






 Swing算法是一种在阿里被广泛验证有效的召回算法,它通过user-item-user结构提升稳定性,优于传统的itemCF。在航旅场景中,用户行为稀疏和发散,导致基于User-Rate矩阵的召回效果不佳。为解决这个问题,引入session划分,以用户意图为中心聚合商品,提高召回的相关性。实验表明,session-based Swing召回效果优于传统方法。
Swing算法是一种在阿里被广泛验证有效的召回算法,它通过user-item-user结构提升稳定性,优于传统的itemCF。在航旅场景中,用户行为稀疏和发散,导致基于User-Rate矩阵的召回效果不佳。为解决这个问题,引入session划分,以用户意图为中心聚合商品,提高召回的相关性。实验表明,session-based Swing召回效果优于传统方法。
1.Swing算法介绍
Swing算法原理比较简单,是阿里早期使用到的一种召回算法,在阿里多个业务被验证过非常有效的一种召回方式,它认为 user-item-user 的结构比 itemCF 的单边结构更稳定,截止目前并没有公开的论文进行介绍和说明(可能是因为比较简单,阿里看不上哈哈),但是根据网上的各种资料,对该算法的原理进行介绍,如有错误,欢迎指正。
Swing指的是秋千,例如用户 和用户 ,都购买过同一件商品 ,则三者之间会构成一个类似秋千的关系图。若用户 和用户 之间除了购买过 外,还购买过商品 ,则认为两件商品是具有某种程度上的相似的。
也就是说,商品与商品之间的相似关系,是通过用户关系来传递的。为了衡量物品 和 的相似性,考察都购买了物品 和 的用户 和用户 , 如果这两个用户共同购买的物品越少,则物品 和 的相似性越高。
Swing算法的表达式如下:
2.Swing Python实现
# -*- coding: utf-8 -*-
"""
Author : Thinkgamer
File : Swing.py
Software: PyCharm
Desc : 基于movie lens数据集实现Swing算法
"""
import pandas as pd
from itertools import combinations
import json
import os
alpha = 0.5
top_k = 20
def load_data(train_path, test_path):
train_data = pd.read_csv(train_path, sep="\t", engine="python", names=["userid", "movieid", "rate", "event_timestamp"])
test_data = pd.read_csv(test_path, sep="\t", engine="python", names=["userid", "movieid", "rate", "event_timestamp"])
print(train_data.head(5))
print(test_data.head(5))
return train_data, test_data
def get_uitems_iusers(train):
u_items = dict()
i_users = dict()
for index, row in train.iterrows():
u_items.setdefault(row["userid"], set())
i_users.setdefault(row["movieid"], set())
u_items[row["userid"]].add(row["movieid"])
i_users[row["movieid"]].add(row["userid"])
print("使用的用户个数为:{}".format(len(u_items)))
print("使用的item个数为:{}".format(len(i_users)))
return u_items, i_users
def cal_similarity(u_items, i_users):
item_pairs = list(combinations(i_users.keys(), 2))
