






猜你喜欢
0、淘宝首页猜你喜欢推荐建模实践
1、【免费下载】2022年8月份热门报告
2、【实践】小红书推荐中台实践
3、微信视频号实时推荐技术架构分享
4、对比学习在宽狩推荐系统中的应用实践
5、微博推荐算法实践与机器学习平台演进
6、腾讯PCG推荐系统应用实践7、强化学习算法在京东广告序列推荐场景的应用8、飞猪信息流内容推荐探索9、华为项目管理培训教材10、美团大脑系列之商品知识图谱的构建和应用本期我们来尝试总结一下到2022年产业界推荐技术的最新进展与发展趋势。
1. 内容概述
推荐系统是非常重要的业务和研究领域。推荐系统是电商、短视频、新闻等互联网关键业务场景的核心流量和利润来源。就比如说,亚马逊35%的收入,Netflix 80%的电影观看,Youtube 60%的视频点击都是推荐系统来驱动的。
正式因为推荐技术兼有重大业务和科研价值,每年都有大量的推荐技术相关学术科研文章和工业界的新闻。我们本次主要聚焦阿里、腾讯、字节、微软四个大厂它们文章与新闻披露出的推荐技术的最新进展。
阿里、腾讯、字节代表了电商广告、社交广告、信息流广告等领域推荐技术的工业界进展。选这三个厂商还有一个重要原因是它们正好是国内互联网公司广告收入的前3名。根据公开披露的消息,阿里广告2021年全年收入为3163亿,腾讯广告为886亿。字节没有公开披露的广告收入数据,据媒体报告其收入应该在2000亿以上,位于阿里与腾讯之间。

我们首先介绍阿里、腾讯、字节、微软的11个最新代表性推荐技术创新,包括每个技术的研发背景、模型创新、工程创新和业务效果。介绍完这些具体技术创新之后,我将整体回顾并展望业界推荐技术发展趋势。
我们认为业界推荐技术呈现出:多场景、多模态、大模型、全链路、平台化、知识化、预训练的7大技术发展趋势。
下面我们将逐步展开介绍这些最近的推荐技术的进展。
2. 阿里推荐技术进展
前面谈到过,阿里全年广告收入为3000亿量级,是中国互联网广告收入的第一。因为收入基线很高,其推荐技术的每一个改进,都可以带来很大的绝对业务收益。阿里的推荐技术进展代表了国内甚至国际电商场景推荐技术的业界前沿进展。
我们这次选择了4个跟阿里相关的推荐技术。包括:
+超长兴趣实时检索推荐(SIM CIKM 2020)
+多场景融合推荐(STAR CIKM 2021)
+特征共现关系建模推荐(CAN WSDM 2022)
+通用预训练推荐模型(UniSRec KDD 2022)
前三个是已经工业落地的推荐技术,最后一个是阿里与人大科研合作的推荐技术。我们下面来一一介绍这些最新的技术进展。
a. 超长兴趣实时检索推荐(SIM CIKM 2020)
要介绍的阿里第一个工作是2020年发表于CIKM的超长兴趣实时检索推荐技术Search-based User Interest Modeling,简称SIM。这个技术让人眼前一亮是因为其打破了原有用户行为序列特征的生成机制和长度限制。
一般推荐系统输入侧的用户行为序列特征长度在千以内,也就是最多只能输入用户的最近千次行为。但是在电商类场景中,用户有频繁的点击行为,每个用户有万级别丰富的行为数据。以往推荐系统的千级别用户行为序列并不能覆盖电商场景用户丰富的历史行为。
这里超长兴趣实时检索推荐技术创造性提出了根据候选广告Item信息实时去用户全量行为库检索最相关用户行为进行推荐预估的方案。SIM推荐模型创造了基于实时检索的工程与模型深度耦合的推荐系统新范式。
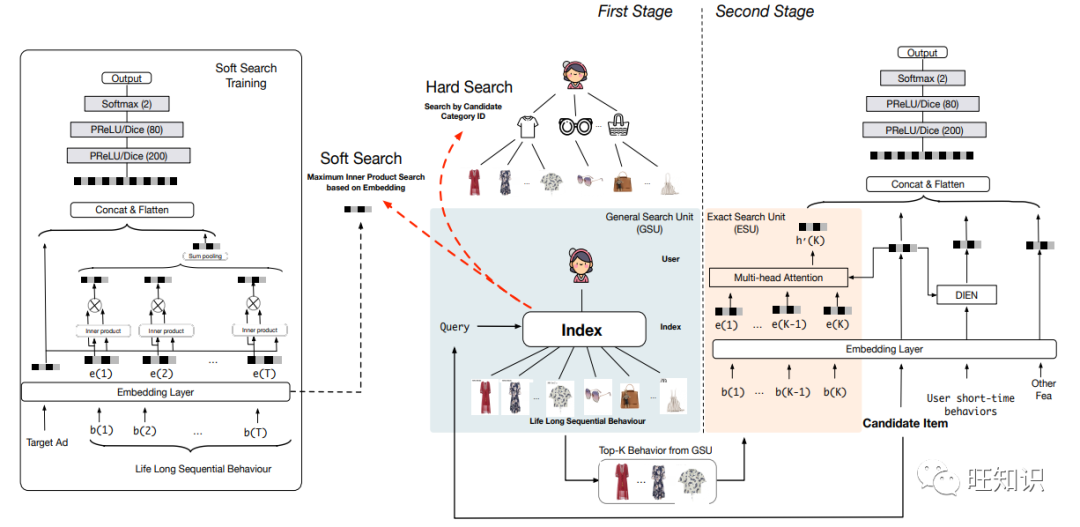
