为新的Set。
union(...collections: Array<Collection<any, T> | Array<T>>): this
别名
merge()
注意:uniton可以在withMutations中使用。
intersect()
在原Set基础上剔除collections中未出现的值,返回为新Set。
intersect(...collections: Array<Collection<any, T> | Array<T>>): this
注意:intersect可以在withMutations中使用。
subtract()
在原Set基础上剔除与collections共同包含的值,返回为新Set。
subtract(...collections: Array<Collection<any, T> | Array<T>>): this
注意:subtract可以在withMutations中使用。
update()
这将是一个很有用的方法来将两个普通方法进行链式调用。RxJS中为"let",lodash中为"thru"。
update<R>(updater: (value: this) => R): R
继承自
Collection#update
例如,在进行map和filter操作后计算总和操作:
const { Seq } = require('immutable')
function sum(collection) {
return collection.reduce((sum, x) => sum + x, 0)
}
Map({ x: 1, y: 2, z: 3 })
.map(x => x + 1)
.filter(x => x % 2 === 0)
.update(sum)
// 6
临时改变
withMutations()
注意:只有部分方法可以被可变的集合调用或者在withMutations中调用!查看文档中各个方法看他是否允许在withMuataions中调用。
withMutations(mutator: (mutable: this) => any): this
见
Map#withMutations
asMutable()
注意:只有部分方法可以被可变的集合调用或者在withMutations中调用!查看文档中各个方法看他是否允许在withMuataions中调用。
asMutable(): this
见
Map#asMutable
asImmutable()
asImmutable(): this
见
Map#asImmutable
转换为JavaScript类型
toJS()
深层地将这个有序的集合转换转换为原生JS数组。
toJS(): Array<any>
继承自
Collection.Index#toJS
toJSON()
浅转换这个有序的集合为原生JS数组。
toJSON(): Array<any>
继承自
Collection.Index#toJSON
toArray()
浅转换这个有序的集合为原生JS数组并且丢弃key。
toArray(): Array<any>
继承自
Collection#toArray
toObject()
浅转换这个有序的集合为原生JS对象。
toObject(): {[key: string]: V}
继承自
Collection#toObject
转换为Seq
toSeq()
返回Seq.Indexed。
toSeq(): Seq.Indexed<T>
继承自
Collection.Indexed#toSeq
fromEntrySeq()
如果这个集合是由[key, value]这种原组构成的,那么这将返回这些原组的Seq.Keyed。
fromEntrySeq(): Seq.Keyed<any, any>
继承自
Collection.Index#fromEntrySeq
toKeyedSeq()
从这个集合返回一个Seq.Keyed,其中索引将视作key。
toKeyedSeq(): Seq.Keyed<number, T>
继承自
Collection#toKeyedSeq
如果你想对Collection.Indexed操作返回一组[index, value]对,这将十分有用。
返回的Seq将与Colleciont有相同的索引顺序。
const { Seq } = require('immutable')
const indexedSeq = Seq([ 'A', 'B', 'C' ])
// Seq [ "A", "B", "C" ]
indexedSeq.filter(v => v === 'B')
// Seq [ "B" ]
const keyedSeq = indexedSeq.toKeyedSeq()
// Seq { 0: "A", 1: "B", 2: "C" }
keyedSeq.filter(v => v === 'B')
// Seq { 1: "B" }
toIndexedSeq()
将这个集合的值丢弃键(key)返回为Seq.Indexed。
toIndexedSeq(): Seq.Indexed<T>
继承自
Collection#toIndexedSeq
toSetSeq()
将这个集合的值丢弃键(key)返回为Seq.Set。
toSetSeq(): Seq.Set<T>
继承自
Collection#toSetSeq
等值比较
equals()
如果当前集合和另一个集合比较为相等,那么返回true,是否相等由Immutable.is()定义。
equals(other: any): boolean
继承自
Collection#equals
注意:此方法与Immutable.is(this, other)等效,提供此方法是为了方便能够链式地使用。
hashCode()
计算并返回这个集合的哈希值。
hashCode(): number
继承自
Collection#hashCode
集合的hashCode用于确定两个集合的相等性,在添加到Set或者被作为Map的键值时用于检测两个实例是否相等而会被使用到。
const a = List([ 1, 2, 3 ]);
const b = List([ 1, 2, 3 ]);
assert(a !== b); // different instances
const set = Set([ a ]);
assert(set.has(b) === true);
当两个值的hashCode相等时,并不能完全保证他们是相等的,但当他们的hashCode不同时,他们一定是不等的。
读值
get()
返回提供的索引位置关联的值,或者当提供的索引越界时返回所提供的notSetValue。
get<NSV>(index: number, notSetValue: NSV): T | NSV
get(index: number): T | undefined
继承自
Collection.Indexed#get
index可以为负值,表示从集合尾部开始索引。s.get(-1)取得集合最后一个元素。
has()
使用Immutable.is判断key值是否在Collection中。
has(key: number): boolean
继承自
Collection#has
includes()
使用Immutable.is判断value值是否在Collection中。
includes(value: T): boolean
继承自
Collection#includes
first()
取得集合第一个值。
first(): T | undefined
继承自
Collection#first
last()
取得集合第一个值。
last(): T | undefined
继承自
Collection#last
读值
get()
返回提供的索引位置关联的值,或者当提供的索引越界时返回所提供的notSetValue。
get<NSV>(index: number, notSetValue: NSV): T | NSV
get(index: number): T | undefined
继承自
Collection.Indexed#get
index可以为负值,表示从集合尾部开始索引。s.get(-1)取得集合最后一个元素。
has()
使用Immutable.is判断key值是否在Collection中。
has(key: number): boolean
继承自
Collection#has
includes()
使用Immutable.is判断value值是否在Collection中。
includes(value: T): boolean
继承自
Collection#includes
first()
取得集合第一个值。
first(): T | undefined
继承自
Collection#first
last()
取得集合第一个值。
last(): T | undefined
继承自
Collection#last
读取深层数据
getIn()
返回根据提供的路径或者索引搜索到的嵌套的值。
getIn(searchKeyPath: Iterable<any>, notSetValue?: any): any
继承自
Collection#getIn
hasIn()
根据提供的路径或者索引检测该处是否设置了值。
hasIn(searchKeyPath: Iterable<any>): boolean
继承自
Collection#hasIn
读值
get()
返回提供的索引位置关联的值,或者当提供的索引越界时返回所提供的notSetValue。
get<NSV>(index: number, notSetValue: NSV): T | NSV
get(index: number): T | undefined
继承自
Collection.Indexed#get
index可以为负值,表示从集合尾部开始索引。s.get(-1)取得集合最后一个元素。
has()
使用Immutable.is判断key值是否在Collection中。
has(key: number): boolean
继承自
Collection#has
includes()
使用Immutable.is判断value值是否在Collection中。
includes(value: T): boolean
继承自
Collection#includes
first()
取得集合第一个值。
first(): T | undefined
继承自
Collection#first
last()
取得集合第一个值。
last(): T | undefined
继承自
Collection#last
读取深层数据
getIn()
返回根据提供的路径或者索引搜索到的嵌套的值。
getIn(searchKeyPath: Iterable<any>, notSetValue?: any): any
继承自
Collection#getIn
hasIn()
根据提供的路径或者索引检测该处是否设置了值。
hasIn(searchKeyPath: Iterable<any>): boolean
继承自
Collection#hasIn
转换为集合
toMap()
将此集合转换为Map,如果键不可哈希,则抛弃。
toMap(): Map<number, T>
继承自
Collection#toMap
注意:这和Map(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toOrderedMap()
将此集合转换为Map,保留索引的顺序。
toOrderedMap(): OrderedMap<number, T>
继承自
Collection#toOrderedMap
注意:这和OrderedMap(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toSet()
将此集合转换为Set,如果值不可哈希,则抛弃。
toSet(): Set<T>
继承自
Collection#toSet
注意:这和Set(this)等效,为了能够方便的进行链式调用而提供。
toOrderSet()
将此集合转换为Set,保留索引的顺序。
toOrderedSet(): OrderedSet<T>
继承自
Collection#toOrderedSet
注意:这和OrderedSet(this.valueSeq())等效,为了能够方便的进行链式调用而提供。
toList()
将此集合转换为List,丢弃键值。
toList(): List<T>
继承自
Collection#toList
此方法和List(collection)类似,为了能够方便的进行链式调用而提供。然而,当在Map或者其他有键的集合上调用时,collection.toList()会丢弃键值,同时创建一个只有值的list,而List(collection)使用传入的元组创建list。
const { Map, List } = require('immutable')
var myMap = Map({ a: 'Apple', b: 'Banana' })
List(myMap) // List [ [ "a", "Apple" ], [ "b", "Banana" ] ]
myMap.toList() // List [ "Apple", "Banana" ]
toStack()
将此集合转换为Stack,丢弃键值,抛弃不可哈希的值。
toStack(): Stack<T>
注意:这和Stack(this)等效,为了能够方便的进行链式调用而提供。
读值
get()
返回提供的索引位置关联的值,或者当提供的索引越界时返回所提供的notSetValue。
get<NSV>(index: number, notSetValue: NSV): T | NSV
get(index: number): T | undefined
继承自
Collection.Indexed#get
index可以为负值,表示从集合尾部开始索引。s.get(-1)取得集合最后一个元素。
has()
使用Immutable.is判断key值是否在Collection中。
has(key: number): boolean
继承自
Collection#has
includes()
使用Immutable.is判断value值是否在Collection中。
includes(value: T): boolean
继承自
Collection#includes
first()
取得集合第一个值。
first(): T | undefined
继承自
Collection#first
last()
取得集合第一个值。
last(): T | undefined
继承自
Collection#last
读取深层数据
getIn()
返回根据提供的路径或者索引搜索到的嵌套的值。
getIn(searchKeyPath: Iterable<any>, notSetValue?: any): any
继承自
Collection#getIn
hasIn()
根据提供的路径或者索引检测该处是否设置了值。
hasIn(searchKeyPath: Iterable<any>): boolean
继承自
Collection#hasIn
转换为集合
toMap()
将此集合转换为Map,如果键不可哈希,则抛弃。
toMap(): Map<number, T>
继承自
Collection#toMap
注意:这和Map(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toOrderedMap()
将此集合转换为Map,保留索引的顺序。
toOrderedMap(): OrderedMap<number, T>
继承自
Collection#toOrderedMap
注意:这和OrderedMap(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toSet()
将此集合转换为Set,如果值不可哈希,则抛弃。
toSet(): Set<T>
继承自
Collection#toSet
注意:这和Set(this)等效,为了能够方便的进行链式调用而提供。
toOrderSet()
将此集合转换为Set,保留索引的顺序。
toOrderedSet(): OrderedSet<T>
继承自
Collection#toOrderedSet
注意:这和OrderedSet(this.valueSeq())等效,为了能够方便的进行链式调用而提供。
toList()
将此集合转换为List,丢弃键值。
toList(): List<T>
继承自
Collection#toList
此方法和List(collection)类似,为了能够方便的进行链式调用而提供。然而,当在Map或者其他有键的集合上调用时,collection.toList()会丢弃键值,同时创建一个只有值的list,而List(collection)使用传入的元组创建list。
const { Map, List } = require('immutable')
var myMap = Map({ a: 'Apple', b: 'Banana' })
List(myMap) // List [ [ "a", "Apple" ], [ "b", "Banana" ] ]
myMap.toList() // List [ "Apple", "Banana" ]
toStack()
将此集合转换为Stack,丢弃键值,抛弃不可哈希的值。
toStack(): Stack<T>
注意:这和Stack(this)等效,为了能够方便的进行链式调用而提供。
迭代器
keys()
一个关于Collection键的迭代器。
keys(): IterableIterator<number>
继承自
Collection#keys
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用keySeq来满足需求。
values()
一个关于Collection值的迭代器。
values(): IterableIterator<T>
继承自
Collection#values
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用valueSeq来满足需求。
entries()
一个关于Collection条目的迭代器,是[ key, value ]这样的元组数据。
entries(): IterableIterator<[number, T]>
继承自
Collection#entries
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用entrySeq来满足需求。
集合(Seq)
keySeq()
返回一个新的Seq.Indexed,其包含这个集合的键值。
keySeq(): Seq.Indexed<number>
继承自
Collection#keySeq
valueSeq()
返回一个新的Seq.Indexed,其包含这个集合的所有值。
valueSeq(): Seq.Indexed<T>
继承自
Collection#valueSeq
entrySeq()
返回一个新的Seq.Indexed,其为[key, value]这样的元组。
entrySeq(): Seq.Indexed<[number, T]>
继承自
Collection#entrySeq
副作用
forEach()
sideEffect将会对集合上每个元素执行。
forEach(
sideEffect: (value: T, key: number, iter: this) => any,
context?: any
): number
继承自
Collection#forEach
与Array#forEach不同,任意一个sideEffect返回false都会停止循环。函数将返回所有参与循环的元素(包括最后一个返回false的那个)。
创建子集
slice()
返回一个新的相同类型的相当于原集合指定范围的元素集合,包含开始索引但不包含结束索引位置的值。
slice(begin?: number, end?: number): this
继承自
Collection#slice
