






省时查报告-专业、及时、全面的行研报告库
省时查方案-专业、及时、全面的营销策划方案库
【免费下载】2024年1月份热门报告合集
推荐技术在vivo互联网商业化业务中的实践.pdf
推荐系统基本问题及系统优化路径.pdf
大规模推荐类深度学习系统的设计实践.pdf
荣耀推荐算法架构演进实践.pdf
推荐系统在腾讯游戏中的应用实践.pdf
微信视频号实时推荐技术架构分享
推荐系统的变与不变
TLDR: 为了缓解多种模态信息融合过程中的冗余参数以及噪声等问题,本文提出一种面向推荐系统场景的基于提示微调的多模态知识蒸馏方法PromptMM。

论文:arxiv.org/html/2402.17188v1
代码:github.com/HKUDS/PromptMM
ChatGPT4国内可以直接访问的链接,无需注册,无需翻墙,支持编程等多个垂直模型,点开即用:https://ai.zntjxt.com(复制链接电脑浏览器或微信中点开即可,也可扫描下方二维码直达)
研究动机
多模态推荐系统极大的便利了人们的生活,比如亚马逊和Netflix都是基于多模态内容进行推荐的。对于学术研究,人们也遵循工业界的趋势,进行modality-aware的用户偏好的建模。然而,目前的工作主要是将多模态feature引入推荐系统中,这样的做法导致了两个问题:
多模态编码器的引入引进了非常多的额外的参数导致了过拟合,因为所输入给模型的是高维度多模态feature。
I1: Overfitting & Sparsity. 当前的多媒体推荐系统通过采用先进的编码器来处理来自预训练提取器(CLIP-ViT、BERT)的高维特征而表现出色。辅助模态缓解了数据稀疏性,但不可避免地导致了增加的资源消耗。例如,关于电子产品(第4.1.1节)数据集的特征提取器,SBERT和CNNs的输出维度分别为768和4,096。它们比当前方法的嵌入维度要大得多,即 𝑑𝑚 ≫ 𝑑。重新训练预训练模型可以改变输出维度,但由于不同的潜在表示和超参数,这将显著影响性能。此外,训练预训练模型需要大量的计算资源,可能需要在多个GPU上花费数天到数周的时间。因此,当前的多模式工作携带额外的高维特征减少层。这些额外的参数加剧了由于数据稀疏性而已经存在的过拟合,进一步增加了收敛的难度。