阿里对这个新模型进行了离线和线上测试,实验结果显示:新模型相较已有模型离线AUC提升了2%,在线点击率CTR提升了7.1%。
超长兴趣实时检索推荐技术SIM的创新点总结如下:
+ 模型创新:
++ 基于实时检索的超长用户行为序列建模,打造了推荐与检索深度融合新范式
++ 两阶段由粗到细的串行用户兴趣抽取模块,兼顾用户兴趣建模的扩展性和准确性。
+ 工程创新:
++ 超长用户行为历史实时高效检索系统
b. 多场景融合推荐(STAR CIKM 2021)
要介绍的第二个阿里的工作是2021年发表于CIKM的多场景融合推荐技术。
这个工作的业务背景是阿里广告有越来越多要推荐的业务场景,包括包括淘宝首页猜你喜欢,购后(包括购物车订单页等八大场景),中小场景,外部投放等100多个场景。以往是每个场景单独建模,这样就造成有100多个模型同时在线服务不同的推荐场景。众多模型逐渐造成了不可承受的计算资源和人力维护资源的开销。另外服务的业务场景有很多是小场景,用户行为数据量较少,每个小场景独立建模会造成训练数据量不足,模型难于收敛到较优解的问题。
为了解决以上问题,阿里提出了STAR的星形网络模型来进行多场景融合建模和推荐。每个场景都对应有一个自己的网络模块,同时会有一个处于中心位置的公用网络模块将他们进行联通。这样就可以同时学习场景内的特性行为和场景间的共性行为。另外这个工作还有一个创新是提出了局部归一化方法,方法实现了对不同场景进行自适应的归一化,保留场景差异信息,方便精细建模。
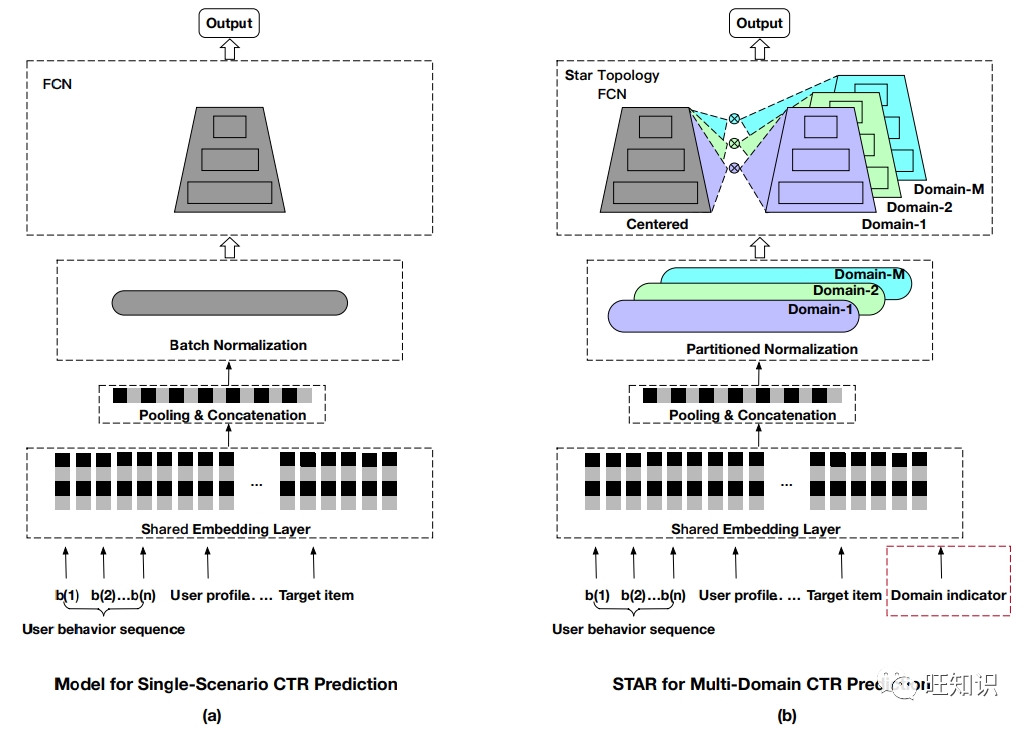
多场景融合推荐技术-STAR 上线后,在不额外增加特征、算力、响应时间的情况下,取得了点击率CTR+8%, 千次展示收入RPM+6% 的业务效果提升。
多场景融合推荐STAR的创新点总结如下:
+ 模型创新:
++ 星形多场景融合推荐模型,从多场景全方面理解用户
++ 场景独立归一化模块,防止场景互相干扰
+工程创新:
++ 多场景实时窗口平滑随机样本采样系统
c. 特征共现关系建模推荐(CAN WSDM 2022)
第三个阿里的工作是2022年发表于WSDM的特征共现关系建模推荐技术,其英文名称为Co-Action Network,简称为CAN。
这个工作的灵感来个起源于阿里同事的一个实验发现,他们发现对序列特征和目标特征进行笛卡尔积组合之后能在推荐模型的离线指标有显著提升。但是这种特征输入端的组合会极大扩充ID编码的词典量,影响系统的扩展性,最终难于工业化上线。那怎么才能充分利用这种特征组合信息同时又保持系统的扩展性和工业化上线部署能力呢?
为了解决以上问题,阿里提出了这里的特征共现关系网络Co-Action Network,简称CAN。CAN可以在输入阶段就能捕获原始特征的共现关系,同时能够有效利用不同"共现特征对"之间通用共享的信息。同时相比于笛卡尔积,CAN能够同时大幅降低模型的参数量。
熟悉推荐算法的朋友可能会发觉这个CAN的作用与经典的DeepFM等特征交叉网络的作用有点类似。他们的不同点在于特征组合的灵活度不同。DeepFM等特征组合嵌入模型要同时负责单一特征的表征学习,又要负责两两特征之间的交互建模,这二者之间实际上是会有矛盾的,会互相干扰和影响。而,CAN这个网络能够将单个特征表征学习的向量空间和特征交互建模的向量空间区分开,尽可能减少冲突。
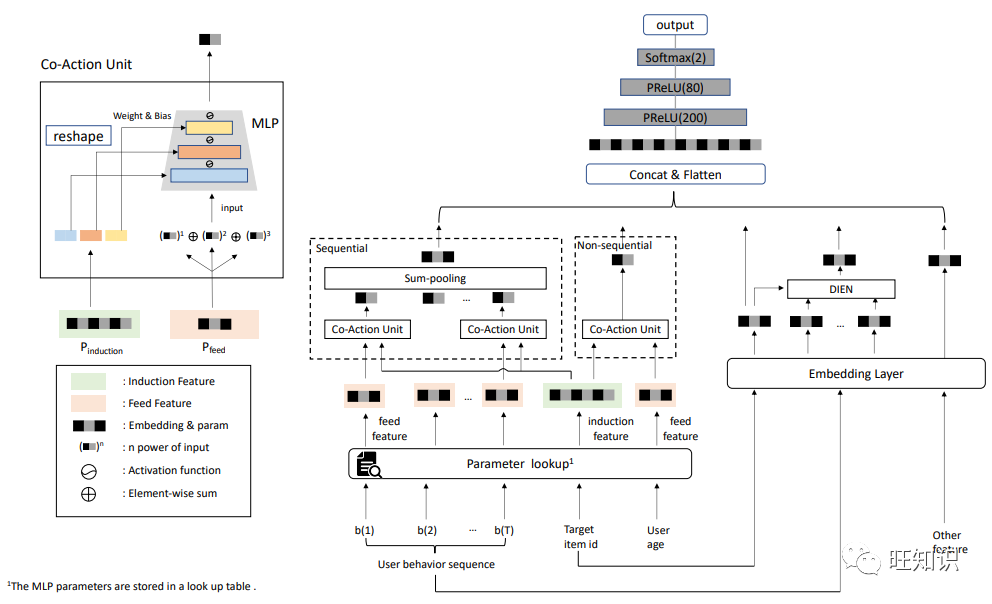
CAN模型成功在阿里展示广告几乎所有场景上线,并取得巨大的提升。比如在首页广告场景CAN上线带来了点击率CTR+11.4% , 千次展示收入RPM+6% 的业务效果提升。
