







hive之反斜杠导致Unicode编码字段里的中文无法正常显示
从mysql拉到hive的ods的表中字段显示不正常,如下
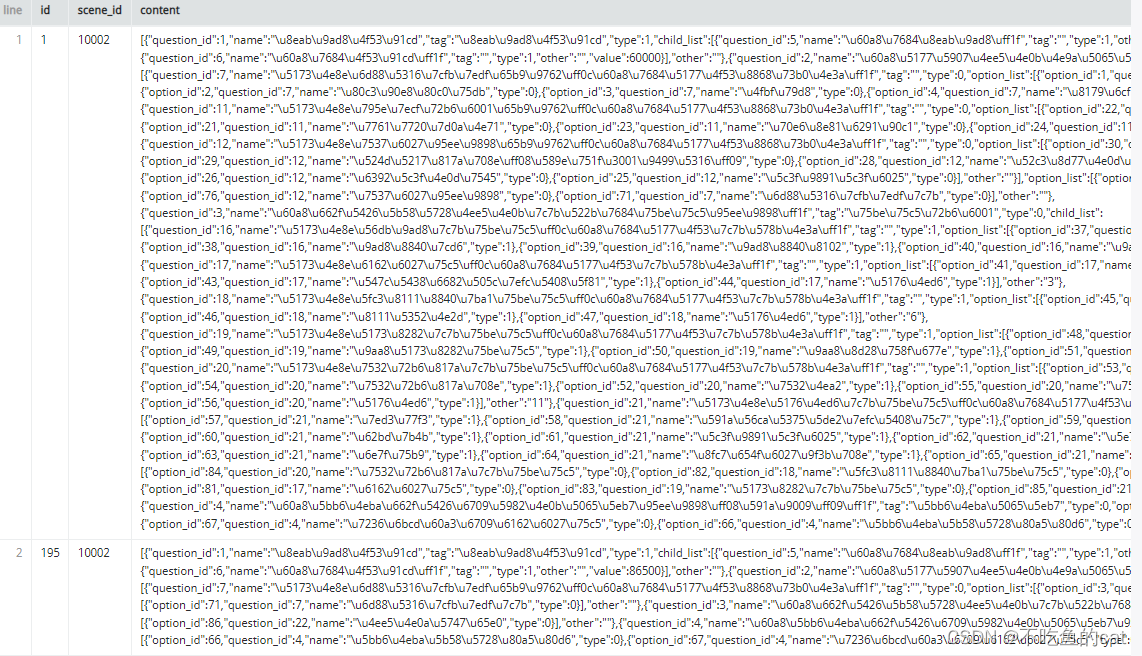
content字段中文无法显示
首先利用在线unicode解析看下具体的中文内容是什么
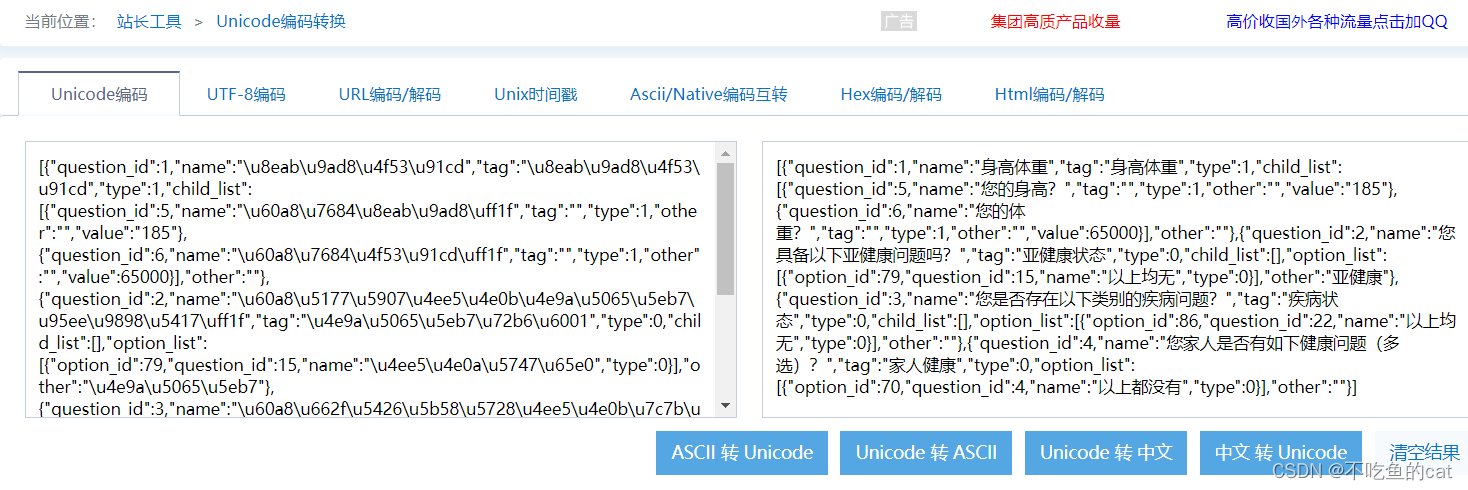
**初始判定问题原因:**此时暂时判定是因为hive没有成功将“unicode”编码格式的字段转化为“utf-8”,故而无法正常显示
因为没有找到合适的函数进行转码,所以自定义UDF,如下
import org.apache.commons.lang3.StringEscapeUtils;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.Text;
public class SelfUnicode extends GenericUDF {
/**
*
* @param arguments 输入参数类型的鉴别器对象
* @return 返回值类型的鉴别器对象
* @throws UDFArgumentException
*/
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
// 判断输入参数的个数
if(arguments==null ||arguments.length!=1){
throw new UDFArgumentLengthException("函数的参数个数不正确!!!");
}
// 判断输入参数的类型
if(!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(0,"函数参数类型不正确!!!");
}
//需要返回string类型的鉴别器对象
return PrimitiveObjectInspectorFactory.writableStringObjectInspector;
}
/**
*
* @param arguments
* @return
*/
//private final IntWritable intWritable = new IntWritable(0);