side information的引入不可避免地带来了噪声和冗余,这样会导致模态启发的依赖,无法正确反映用户偏好。
I2: Noise & Semantic Gap. 作为附加信息,当使用协同关系来建模用户偏好时,多媒体内容存在固有的不准确性和冗余性。例如,用户可能被文本标题吸引,但图像内容无关;微视频中的音乐可能是为了潮流,而不是用户偏好。盲目依赖噪声模态数据可能会误导用户与项目之间的关系建模。此外,多模态上下文和用户与项目的协同关系最初来自两个不同的分布,存在着较大的语义差距,这给挖掘模态感知用户偏好带来了挑战,甚至破坏了现有的稀疏监督信号。
为了解决这些问题, PromptMM提出通过知识蒸馏的方式简化并强化推荐系统。而知识蒸馏是被Prompt Tuning所增强的,以为了防止过拟合并得到adaptive的知识。具体地,知识蒸馏进行了模型压缩,通过UI边的关系和多模态节点的关系, 使得老师模型中的这些知识传递到学生当中, 使学生避免了使用额外的多模态feature编码的参数。为了将多模态内容和协同过滤的语义gap缩小以防止过拟和,soft prompt-tuning被引入,使得学生模型得到task adaptive的知识。此外,为了调整不正确性的多模态知识,一个多模态listwise的蒸馏被提出,它是通过re-weight机制来调节噪声。在真实数据上,全面的实验展示了模型的有效性,消融实验也证明了关键组件的作用,额外的实验测试了模型的有效性和效率。
网络架构
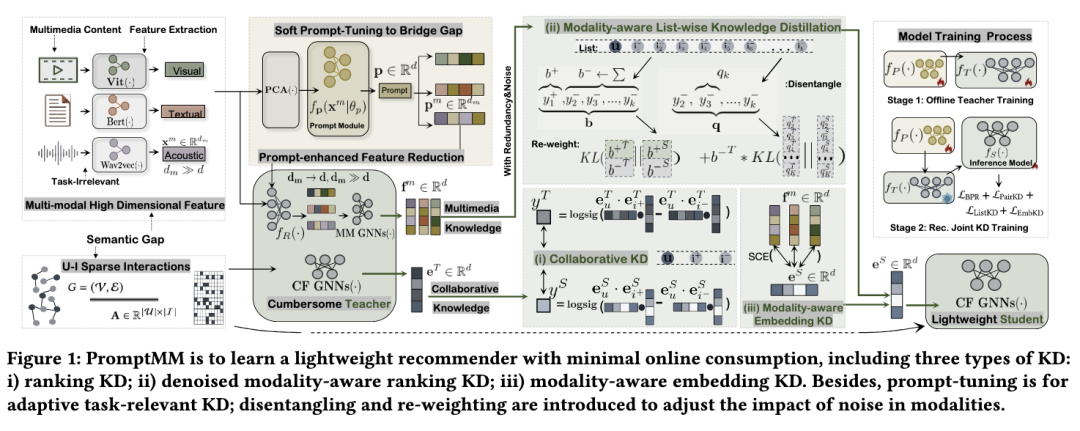
一. 模态启发任务适应性建模
1. 老师模型和学生模型
老师模型:编码高阶多模态信息的冗余模型。
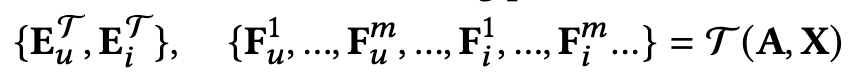
学生模型:专注于协同过滤的轻量级模型。
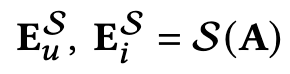
2. Soft Prompt-Tuning作为语义链接