特征共现关系建模推荐CAN的创新点总结如下:
+ 模型创新:
++ 特征共现关系建模网络推荐模型,提供参数量更少的可扩展性方案来逼近输入端笛卡尔积特征组合效果
+工程创新:
++ 大规模矩阵乘法和求和运算计算内核融合优化,提升60+%QPS
d. 通用预训练推荐模型(UniSRec KDD 2022)
第四个要介绍的阿里相关推荐技术是阿里与人民大学合作的预研工作:通用预训练推荐模型,Universal Sequence Representation Learning, 简称为UniSRec。这个工作在2022年发表于KDD会议。
现有业界应用的推荐算法所依赖的绝大部分特征都是不含语义的ID类特征。举例来说,一个旺仔牛奶礼盒的商品,这个商品输入给现有推荐算法的绝大部分特征都是类似下图中113这种不能直接理解的数字。对于这个商品有更多语义信息的文字描述和商品照片,最终也是处理成一些列本身没有含义的数字id进入推荐系统。商品原始文字和图片的语义信息在现有推荐系统中并没有得到足够的重视。

因为ID类特征本身是不含语义的,现有推荐系统就不得不在海量用户行为数据中去学习这些ID本身的含义和ID之间的相关性信息。这就造成现有推荐系统严重依赖海量的用户行为数据,在数据量不充足的场景,推荐系统就存在包括冷启动问题、信息茧房问题等等非常难于解决的技术难题。同时因为ID是在每个场景中随机分配的,基于ID类特征的推荐模型也就无法在场景之间做迁移。
针对上面的问题,人大和阿里合作预研了通用预训练推荐模型UniSRec。为了解决ID类特征不能够跨场景迁移的问题,UniSRec基于Item原始文本语义特征进行学习。具体来说,UniSRec基于预训练语言模型,使用商品文本学习通用商品表征,使用用户交互行为对应的商品表征序列来学习通用用户兴趣序列表征。由于使用原始文本特征作为输入,训练好的UniSRec推荐模型就可以通过在新场景上面做Finetune二次训练来进行迁移。
这个工作的主要的模型技术难点在于如何解决文本表示的语义空间针对多领域推荐任务的适配和优化。直接引入原始文本表征作为额外商品特征往往会带来次优的推荐结果。同时多个领域文本语义空间分布不同,多领域语义融合建模过程往往会发生跷跷板效应,即从不同的领域特定的模式中学习会导致冲突与震荡。该工作提出了包括基于参数白化的语义转换、基于混合专家增强适配器模块的领域融合与适配、多领域序列表示预训练、参数高效微调等创新来应对以上技术难题。
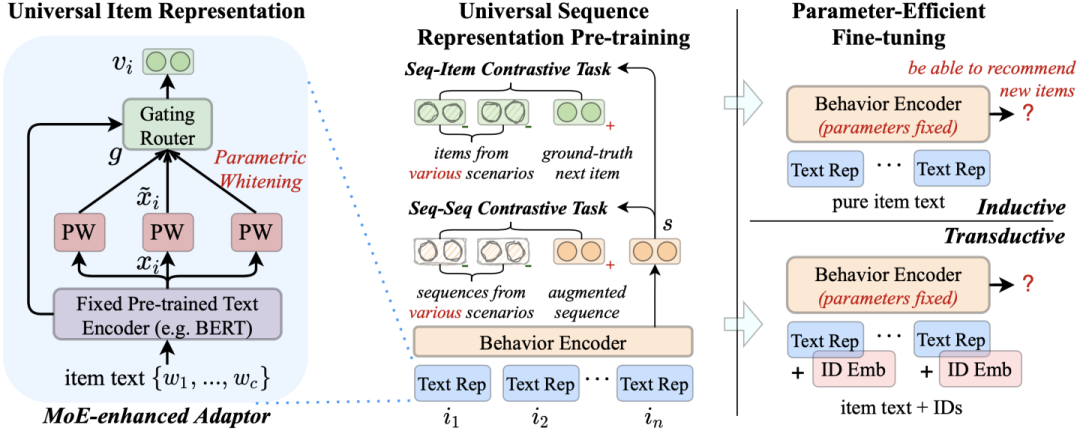
作者在Amazon公开数据集的5个领域数据(包括Food, Home, CDs, Kindle, Movies)做了预训练,然后测试了模型迁移到跨域场景(Pantry, Scientific, Instruments, Arts, Office),和模型迁移到跨平台场景(某英国电商数据集)的性能。学术实验结果显示,预训练后的UniSRec 模型可以高效地在新的域和新的平台上微调并取得优秀的推荐效果。
通用预训练推荐模型UniSRec的创新点总结如下:
+ 模型创新:
++ 基于原始文字特征的通用可迁移预训练推荐模型
++ 文本表示的语义空间针对多领域推荐任务的适配和优化技术
+工程创新:
++ 模型暂时没有工业上线
3. 腾讯推荐技术进展
腾讯全年广告收入为1000亿量级,是中国互联网广告收入的第三。腾讯广告收入主力为以朋友圈为代表的社交场景,腾讯广告的推荐技术进展代表了国内的社交场景推荐技术的业界前沿进展。