如果起始值为负,那么表示从集合结束开始查找。例如slice(-2)返回集合最后两个元素。如果没有提供,那么新的集合将会从最开始那个元素开始。
如果终止值为负,表示从集合结束开始查找。例如silice(0, -1)返回除集合最后一个元素外所有元素。如果没提供,新的集合将会包含到原集合最后一个元素。
如果请求的子集与原集合相等,那么将会返回原集合。
rest()
返回一个不包含原集合第一个元素的新的同类型的集合。
rest(): this
继承自
Collection#rest
butLast()
返回一个不包含原集合最后一个元素的新的同类型的集合。
butLast(): this
继承自
Collection#butLast
skip()
返回一个不包含原集合从头开始amount个数元素的新的同类型集合。
skip(amount: number): this
继承自
Collection#skip
skipLast()
返回一个不包含原集合从结尾开始amount个数元素的新的同类型集合。
skipLast(amount: number): this
继承自
Collection#skipLast
skipWhile()
返回一个原集合从predicate返回false那个元素开始的新的同类型集合。
skipWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipWhile(x => x.match(/g/))
// List [ "cat", "hat", "god" ]
skipUntil()
返回一个原集合从predicate返回true那个元素开始的新的同类型集合。
skipUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipUntil(x => x.match(/hat/))
// List [ "hat", "god"" ]
take()
返回一个包含原集合从头开始的amount个元素的新的同类型集合。
take(amount: number): this
继承自
Collection#take
takeLast()
返回一个包含从原集合结尾开始的amount个元素的新的同类型集合。
takeLast(amount: number): this
继承自
Collection#take
takeWhile()
返回一个包含原集合从头开始的prediacte返回true的那些元素的新的同类型集合。
takeWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeWhile(x => x.match(/o/))
// List [ "dog", "frog" ]
takeUntil()
返回一个包含原集合从头开始的prediacte返回false的那些元素的新的同类型集合。
takeUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeUntil(x => x.match(/at/))
// List [ "dog", "frog" ]
创建子集
slice()
返回一个新的相同类型的相当于原集合指定范围的元素集合,包含开始索引但不包含结束索引位置的值。
slice(begin?: number, end?: number): this
继承自
Collection#slice
如果起始值为负,那么表示从集合结束开始查找。例如slice(-2)返回集合最后两个元素。如果没有提供,那么新的集合将会从最开始那个元素开始。
如果终止值为负,表示从集合结束开始查找。例如silice(0, -1)返回除集合最后一个元素外所有元素。如果没提供,新的集合将会包含到原集合最后一个元素。
如果请求的子集与原集合相等,那么将会返回原集合。
rest()
返回一个不包含原集合第一个元素的新的同类型的集合。
rest(): this
继承自
Collection#rest
butLast()
返回一个不包含原集合最后一个元素的新的同类型的集合。
butLast(): this
继承自
Collection#butLast
skip()
返回一个不包含原集合从头开始amount个数元素的新的同类型集合。
skip(amount: number): this
继承自
Collection#skip
skipLast()
返回一个不包含原集合从结尾开始amount个数元素的新的同类型集合。
skipLast(amount: number): this
继承自
Collection#skipLast
skipWhile()
返回一个原集合从predicate返回false那个元素开始的新的同类型集合。
skipWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipWhile(x => x.match(/g/))
// List [ "cat", "hat", "god" ]
skipUntil()
返回一个原集合从predicate返回true那个元素开始的新的同类型集合。
skipUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipUntil(x => x.match(/hat/))
// List [ "hat", "god"" ]
take()
返回一个包含原集合从头开始的amount个元素的新的同类型集合。
take(amount: number): this
继承自
Collection#take
takeLast()
返回一个包含从原集合结尾开始的amount个元素的新的同类型集合。
takeLast(amount: number): this
继承自
Collection#take
takeWhile()
返回一个包含原集合从头开始的prediacte返回true的那些元素的新的同类型集合。
takeWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeWhile(x => x.match(/o/))
// List [ "dog", "frog" ]
takeUntil()
返回一个包含原集合从头开始的prediacte返回false的那些元素的新的同类型集合。
takeUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeUntil(x => x.match(/at/))
// List [ "dog", "frog" ]
组合
flatten()
压平嵌套的集合。
flatten(depth?: number): Collection<any, any>
flatten(shallow?: boolean): Collection<any, any>
继承自
Collection#flatten
默认会深度地经常压平集合操作,返回一个同类型的集合。可以指定depth为压平深度或者是否深度压平(为true表示仅进行一层的浅层压平)。如果深度为0(或者shllow:false)将会深层压平。
压平仅会操作其他集合,数组和对象不会进行此操作。
注意:flatten(true)操作是在集合上进行,同时返回一个集合。
减少值
reduce()
将传入的方法reducer在集合每个元素上调用并传递缩减值,以此来缩减集合的值。
reduce<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduce<R>(reducer: (reduction: T | R, value: T, key: number, iter: this) => R): R
继承自
Collection#reduce
见
Array#reduce
如果initialReduction未提供,那么将会使用集合第一个元素。
reduceRight()
逆向地缩减集合的值(从结尾开始)。
reduceRight<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduceRight<R>(
reducer: (reduction: T | R, value: T, key: number, iter: this) => R
): R
继承自
Collection#reduceRight
注意:与this.reverse().reduce()等效,为了与Array#reduceRight看齐而提供。
every()
当集合中所有元素predicate都判定为true时返回ture。
every(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#every
some()
当集合中任意元素predicate判定为true时返回ture。
some(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#some
join()
将值连接为字符串,并且在每两个值之间插入分割。默认分隔为","。
join(separator?: string): string
继承自
Collection#join
isEmpty()
当集合不包含值时返回true。
isEmpty(): boolean
继承自
Collection#isEmpty
对于惰性Seq,isEmpty会对他经常迭代来确定是否为空。至少会迭代一次。
count()
返回集合的大小。
count(): number
count(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number
继承自
Collection#count
不管此集合是否惰性地确定大小(某些Seq不能),这个方法将总是返回正确的大小。如果必要,他将会评估一个惰性的Seq。
如果predicate提供了,方法返回的数量将是集合中predicate返回true的元素个数。
countBy()
返回Seq.Keyed的数量,由grouper方法将值分组。
countBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Map<G, number>
注意:这不是一个惰性操作。
查找
find()
返回集合中第一个符合与所提供的断言的值。
find(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#find
findLast()
返回集合中最后一个符合与所提供的断言的值。
findLast(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#findLast
注意:predicate将会逆序地在每个值上调用。
findEntry()
返回第一个符合所提供断言的值的[key, value]。
findEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findEntry
findLastEntry()
返回最后一个符合所提供断言的值的[key, value]。
findLastEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findLastEntry
注意:predicate将会逆序地在每个值上调用。
findKey()
返回第一个predicate返回为true的键。
findKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findKey
findLastKey()
返回最后一个predicate返回为true的键。
findLastKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findLastKey
注意:predicate将会逆序地在每个值上调用。
keyOf()
返回与提供的搜索值关联的键,或者undefined。
keyOf(searchValue: T): number | undefined
继承自
Collection#keyOf
lastKeyOf()
返回最后一个与提供的搜索值关联的键或者undefined。
lastKeyOf(searchValue: T): number | undefined
继承自
Collection#lastKeyOf
max()
返回集合中最大的值。如果有多个值比较为相等,那么将返回第一个。
max(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#max
comparator的使用方法与Collection#sort是一样的,如果未提供那么默认的比较为>。
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么max将会独立于输入的顺序。默认的比较器>只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
maxBy()
和max类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
maxBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#maxBy
例
hitters.maxBy(hitter => hitter.avgHits)
min()
返回集合中最小的值,如果有多个值比较为相等,将会返回第一个。
min(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#min
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么min将会独立于输入的顺序。默认的比较器<只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
minBy()
和min类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
minBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#minBy
例
hitters.minBy(hitter => hitter.avgHits)
对比
isSubset()
如果iter包含集合中所有元素则返回true。
isSubset(iter: Iterable<T>): boolean
继承自
Collection#isSubset
isSuperset()
如果集合包含iter中所有元素则返回true。
isSuperset(iter: Iterable<T>): boolean
继承自
Collection#isSuperset
Stack
Stack(栈)是一种支持复杂度为O(1)的高效添加和删除数据的集合,在栈顶添加和删除数据使用unshift(v)和shift()。
class Stack<T> extends Collection.Indexed<T>
为照顾习惯,Stack提供了push(v),pop()和peek(),但请注意,这些都是在首部进行操作,这与List和JS数组不一样。
注意:reverse()或者任何从反方向的操作(reduceRight,lastIndexOf等)在Stack上都是效率不高的。
Stack是以单向链表实现的。
构造器
Stack()
使用提供的集合类值构建一个新的不可变Stack。
Stack(): Stack<any>
Stack<T>(): Stack<T>
Stack<T>(collection: Iterable<T>): Stack<T>
所提供的集合中的遍历顺序将会在生成的Stack中保存。
静态方法
Stack.isStack()
如果提供的值为Stack返回true。
Stack.isStack(maybeStack: any): boolean
Stack.of()
返回新的包含提供值的Stack。
Stack.of<T>(...values: Array<T>): Stack<T>
成员
size
size
读值
peek()
Stack.first()的别名。
peek(): T | undefined
get()
返回提供的索引位置关联的值,或者当提供的索引越界时返回所提供的notSetValue。
get<NSV>(index: number, notSetValue: NSV): T | NSV
get(index: number): T | undefined
继承自
Collection.Indexed#get
index可以为负值,表示从集合尾部开始索引。s.get(-1)取得集合最后一个元素。
has()
使用Immutable.is判断key值是否在Collection中。
has(key: number): boolean
继承自
Collection#has
includes()
使用Immutable.is判断value值是否在Collection中。
includes(value: T): boolean
继承自
Collection#includes
first()
取得集合第一个值。
first(): T | undefined
继承自
Collection#first
last()
取得集合第一个值。
last(): T | undefined
继承自
Collection#last
修改持久化
clear()
返回一个新的长度为0的不包含值的Stack。
claer(value: T): this
注意:claer可以在withMutations中使用。
unshift()
将提供的values放在原Stack首部,将其他值索引移至更高位,返回为新的Stack。
unshift(...values: Array<T>): Stack<T>
这个操作在Stack上非常高效。
注意:unshift可以在withMutations中使用。
unshiftAll()
和Stack#unshift相似,但接受一个集合而不是单个变量。
unshiftAll(iter: Iterable<T>): Stack<T>
注意:unshiftAll可以在withMutations中使用。
shift()
返回一个新的长度缩减一位的Stack,不包含原Stack第一位元素,将其他值索引移至更低位。
shift(): Stack<T>
注意:这与Array#shift效果不同,因其返回一个新的Stack而不是被移除的项。使用first()或者peek()来取得Stack中第一项值。
注意:shift可以在withMutations中使用。
push()
Stack#unshift的别名,与List#push不同。
push(...values: Array<T>): Stack<T>
pushAll()
Stack#unshiftAll的别名。
pushAll(iter: Iterable<T>): Stack<T>
pop()
Stack#shift的别名,与List#pop不同。
pop(): Stack<T>
update()
这将是一个很有用的方法来将两个普通方法进行链式调用。RxJS中为"let",lodash中为"thru"。
update<R>(updater: (value: this) => R): R
继承自
Collection#update
例如,在进行map和filter操作后计算总和操作:
const { Seq } = require('immutable')
function sum(collection) {
return collection.reduce((sum, x) => sum + x, 0)
}
Map({ x: 1, y: 2, z: 3 })
.map(x => x + 1)
.filter(x => x % 2 === 0)
.update(sum)
// 6
临时改变
withMutations()
注意:只有部分方法可以被可变的集合调用或者在withMutations中调用!查看文档中各个方法看他是否允许在withMuataions中调用。
withMutations(mutator: (mutable: this) => any): this
见
Map#withMutations
asMutable()