模态内容不可避免地包含任务无关的冗余,他们不仅会影响CF任务,还会加重过拟合。此外,多模态建模和u-i交互建模之间巨大的语义gap还会影响真实用户偏好的学习。soft prompt-tuning被引入来解决这个问题。具体地,为了从模态中抽取协同信号, prompt p被整合到多模态老师的feature编码层R(.)中。prompt p于多模态老师中被构建,在学生模型中被fine-tune来提升被冻住的老师模型。prompt p能够为老师模型引入学生任务相关的信号。
具体的过程可以被分为三步,i) 构建prompt;ii) 把soft-prompt整合进老师模型;iii) 进行prompt-tuning。
构建prompt:
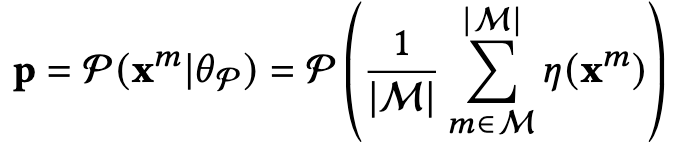
得到prompt-guided的老师,即将得到的prompt整合进老师的特征编码层中:
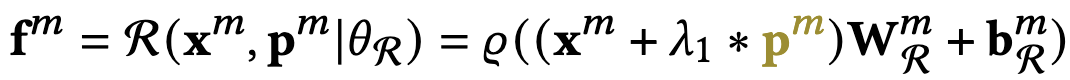
进行soft-prompt tuning: 将冗余的多模态老师作为pre-trained model,soft prompt-tuning能对老师模型进行微调。整个训练过程分为两个阶段:1)在老师训练阶段prompt模块梯度下降更新参数,指导老师模型的inference过程。2)在学生训练阶段,模型使用线下知识蒸馏,冻住老师模型,用学生模型loss的下降再次调整prompt模块适应student。
二. 模态启发的ranking知识蒸馏
为了全面地获得高质量的协同信号和模态启发的用户偏好从老师模型,PromptMM设计了三种知识蒸馏的范式:1) 高质量的ranking蒸馏 2) 去噪的模态启发的ranking蒸馏 3) 模态启发的embedding蒸馏。
高质量的ranking蒸馏:通用的知识蒸馏往往发生在多分类任务上,分类的logit作为被蒸馏的知识,为了适用推荐任务,模型将BPR的logit作为需要被蒸馏的知识。除了正常的BPR loss, 这里的高质量的ranking蒸馏从老师模型获得暗知识作为辅助,使得原来的模型跳出局部最优,得到更好的结果。
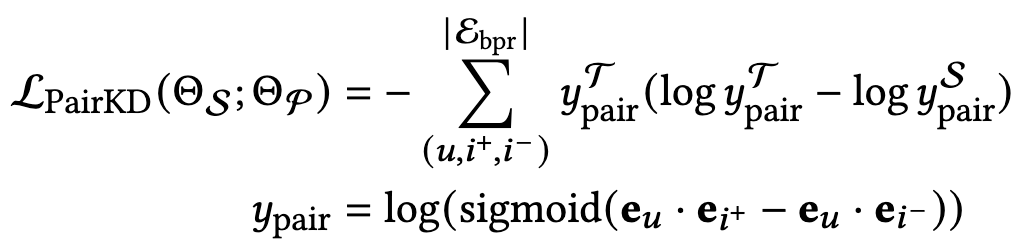
