







1)相关技术:
1、在Vmware中安装CentOs7系统
2、克隆虚拟机
3、修改静态IP
查看当前IP信息
ip addr
修改配置文件
vim /etc/systemconfig/network-scripts/ifcfg-ens33(不一定是ifcfg-ens33,具体看/etc/systemconfig/network-scripts下的情况),具体IP规划后面讲,保存退出

重启网络服务
systemctl network restart再次查看IP是否修改成功
4、修改主机名(在CentOs7上)
修改主机名
hostnamectl set-hostname hadoop000查看主机名
hostname
修改hosts
vim /etc/hosts
5、关闭防火墙(CentOs7系统)
查看防火墙状态
firewall-cmd --state关闭防火墙
systemctl stop firewalld.service禁止firewall开机启动
systemctl disable firewalld.service6、创建hadoop用户(系统若提示过于简单,可忽略)
创建一个用户名为:hadoop
adduser hadoop
设置密码:
passwd hadoop扩展
删除用户
userdel -rf hadoop7、配置hadoop用户具有root权限
先给与root权限进行操作
su root给sudoers文件权限
chmod 640 /etc/sudoers修改sudoers文件
vim /etc/sudoers 添加 hadoop ALL=(ALL) ALL
保存退出

恢复sudoers权限
chmod 440 /etc/sudoers8、在/opt目录下创建文件夹module(集群安装地址)、software(安装包存放地址)
创建文件夹module、software
sudo mkdir module software修改module和software文件夹所有者
sudo chown hadoop:hadoop module/ software/ 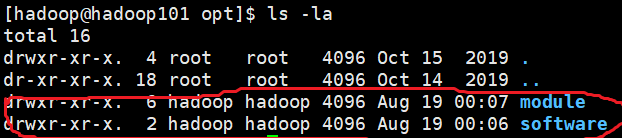
9、查看hadoop --HDFS可用空间
hdfs dfsadmin -report 
查看hadoop中空间
df -lh
2)集群规划:
服务器准备:hadoop101、hadoop102、hadoop103
IP划分如下
| 服务器名称 | IP | 子网掩码 | 网关 |
| hadoop000 | 192.168.116.129 | 255.255.255.0 | 192.168.116.2 |
| hadoop101 | 192.168.116.130 | 255.255.255.0 | 192.168.116.2 |
| hadoop102 | 192.168.116.131 | 255.255.255.0 | 192.168.116.2 |
| hadoop103 | 192.168.116.132 | 255.255.255.0 | 192.168.116.2 |
整体规划如下(考虑内存压力)

3)虚拟机环境准备:
1、在Vmware中安装一个CentOs7系统(包含设置静态IP--192.168.116.129、主机名--hadoop000、关闭防火墙、创建hadoop用户、配置hadoop用户root权限、创建module和software文件夹并修改文件夹所有者,)--可将其作为原版备份,方便以后使用
2、克隆虚拟机(一共三份)
3、修改克隆虚拟机的静态IP,见前面IP划分
4、修改主机名(将三份克隆虚拟机主机名分别修改为hadoop101,hadoop102,hadoop103)
4)集群搭建
1、安装jdk(在hadoop101中)
将jdk文件放置到software中
解压jdk文件到module中
tar -zxvf /opt/module/jdk-8u144-linux-x64.tar.gz -C /opt/software/在/etc/profile中配置jdk的环境变量(/opt/module/jdk1.8.0_144是jdk安装路径)
sudo vim /etc/profile在profile文件末尾中添加,并保存退出

让修改后文件生效
source /etc/profile测试是否生效
java -version
2、SSH免密登陆
使用hadoop用户进行生成公钥和私钥(在hadoop101中)
ssh-keygen -t rsa进入到.ssh目录下,将公钥拷贝到免密登陆的目标机器上
ssh-copy-id hadoop102
ssh-copy-id hadoop103hadoop102和hadoop103进行同样的操作,这样三台机器都可以相互免密了
3、安装hadoop(在hadoop101上)
(1)将Hadoop安装包放到/opt/software下
(2)解压Hadoop
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/(3)获取Hadoop安装路径
pwd![]()
(4)在/etc/profile中配置Hadoop环境变量(与之前配置jdk方法相同),保存退出

(5)让修改后的文件生效
source /etc/profile(6)配置core-site.xml(在/opt/module/hadoop-2.7.2/etc/hadoop目录下),保存退出
vim core-site.xml
(7)配置hadoop-env.sh
vim hadoop-env.sh

(8)配置hdfs-site.xml(此处副本系数设置为1是因为磁盘空间较少,一般情况下设置为3)
vim hdfs-site.xml
(9)配置yarn-env.sh
vim yarn-env.sh![]()
(10)配置yarn-site.xml
vim yanr-site.xml
(11)配置mapred-env.sh
vim mapred-env.sh
(12)配置mapred-site.xml(先将mapred-site.xml.template修改名为mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml vim mapred-site.xml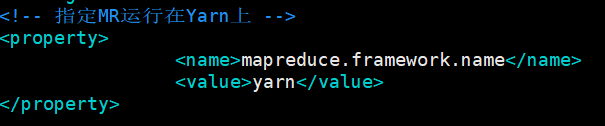
(13)配置slave
vim slaves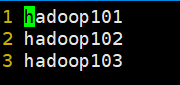
至此,配置文件全部配置完成
(14)编写集群分发脚本xsync(将文件发送到hadoop102、hadoop103)
(a)在/home/hadoop目录下创建bin目录,在bin目录下创建文件xsync,xsync内容如下
mkdir bin
cd bin/
vim xsync
(b)修改脚本xsync执行权限
chmod 777 xsync(15)使用分发脚本xsync将hadoop配置好的文件发送到hadoop102、hadoop103
xsync /opt/module/hadoop-2.7.2/(16)使用分发脚本xsync将/etc/profile发送到hadoop102、hadoop103
xsync /etc/profile4)、启动hadoop
1、首次启动,需要格式化NameNode
hadoop namenode -format2、分别在hadoop101和hadoop102上启动HDFS和yarn(由于配置时NameNode在hadoop101上,ResourceManager在hadoop102上)
在hadoop101上(bin目录下)
./start-dfs.sh在hadoop102(bin目录下)
./yarn-site.sh3、通过jps命令查看启动进程
4、也可以通过浏览器查看:hadoop101:50070
至此,整个集群安装完成!!!















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