我们这次选择了4个跟腾讯相关的推荐技术。包括:
+用户兴趣推荐大模型 (2022)
+多场景推荐大模型 (2022)
+推荐链路一致建模 (2022)
+层级意向嵌入网络推荐(HIEN SIGIR 2022)
前三个是已经工业落地的推荐技术,最后一个是科研合作的推荐技术。我们下面来一一介绍这些最新的技术进展。
a. 用户兴趣推荐大模型 (2022)
我们要介绍的腾讯第一个工作是2022年公开的用户兴趣推荐大模型。
推荐系统有两种基本构建范式,推荐小模型范式和推荐大模型范式。推荐小模型范式中包含复杂离线特征工程和简单在线推荐模型;这里主要通过人工离线特征工程挖掘更加高级的特征来优化推荐效果。推荐大模型范式中包含简单的离线特征工程和复杂的在线推荐模型;这里主要是研发更加精细准确的用户兴趣和内容匹配网络来提升推荐效果。
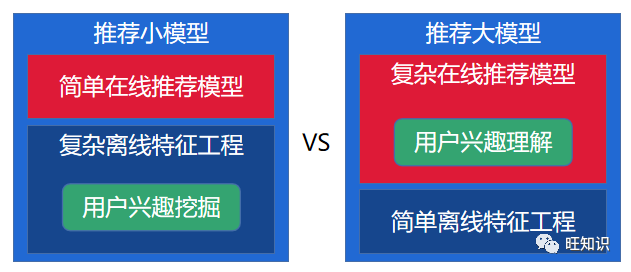
两种推荐系统范式各自都有自己的优缺点。推荐小模型范式更加节省线上计算资源,更利于人工快速干预和优化推荐效果,但是由于采用两段式特征工程和建模,整个推荐系统的效果优化天花板比较低。推荐大模型范式因为有更原始数据输入模型,优点是推荐效果优化的天花板比较高,更利于沉淀可复用通用模型技术,缺点是效果优化门槛更高,更加消耗线上计算资源,对于工程能力要求也更高。
由于线上计算能力、人员模型调优能力等等的限制,以前的推荐系统大部分都采用的是推荐小模型的范式。近年来随着线上算力的扩张和线上模型研发人员经验的提升,国内外大厂都开始了逐渐从推荐小模型范式到推荐大模型范式的迁移。这里将要讲的腾讯用户兴趣推荐大模型的工作就是其中一个往大模型范式迁移的案例。
具体来说,腾讯广告团队直接把用户曝光、点击、转化、文章阅读等行为高维特征直接输入推荐大模型。这里的难点在于,怎么样才能让推荐大模型能够完美学习和利用这些更加原始的用户行为信息。腾讯这里主要是采用AutoAttention网络结构,通过自动注意力机制,在后续推荐中更加重视用户行为中与当前候选广告更加相关的行为信息。
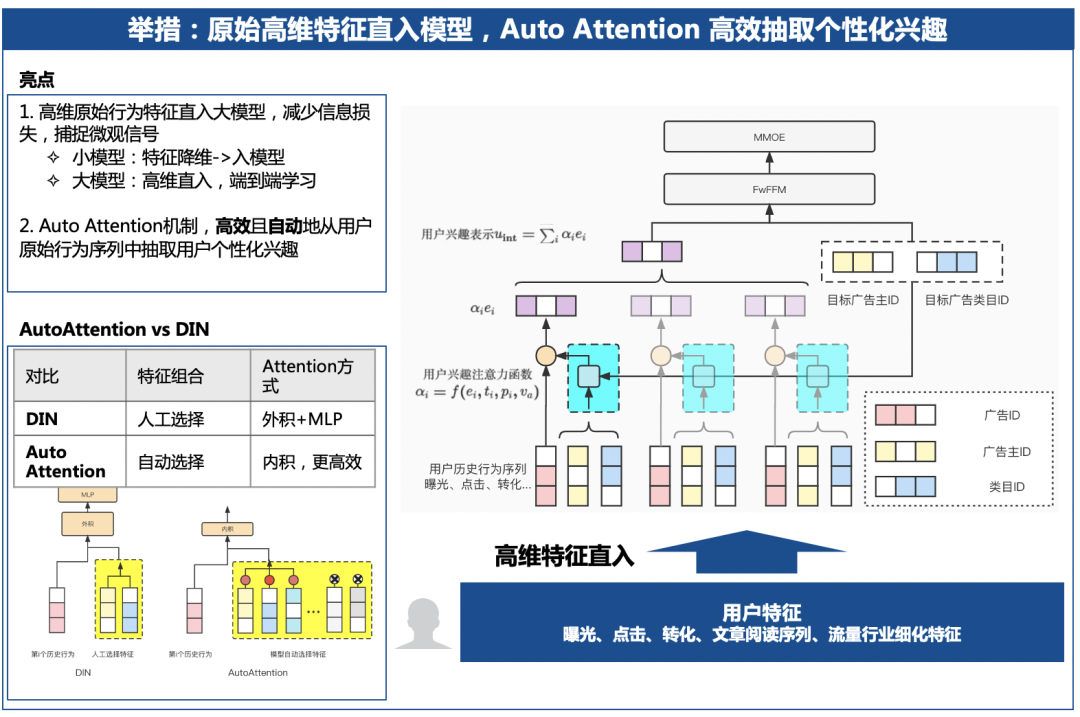
该精排大模型各项算法指标相对于以往百亿规模小模型有显著提升。全流量上线后,相比以前的小模型算法,腾讯广告精排大模型已累计给广告主带来15%的GMV提升。
用户兴趣推荐大模型的创新点总结如下:
+ 模型创新:
++ 直接理解用户原始行为的用户兴趣推荐大模型
++ AutoAttention自动高效用户行为注意力机制
+工程创新:
++ 支持千亿参数、可支持10TB级模型训练、TB级模型推理和分钟级模型发布上线的机器学习平台
++ 支持多维特征融合、复杂模型结构的参数服务器系统
b. 多场景推荐大模型 (2022)
第二个要介绍的腾讯工作是2022年公开的多场景推荐大模型。
腾讯这个工作的背景与前面的阿里的多场景融合推荐(STAR CIKM 2021)是类似的。腾讯广告的推荐场景很多,以前每个场景构建一个模型,会造成模型过多,计算和人工维护成本都非常高。而且,对于一些小的推荐场景,还存在自身用户行为数据不足,独立模型训练难于收敛到较优解的问题。
为了解决以上问题,腾讯提出了多场景融合推荐大模型。这里的技术难点在于如何解决:不同场景差异大,融合之后会存在高度不均衡的样本分布,多样本的场景在训练中会带偏少样本场景的问题。腾讯通过在表示层、隐藏层、输出层的一系列偏置网络、领域独立样本归一、场景独立塔等设计来优化以上问题。