之前编码的多模态内容 f_m^u, f_m^i 在教师模型 T(·) 中含有噪音,可能会影响模态感知用户偏好建模。为了在减少任务无关部分影响的同时进行精确和细粒度的蒸馏,模型设计了一个去噪的模态感知知识蒸馏。具体而言,模型使用 f_m^u, f_m^i 计算列表式分数来进行模态感知排名知识蒸馏。此外,为了进一步减少噪音的影响,模型将知识蒸馏损失重构为解耦部分的加权和。
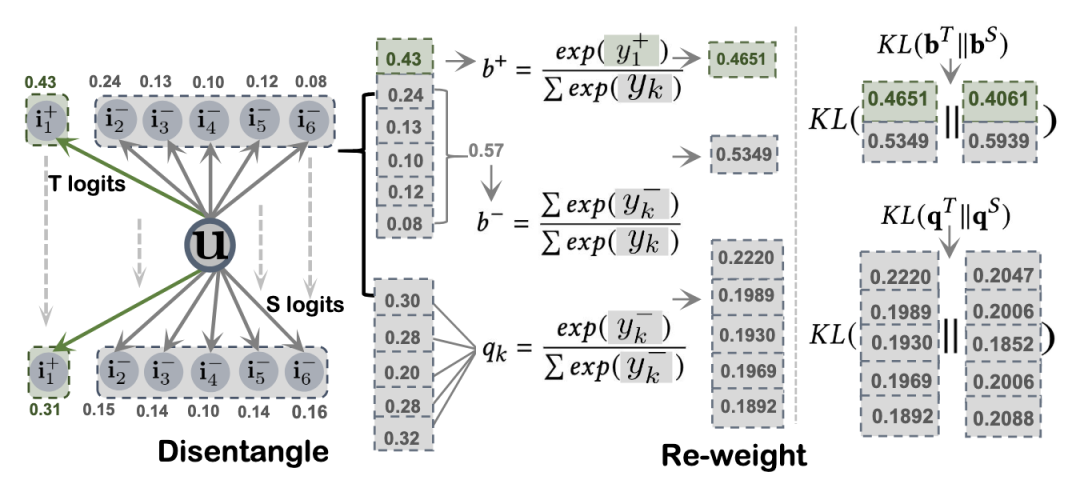

list-wise ranking KD损失被重构为两个项的加权和,可调节地传递可靠知识并增强与模态相关的用户偏好的准确性。强调置信度较高的是user preference的部分
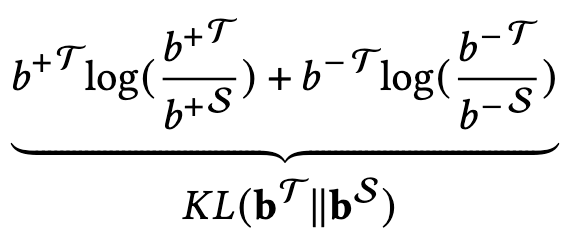
较低的分数被分配给那些不确定的用户-物品关系,以降低它们在知识蒸馏过程中的影响。这使得 PromptMM 可以专注于来自教师模型的最可靠信号,进行去噪的知识传递。即,对置信度较低的部分重新赋予权重,以减轻模态中可能存在的噪声的影响:
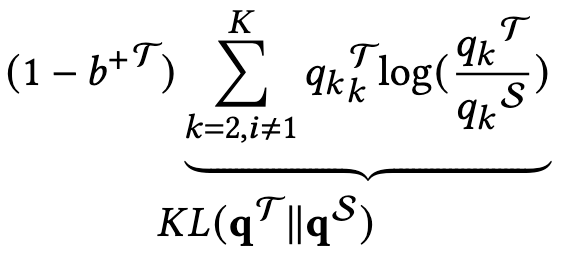
除了基于logit的知识蒸馏之外,模型提出用嵌入级别蒸馏来增强模型的PromptMM框架。为了在模型的PromptMM中实现嵌入对齐,模型采用了Scale Cosine Error (SCE)损失函数,并结合自动编码器进行鲁棒训练,而不是使用均方误差(MSE)。这是因为MSE具有敏感性和不稳定性,可能会由于不同的特征向量范数和维度灾难导致训练崩溃。模态启发的embedding蒸馏:是feature-based的蒸馏,通过SCE loss实现:
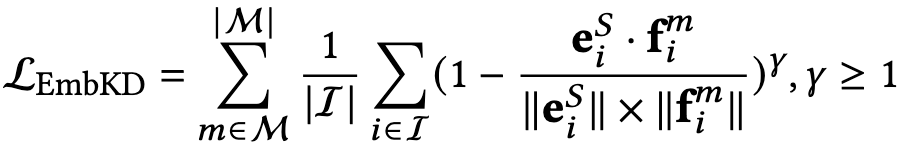
三. 最终的优化目标
最终的优化目标是BPR loss与三种KD loss的结合:
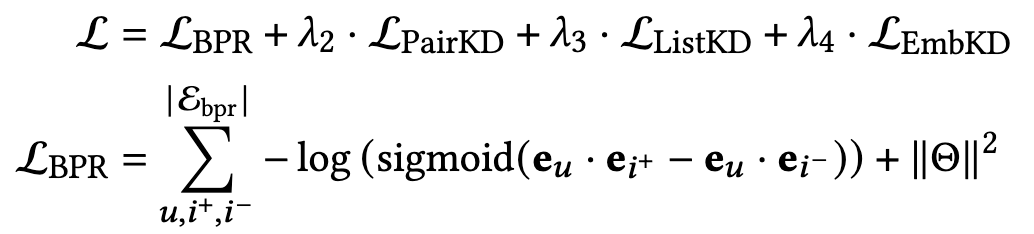
实验结果
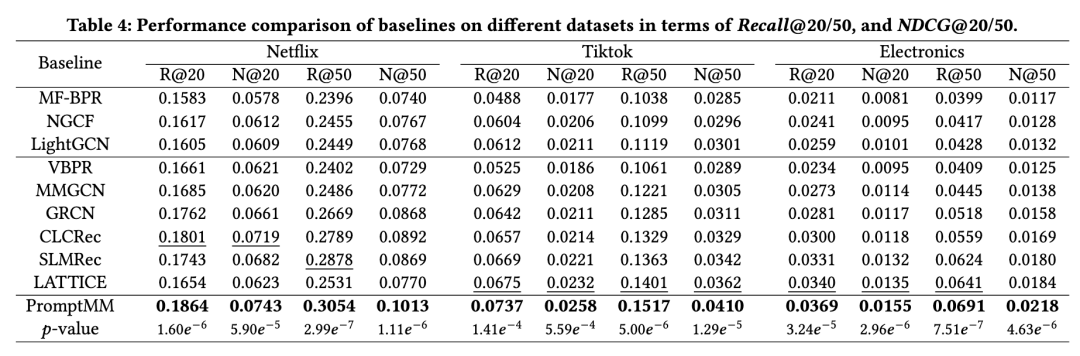
一. 主实验