private final Text result = new Text();
public Object evaluate( DeferredObject[] arguments) throws HiveException {
Object o = arguments[0].get();
if(o==null){
result.set("NULL");
return result;
}
String str = o.toString();
if(str.equals("")){
result.set("字段值为空");
return result;
}
String res_str="";
try {
res_str = URLDecoder.decode(str, "utf-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
result.set(res_str);
return result;
}
public String getDisplayString(String[] strings) {
return "";
}
}
上传hdfs后,添加临时函数,测试运行得结果
add jar hdfs:///user/hive/warehouse/auxlib/self_unicode-1.0-SNAPSHOT.jar;
create temporary function my_unicode as 'com.atweimiao.unicodeudf.SelfUnicode';
select my_unicode('"question_id":1,"name":"\u8eab\u9ad8\u4f53\u91cd","tag":"\u8eab\u9ad8\u4f53\u91cd","type":1')
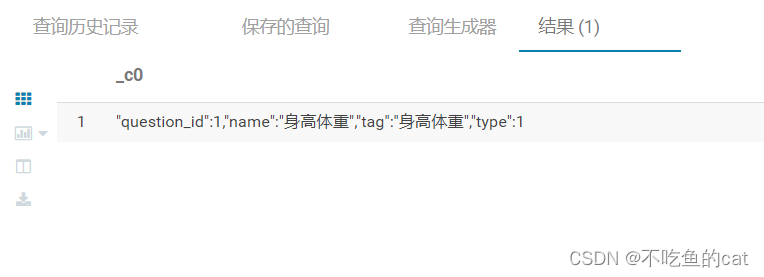
当我以为问题解决的时候,现实很骨感,竟然还是无法转码显示
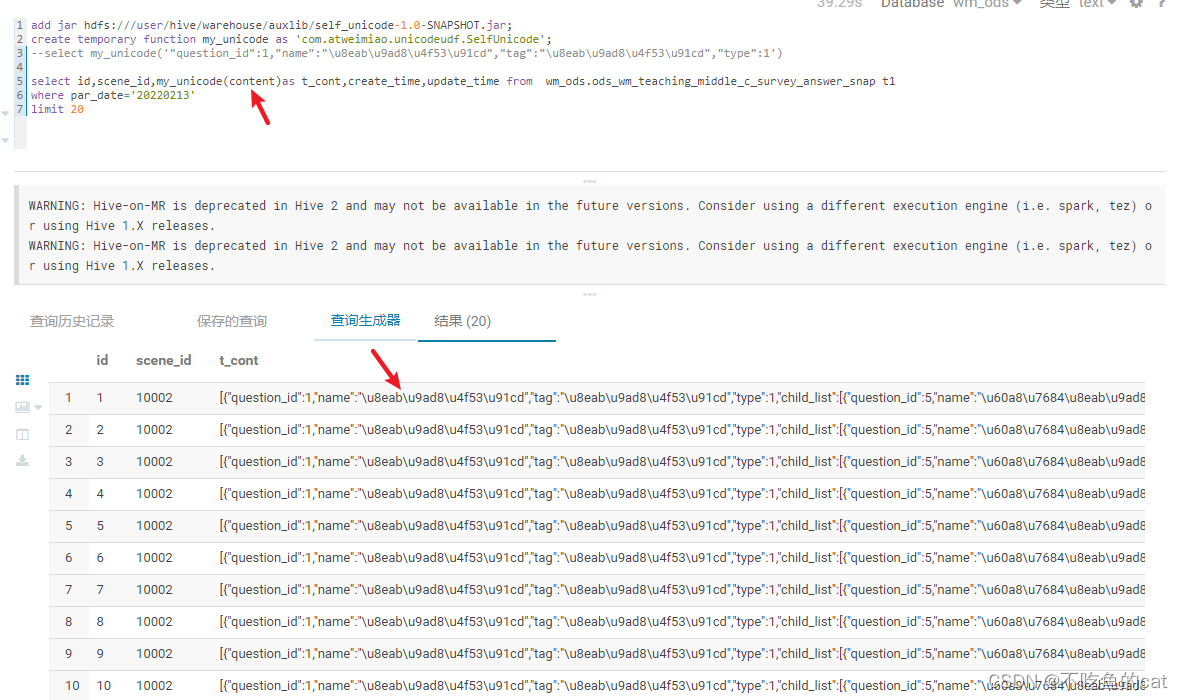
我以为代码出了问题,换网络IO的传递对象、换处理的方法,最终还是测试过程没问题,唯独解析不了字段,难受!