表示层:学习共享Embedding在不同领域下的权重,并通过位置偏置网络和多维度场景交叉特征强化场景差异;
隐藏层:采用Partitioned layer normalization,对不同领域的样本分别进行归一化,增强模型分领域的收敛速度;
输出层:按照场景拆分公共塔和场景独立塔,强化场景个性表达。
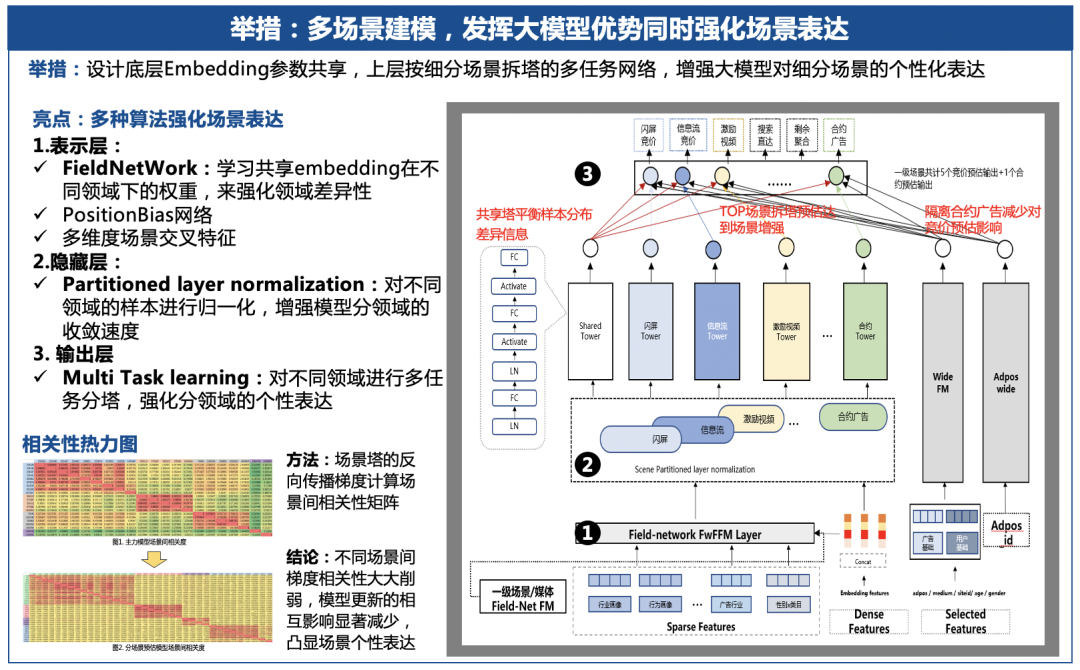
通过上述优化,之前因为领域差异拆开的模型能重新合起来,如公众号页面点击预估现在只需要一个模型,这里不仅会降低了维护成本,同时也取得业务GMV效果的提升。
多场景推荐大模型的创新点总结如下:
+ 模型创新:
++ 多场景融合推荐大模型
++ 偏置网络、领域独立样本归一、场景独立塔等设计缓解多场景样本干扰
+工程创新:
++ 支持千亿参数、可支持10TB级模型训练、TB级模型推理和分钟级模型发布上线的机器学习平台
++ 支持多维特征融合、复杂模型结构的参数服务器系统
c. 推荐链路一致建模 (2022)
第三个要介绍的腾讯工作为2022年公开的推荐链路一致性建模。
记得我们在往期内容中讲过《广告推荐系统技术难点》,其中有一个难点就是链路一致性问题。广告链路包含多个含有推荐算法的环节,包括召回、粗排、精排等等。
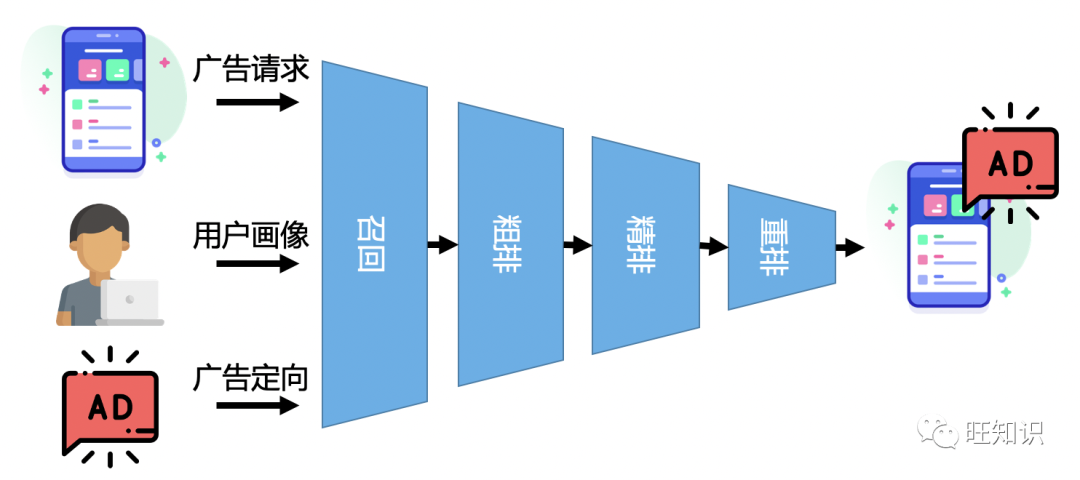
这些环节的推荐算法所用的用户特征、广告特征、优化目标等等在实际实现的时候往往存在一定的差异。这些差异会造成整个广告推荐链路优化方向的不一致问题。广告链路优化方向不一致会降低整个推荐系统优化的业务效果和最终优化空间的天花板。
为了解决这个问题,腾讯广告将召回、粗排模型从原来业界常用的简化CXR模型,也叫LiteCXR模型,全面转向了排序学习LTR模型,它们以精排结果为学习目标。对比LiteCXR模型,LTR模型更加简洁高效,之前数据稀疏、样本选择偏差问题也得到大幅缓解。通过实现这种新的架构,精排模型能够直接牵引粗排、召回等前序模型的优化方向,更利于实现整个推荐链路优化的一致性。
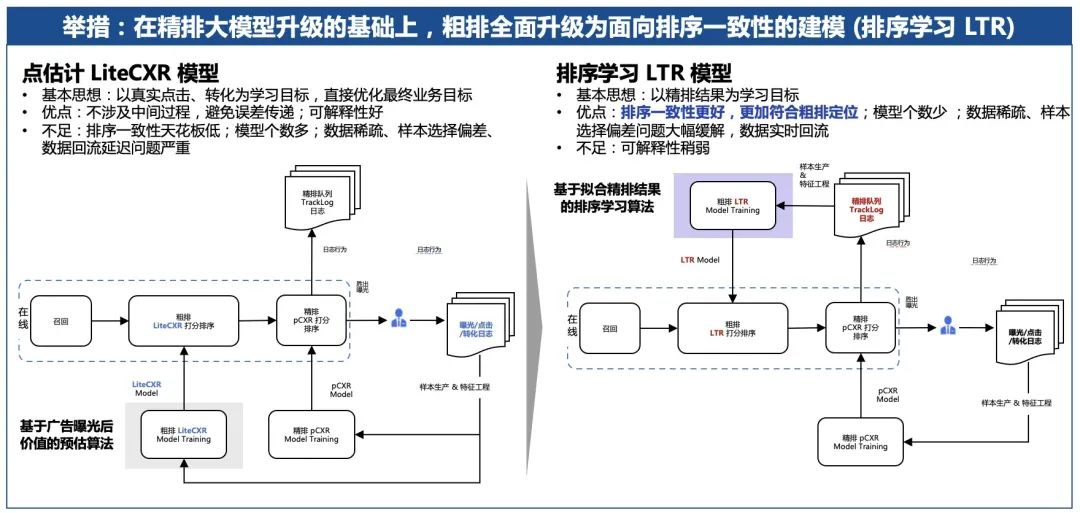
腾讯广告推荐链路一致性建模的改造也已经全量上线,取得了显著业务GMV提升。
推荐链路一致建模的创新点总结如下:
+ 模型创新:
++ 召回、粗排LTR模型,以精排结果为学习目标
+工程创新:
++ 精排排序结果实时前序链路透传技术
d. 层级意向嵌入网络推荐(HIEN SIGIR 2022)
我们第四个要介绍的腾讯工作是2022年发表于SIGIR的层级意向嵌入网络推荐技术,Hierarchical Intention Embedding Network,简称HIEN。
这个工作的研究动机是,当时在腾讯广告推荐真实业务场景中发现已有点击率预估算法对于一些转化数据稀疏广告的预估效果比较差。一些长尾类目和深度目标广告的用户的转化行为非常稀疏。比如一些小众商品,可能几天才有一个转化。又比如游戏的用户付费行为,曝光一万次还不一定有一个付费用户。机器学习模型难于对这种非常稀疏的转化行为进行学习和预测。转化稀疏问题是推荐系统面临的7个技术难点之一,如果你对于其他技术难点感兴趣的话,可以请参考往期内容《广告推荐系统技术难点》。
为了解决以上问题,腾讯和上交大合作预研了层级意向嵌入网络推荐技术HIEN。HIEN的主要思路是利用推荐特征中广泛存在但被忽略的层级关系信息,以及用户和广告双向粗粒度属性交叉意向的提取来优化推荐效果。