所提出的 PromptMM 在所有三个数据集上始终优于普通的协同过滤(CF)模型和最先进的多模态推荐方法,表明其在多模态推荐中的有效性。改进的结果归因于moxing 设计的通过提示调整增强的多模态知识蒸馏,这不仅在多模态知识传递过程中弥合了语义差距,还消除了模态数据的噪声和冗余影响。此外,模型的结果支持多模态推荐系统比普通的 CF 模型表现更好的观点,因为多模态上下文的融合有助于在稀疏数据下辅助用户偏好学习。模型的 PromptMM 通过轻量级架构和定制转移知识取得了竞争性的结果,这表明多模态数据中可能存在噪声。这一发现证实了模型的动机,即直接将多模态信息纳入用户表示可能会引入噪声,从而误导模态感知用户偏好的编码。为了解决这个问题,模型提出的方法在知识蒸馏过程中解耦了协作关系的软标签,有效地通过向学生模型传递更多信息丰富的信号,从而减轻了多模态内容的噪声。
二. 消融实验
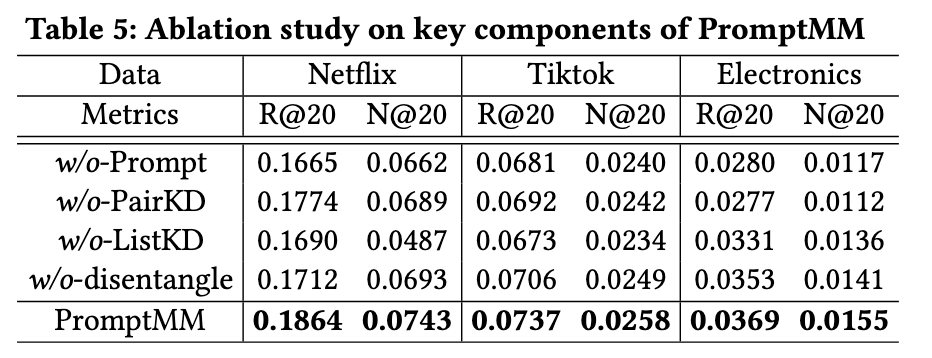
消融实验说明了知识蒸馏和soft prompt-tuning的效用。如表5所示:(1)对于没有Prompt的变体,其在所有三个数据集上的性能都比PromptMM要差。这表明去除提示调整可能会导致知识蒸馏的语义差距。模态感知投影可能也存在过拟合,并且可能仅限于编码与推荐任务相关的多模态上下文,而没有提示调整增强。(2)在去除成对蒸馏时,没有PairKD的变体表现出与PromptMM相比的性能下降,这表明了LPKD在提取基于排名的信号进行模型对齐方面的强大能力。(3)模态感知列表式蒸馏可以精确地提取质量良好的模态感知协作关系,有助于多模态推荐。因此,没有ListKD的变体不如PromptMM的结果。(4)以物品为中心的模态特征对用户的偏好存在严重偏差。因此,在没有解耦和重新加权蒸馏软标签的情况下,没有Disentangle的变体表现不佳。
三. 资源消耗实验
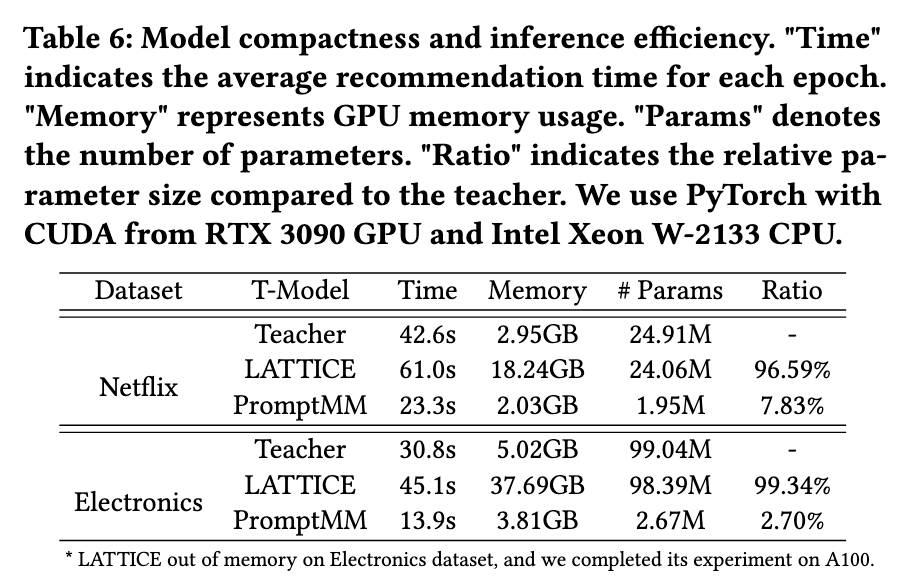
工作研究了老师、学生和几个基线(LATTICE)在训练时间、存储、参数数量和学生与教师参数比等方面的资源利用情况,以进行模型压缩。在Netflix和Electronics数据集上的具体数值结果报告在表6中。结果显示,工作的学生模型在推理和推荐时间消耗方面明显低于其他模型,可能是由于它们较大的大小,在梯度下降参数更新期间需要更多时间。