注意:只有部分方法可以被可变的集合调用或者在withMutations中调用!查看文档中各个方法看他是否允许在withMuataions中调用。
asMutable(): this
见
Map#asMutable
asImmutable()
asImmutable(): this
见
Map#asImmutable
序列算法
cancat()
将其他的值或者集合与这个Set串联起来返回为一个新Set。
concat<C>(...valuesOrCollections: Array<Iterable<C> | C>): Set<T | C>
覆盖
Collection#concat
map()
返回一个由传入的mapper函数处理过值的新Set。
map<M>(mapper: (value: T, key: number, iter: this) => M, context?: any): Set<M>
覆盖
Collection#map
例
Set([ 1, 2 ]).map(x => 10 * x)
// Set [ 10, 20 ]
注意:map()总是返回一个新的实例,即使它产出的每一个值都与原始值相同。
flatMap()
扁平化这个Set为一个新Set。
flatMap<M>(
mapper: (value: T, key: number, iter: this) => Iterable<M>,
context?: any
): Set<M>
覆盖
Collection#flatMap
与set.map(...).flatten(true)相似。
filter()
返回一个只有由传入方法predicate返回为true的值组成的新Set。
filter<F>(
predicate: (value: T, index: number, iter: this) => boolean,
context?: any
): Set<F>
filter(
predicate: (value: T, index: number, iter: this) => any,
context?: any
): this
覆盖
Collection#filter
注意:filter()总是返回一个新的实例,即使它的结果没有过滤掉任何一个值。
[Symbol.iterator]
[Symbol.iterator](): IterableIterator<T>
继承自
Collection.Set#[Symbol.iterator]
filterNot()
返回一个由所提供的predicate方法返回false过滤的新的相同类型的集合。
filterNot(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#filterNot
例
const { Map } = require('immutable')
Map({ a: 1, b: 2, c: 3, d: 4}).filterNot(x => x % 2 === 0)
// Map { "a": 1, "c": 3 }
注意:filterNot总是返回一个新的实例,即使它没有过滤掉任何一个值。
reverse()
返回为一个逆序的新的同类型集合。
reverse(): this
继承自
Collection#reverse
sort()
返回一个使用传入的comparator重新排序的新同类型集合。
sort(comparator?: (valueA: T, valueB: T) => number): this
继承自
Collection#sort
如果没有提供comparator方法,那么默认的比较将使用<和>。
comparator(valueA, valueB):
- 返回值为
0这个元素将不会被交换。 - 返回值为
-1(或者任意负数)valueA将会移到valueB之前。 - 返回值为
1(或者任意正数)valueA将会移到valueB之后。 - 为空,这将会返回相同的值和顺序。
当被排序的集合没有定义顺序,那么将会返回同等的有序集合。比如map.sort()将返回OrderedMap。
const { Map } = require('immutable')
Map({ "c": 3, "a": 1, "b": 2 }).sort((a, b) => {
if (a < b) { return -1; }
if (a > b) { return 1; }
if (a === b) { return 0; }
});
// OrderedMap { "a": 1, "b": 2, "c": 3 }
注意:sort()总是返回一个新的实例,即使它没有改变排序。
sortBy()
与sort类似,但能接受一个comparatorValueMapper方法,它允许通过更复杂的方式进行排序:
sortBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): this
继承自
Collection#sortBy
例
hitters.sortBy(hitter => hitter.avgHits)
注意:sortBy()总是返回一个新的实例,即使它没有改变排序。
groupBy()
返回一个Collection.Keyeds的Collection.keyed,由传入的grouper方法分组。
groupBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Seq.Keyed<G, Collection<number, T>>
继承自
Collection#groupBy
const { List, Map } = require('immutable')
const listOfMaps = List([
Map({ v: 0 }),
Map({ v: 1 }),
Map({ v: 1 }),
Map({ v: 0 }),
Map({ v: 2 })
])
const groupsOfMaps = listOfMaps.groupBy(x => x.get('v'))
// Map {
// 0: List [ Map{ "v": 0 }, Map { "v": 0 } ],
// 1: List [ Map{ "v": 1 }, Map { "v": 1 } ],
// 2: List [ Map{ "v": 2 } ],
// }
map()
返回一个由传入的mapper函数处理过值的新Set。
map<M>(mapper: (value: T, key: number, iter: this) => M, context?: any): Set<M>
覆盖
Collection#map
例
Set([ 1, 2 ]).map(x => 10 * x)
// Set [ 10, 20 ]
注意:map()总是返回一个新的实例,即使它产出的每一个值都与原始值相同。
flatMap()
扁平化这个Set为一个新Set。
flatMap<M>(
mapper: (value: T, key: number, iter: this) => Iterable<M>,
context?: any
): Set<M>
覆盖
Collection#flatMap
与set.map(...).flatten(true)相似。
filter()
返回一个只有由传入方法predicate返回为true的值组成的新Set。
filter<F>(
predicate: (value: T, index: number, iter: this) => boolean,
context?: any
): Set<F>
filter(
predicate: (value: T, index: number, iter: this) => any,
context?: any
): this
覆盖
Collection#filter
注意:filter()总是返回一个新的实例,即使它的结果没有过滤掉任何一个值。
[Symbol.iterator]
[Symbol.iterator](): IterableIterator<T>
继承自
Collection.Set#[Symbol.iterator]
filterNot()
返回一个由所提供的predicate方法返回false过滤的新的相同类型的集合。
filterNot(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#filterNot
例
const { Map } = require('immutable')
Map({ a: 1, b: 2, c: 3, d: 4}).filterNot(x => x % 2 === 0)
// Map { "a": 1, "c": 3 }
注意:filterNot总是返回一个新的实例,即使它没有过滤掉任何一个值。
reverse()
返回为一个逆序的新的同类型集合。
reverse(): this
继承自
Collection#reverse
sort()
返回一个使用传入的comparator重新排序的新同类型集合。
sort(comparator?: (valueA: T, valueB: T) => number): this
继承自
Collection#sort
如果没有提供comparator方法,那么默认的比较将使用<和>。
comparator(valueA, valueB):
- 返回值为
0这个元素将不会被交换。 - 返回值为
-1(或者任意负数)valueA将会移到valueB之前。 - 返回值为
1(或者任意正数)valueA将会移到valueB之后。 - 为空,这将会返回相同的值和顺序。
当被排序的集合没有定义顺序,那么将会返回同等的有序集合。比如map.sort()将返回OrderedMap。
const { Map } = require('immutable')
Map({ "c": 3, "a": 1, "b": 2 }).sort((a, b) => {
if (a < b) { return -1; }
if (a > b) { return 1; }
if (a === b) { return 0; }
});
// OrderedMap { "a": 1, "b": 2, "c": 3 }
注意:sort()总是返回一个新的实例,即使它没有改变排序。
sortBy()
与sort类似,但能接受一个comparatorValueMapper方法,它允许通过更复杂的方式进行排序:
sortBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): this
继承自
Collection#sortBy
例
hitters.sortBy(hitter => hitter.avgHits)
注意:sortBy()总是返回一个新的实例,即使它没有改变排序。
groupBy()
返回一个Collection.Keyeds的Collection.keyed,由传入的grouper方法分组。
groupBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Seq.Keyed<G, Collection<number, T>>
继承自
Collection#groupBy
const { List, Map } = require('immutable')
const listOfMaps = List([
Map({ v: 0 }),
Map({ v: 1 }),
Map({ v: 1 }),
Map({ v: 0 }),
Map({ v: 2 })
])
const groupsOfMaps = listOfMaps.groupBy(x => x.get('v'))
// Map {
// 0: List [ Map{ "v": 0 }, Map { "v": 0 } ],
// 1: List [ Map{ "v": 1 }, Map { "v": 1 } ],
// 2: List [ Map{ "v": 2 } ],
// }
转换为JavaScript类型
toJS()
深层地将这个有序的集合转换转换为原生JS数组。
toJS(): Array<any>
继承自
Collection.Index#toJS
toJSON()
浅转换这个有序的集合为原生JS数组。
toJSON(): Array<any>
继承自
Collection.Index#toJSON
toArray()
浅转换这个有序的集合为原生JS数组并且丢弃key。
toArray(): Array<any>
继承自
Collection#toArray
toObject()
浅转换这个有序的集合为原生JS对象。
toObject(): {[key: string]: V}
继承自
Collection#toObject
转换为Seq
toSeq()
返回Seq.Indexed。
toSeq(): Seq.Indexed<T>
继承自
Collection.Indexed#toSeq
fromEntrySeq()
如果这个集合是由[key, value]这种原组构成的,那么这将返回这些原组的Seq.Keyed。
fromEntrySeq(): Seq.Keyed<any, any>
继承自
Collection.Index#fromEntrySeq
toKeyedSeq()
从这个集合返回一个Seq.Keyed,其中索引将视作key。
toKeyedSeq(): Seq.Keyed<number, T>
继承自
Collection#toKeyedSeq
如果你想对Collection.Indexed操作返回一组[index, value]对,这将十分有用。
返回的Seq将与Colleciont有相同的索引顺序。
const { Seq } = require('immutable')
const indexedSeq = Seq([ 'A', 'B', 'C' ])
// Seq [ "A", "B", "C" ]
indexedSeq.filter(v => v === 'B')
// Seq [ "B" ]
const keyedSeq = indexedSeq.toKeyedSeq()
// Seq { 0: "A", 1: "B", 2: "C" }
keyedSeq.filter(v => v === 'B')
// Seq { 1: "B" }
toIndexedSeq()
将这个集合的值丢弃键(key)返回为Seq.Indexed。
toIndexedSeq(): Seq.Indexed<T>
继承自
Collection#toIndexedSeq
toSetSeq()
将这个集合的值丢弃键(key)返回为Seq.Set。
toSetSeq(): Seq.Set<T>
继承自
Collection#toSetSeq
组合
interpose()
返回一个在原集合每两个元素之间插入提供的separator的同类型集合。
interpose(separator: T): this
继承自
COllection.Indexed#interpose
interleave()
返回一个原集合与所提供collections交叉的痛类型集合。
interleave(...collections: Array<Collection<any, T>>): this
继承自
Collection.Indexed#interleave
返回的集合依次包含第一个集合元素与第二个集合元素。
const { List } = require('immutable')
List([ 1, 2, 3 ]).interleave(List([ 'A', 'B', 'C' ]))
// List [ 1, "A", 2, "B", 3, "C"" ]
由最短的集合结束交叉。
List([ 1, 2, 3 ]).interleave(
List([ 'A', 'B' ]),
List([ 'X', 'Y', 'Z' ])
)
// List [ 1, "A", "X", 2, "B", "Y"" ]
splice()
返回一个由指定值替换了原集合某个范围的值的新的有序集合。如果没提供替换的值,那么会跳过要删除的范围。
splice(index: number, removeNum: number, ...values: Array<T>): this
继承自
Collection.Indexed#splice
index可以为负值,表示从集合结尾开始索引。s.splice(-2)表示倒数第二个元素开始拼接。
const { List } = require('immutable')
List([ 'a', 'b', 'c', 'd' ]).splice(1, 2, 'q', 'r', 's')
// List [ "a", "q", "r", "s", "d" ]
flatten()
压平嵌套的集合。
flatten(depth?: number): Collection<any, any>
flatten(shallow?: boolean): Collection<any, any>
继承自
Collection#flatten
默认会深度地经常压平集合操作,返回一个同类型的集合。可以指定depth为压平深度或者是否深度压平(为true表示仅进行一层的浅层压平)。如果深度为0(或者shllow:false)将会深层压平。
压平仅会操作其他集合,数组和对象不会进行此操作。
注意:flatten(true)操作是在集合上进行,同时返回一个集合。
查找
indexOf()
返回集合中第一个与所提供的搜索值匹配的索引,无匹配值则返回-1。
indexOf(searchValue: T): number
继承自
Collection.Indexed#indexOf
lastIndexOf()
返回集合中最后一个与所提供的搜索值匹配的索引,无匹配值则返回-1。
lastIndexOf(searchValue: T): number
继承自
Collection.Indexed#lastIndexOf
findIndex()
返回集合中第一个符合与所提供的断言的索引,均不符合则返回-1。
findIndex(
predicate: (value: T, index: number, iter: this) => boolean,
context?: any
): number
继承自
Collection.Indexed#findIndex
findLastIndex()
返回集合中最后一个符合与所提供的断言的索引,均不符合则返回-1。
findLastIndex(
predicate: (value: T, index: number, iter: this) => boolean,
context?: any
): number
继承自
Collection.Indexed#findLastIndex
find()
返回集合中第一个符合与所提供的断言的值。
find(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#find
findLast()
返回集合中最后一个符合与所提供的断言的值。
findLast(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#findLast
注意:predicate将会逆序地在每个值上调用。
findEntry()
返回第一个符合所提供断言的值的[key, value]。
findEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findEntry
findLastEntry()
返回最后一个符合所提供断言的值的[key, value]。
findLastEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findLastEntry
注意:predicate将会逆序地在每个值上调用。
findKey()
返回第一个predicate返回为true的键。
findKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findKey
findLastKey()