print("item pairs length:{}".format(len(item_pairs))) # 1410360
item_sim_dict = dict()
cnt = 0
for (i, j) in item_pairs:
cnt += 1
print(cnt)
user_pairs = list(combinations(i_users[i] & i_users[j], 2))
result = 0.0
for (u, v) in user_pairs:
result += 1 / (alpha + list(u_items[u] & u_items[v]).__len__())
item_sim_dict.setdefault(i, dict())
item_sim_dict[i][j] = result
# print(item_sim_dict[i][j])
return item_sim_dict
def save_item_sims(item_sim_dict, path):
new_item_sim_dict = dict()
for item, sim_items in item_sim_dict.items():
new_item_sim_dict.setdefault(item, dict())
new_item_sim_dict[item] = dict(sorted(sim_items.items(), key = lambda k:k[1], reverse=True)[:top_k])
json.dump(new_item_sim_dict, open(path, "w"))
print("item 相似 item({})保存成功!".format(top_k))
return new_item_sim_dict
def evaluate(item_sim_dict, test):
# 可以参考《推荐系统开发实战》中的cf验证方式
pass
if __name__ == "__main__":
train_data_path = "../../data/ml-100k/ua.base"
test_data_path = "../../data/ml-100k/ua.test"
item_sim_save_path = "../../model/swing/item_sim_dict.json"
train, test = load_data(train_data_path, test_data_path)
if not os.path.exists(item_sim_save_path):
u_items, i_users = get_uitems_iusers(train)
item_sim_dict = cal_similarity(u_items, i_users)
new_item_sim_dict = save_item_sims(item_sim_dict, item_sim_save_path)
else:
new_item_sim_dict = json.load(open(item_sim_save_path, "r"))
evaluate(new_item_sim_dict, test)
3.Swing Spark实现
创建Swing类,其中的评估函数和predict函数这里并未提供,感兴趣的可以自己实现
/**
* @ClassName: Swing
* @Description: 实现Swing算法
* @author: Thinkgamer
**/
class SwingModel(spark: SparkSession) extends Serializable{
var alpha: Option[Double] = Option(0.0)
var items: Option[ArrayBuffer[String]] = Option(new ArrayBuffer[String]())
var userInterpMap: Option[Map[String, Map[String, Int]]] = Option(Map[String, Map[String, Int]]())
/*
* @Description 给参数 alpha赋值
* @Param double