HIEN模型提出了5个主要的创新点:广告属性层级信息建模、用户属性层级信息建模、用户到广告属性意向建模、广告到用户属性意向建模、树结构定制优化卷积算子。
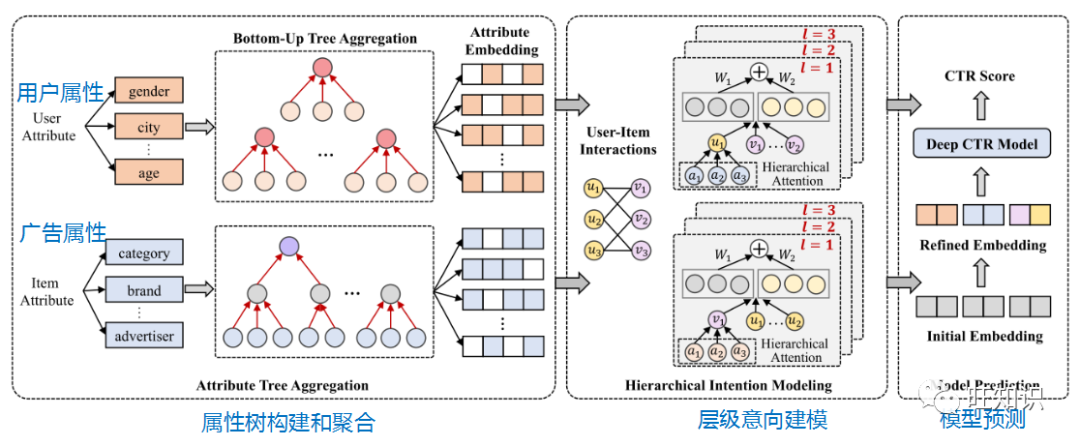
基于以上创新,HIEN算法刷新了阿里和腾讯真实数据上面推荐效果SOTA。同时HIEN模型能够作为前置特征工程模块为已有经典和前沿CTR模型进一步提升性能;HIEN模型也给推荐算法提供了更好更直观的可解释性。
更详细介绍请参考往期内容《SIGIR2022点击率预估模型HIEN-刷新阿里腾讯推荐效果SOTA》。
层级意向嵌入网络推荐HIEN的创新点总结如下:
+ 模型创新:
++ 广告属性层级信息建模、用户属性层级信息建模
++ 用户到广告属性意向建模、广告到用户属性意向建模
+工程创新:
++ 模型暂时没有工业上线
4. 字节推荐技术进展
字节全年广告收入为2000亿量级,是中国互联网广告收入的第二。字节广告收入主力为以抖音、头条为代表信息流场景,字节广告的推荐技术进展代表了国内的信息流场景推荐技术的业界前沿进展。
字节公开能够获取的技术类资料不多,我们这次选择了2个跟字节相关的推荐技术,包括:
+ 大规模推荐系统磐石(2021)
+ 深度开放智能推荐平台(2022)
我们下面来一一介绍这些最新的技术进展。
a. 大规模推荐系统磐石(2021)
第一个要介绍的字节工作为2021年公开的大规模推荐系统磐石。
这个工作的业务背景是,业界的推荐模型一直朝着大规模、实时化、精细化的趋势不断演进。模型训练样本达到可以达到百亿甚至数万亿,单个模型达到 TB 甚至 10TB 以上;特征、模型实时更新;特征工程、模型结构、优化方法等多方面各种创新思路层出不穷。但是,大规模推荐系统的落地,工程挑战很大。市面上已有的开源方案,包括Tensorflow、PyTorch、XDL、Angel等都不能很好支撑实时精细推荐大模型的研发和上线。
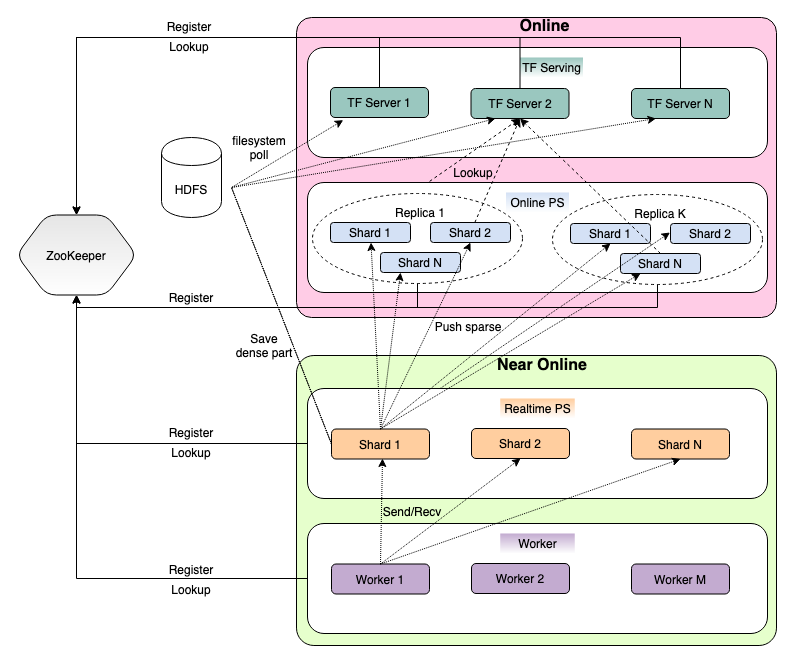
为了解决以上问题,字节研发了直接覆盖数据校验、特征工程、模型开发、线上服务、AB测试等全流程,让业务轻松搭建一套一流的推荐系统的大规模推荐系统磐石。磐石采用PS架构,包括ZooKeeper、近线计算,在线计算几个部分,包含了模型训练/模型服务/参数同步等能力。磐石的核心技术是解决了TensorFlow PS 通信瓶颈、支持全方位容错、支持分布式大模型Serving、进行了诸多网络通讯内存计算等方面的底层性能优化。
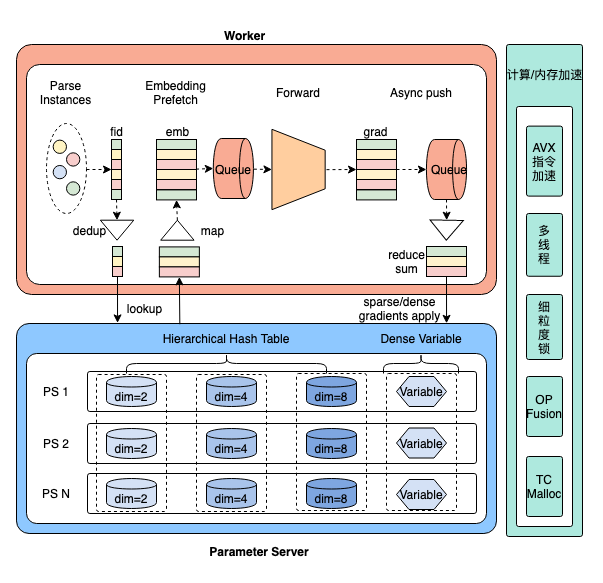
目前,磐石已通过推荐平台成功应用在电商、社区、视频等多个行业的场景上,效果、稳定性、性能均得到了充足的验证。
大规模推荐系统磐石的创新点总结如下:
+工程创新:
++ 大规模实时推荐系统
++ TensorFlow PS 通信瓶颈优化
++ 支持全方位容错
++ 支持分布式大模型Serving
b. 深度开放智能推荐平台(2022)
第二个要介绍的字节工作为2022年公开的深度开放智能推荐平台。
工业界推荐系统涉及的功能模块非常多和复杂。推荐系统离线部分需要对数据进行预处理、特征工程、模型训练;在线部分包括召回、粗排、精排等多个推荐环节;同时还要支持大量的AB实验来验证推荐效果。以前搭建一套推荐系统要配置多个平台和系统才能完成。系统搭建的门槛很高,而且不利于快速迭代更新推荐技术。