返回最后一个predicate返回为true的键。
findLastKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findLastKey
注意:predicate将会逆序地在每个值上调用。
keyOf()
返回与提供的搜索值关联的键,或者undefined。
keyOf(searchValue: T): number | undefined
继承自
Collection#keyOf
lastKeyOf()
返回最后一个与提供的搜索值关联的键或者undefined。
lastKeyOf(searchValue: T): number | undefined
继承自
Collection#lastKeyOf
max()
返回集合中最大的值。如果有多个值比较为相等,那么将返回第一个。
max(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#max
comparator的使用方法与Collection#sort是一样的,如果未提供那么默认的比较为>。
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么max将会独立于输入的顺序。默认的比较器>只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
maxBy()
和max类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
maxBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#maxBy
例
hitters.maxBy(hitter => hitter.avgHits)
min()
返回集合中最小的值,如果有多个值比较为相等,将会返回第一个。
min(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#min
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么min将会独立于输入的顺序。默认的比较器<只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
minBy()
和min类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
minBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#minBy
例
hitters.minBy(hitter => hitter.avgHits)
查找
indexOf()
返回集合中第一个与所提供的搜索值匹配的索引,无匹配值则返回-1。
indexOf(searchValue: T): number
继承自
Collection.Indexed#indexOf
lastIndexOf()
返回集合中最后一个与所提供的搜索值匹配的索引,无匹配值则返回-1。
lastIndexOf(searchValue: T): number
继承自
Collection.Indexed#lastIndexOf
findIndex()
返回集合中第一个符合与所提供的断言的索引,均不符合则返回-1。
findIndex(
predicate: (value: T, index: number, iter: this) => boolean,
context?: any
): number
继承自
Collection.Indexed#findIndex
findLastIndex()
返回集合中最后一个符合与所提供的断言的索引,均不符合则返回-1。
findLastIndex(
predicate: (value: T, index: number, iter: this) => boolean,
context?: any
): number
继承自
Collection.Indexed#findLastIndex
find()
返回集合中第一个符合与所提供的断言的值。
find(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#find
findLast()
返回集合中最后一个符合与所提供的断言的值。
findLast(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#findLast
注意:predicate将会逆序地在每个值上调用。
findEntry()
返回第一个符合所提供断言的值的[key, value]。
findEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findEntry
findLastEntry()
返回最后一个符合所提供断言的值的[key, value]。
findLastEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findLastEntry
注意:predicate将会逆序地在每个值上调用。
findKey()
返回第一个predicate返回为true的键。
findKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findKey
findLastKey()
返回最后一个predicate返回为true的键。
findLastKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findLastKey
注意:predicate将会逆序地在每个值上调用。
keyOf()
返回与提供的搜索值关联的键,或者undefined。
keyOf(searchValue: T): number | undefined
继承自
Collection#keyOf
lastKeyOf()
返回最后一个与提供的搜索值关联的键或者undefined。
lastKeyOf(searchValue: T): number | undefined
继承自
Collection#lastKeyOf
max()
返回集合中最大的值。如果有多个值比较为相等,那么将返回第一个。
max(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#max
comparator的使用方法与Collection#sort是一样的,如果未提供那么默认的比较为>。
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么max将会独立于输入的顺序。默认的比较器>只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
maxBy()
和max类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
maxBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#maxBy
例
hitters.maxBy(hitter => hitter.avgHits)
min()
返回集合中最小的值,如果有多个值比较为相等,将会返回第一个。
min(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#min
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么min将会独立于输入的顺序。默认的比较器<只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
minBy()
和min类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
minBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#minBy
例
hitters.minBy(hitter => hitter.avgHits)
等值比较
equals()
如果当前集合和另一个集合比较为相等,那么返回true,是否相等由Immutable.is()定义。
equals(other: any): boolean
继承自
Collection#equals
注意:此方法与Immutable.is(this, other)等效,提供此方法是为了方便能够链式地使用。
hashCode()
计算并返回这个集合的哈希值。
hashCode(): number
继承自
Collection#hashCode
集合的hashCode用于确定两个集合的相等性,在添加到Set或者被作为Map的键值时用于检测两个实例是否相等而会被使用到。
const a = List([ 1, 2, 3 ]);
const b = List([ 1, 2, 3 ]);
assert(a !== b); // different instances
const set = Set([ a ]);
assert(set.has(b) === true);
当两个值的hashCode相等时,并不能完全保证他们是相等的,但当他们的hashCode不同时,他们一定是不等的。
读取深层数据
getIn()
返回根据提供的路径或者索引搜索到的嵌套的值。
getIn(searchKeyPath: Iterable<any>, notSetValue?: any): any
继承自
Collection#getIn
hasIn()
根据提供的路径或者索引检测该处是否设置了值。
hasIn(searchKeyPath: Iterable<any>): boolean
继承自
Collection#hasIn
转换为集合
toMap()
将此集合转换为Map,如果键不可哈希,则抛弃。
toMap(): Map<number, T>
继承自
Collection#toMap
注意:这和Map(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toOrderedMap()
将此集合转换为Map,保留索引的顺序。
toOrderedMap(): OrderedMap<number, T>
继承自
Collection#toOrderedMap
注意:这和OrderedMap(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toSet()
将此集合转换为Set,如果值不可哈希,则抛弃。
toSet(): Set<T>
继承自
Collection#toSet
注意:这和Set(this)等效,为了能够方便的进行链式调用而提供。
toOrderSet()
将此集合转换为Set,保留索引的顺序。
toOrderedSet(): OrderedSet<T>
继承自
Collection#toOrderedSet
注意:这和OrderedSet(this.valueSeq())等效,为了能够方便的进行链式调用而提供。
toList()
将此集合转换为List,丢弃键值。
toList(): List<T>
继承自
Collection#toList
此方法和List(collection)类似,为了能够方便的进行链式调用而提供。然而,当在Map或者其他有键的集合上调用时,collection.toList()会丢弃键值,同时创建一个只有值的list,而List(collection)使用传入的元组创建list。
const { Map, List } = require('immutable')
var myMap = Map({ a: 'Apple', b: 'Banana' })
List(myMap) // List [ [ "a", "Apple" ], [ "b", "Banana" ] ]
myMap.toList() // List [ "Apple", "Banana" ]
toStack()
将此集合转换为Stack,丢弃键值,抛弃不可哈希的值。
toStack(): Stack<T>
注意:这和Stack(this)等效,为了能够方便的进行链式调用而提供。
迭代器
keys()
一个关于Collection键的迭代器。
keys(): IterableIterator<number>
继承自
Collection#keys
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用keySeq来满足需求。
values()
一个关于Collection值的迭代器。
values(): IterableIterator<T>
继承自
Collection#values
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用valueSeq来满足需求。
entries()
一个关于Collection条目的迭代器,是[ key, value ]这样的元组数据。
entries(): IterableIterator<[number, T]>
继承自
Collection#entries
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用entrySeq来满足需求。
集合(Seq)
keySeq()
返回一个新的Seq.Indexed,其包含这个集合的键值。
keySeq(): Seq.Indexed<number>
继承自
Collection#keySeq
valueSeq()
返回一个新的Seq.Indexed,其包含这个集合的所有值。
valueSeq(): Seq.Indexed<T>
继承自
Collection#valueSeq
entrySeq()
返回一个新的Seq.Indexed,其为[key, value]这样的元组。
entrySeq(): Seq.Indexed<[number, T]>
继承自
Collection#entrySeq
副作用
forEach()
sideEffect将会对集合上每个元素执行。
forEach(
sideEffect: (value: T, key: number, iter: this) => any,
context?: any
): number
继承自
Collection#forEach
与Array#forEach不同,任意一个sideEffect返回false都会停止循环。函数将返回所有参与循环的元素(包括最后一个返回false的那个)。
创建子集
slice()
返回一个新的相同类型的相当于原集合指定范围的元素集合,包含开始索引但不包含结束索引位置的值。
slice(begin?: number, end?: number): this
继承自
Collection#slice
如果起始值为负,那么表示从集合结束开始查找。例如slice(-2)返回集合最后两个元素。如果没有提供,那么新的集合将会从最开始那个元素开始。
如果终止值为负,表示从集合结束开始查找。例如silice(0, -1)返回除集合最后一个元素外所有元素。如果没提供,新的集合将会包含到原集合最后一个元素。
如果请求的子集与原集合相等,那么将会返回原集合。
rest()
返回一个不包含原集合第一个元素的新的同类型的集合。
rest(): this
继承自
Collection#rest
butLast()
返回一个不包含原集合最后一个元素的新的同类型的集合。
butLast(): this
继承自
Collection#butLast
skip()
返回一个不包含原集合从头开始amount个数元素的新的同类型集合。
skip(amount: number): this
继承自
Collection#skip
skipLast()
返回一个不包含原集合从结尾开始amount个数元素的新的同类型集合。
skipLast(amount: number): this
继承自
Collection#skipLast
skipWhile()
返回一个原集合从predicate返回false那个元素开始的新的同类型集合。
skipWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipWhile(x => x.match(/g/))
// List [ "cat", "hat", "god" ]
skipUntil()
返回一个原集合从predicate返回true那个元素开始的新的同类型集合。
skipUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipUntil(x => x.match(/hat/))
// List [ "hat", "god"" ]
take()
返回一个包含原集合从头开始的amount个元素的新的同类型集合。
take(amount: number): this
继承自
Collection#take
takeLast()
返回一个包含从原集合结尾开始的amount个元素的新的同类型集合。
takeLast(amount: number): this
继承自
Collection#take
takeWhile()
返回一个包含原集合从头开始的prediacte返回true的那些元素的新的同类型集合。
takeWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeWhile(x => x.match(/o/))
// List [ "dog", "frog" ]
takeUntil()
返回一个包含原集合从头开始的prediacte返回false的那些元素的新的同类型集合。
takeUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeUntil(x => x.match(/at/))
// List [ "dog", "frog" ]
读取深层数据
getIn()
返回根据提供的路径或者索引搜索到的嵌套的值。
getIn(searchKeyPath: Iterable<any>, notSetValue?: any): any
继承自
Collection#getIn
hasIn()
根据提供的路径或者索引检测该处是否设置了值。
hasIn(searchKeyPath: Iterable<any>): boolean
继承自
Collection#hasIn
转换为集合
toMap()
将此集合转换为Map,如果键不可哈希,则抛弃。
toMap(): Map<number, T>
继承自
Collection#toMap
注意:这和Map(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toOrderedMap()
将此集合转换为Map,保留索引的顺序。
toOrderedMap(): OrderedMap<number, T>
继承自
Collection#toOrderedMap
注意:这和OrderedMap(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toSet()
将此集合转换为Set,如果值不可哈希,则抛弃。
toSet(): Set<T>
继承自
Collection#toSet
注意:这和Set(this)等效,为了能够方便的进行链式调用而提供。
toOrderSet()
将此集合转换为Set,保留索引的顺序。
toOrderedSet(): OrderedSet<T>
继承自
Collection#toOrderedSet
注意:这和OrderedSet(this.valueSeq())等效,为了能够方便的进行链式调用而提供。
toList()
将此集合转换为List,丢弃键值。
toList(): List<T>
继承自
Collection#toList
此方法和List(collection)类似,为了能够方便的进行链式调用而提供。然而,当在Map或者其他有键的集合上调用时,collection.toList()会丢弃键值,同时创建一个只有值的list,而List(collection)使用传入的元组创建list。