* @return cf.SwingModel
**/
def setAlpha(alpha: Double): SwingModel = {
this.alpha = Option(alpha)
this
}
/*
* @Description 给所有的item进行赋值
* @Param [array]
* @return cf.SwingModel
**/
def setAllItems(array: Array[String]): SwingModel = {
this.items = Option(array.toBuffer.asInstanceOf[ArrayBuffer[String]])
this
}
/*
* @Description 获取两两用户有行为的item交集个数
* @Param [spark, data]
* @return scala.collection.immutable.Map<java.lang.String,scala.collection.immutable.Map<java.lang.String,java.lang.Object>>
**/
def calUserRateItemInterp(data: RDD[(String, String, Double)]): Map[String, Map[String, Int]] = {
val rdd = data.map(l => (l._1, l._2)).groupByKey().map(l => (l._1, l._2.toSet))
val map = (rdd cartesian rdd).map(l => (l._1._1, (l._2._1, (l._1._2 & l._2._2).toArray.length)))
.groupByKey()
.map(l => (l._1, l._2.toMap))
.collectAsMap().toMap
map.take(10).foreach(println)
map
}
def fit(data: RDD[(String, String, Double)]): RDD[(String, String, Double)]= {
this.userInterpMap = Option(this.calUserRateItemInterp(data))
println(this.userInterpMap.take(10))
val rdd = data.map(l => (l._2, l._1)).groupByKey().map(l => (l._1, l._2.toSet))
val result: RDD[(String, String, Double)] = (rdd cartesian rdd).map(l => {
val item1 = l._1._1
val item2 = l._2._1
val interpUsers = l._1._2 & l._2._2
var score = 0.0
for(u1 <- interpUsers){
for(u2 <- interpUsers){
score += 1.0 / (this.userInterpMap.get.get(u1).get(u2).toDouble + this.alpha.get)
}
}
(item1, item2, score) // (item1, item2, swingsocre)
})
result
}
def evalute(test: RDD[(String, String, Double)]) = { }
def predict(userid: String) = { }
def predict(userids: Array[String]) = { }
}
main函数调用
object Swing {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[10]").appName("Swing").enableHiveSupport().getOrCreate()
Logger.getRootLogger.setLevel(Level.WARN)
val trainDataPath = "data/ml-100k/ua.base"