为了降低推荐系统搭建的门槛,提高技术迭代效率,字节推出了深度开放的智能推荐平台。这个平台能帮助企业实现从数据接入到推荐结果输出,这一完整的端到端推荐服务的搭建;在特征工程/模型开发模块,平台既能通过简单的配置提供入门级的功能,同时也提供了低代码的开发能力,让工程师可以结合自己的经验深度参与到效果的优化中;与此同时,模型支持实时训练,能够更快将用户的行为和偏好体现在推荐结果中。

目前,这套平台已在电商、内容、视频等多个领域服务了很多客户,并将积累的行业经验,沉淀成行业模板,可以为不同领域的企业提供更专业的推荐服务。
深度开放智能推荐平台的创新点总结如下:
+工程创新:
++ 一站式端到端深度开放推荐平台
++ 实时特征工程与模型训练
5. 微软推荐技术进展
这里要介绍的微软工作是2022年发表于SIGIR的多模态新闻推荐,Multimodal News Recommendation,简称为MM-Rec。
现在推荐内容的越来越丰富,内容从单一文本内容逐步扩展到包含更多图像、声音和视频。用户点击新闻不再单纯因为对于标题感兴趣,还可能是因为被新闻图片所吸引。以往的推荐相关性建模中往往是建模单个模态的相关性,比如文字和文字的相关性,图片和图片的相关性,跨越模态的相关性没有被充分利用。举例来说,下图中候选新闻的图像与用户第二次点击新闻标题文字中的球队名"Cowboys"存在的相关性就是跨模态的相关性。

基于以上观察,微软和清华大学科研合作提出了多模态新闻推荐技术MM-Rec。MM-Rec首先通过对象检测从新闻图像中提取感兴趣区域(ROI),然后,使用预先训练的视觉语言模型对新闻文本和图像ROI进行编码,并对它们的内在关联性进行建模。此外,MM-Rec还提出了一种跨模态的候选新闻感知注意力网络,用于选择相关的历史点击新闻,来更准确建模用户对候选新闻的兴趣。
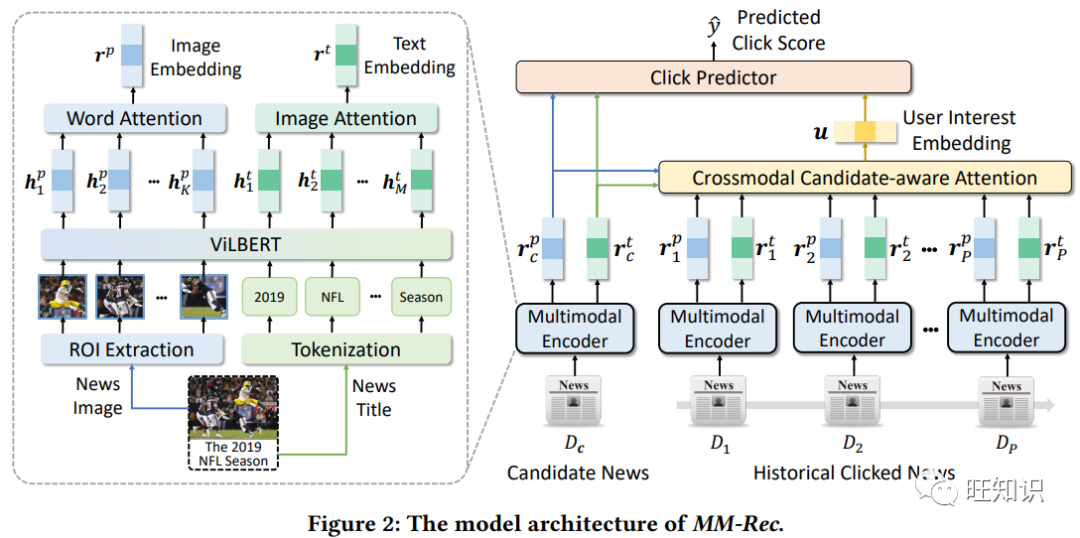
这个工作自己构建了包含多模态信息的数据集合,并通过一些列数据实验显示了MM-Rec相对已有Baseline能够取得更好的多模态推荐效果。
多模态新闻推荐MM-Rec的创新点总结如下:
+模型创新:
++ 图片、文字多模态表征学习网络
++ 跨模态的候选新闻感知注意力网络
6. 进展总结与未来趋势
最后我们总结一下2022年业界推荐技术的进展与未来趋势。这里先回顾一下前面内容。
我们介绍了4个阿里的推荐技术,它们是:
+超长兴趣实时检索推荐(SIM CIKM 2020)
+多场景融合推荐(STAR CIKM 2021)
+特征共现关系建模推荐(CAN WSDM 2022)
+通用预训练推荐模型(UniSRec KDD 2022)
我们介绍了4个腾讯的推荐技术,它们是:
+用户兴趣推荐大模型 (2022)
+多场景推荐大模型 (2022)
+推荐链路一致建模 (2022)
+层级意向嵌入网络推荐(HIEN SIGIR 2022)
我们介绍了2个字节的推荐技术,它们是:
+ 大规模推荐系统磐石(2021)
+ 深度开放智能推荐平台(2022)
我们介绍1个微软的推荐技术,它是:多模态新闻推荐技术(MM-Rec SIGIR 2022)。
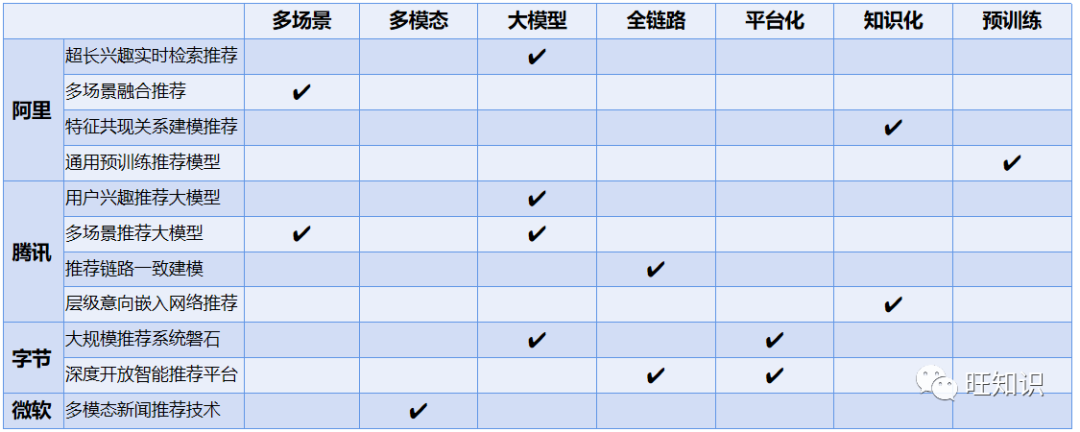
从以上工作我们能够看到2022年的业界推荐技术呈现出:多场景、多模态、大模型、全链路、平台化、知识化、预训练的7大技术发展趋势。具体来说:
多场景是从单个场景独立建模过渡到多个场景联合建模。阿里的多场景融合推荐(STAR CIKM 2021)和腾讯的多场景推荐大模型 (2022)都是代表多场景趋势的推荐技术。