const { Map, List } = require('immutable')
var myMap = Map({ a: 'Apple', b: 'Banana' })
List(myMap) // List [ [ "a", "Apple" ], [ "b", "Banana" ] ]
myMap.toList() // List [ "Apple", "Banana" ]
toStack()
将此集合转换为Stack,丢弃键值,抛弃不可哈希的值。
toStack(): Stack<T>
注意:这和Stack(this)等效,为了能够方便的进行链式调用而提供。
迭代器
keys()
一个关于Collection键的迭代器。
keys(): IterableIterator<number>
继承自
Collection#keys
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用keySeq来满足需求。
values()
一个关于Collection值的迭代器。
values(): IterableIterator<T>
继承自
Collection#values
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用valueSeq来满足需求。
entries()
一个关于Collection条目的迭代器,是[ key, value ]这样的元组数据。
entries(): IterableIterator<[number, T]>
继承自
Collection#entries
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用entrySeq来满足需求。
集合(Seq)
keySeq()
返回一个新的Seq.Indexed,其包含这个集合的键值。
keySeq(): Seq.Indexed<number>
继承自
Collection#keySeq
valueSeq()
返回一个新的Seq.Indexed,其包含这个集合的所有值。
valueSeq(): Seq.Indexed<T>
继承自
Collection#valueSeq
entrySeq()
返回一个新的Seq.Indexed,其为[key, value]这样的元组。
entrySeq(): Seq.Indexed<[number, T]>
继承自
Collection#entrySeq
副作用
forEach()
sideEffect将会对集合上每个元素执行。
forEach(
sideEffect: (value: T, key: number, iter: this) => any,
context?: any
): number
继承自
Collection#forEach
与Array#forEach不同,任意一个sideEffect返回false都会停止循环。函数将返回所有参与循环的元素(包括最后一个返回false的那个)。
创建子集
slice()
返回一个新的相同类型的相当于原集合指定范围的元素集合,包含开始索引但不包含结束索引位置的值。
slice(begin?: number, end?: number): this
继承自
Collection#slice
如果起始值为负,那么表示从集合结束开始查找。例如slice(-2)返回集合最后两个元素。如果没有提供,那么新的集合将会从最开始那个元素开始。
如果终止值为负,表示从集合结束开始查找。例如silice(0, -1)返回除集合最后一个元素外所有元素。如果没提供,新的集合将会包含到原集合最后一个元素。
如果请求的子集与原集合相等,那么将会返回原集合。
rest()
返回一个不包含原集合第一个元素的新的同类型的集合。
rest(): this
继承自
Collection#rest
butLast()
返回一个不包含原集合最后一个元素的新的同类型的集合。
butLast(): this
继承自
Collection#butLast
skip()
返回一个不包含原集合从头开始amount个数元素的新的同类型集合。
skip(amount: number): this
继承自
Collection#skip
skipLast()
返回一个不包含原集合从结尾开始amount个数元素的新的同类型集合。
skipLast(amount: number): this
继承自
Collection#skipLast
skipWhile()
返回一个原集合从predicate返回false那个元素开始的新的同类型集合。
skipWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipWhile(x => x.match(/g/))
// List [ "cat", "hat", "god" ]
skipUntil()
返回一个原集合从predicate返回true那个元素开始的新的同类型集合。
skipUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipUntil(x => x.match(/hat/))
// List [ "hat", "god"" ]
take()
返回一个包含原集合从头开始的amount个元素的新的同类型集合。
take(amount: number): this
继承自
Collection#take
takeLast()
返回一个包含从原集合结尾开始的amount个元素的新的同类型集合。
takeLast(amount: number): this
继承自
Collection#take
takeWhile()
返回一个包含原集合从头开始的prediacte返回true的那些元素的新的同类型集合。
takeWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeWhile(x => x.match(/o/))
// List [ "dog", "frog" ]
takeUntil()
返回一个包含原集合从头开始的prediacte返回false的那些元素的新的同类型集合。
takeUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeUntil(x => x.match(/at/))
// List [ "dog", "frog" ]
减少值
reduce()
将传入的方法reducer在集合每个元素上调用并传递缩减值,以此来缩减集合的值。
reduce<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduce<R>(reducer: (reduction: T | R, value: T, key: number, iter: this) => R): R
继承自
Collection#reduce
见
Array#reduce
如果initialReduction未提供,那么将会使用集合第一个元素。
reduceRight()
逆向地缩减集合的值(从结尾开始)。
reduceRight<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduceRight<R>(
reducer: (reduction: T | R, value: T, key: number, iter: this) => R
): R
继承自
Collection#reduceRight
注意:与this.reverse().reduce()等效,为了与Array#reduceRight看齐而提供。
every()
当集合中所有元素predicate都判定为true时返回ture。
every(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#every
some()
当集合中任意元素predicate判定为true时返回ture。
some(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#some
join()
将值连接为字符串,并且在每两个值之间插入分割。默认分隔为","。
join(separator?: string): string
继承自
Collection#join
isEmpty()
当集合不包含值时返回true。
isEmpty(): boolean
继承自
Collection#isEmpty
对于惰性Seq,isEmpty会对他经常迭代来确定是否为空。至少会迭代一次。
count()
返回集合的大小。
count(): number
count(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number
继承自
Collection#count
不管此集合是否惰性地确定大小(某些Seq不能),这个方法将总是返回正确的大小。如果必要,他将会评估一个惰性的Seq。
如果predicate提供了,方法返回的数量将是集合中predicate返回true的元素个数。
countBy()
返回Seq.Keyed的数量,由grouper方法将值分组。
countBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Map<G, number>
注意:这不是一个惰性操作。
对比
isSubset()
如果iter包含集合中所有元素则返回true。
isSubset(iter: Iterable<T>): boolean
继承自
Collection#isSubset
isSuperset()
如果集合包含iter中所有元素则返回true。
isSuperset(iter: Iterable<T>): boolean
继承自
Collection#isSuperset
Range()
返回由Seq.Indexed指明的从start到end由step指定增量的数值(包含start,不包含end),默认值start为0,step为1,end为无穷大。当start与end相等时,返回一个空范围。
Range(start?: number, end?: number, step?: number): Seq.Indexed<number>
例
const { Range } = require('immutable')
Range() // [ 0, 1, 2, 3, ... ]
Range(10) // [ 10, 11, 12, 13, ... ]
Range(10, 15) // [ 10, 11, 12, 13, 14 ]
Range(10, 30, 5) // [ 10, 15, 20, 25 ]
Range(30, 10, 5) // [ 30, 25, 20, 15 ]
Range(30, 30, 5) // []
Repeat()
返回右Seq.Indexed指明的重复times次数的value,当times未定义时,返回值为无穷Seq的value。
Repeat<T>(value: T, times?: number): Seq.Indexed<T>
const { Repeat } = require('immutable')
Repeat('foo') // [ 'foo', 'foo', 'foo', ... ]
Repeat('bar', 4) // [ 'bar', 'bar', 'bar', 'bar' ]
Record
建立一个继承自Record的新类型。它类似于JS的对象,但需要明确指定可设置的键及其对应的值。
例
const { Record } = require('immutable')
const ABRecord = Record({ a: 1, b: 2 })
const myRecord = new ABRecord({ b: 3 })
Record中定义的键一定有对应的值。从Record中reomove一个键仅仅是为他设置了一个默认值。
myRecord.size // 2
myRecord.get('a') // 1
myRecord.get('b') // 3
const myRecordWithoutB = myRecord.remove('b')
myRecordWithoutB.get('b') // 2
myRecordWithoutB.size // 2
提供给构造器的值如果在Record类型定义中未出现,那么他将会被忽略。如,在这个情况下,ABRecord提供了"x"这个键而只有"a"和"b"两个键被定义了,那么在这个Record中,"x"的值将会被忽略。
const myRecord = new ABRecord({ b: 3, x: 10 })
myRecord.get('x') // undefined
因为Record拥有已知的键值集,所以通过属性取值将会正常运行,但设置值将会抛出异常。
注意:IE8不支持按属性取值。如需支持IE8请只使用get()。
myRecord.b // 3
myRecord.b = 5 // throws Error
Record类可被正常地继承,允许在其上自定义方法。这在函数式环境下并不是常见的样例,但出现在很多JS程序中。
class ABRecord extends Record({ a: 1, b: 2 }) {
getAB() {
return this.a + this.b;
}
}
var myRecord = new ABRecord({b: 3})
myRecord.getAB() // 4
构造器
Record()
Record<T>(defaultValues: T, name?: string): Record.Class<T>
静态方法
Record.isRecord()
如果提供的值为Record返回true。
Record.isRecord(maybeRecord: any): boolean
Record.getDescriptiveName()
Record允许通过第二个参数来定义其描述名称,当转换Record为字符串或者在错误信息中展示。任意Record的描述名称可以通过此方法来获取。未定义情况下将返回"Record"。
Record.getDescriptiveName(record: Instance<any>): string
例
const { Record } = require('immutable')
const Person = Record({
name: null
}, 'Person')
var me = Person({ name: 'My Name' })
me.toString() // "Person { "name": "My Name" }"
Record.getDescriptiveName(me) // "Person"
类型
Record.Class
Seq
相当于一系列值,但不能具体表现为某种数据结构。
class Seq<K, V> extends Collection<K, V>
Seq是不可变的 — 一旦Seq被创建,他将不可被修改、添加值、重新排序以及其它形式地修改。所以,任何应用于Seq的方法都将创建一个新的Seq。
Seq是懒惰的(lazy) — Seq会为回应任意方法的调用做一些微小的工作。值通常都将在迭代中被创建,包括隐式的在缩减操作(reduce)或者转换为类似List或JS数组这类强结构数据时。
例如,以下操作将不会执行,因为生成的Seq的值没有被迭代:
const { Seq } = require('immutable')
const oddSquares = Seq([ 1, 2, 3, 4, 5, 6, 7, 8 ])
.filter(x => x % 2 !== 0)
.map(x => x * x)
当Seq被使用时,也将只有被需要的操作才会执行。在以下样例中,没有临时的数据结构会被创建,filter将只会被调用三次,map则仅会调用一次:
oddSquares.get(1); // 9
Seq能够进行高效地链式操作,可以有效的表达用其它方式可能非常乏味的逻辑。
Seq({ a: 1, b: 1, c: 1})
.flip()
.map(key => key.toUpperCase())
.flip()
// Seq { A: 1, B: 1, C: 1 }
同时也可以表达用其它方式可能非常消耗内存或者时间的逻辑:
const { Range } = require('immutable')
Range(1, Infinity)
.skip(1000)
.map(n => -n)
.filter(n => n % 2 === 0)
.take(2)
.reduce((r, n) => r * n, 1)
// 1006008
Seq通常用来为API提供丰富集合的JS对象。
Seq({ x: 0, y: 1, z: 2 }).map(v => v * 2).toObject();
// { x: 0, y: 2, z: 4 }
构造器
Seq()
创建一个Seq。
Seq<S>(seq: S): S
Seq<K, V>(collection: Collection.Keyed<K, V>): Seq.Keyed<K, V>
Seq<T>(collection: Collection.Indexed<T>): Seq.Indexed<T>
Seq<T>(collection: Collection.Set<T>): Seq.Set<T>
Seq<T>(collection: Iterable<T>): Seq.Indexed<T>
Seq<V>(obj: {[key: string]: V}): Seq.Keyed<string, V>
Seq(): Seq<any, any>
返回一个基于输入的特定类型的Seq。
- 当输入为
Seq,则返回同样为Seq - 当输入为
Collection,则返回同类型(Keyed, Indexed 或者 Set)的Seq - 当输入为数组类似时,返回
Seq.Indexed。 - 当输入为具有迭代器(Iterator)的对象时,返回
Seq.Indexed。 - 当输入为迭代器(Iterator)时,返回
Seq.Indexed。 - 当输入为对象时,返回
Seq.Keyed。
静态方法
Seq.isSeq()
如果输入为Seq则返回True,他不会强类型数据结构支持如Map,List或者Set。
Seq.isSeq(maybeSeq: any): boolean
Seq.of()
用输入值创建一个Seq。Seq.Indexed.of()的别名。
Seq.of<T>(...values: Array<T>): Seq.Indexed<T>
类型
Seq.Keyed
成员
size
size
强制估值
cacheResult()
由于Seq是懒计算的同时为链式设计的,他们不会缓存结果。例如,这个map方法总共调用了6次,每个Seq的join迭代3三次。
cacheResult(): this
例
var squares = Seq([ 1, 2, 3 ]).map(x => x * x)
squares.join() + squares.join()
如果你知道某个Seq会被使用多次,将其缓存在内存中将可能更加高效。以下,map方法只调用了三次。
var squares = Seq([ 1, 2, 3 ]).map(x => x * x).cacheResult()
squares.join() + squares.join()
请谨慎使用这个方法,因为他会完整地估算Seq这可能会对性能和内存造成负担。
注意:调用cacheResult之后,Seq将一直拥有size。
序列算法
map()
返回一个由传入的mapper函数处理过值的新Set。
map<M>(mapper: (value: T, key: number, iter: this) => M, context?: any): Set<M>
覆盖
Collection#map
例
Set([ 1, 2 ]).map(x => 10 * x)
// Set [ 10, 20 ]
注意:map()总是返回一个新的实例,即使它产出的每一个值都与原始值相同。
flatMap()
扁平化这个Set为一个新Set。
flatMap<M>(