此外,LATTICE必须动态学习同质图,这增加了计算时间消耗。工作发现,在工作的模型中计算KL散度并不会显著增加时间消耗,从而降低了延迟。此外,结果显示工作的模型存储消耗较低,参数数量远低于其他模型,例如LATTICE需要动态计算和存储物品-时间关系,产生了显著的开销。"ratio=11.24% or 2.70%"的数值表明了工作的模型作为压缩算法的有效性。
总结
这项工作的目标是使用一种新颖的模态感知KD框架,通过提示调整来简化和增强多模态推荐系统。为了有效地将任务相关的知识从教师模型转移到学生模型,模型引入了一个可学习的提示模块,动态地弥合了教师模型中的多模态上下文编码与学生模型中协作关系建模之间的语义差距。此外,模型提出的框架名为PromptMM,旨在分解信息性的协作关系,从而实现增强型知识蒸馏。通过大量实验,模型证明了PromptMM相比最先进的解决方案显著提高了模型效率,同时保持了更优的准确性。模型未来的工作计划是将LLMs与多模态上下文编码相结合,以提高性能。
ChatGPT4国内可以直接访问的链接,无需注册,无需翻墙,支持编程等多个垂直模型,点开即用:https://ai.zntjxt.com(复制链接电脑浏览器或微信中点开即可,也可扫描下方二维码直达)

「 更多干货,更多收获 」

【免费下载】2023年12月份热门报告合集
ChatGPT的发展历程、原理、技术架构及未来方向
《ChatGPT:真格基金分享.pdf》
2023年AIGC发展趋势报告:人工智能的下一时代
推荐系统在腾讯游戏中的应用实践.pdf
推荐技术在vivo互联网商业化业务中的实践.pdf
2023年,如何科学制定年度规划?
《底层逻辑》高清配图
推荐技术在vivo互联网商业化业务中的实践.pdf
推荐系统基本问题及系统优化路径.pdf
荣耀推荐算法架构演进实践.pdf
大规模推荐类深度学习系统的设计实践.pdf
某视频APP推荐策略详细拆解(万字长文)关注我们
智能推荐 个性化推荐技术与产品社区 | 长按并识别关注
|

一个「在看」,一段时光👇


















 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