val testDataPath = "data/ml-100k/ua.test"
import spark.sqlContext.implicits._
val train: RDD[(String, String, Double)] = spark.sparkContext.textFile(trainDataPath).map(_.split("\t")).map(l => (l(0), l(1), l(2).toDouble))
val test: RDD[(String, String, Double)] = spark.sparkContext.textFile(testDataPath).map(_.split("\t")).map(l => (l(0), l(1), l(2).toDouble))
val items: Array[String] = train.map(_._2).collect()
val swing = new SwingModel(spark).setAlpha(1).setAllItems(items)
val itemSims: RDD[(String, String, Double)] = swing.fit(train)
swing.evalute(test)
swing.predict("")
swing.predict(Array("", ""))
spark.close()
}
}
4.Swing在阿里飞猪的应用
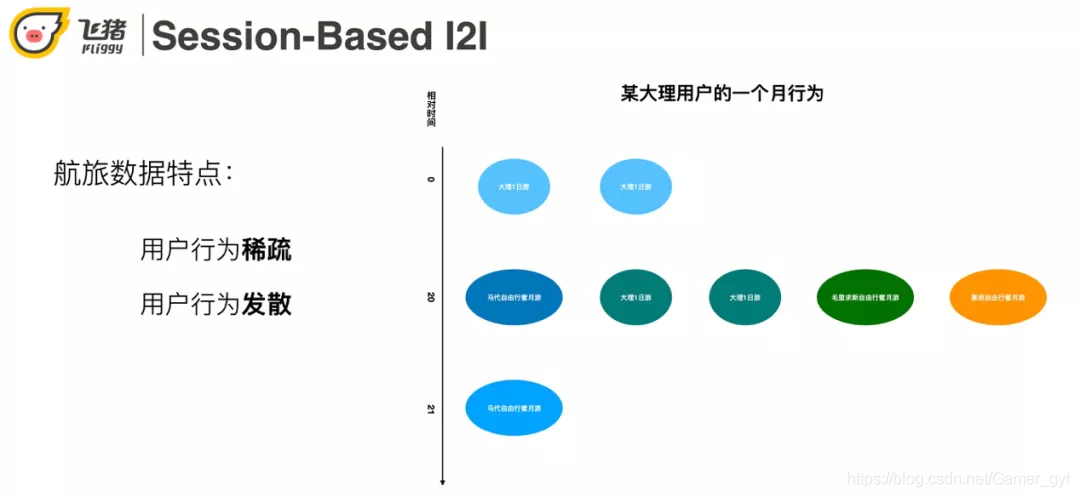
航旅用户的行为有稀疏和发散的特点。利用右图一个具体的用户实例来说明这两个特点:用户在第一天点击了两个大理一日游,第 20 天点击了一些马尔代夫蜜月相关的商品,第 21 天又点击了大理的一日游。稀疏性体现在一个月只来了 3 次,点击了 8 个宝贝。发散性体现在用户大理一日游和出国蜜月游两个 topic 感兴趣。
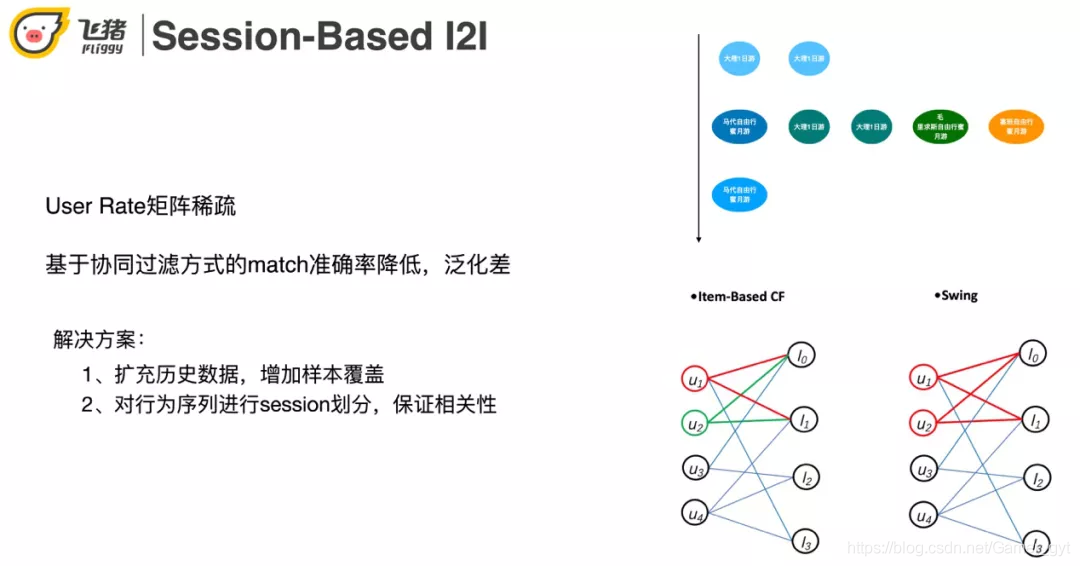
在用户有行为的情况下进行召回,我们常采用的方法是基于 User-Rate 矩阵的协同过滤方法 ( 如 ItemCF,Swing。ItemCF 认为同时点击两个商品的用户越多则这两个商品越相似。Swing 是在阿里多个业务被验证过非常有效的一种召回方式,它认为 user-item-user 的结构比 itemCF 的单边结构更稳定 ),但是由于航旅用户行为稀疏,基于 User-Rate 矩阵召回结果的准确率比较低,泛化性差。针对这两个问题我们可以通过扩充历史数据来增加样本覆盖。航旅场景因为用户点击数据比较稀疏,需要比电商 ( 淘宝 ) 扩充更多 ( 时间更长 ) 的数据才够。这又带来了兴趣点转移多的问题。在这里我们采用对行为序列进行 session 划分,保证相关性。
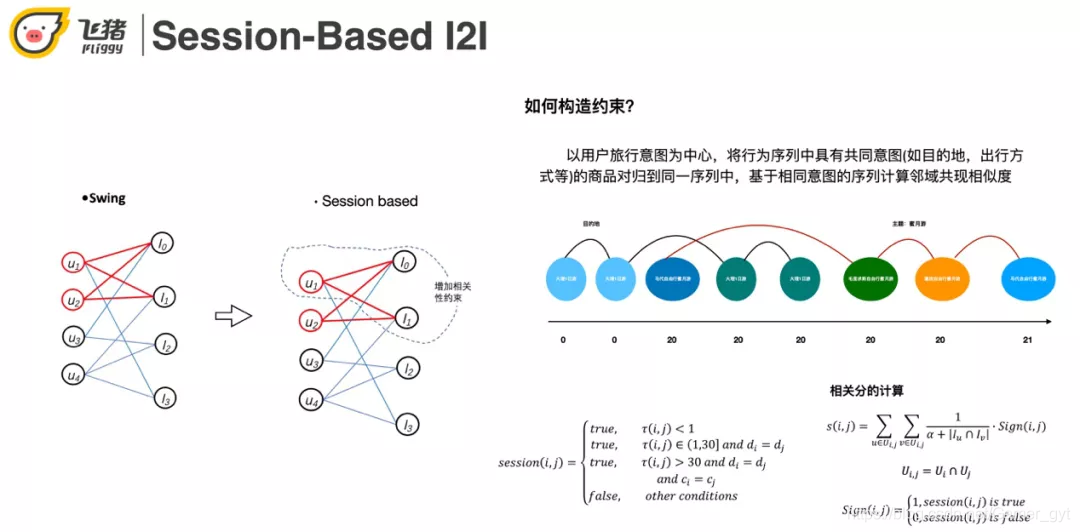
这里以 swing 为例讲解一下构造约束的方式。我们以用户的行为意图为中心,将表示共同意图的商品聚合在一个序列中,如上图对用户行为序列的切分。

在这个 case 中,上面是传统 swing 的召回结果,下面是基于 session 的召回结果。当 trigger 是沙溪古镇一日游的时候,上面有一个杭州莫干山和玉龙雪山一日游,这两个不相关结果的出现是因为它们是热门商品,也称哈利波特效应。下面的召回结果就都是和沙溪古镇相关的了。从指标来看,session-based 召回比 swing 和 itemCF 都高。
参考:
https://zhuanlan.zhihu.com/p/67126386
https://www.infoq.cn/article/qfl1nxcxhuxv723imb7v
更多干货请点击:
2021年3月热门报告盘点(附下载链接)某视频APP推荐策略详细拆解(万字长文)哔哩哔哩推荐策略分析与参考华为到底在研发怎样的核心技术?
全网最全数字化资料包(附下载链接)
关注我们
省时查报告 专业、及时、全面的行研报告库 | 长按并识别关注
|



















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