mapper: (value: T, key: number, iter: this) => Iterable<M>,
context?: any
): Set<M>
覆盖
Collection#flatMap
与set.map(...).flatten(true)相似。
filter()
返回一个只有由传入方法predicate返回为true的值组成的新Set。
filter<F>(
predicate: (value: T, index: number, iter: this) => boolean,
context?: any
): Set<F>
filter(
predicate: (value: T, index: number, iter: this) => any,
context?: any
): this
覆盖
Collection#filter
注意:filter()总是返回一个新的实例,即使它的结果没有过滤掉任何一个值。
filterNot()
返回一个由所提供的predicate方法返回false过滤的新的相同类型的集合。
filterNot(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#filterNot
例
const { Map } = require('immutable')
Map({ a: 1, b: 2, c: 3, d: 4}).filterNot(x => x % 2 === 0)
// Map { "a": 1, "c": 3 }
注意:filterNot总是返回一个新的实例,即使它没有过滤掉任何一个值。
reverse()
返回为一个逆序的新的同类型集合。
reverse(): this
继承自
Collection#reverse
sort()
返回一个使用传入的comparator重新排序的新同类型集合。
sort(comparator?: (valueA: T, valueB: T) => number): this
继承自
Collection#sort
如果没有提供comparator方法,那么默认的比较将使用<和>。
comparator(valueA, valueB):
- 返回值为
0这个元素将不会被交换。 - 返回值为
-1(或者任意负数)valueA将会移到valueB之前。 - 返回值为
1(或者任意正数)valueA将会移到valueB之后。 - 为空,这将会返回相同的值和顺序。
当被排序的集合没有定义顺序,那么将会返回同等的有序集合。比如map.sort()将返回OrderedMap。
const { Map } = require('immutable')
Map({ "c": 3, "a": 1, "b": 2 }).sort((a, b) => {
if (a < b) { return -1; }
if (a > b) { return 1; }
if (a === b) { return 0; }
});
// OrderedMap { "a": 1, "b": 2, "c": 3 }
注意:sort()总是返回一个新的实例,即使它没有改变排序。
sortBy()
与sort类似,但能接受一个comparatorValueMapper方法,它允许通过更复杂的方式进行排序:
sortBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): this
继承自
Collection#sortBy
例
hitters.sortBy(hitter => hitter.avgHits)
注意:sortBy()总是返回一个新的实例,即使它没有改变排序。
groupBy()
返回一个Collection.Keyeds的Collection.keyed,由传入的grouper方法分组。
groupBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Seq.Keyed<G, Collection<number, T>>
继承自
Collection#groupBy
const { List, Map } = require('immutable')
const listOfMaps = List([
Map({ v: 0 }),
Map({ v: 1 }),
Map({ v: 1 }),
Map({ v: 0 }),
Map({ v: 2 })
])
const groupsOfMaps = listOfMaps.groupBy(x => x.get('v'))
// Map {
// 0: List [ Map{ "v": 0 }, Map { "v": 0 } ],
// 1: List [ Map{ "v": 1 }, Map { "v": 1 } ],
// 2: List [ Map{ "v": 2 } ],
// }
等值比较
equals()
如果当前集合和另一个集合比较为相等,那么返回true,是否相等由Immutable.is()定义。
equals(other: any): boolean
继承自
Collection#equals
注意:此方法与Immutable.is(this, other)等效,提供此方法是为了方便能够链式地使用。
hashCode()
计算并返回这个集合的哈希值。
hashCode(): number
继承自
Collection#hashCode
集合的hashCode用于确定两个集合的相等性,在添加到Set或者被作为Map的键值时用于检测两个实例是否相等而会被使用到。
const a = List([ 1, 2, 3 ]);
const b = List([ 1, 2, 3 ]);
assert(a !== b); // different instances
const set = Set([ a ]);
assert(set.has(b) === true);
当两个值的hashCode相等时,并不能完全保证他们是相等的,但当他们的hashCode不同时,他们一定是不等的。
读值
get()
返回提供的索引位置关联的值,或者当提供的索引越界时返回所提供的notSetValue。
get<NSV>(index: number, notSetValue: NSV): T | NSV
get(index: number): T | undefined
继承自
Collection.Indexed#get
index可以为负值,表示从集合尾部开始索引。s.get(-1)取得集合最后一个元素。
has()
使用Immutable.is判断key值是否在Collection中。
has(key: number): boolean
继承自
Collection#has
includes()
使用Immutable.is判断value值是否在Collection中。
includes(value: T): boolean
继承自
Collection#includes
first()
取得集合第一个值。
first(): T | undefined
继承自
Collection#first
last()
取得集合第一个值。
last(): T | undefined
继承自
Collection#last
读取深层数据
getIn()
返回根据提供的路径或者索引搜索到的嵌套的值。
getIn(searchKeyPath: Iterable<any>, notSetValue?: any): any
继承自
Collection#getIn
hasIn()
根据提供的路径或者索引检测该处是否设置了值。
hasIn(searchKeyPath: Iterable<any>): boolean
继承自
Collection#hasIn
修改持久化
update()
这将是一个很有用的方法来将两个普通方法进行链式调用。RxJS中为"let",lodash中为"thru"。
update<R>(updater: (value: this) => R): R
继承自
Collection#update
例如,在进行map和filter操作后计算总和操作:
const { Seq } = require('immutable')
function sum(collection) {
return collection.reduce((sum, x) => sum + x, 0)
}
Map({ x: 1, y: 2, z: 3 })
.map(x => x + 1)
.filter(x => x % 2 === 0)
.update(sum)
// 6
转换为JavaScript类型
toJS()
深层地将这个有序的集合转换转换为原生JS数组。
toJS(): Array<any>
继承自
Collection.Index#toJS
toJSON()
浅转换这个有序的集合为原生JS数组。
toJSON(): Array<any>
继承自
Collection.Index#toJSON
toArray()
浅转换这个有序的集合为原生JS数组并且丢弃key。
toArray(): Array<any>
继承自
Collection#toArray
toObject()
浅转换这个有序的集合为原生JS对象。
toObject(): {[key: string]: V}
继承自
Collection#toObject
转换为JavaScript类型
toJS()
深层地将这个有序的集合转换转换为原生JS数组。
toJS(): Array<any>
继承自
Collection.Index#toJS
toJSON()
浅转换这个有序的集合为原生JS数组。
toJSON(): Array<any>
继承自
Collection.Index#toJSON
toArray()
浅转换这个有序的集合为原生JS数组并且丢弃key。
toArray(): Array<any>
继承自
Collection#toArray
toObject()
浅转换这个有序的集合为原生JS对象。
toObject(): {[key: string]: V}
继承自
Collection#toObject
转换为Seq
toSeq()
返回Seq.Indexed。
toSeq(): Seq.Indexed<T>
继承自
Collection.Indexed#toSeq
fromEntrySeq()
如果这个集合是由[key, value]这种原组构成的,那么这将返回这些原组的Seq.Keyed。
fromEntrySeq(): Seq.Keyed<any, any>
继承自
Collection.Index#fromEntrySeq
toKeyedSeq()
从这个集合返回一个Seq.Keyed,其中索引将视作key。
toKeyedSeq(): Seq.Keyed<number, T>
继承自
Collection#toKeyedSeq
如果你想对Collection.Indexed操作返回一组[index, value]对,这将十分有用。
返回的Seq将与Colleciont有相同的索引顺序。
const { Seq } = require('immutable')
const indexedSeq = Seq([ 'A', 'B', 'C' ])
// Seq [ "A", "B", "C" ]
indexedSeq.filter(v => v === 'B')
// Seq [ "B" ]
const keyedSeq = indexedSeq.toKeyedSeq()
// Seq { 0: "A", 1: "B", 2: "C" }
keyedSeq.filter(v => v === 'B')
// Seq { 1: "B" }
toIndexedSeq()
将这个集合的值丢弃键(key)返回为Seq.Indexed。
toIndexedSeq(): Seq.Indexed<T>
继承自
Collection#toIndexedSeq
toSetSeq()
将这个集合的值丢弃键(key)返回为Seq.Set。
toSetSeq(): Seq.Set<T>
继承自
Collection#toSetSeq
迭代器
keys()
一个关于Collection键的迭代器。
keys(): IterableIterator<number>
继承自
Collection#keys
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用keySeq来满足需求。
values()
一个关于Collection值的迭代器。
values(): IterableIterator<T>
继承自
Collection#values
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用valueSeq来满足需求。
entries()
一个关于Collection条目的迭代器,是[ key, value ]这样的元组数据。
entries(): IterableIterator<[number, T]>
继承自
Collection#entries
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用entrySeq来满足需求。
集合(Seq)
keySeq()
返回一个新的Seq.Indexed,其包含这个集合的键值。
keySeq(): Seq.Indexed<number>
继承自
Collection#keySeq
valueSeq()
返回一个新的Seq.Indexed,其包含这个集合的所有值。
valueSeq(): Seq.Indexed<T>
继承自
Collection#valueSeq
entrySeq()
返回一个新的Seq.Indexed,其为[key, value]这样的元组。
entrySeq(): Seq.Indexed<[number, T]>
继承自
Collection#entrySeq
副作用
forEach()
sideEffect将会对集合上每个元素执行。
forEach(
sideEffect: (value: T, key: number, iter: this) => any,
context?: any
): number
继承自
Collection#forEach
与Array#forEach不同,任意一个sideEffect返回false都会停止循环。函数将返回所有参与循环的元素(包括最后一个返回false的那个)。
创建子集
slice()
返回一个新的相同类型的相当于原集合指定范围的元素集合,包含开始索引但不包含结束索引位置的值。
slice(begin?: number, end?: number): this
继承自
Collection#slice
如果起始值为负,那么表示从集合结束开始查找。例如slice(-2)返回集合最后两个元素。如果没有提供,那么新的集合将会从最开始那个元素开始。
如果终止值为负,表示从集合结束开始查找。例如silice(0, -1)返回除集合最后一个元素外所有元素。如果没提供,新的集合将会包含到原集合最后一个元素。
如果请求的子集与原集合相等,那么将会返回原集合。
rest()
返回一个不包含原集合第一个元素的新的同类型的集合。
rest(): this
继承自
Collection#rest
butLast()
返回一个不包含原集合最后一个元素的新的同类型的集合。
butLast(): this
继承自
Collection#butLast
skip()
返回一个不包含原集合从头开始amount个数元素的新的同类型集合。
skip(amount: number): this
继承自
Collection#skip
skipLast()
返回一个不包含原集合从结尾开始amount个数元素的新的同类型集合。
skipLast(amount: number): this
继承自
Collection#skipLast
skipWhile()
返回一个原集合从predicate返回false那个元素开始的新的同类型集合。
skipWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipWhile(x => x.match(/g/))
// List [ "cat", "hat", "god" ]
skipUntil()
返回一个原集合从predicate返回true那个元素开始的新的同类型集合。
skipUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#skipUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipUntil(x => x.match(/hat/))
// List [ "hat", "god"" ]
take()
返回一个包含原集合从头开始的amount个元素的新的同类型集合。
take(amount: number): this
继承自
Collection#take
takeLast()
返回一个包含从原集合结尾开始的amount个元素的新的同类型集合。
takeLast(amount: number): this
继承自
Collection#take
takeWhile()
返回一个包含原集合从头开始的prediacte返回true的那些元素的新的同类型集合。
takeWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeWhile
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeWhile(x => x.match(/o/))
// List [ "dog", "frog" ]
takeUntil()
返回一个包含原集合从头开始的prediacte返回false的那些元素的新的同类型集合。
takeUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
继承自
Collection#takeUntil
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeUntil(x => x.match(/at/))
// List [ "dog", "frog" ]
组合
cancat()
将其他的值或者集合与这个Set串联起来返回为一个新Set。
concat<C>(...valuesOrCollections: Array<Iterable<C> | C>): Set<T | C>
覆盖
Collection#concat
在Seq中,所有元素都会在生成的Seq中出现,即使他们有相同的键。
flatten()
压平嵌套的集合。
flatten(depth?: number): Collection<any, any>
flatten(shallow?: boolean): Collection<any, any>
继承自
Collection#flatten
默认会深度地经常压平集合操作,返回一个同类型的集合。可以指定depth为压平深度或者是否深度压平(为true表示仅进行一层的浅层压平)。如果深度为0(或者shllow:false)将会深层压平。
压平仅会操作其他集合,数组和对象不会进行此操作。
注意:flatten(true)操作是在集合上进行,同时返回一个集合。
减少值
reduce()
将传入的方法reducer在集合每个元素上调用并传递缩减值,以此来缩减集合的值。
reduce<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduce<R>(reducer: (reduction: T | R, value: T, key: number, iter: this) => R): R
继承自
Collection#reduce
见
Array#reduce
如果initialReduction未提供,那么将会使用集合第一个元素。
reduceRight()
逆向地缩减集合的值(从结尾开始)。
reduceRight<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduceRight<R>(