多模态是从单个模态独立建模过渡到多个模态混合建模。微软的多模态新闻推荐(MM-Rec SIGIR 2022)是多模态趋势的代表推荐技术。
大模型是从【复杂离线特征工程】+【简单在线推荐模型】的小模型系统范式过渡到【简单离线特征工程】+【复杂在线推荐模型】的大模型推荐范式。阿里的超长兴趣实时检索推荐(SIM CIKM 2020)、多场景融合推荐(STAR CIKM 2021),腾讯的用户兴趣推荐大模型 (2022)、多场景推荐大模型 (2022)等都是代表大模型趋势的推荐技术。
全链路是从召回、粗排、精排各个推荐环节独立优化过渡到全链路所有推荐环节整体优化。腾讯的推荐链路一致建模 (2022)是全链路趋势的代表推荐技术。
平台化是从原来繁多独立的推荐工程组件过渡到端到端高效整体一站式推荐平台。字节的大规模推荐系统磐石(2021)、深度开放智能推荐平台(2022)是平台化趋势的代表推荐技术。
知识化是从单纯依赖用户行为建模过渡到同时引入特征、场景、样本本身的属性和关系的背景知识。阿里的特征共现关系建模推荐(CAN WSDM 2022),腾讯的层级意向嵌入网络推荐(HIEN SIGIR 2022)是知识化趋势的代表性推荐技术。
预训练是从单独依赖ID类非语义特征过渡到更多基于原始文本、图片等语义特征,构建通用可迁移推荐模型。阿里的通用预训练推荐模型(UniSRec KDD 2022)是预训练趋势的代表性推荐技术。
我们相信多场景、多模态、大模型、全链路、平台化、知识化、预训练这7大推荐技术发展趋势将能够带来更加深入理解用户和内容的推荐系统。
同时我们这里也要说明一下,上面总结的这些大都是业界中大推荐场景的技术发展趋势,而且大部分技术趋势本身也有其发展的先决条件。多场景需要有多个相关场景数据,多模态需要有多种模态的数据,大模型需要有大量的用户行为数据,全链路需要掌握全推荐环节,平台化需要有强大的模型、工程、系统协作的研发团队,预训练推荐技术太新需要有同时精通语言模型和推荐算法的模型团队。唯有“知识化”是一个普适的全推荐场景都可采用的技术演进趋势。引入更多特征、场景、样本本身的属性和关系的背景知识将是推荐技术发展的普适性第二性能增长曲线。
对于一个具体的推荐场景,应该采用什么样的推荐技术,最重要的还是要根据这个场景的数据和目标特点来决定。比如一个场景如果用户行为很少,那可能比较适应【复杂离线特征工程】+【简单在线推荐模型】的小模型系统范式,而不是【简单离线特征工程】+【复杂在线推荐模型】的大模型推荐范式。总的判断思路是,小数据适合简单模型+知识,大数据适合复杂模型+知识,数据越多越丰富能够训练的模型越大越复杂。
「 更多干货,更多收获 」

推荐系统工程师技能树
【免费下载】2022年8月份热门报告盘点
美团大脑系列之:商品知识图谱的构建及应用
【干货】2021社群运营策划方案.pptx大数据驱动的因果建模在滴滴的应用实践
联邦学习在腾讯微视广告投放中的实践如何搭建一个好的指标体系?如何打造标准化的数据治理评估体系?【干货】小米用户画像实践.pdf(附下载链接)
推荐系统解构.pdf(附下载链接)
短视频爆粉表现指南手册.pdf(附下载链接)
推荐系统架构与算法流程详解如何搭建一套个性化推荐系统?某视频APP推荐策略详细拆解(万字长文)关注我们
智能推荐 个性化推荐技术与产品社区 | 长按并识别关注
|

一个「在看」,一段时光👇


















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