后来我将这堆字符串黏贴到java中发现了端倪,当这个函数处理字段的时候不是页面显示的样子,其实处理过程多了很多的转义字符‘\’

因为这些转义字符,导致URLDecoder.decode(str, "utf-8")无法正确解析str字符串
**最终判定问题原因:**思考之后,其实是反斜杠的原因,导致无法进行解析字符串
故而,使用org.apache.commons.lang3.StringEscapeUtils里的unescapeJava方法可以实现反转义
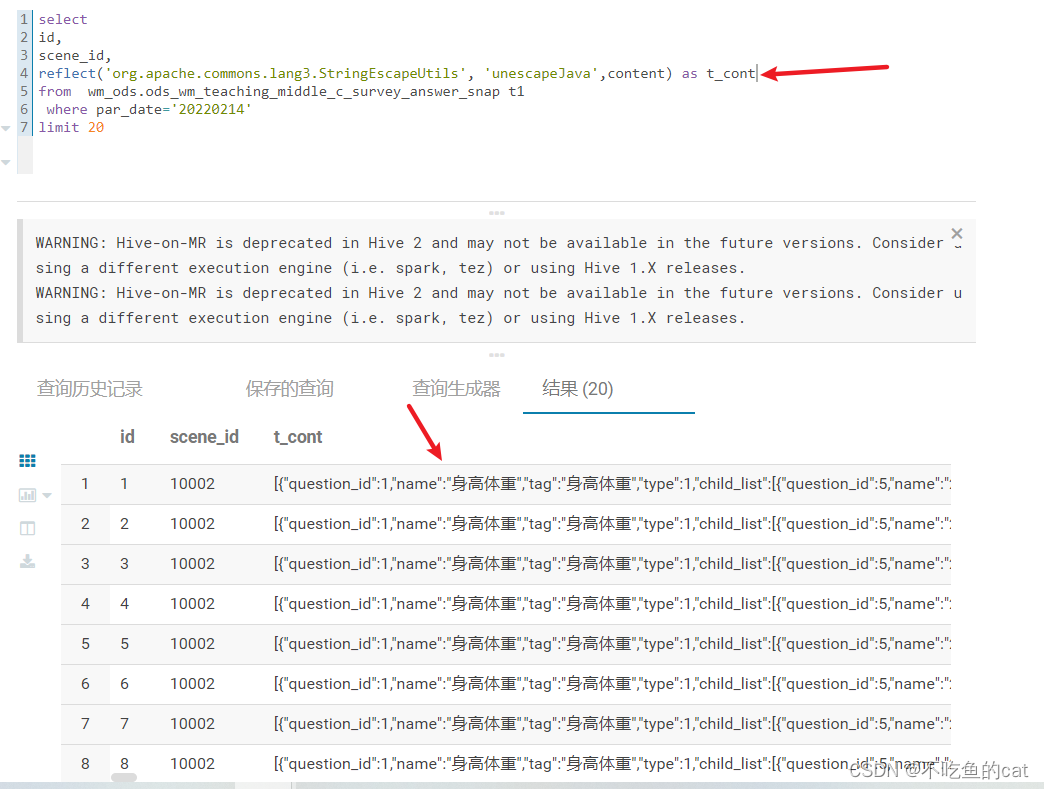
使用hive的函数reflect()有时可以实现自定义UDF的一些功能的,所以使用reflect
reflect('org.apache.commons.lang3.StringEscapeUtils', 'unescapeJava',content)
测试运行如下,成功转码显示















 1405
1405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