reducer: (reduction: T | R, value: T, key: number, iter: this) => R
): R
继承自
Collection#reduceRight
注意:与this.reverse().reduce()等效,为了与Array#reduceRight看齐而提供。
every()
当集合中所有元素predicate都判定为true时返回ture。
every(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#every
some()
当集合中任意元素predicate判定为true时返回ture。
some(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
继承自
Collection#some
join()
将值连接为字符串,并且在每两个值之间插入分割。默认分隔为","。
join(separator?: string): string
继承自
Collection#join
isEmpty()
当集合不包含值时返回true。
isEmpty(): boolean
继承自
Collection#isEmpty
对于惰性Seq,isEmpty会对他经常迭代来确定是否为空。至少会迭代一次。
count()
返回集合的大小。
count(): number
count(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number
继承自
Collection#count
不管此集合是否惰性地确定大小(某些Seq不能),这个方法将总是返回正确的大小。如果必要,他将会评估一个惰性的Seq。
如果predicate提供了,方法返回的数量将是集合中predicate返回true的元素个数。
countBy()
返回Seq.Keyed的数量,由grouper方法将值分组。
countBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Map<G, number>
注意:这不是一个惰性操作。
查找
find()
返回集合中第一个符合与所提供的断言的值。
find(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#find
findLast()
返回集合中最后一个符合与所提供的断言的值。
findLast(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
继承自
Collection#findLast
注意:predicate将会逆序地在每个值上调用。
findEntry()
返回第一个符合所提供断言的值的[key, value]。
findEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findEntry
findLastEntry()
返回最后一个符合所提供断言的值的[key, value]。
findLastEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
继承自
Collection#findLastEntry
注意:predicate将会逆序地在每个值上调用。
findKey()
返回第一个predicate返回为true的键。
findKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findKey
findLastKey()
返回最后一个predicate返回为true的键。
findLastKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
继承自
Collection#findLastKey
注意:predicate将会逆序地在每个值上调用。
keyOf()
返回与提供的搜索值关联的键,或者undefined。
keyOf(searchValue: T): number | undefined
继承自
Collection#keyOf
lastKeyOf()
返回最后一个与提供的搜索值关联的键或者undefined。
lastKeyOf(searchValue: T): number | undefined
继承自
Collection#lastKeyOf
max()
返回集合中最大的值。如果有多个值比较为相等,那么将返回第一个。
max(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#max
comparator的使用方法与Collection#sort是一样的,如果未提供那么默认的比较为>。
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么max将会独立于输入的顺序。默认的比较器>只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
maxBy()
和max类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
maxBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#maxBy
例
hitters.maxBy(hitter => hitter.avgHits)
min()
返回集合中最小的值,如果有多个值比较为相等,将会返回第一个。
min(comparator?: (valueA: T, valueB: T) => number): T | undefined
继承自
Collection#min
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么min将会独立于输入的顺序。默认的比较器<只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
minBy()
和min类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
minBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
继承自
Collection#minBy
例
hitters.minBy(hitter => hitter.avgHits)
对比
isSubset()
如果iter包含集合中所有元素则返回true。
isSubset(iter: Iterable<T>): boolean
继承自
Collection#isSubset
isSuperset()
如果集合包含iter中所有元素则返回true。
isSuperset(iter: Iterable<T>): boolean
继承自
Collection#isSuperset
Collection
Collection是一组可迭代的键值对集合,它也是所有immutable的基类,确保它们能使用集合的方法(如map,filter)。
class Collection<K, V> extends ValueObject
注意:一个集合的迭代顺序将是固定的,尽管这个顺序不总是能定义,如Map和Set那样。
Collection对于实际的数据结构是抽象的基类,他不能被直接的实例化。
实例化他需要扩展以下任意一个子类,Collection.Keyed, Collection.Indexed或者 Collection.Set.
构造器
Collection()
构造一个Collection。
Collection<I>(collection: I): I
Collection<T>(collection: Iterable<T>): Collection.Indexed<T>
Collection<V>(obj: {[key: string]: V}): Collection.Keyed<string, V>
生成的集合类型将取决于输入。
- 当输入为
Collection,则返回同样为Collection - 当输入为
Collection,则返回同类型(Keyed, Indexed 或者 Set)的Collection - 当输入为数组类似时,返回
Collection.Indexed。 - 当输入为具有迭代器(Iterator)的对象时,返回
Collection.Indexed。 - 当输入为迭代器(Iterator)时,返回
Collection.Indexed。 - 当输入为对象时,返回
Collection.Keyed。
此方法强制将对象和字符串转换为collection,如果你希望确保返回值为Collectin,请使用Seq.of。
类型
Collection.Keyed
等值比较
equals()
如果当前集合和另一个集合比较为相等,那么返回true,是否相等由Immutable.is()定义。
equals(other: any): boolean
覆盖
ValueObject#equals
注意:此方法与Immutable.is(this, other)等效,提供此方法是为了方便能够链式地使用。
hashCode()
计算并返回这个集合的哈希值。
hashCode(): number
覆盖
ValueObject#hashCode
集合的hashCode用于确定两个集合的相等性,在添加到Set或者被作为Map的键值时用于检测两个实例是否相等而会被使用到。
const a = List([ 1, 2, 3 ]);
const b = List([ 1, 2, 3 ]);
assert(a !== b); // different instances
const set = Set([ a ]);
assert(set.has(b) === true);
当两个值的hashCode相等时,并不能完全保证他们是相等的,但当他们的hashCode不同时,他们一定是不等的。
等值比较
equals()
如果当前集合和另一个集合比较为相等,那么返回true,是否相等由Immutable.is()定义。
equals(other: any): boolean
注意:此方法与Immutable.is(this, other)等效,提供此方法是为了方便能够链式地使用。
hashCode()
计算并返回这个集合的哈希值。
hashCode(): number
集合的hashCode用于确定两个集合的相等性,在添加到Set或者被作为Map的键值时用于检测两个实例是否相等而会被使用到。
const a = List([ 1, 2, 3 ]);
const b = List([ 1, 2, 3 ]);
assert(a !== b); // different instances
const set = Set([ a ]);
assert(set.has(b) === true);
当两个值的hashCode相等时,并不能完全保证他们是相等的,但当他们的hashCode不同时,他们一定是不等的。
读值
get()
返回提供的索引位置关联的值,或者当提供的索引越界时返回所提供的notSetValue。
get<NSV>(index: number, notSetValue: NSV): T | NSV
get(index: number): T | undefined
注意:某个键对于的值为undefined是可能的,说以如果notSetValue没被提供时将会返回undefined,不能用这个来确认是否为键值不存在。
has()
使用Immutable.is判断key值是否在Collection中。
has(key: number): boolean
includes()
使用Immutable.is判断value值是否在Collection中。
includes(value: T): boolean
别名
contains()
first()
取得集合第一个值。
first(): T | undefined
last()
取得集合第一个值。
last(): T | undefined
等值比较
equals()
如果当前集合和另一个集合比较为相等,那么返回true,是否相等由Immutable.is()定义。
equals(other: any): boolean
注意:此方法与Immutable.is(this, other)等效,提供此方法是为了方便能够链式地使用。
hashCode()
计算并返回这个集合的哈希值。
hashCode(): number
集合的hashCode用于确定两个集合的相等性,在添加到Set或者被作为Map的键值时用于检测两个实例是否相等而会被使用到。
const a = List([ 1, 2, 3 ]);
const b = List([ 1, 2, 3 ]);
assert(a !== b); // different instances
const set = Set([ a ]);
assert(set.has(b) === true);
当两个值的hashCode相等时,并不能完全保证他们是相等的,但当他们的hashCode不同时,他们一定是不等的。
读值
get()
返回提供的索引位置关联的值,或者当提供的索引越界时返回所提供的notSetValue。
get<NSV>(index: number, notSetValue: NSV): T | NSV
get(index: number): T | undefined
继承自
Collection.Indexed#get
index可以为负值,表示从集合尾部开始索引。s.get(-1)取得集合最后一个元素。
has()
使用Immutable.is判断key值是否在Collection中。
has(key: number): boolean
includes()
使用Immutable.is判断value值是否在Collection中。
includes(value: T): boolean
first()
取得集合第一个值。
first(): T | undefined
last()
取得集合第一个值。
last(): T | undefined
读取深层数据
getIn()
返回根据提供的路径或者索引搜索到的嵌套的值。
getIn(searchKeyPath: Iterable<any>, notSetValue?: any): any
hasIn()
根据提供的路径或者索引检测该处是否设置了值。
hasIn(searchKeyPath: Iterable<any>): boolean
修改持久化
update()
这将是一个很有用的方法来将两个普通方法进行链式调用。RxJS中为"let",lodash中为"thru"。
update<R>(updater: (value: this) => R): R
例如,在进行map和filter操作后计算总和操作:
const { Seq } = require('immutable')
function sum(collection) {
return collection.reduce((sum, x) => sum + x, 0)
}
Map({ x: 1, y: 2, z: 3 })
.map(x => x + 1)
.filter(x => x % 2 === 0)
.update(sum)
// 6
转换为JavaScript类型
toJS()
深层地将这个有序的集合转换转换为原生JS数组或对象。
toJS(): Array<any>
Collection.Index与Collection.Set转换为Array,而Collection.Keyed转换为Object键将会转换为字符串。
toJSON()
浅转换这个有序的集合为原生JS数组或对象。
toJSON(): Array<any>
Collection.Index与Collection.Set转换为Array,而Collection.Keyed转换为Object键将会转换为字符串。
toArray()
浅转换这个有序的集合为原生JS数组并且丢弃key。
toArray(): Array<any>
toObject()
浅转换这个有序的集合为原生JS对象。
toObject(): {[key: string]: V}
转换为集合
toMap()
将此集合转换为Map,如果键不可哈希,则抛弃。
toMap(): Map<number, T>
注意:这和Map(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toOrderedMap()
将此集合转换为Map,保留索引的顺序。
toOrderedMap(): OrderedMap<number, T>
注意:这和OrderedMap(this.toKeyedSeq())等效,为了能够方便的进行链式调用而提供。
toSet()
将此集合转换为Set,如果值不可哈希,则抛弃。
toSet(): Set<T>
注意:这和Set(this)等效,为了能够方便的进行链式调用而提供。
toOrderSet()
将此集合转换为Set,保留索引的顺序。
toOrderedSet(): OrderedSet<T>
注意:这和OrderedSet(this.valueSeq())等效,为了能够方便的进行链式调用而提供。
toList()
将此集合转换为List,丢弃键值。
toList(): List<T>
此方法和List(collection)类似,为了能够方便的进行链式调用而提供。然而,当在Map或者其他有键的集合上调用时,collection.toList()会丢弃键值,同时创建一个只有值的list,而List(collection)使用传入的元组创建list。
const { Map, List } = require('immutable')
var myMap = Map({ a: 'Apple', b: 'Banana' })
List(myMap) // List [ [ "a", "Apple" ], [ "b", "Banana" ] ]
myMap.toList() // List [ "Apple", "Banana" ]
toStack()
将此集合转换为Stack,丢弃键值,抛弃不可哈希的值。
toStack(): Stack<T>
注意:这和Stack(this)等效,为了能够方便的进行链式调用而提供。
转换为Seq
toSeq()
返回Seq.Indexed。
toSeq(): Seq.Indexed<T>
toKeyedSeq()
从这个集合返回一个Seq.Keyed,其中索引将视作key。
toKeyedSeq(): Seq.Keyed<number, T>
如果你想对Collection.Indexed操作返回一组[index, value]对,这将十分有用。
返回的Seq将与Colleciont有相同的索引顺序。
const { Seq } = require('immutable')
const indexedSeq = Seq([ 'A', 'B', 'C' ])
// Seq [ "A", "B", "C" ]
indexedSeq.filter(v => v === 'B')
// Seq [ "B" ]
const keyedSeq = indexedSeq.toKeyedSeq()
// Seq { 0: "A", 1: "B", 2: "C" }
keyedSeq.filter(v => v === 'B')
// Seq { 1: "B" }
toIndexedSeq()
将这个集合的值丢弃键(key)返回为Seq.Indexed。
toIndexedSeq(): Seq.Indexed<T>
toSetSeq()
将这个集合的值丢弃键(key)返回为Seq.Set。
toSetSeq(): Seq.Set<T>
迭代器
keys()
一个关于Collection键的迭代器。
keys(): IterableIterator<number>
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用keySeq来满足需求。
values()
一个关于Collection值的迭代器。
values(): IterableIterator<T>
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用valueSeq来满足需求。
entries()
一个关于Collection条目的迭代器,是[ key, value ]这样的元组数据。
entries(): IterableIterator<[number, T]>
注意:此方法将返回ES6规范的迭代器,并不支持Immutable.js的sequence算法,你可以尝试使用entrySeq来满足需求。
集合(Seq)
keySeq()
返回一个新的Seq.Indexed,其包含这个集合的键值。
keySeq(): Seq.Indexed<number>
valueSeq()
返回一个新的Seq.Indexed,其包含这个集合的所有值。
valueSeq(): Seq.Indexed<T>
entrySeq()
返回一个新的Seq.Indexed,其为[key, value]这样的元组。
entrySeq(): Seq.Indexed<[number, T]>
序列算法
map()
返回一个由传入的mapper函数处理过值的新Set。
map<M>(mapper: (value: T, key: number, iter: this) => M, context?: any): Set<M>
例
Set([ 1, 2 ]).map(x => 10 * x)
// Set [ 10, 20 ]
注意:map()总是返回一个新的实例,即使它产出的每一个值都与原始值相同。
filter()
返回一个只有由传入方法predicate返回为true的值组成的新Set。
filter<F>(
predicate: (value: V, key: K, iter: this) => boolean,
context?: any
): Collection<K, F>
filter(predicate: (value: V, key: K, iter: this) => any, context?: any): this
例
const { Map } = require('immutable')
Map({ a: 1, b: 2, c: 3, d: 4}).filter(x => x % 2 === 0)
// Map { "b": 2, "d": 4 }
注意:filter()总是返回一个新的实例,即使它的结果没有过滤掉任何一个值。
filterNot()
返回一个由所提供的predicate方法返回false过滤的新的相同类型的集合。
filterNot(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
例
const { Map } = require('immutable')
Map({ a: 1, b: 2, c: 3, d: 4}).filterNot(x => x % 2 === 0)
// Map { "a": 1, "c": 3 }
注意:filterNot总是返回一个新的实例,即使它没有过滤掉任何一个值。
reverse()
返回为一个逆序的新的同类型集合。
reverse(): this
sort()
返回一个使用传入的comparator重新排序的新同类型集合。
sort(comparator?: (valueA: T, valueB: T) => number): this
如果没有提供comparator方法,那么默认的比较将使用<和>。
comparator(valueA, valueB):
- 返回值为
0这个元素将不会被交换。 - 返回值为
-1(或者任意负数)valueA将会移到valueB之前。 - 返回值为
1(或者任意正数)valueA将会移到valueB之后。 - 为空,这将会返回相同的值和顺序。
当被排序的集合没有定义顺序,那么将会返回同等的有序集合。比如map.sort()将返回OrderedMap。
const { Map } = require('immutable')
Map({ "c": 3, "a": 1, "b": 2 }).sort((a, b) => {
if (a < b) { return -1; }
if (a > b) { return 1; }
if (a === b) { return 0; }
});
// OrderedMap { "a": 1, "b": 2, "c": 3 }
注意:sort()总是返回一个新的实例,即使它没有改变排序。
sort()
返回一个使用传入的comparator重新排序的新同类型集合。
sort(comparator?: (valueA: T, valueB: T) => number): this
如果没有提供comparator方法,那么默认的比较将使用<和>。
comparator(valueA, valueB):
- 返回值为
0这个元素将不会被交换。 - 返回值为
-1(或者任意负数)valueA将会移到valueB之前。 - 返回值为
1(或者任意正数)valueA将会移到valueB之后。 - 为空,这将会返回相同的值和顺序。
当被排序的集合没有定义顺序,那么将会返回同等的有序集合。比如map.sort()将返回OrderedMap。
const { Map } = require('immutable')
Map({ "c": 3, "a": 1, "b": 2 }).sort((a, b) => {
if (a < b) { return -1; }
if (a > b) { return 1; }
if (a === b) { return 0; }
});
// OrderedMap { "a": 1, "b": 2, "c": 3 }
注意:sort()总是返回一个新的实例,即使它没有改变排序。
sortBy()
与sort类似,但能接受一个comparatorValueMapper方法,它允许通过更复杂的方式进行排序:
sortBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): this
例
hitters.sortBy(hitter => hitter.avgHits)
注意:sortBy()总是返回一个新的实例,即使它没有改变排序。
groupBy()
返回一个Collection.Keyeds的Collection.keyed,由传入的grouper方法分组。
groupBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Seq.Keyed<G, Collection<number, T>>
注意:这不总是一个立即地操作。
const { List, Map } = require('immutable')
const listOfMaps = List([
Map({ v: 0 }),
Map({ v: 1 }),
Map({ v: 1 }),
Map({ v: 0 }),
Map({ v: 2 })
])
const groupsOfMaps = listOfMaps.groupBy(x => x.get('v'))
// Map {
// 0: List [ Map{ "v": 0 }, Map { "v": 0 } ],
// 1: List [ Map{ "v": 1 }, Map { "v": 1 } ],
// 2: List [ Map{ "v": 2 } ],
// }
副作用
forEach()
sideEffect将会对集合上每个元素执行。
forEach(
sideEffect: (value: T, key: number, iter: this) => any,
context?: any
): number
与Array#forEach不同,任意一个sideEffect返回false都会停止循环。函数将返回所有参与循环的元素(包括最后一个返回false的那个)。
创建子集
slice()
返回一个新的相同类型的相当于原集合指定范围的元素集合,包含开始索引但不包含结束索引位置的值。
slice(begin?: number, end?: number): this
如果起始值为负,那么表示从集合结束开始查找。例如slice(-2)返回集合最后两个元素。如果没有提供,那么新的集合将会从最开始那个元素开始。
如果终止值为负,表示从集合结束开始查找。例如silice(0, -1)返回除集合最后一个元素外所有元素。如果没提供,新的集合将会包含到原集合最后一个元素。
如果请求的子集与原集合相等,那么将会返回原集合。
rest()
返回一个不包含原集合第一个元素的新的同类型的集合。
rest(): this
继承自
Collection#rest
butLast()
返回一个不包含原集合最后一个元素的新的同类型的集合。
butLast(): this
继承自
Collection#butLast
skip()
返回一个不包含原集合从头开始amount个数元素的新的同类型集合。
skip(amount: number): this
skipLast()
返回一个不包含原集合从结尾开始amount个数元素的新的同类型集合。
skipLast(amount: number): this
skipWhile()
返回一个原集合从predicate返回false那个元素开始的新的同类型集合。
skipWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipWhile(x => x.match(/g/))
// List [ "cat", "hat", "god" ]
skipUntil()
返回一个原集合从predicate返回true那个元素开始的新的同类型集合。
skipUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.skipUntil(x => x.match(/hat/))
// List [ "hat", "god"" ]
take()
返回一个包含原集合从头开始的amount个元素的新的同类型集合。
take(amount: number): this
takeLast()
返回一个包含从原集合结尾开始的amount个元素的新的同类型集合。
takeLast(amount: number): this
takeWhile()
返回一个包含原集合从头开始的prediacte返回true的那些元素的新的同类型集合。
takeWhile(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeWhile(x => x.match(/o/))
// List [ "dog", "frog" ]
takeUntil()
返回一个包含原集合从头开始的prediacte返回false的那些元素的新的同类型集合。
takeUntil(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): this
例
const { List } = require('immutable')
List([ 'dog', 'frog', 'cat', 'hat', 'god' ])
.takeUntil(x => x.match(/at/))
// List [ "dog", "frog" ]
组合
cancat()
将其他的值或者集合与这个Set串联起来返回为一个新Set。
concat<C>(...valuesOrCollections: Array<Iterable<C> | C>): Set<T | C>
flatten()
压平嵌套的集合。
flatten(depth?: number): Collection<any, any>
flatten(shallow?: boolean): Collection<any, any>
默认会深度地经常压平集合操作,返回一个同类型的集合。可以指定depth为压平深度或者是否深度压平(为true表示仅进行一层的浅层压平)。如果深度为0(或者shllow:false)将会深层压平。
压平仅会操作其他集合,数组和对象不会进行此操作。
注意:flatten(true)操作是在集合上进行,同时返回一个集合。
flatMap()
扁平化这个Set为一个新Set。
flatMap<M>(
mapper: (value: T, key: number, iter: this) => Iterable<M>,
context?: any
): Set<M>
与set.map(...).flatten(true)相似。
减少值
reduce()
将传入的方法reducer在集合每个元素上调用并传递缩减值,以此来缩减集合的值。
reduce<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduce<R>(reducer: (reduction: T | R, value: T, key: number, iter: this) => R): R
见
Array#reduce
如果initialReduction未提供,那么将会使用集合第一个元素。
reduceRight()
逆向地缩减集合的值(从结尾开始)。
reduceRight<R>(
reducer: (reduction: R, value: T, key: number, iter: this) => R,
initialReduction: R,
context?: any
): R
reduceRight<R>(
reducer: (reduction: T | R, value: T, key: number, iter: this) => R
): R
注意:与this.reverse().reduce()等效,为了与Array#reduceRight看齐而提供。
every()
当集合中所有元素predicate都判定为true时返回ture。
every(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
some()
当集合中任意元素predicate判定为true时返回ture。
some(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): boolean
join()
将值连接为字符串,并且在每两个值之间插入分割。默认分隔为","。
join(separator?: string): string
isEmpty()
当集合不包含值时返回true。
isEmpty(): boolean
对于惰性Seq,isEmpty会对他经常迭代来确定是否为空。至少会迭代一次。
count()
返回集合的大小。
count(): number
count(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number
不管此集合是否惰性地确定大小(某些Seq不能),这个方法将总是返回正确的大小。如果必要,他将会评估一个惰性的Seq。
如果predicate提供了,方法返回的数量将是集合中predicate返回true的元素个数。
countBy()
返回Seq.Keyed的数量,由grouper方法将值分组。
countBy<G>(
grouper: (value: T, key: number, iter: this) => G,
context?: any
): Map<G, number>
注意:这不是一个惰性操作。
查找
find()
返回集合中第一个符合与所提供的断言的值。
find(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
findLast()
返回集合中最后一个符合与所提供的断言的值。
findLast(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): T | undefined
注意:predicate将会逆序地在每个值上调用。
findEntry()
返回第一个符合所提供断言的值的[key, value]。
findEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
findLastEntry()
返回最后一个符合所提供断言的值的[key, value]。
findLastEntry(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any,
notSetValue?: T
): [number, T] | undefined
注意:predicate将会逆序地在每个值上调用。
findKey()
返回第一个predicate返回为true的键。
findKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
findLastKey()
返回最后一个predicate返回为true的键。
findLastKey(
predicate: (value: T, key: number, iter: this) => boolean,
context?: any
): number | undefined
注意:predicate将会逆序地在每个值上调用。
keyOf()
返回与提供的搜索值关联的键,或者undefined。
keyOf(searchValue: T): number | undefined
lastKeyOf()
返回最后一个与提供的搜索值关联的键或者undefined。
lastKeyOf(searchValue: T): number | undefined
max()
返回集合中最大的值。如果有多个值比较为相等,那么将返回第一个。
max(comparator?: (valueA: T, valueB: T) => number): T | undefined
comparator的使用方法与Collection#sort是一样的,如果未提供那么默认的比较为>。
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么max将会独立于输入的顺序。默认的比较器>只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
maxBy()
和max类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
maxBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
例
hitters.maxBy(hitter => hitter.avgHits)
min()
返回集合中最小的值,如果有多个值比较为相等,将会返回第一个。
min(comparator?: (valueA: T, valueB: T) => number): T | undefined
当两个值比较为相等时,第一个遇见的值将会被返回。另一方面,如果comparator是可交换的,那么min将会独立于输入的顺序。默认的比较器<只有在类型不一致时才可交换。
如果comparator返回0或者值为NaN、undefined或者null,这个值将会被返回。
minBy()
和min类似,但还能接受一个comparatorValueMapper来实现更复杂的比较。
minBy<C>(
comparatorValueMapper: (value: T, key: number, iter: this) => C,
comparator?: (valueA: C, valueB: C) => number
): T | undefined
例
hitters.minBy(hitter => hitter.avgHits)
对比
isSubset()
如果iter包含集合中所有元素则返回true。
isSubset(iter: Iterable<T>): boolean
isSuperset()
如果集合包含iter中所有元素则返回true。
isSuperset(iter: Iterable<T>): boolean















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









